This is the multi-page printable view of this section. Click here to print.
Workflow Steps
- 1: Workflow Control Steps
- 1.1: Create Workflow
- 1.2: Run Workflow
- 1.3: Stop Workflow
- 1.4: Copy Workflow
- 1.5: Rename Workflow
- 1.6: Delete Workflow
- 1.7: Set Project Variable
- 1.8: Set Workflow Variable
- 1.9: Worklow Loop
- 1.10: Raise Workflow Error
- 1.11: Clear Workflow Log
- 2: Import Steps
- 2.1: Import Archive
- 2.2: Import CSV
- 2.3: Import Excel
- 2.4: Import External Database Tables
- 2.5: Import Fixed Width
- 2.6: Import Google BigQuery
- 2.7: Import Google Spreadsheet
- 2.8: Import HDF
- 2.9: Import HTML
- 2.10: Import JSON
- 2.11: Import Project Table
- 2.12: Import Quandl
- 2.13: Import SAS7BDAT
- 2.14: Import SPSS
- 2.15: Import SQL
- 2.16: Import Stata
- 2.17: Import XML
- 3: Export Steps
- 3.1: Export to CSV
- 3.2: Export to Excel
- 3.3: Export to External Project Table
- 3.4: Export to Google Spreadsheet
- 3.5: Export to HDF
- 3.6: Export to HTML
- 3.7: Export to JSON
- 3.8: Export to Quandl
- 3.9: Export to SQL
- 3.10: Export to Table Archive
- 3.11: Export to XML
- 4: Table Steps
- 4.1: Table Anti Join
- 4.2: Table Append
- 4.3: Table Clear
- 4.4: Table Copy
- 4.5: Table Cross Join
- 4.6: Table Drop
- 4.7: Table Extract
- 4.8: Table Faker
- 4.9: Table In-Place Delete
- 4.10: Table In-Place Update
- 4.11: Table Inner Join
- 4.12: Table Lookup
- 4.13: Table Melt
- 4.14: Table Outer Join
- 4.15: Table Pivot
- 4.16: Table Union All
- 4.17: Table Union Distinct
- 4.18: Table Upsert
- 5: Dimension Steps
- 5.1: Dimension Clear
- 5.2: Dimension Create
- 5.3: Dimension Delete
- 5.4: Dimension Export
- 5.5: Dimension Load
- 5.6: Dimension Sort
- 6: Document Steps
- 6.1: Compress PDF
- 6.2: Concatenate Files
- 6.3: Convert Document Encoding
- 6.4: Convert Document Encoding to ASCII
- 6.5: Convert Document Encoding to UTF-8
- 6.6: Convert Document Encoding to UTF-16
- 6.7: Convert Image to PDF
- 6.8: Convert PDF or Image to JPEG
- 6.9: Copy Document Directory
- 6.10: Copy Document File
- 6.11: Create Document Directory
- 6.12: Crop Image to Headshot
- 6.13: Delete Document Directory
- 6.14: Delete Document File
- 6.15: Document Text Substitution
- 6.16: Fix File Extension
- 6.17: Merge Multiple PDFs
- 6.18: Rename Document Directory
- 6.19: Rename Document File
- 7: Notification Steps
- 7.1: Notify Distribution Group
- 7.2: Notify Agent
- 7.3: Notify Via Email
- 7.4: Notify Via Log
- 7.5: Notify via Microsoft Teams
- 7.6: Notify via Slack
- 7.7: Notify Via SMS
- 7.8: Notify Via Twitter
- 7.9: Notify Via Web Hook
- 8: Agent Steps
- 8.1: Agent Remote Execution of SQL
- 8.2: Agent Remote Export of SQL Result
- 8.3: Agent Remote Import Table into SQL Database
- 8.4: Document - Remote Delete File
- 8.5: Document - Remote Export File
- 8.6: Document - Remote Import File
- 8.7: Document - Remote Rename File
- 9: General Steps
- 9.1: Pass
- 9.2: Run Remote Python
- 9.3: User Defined Transform
- 9.4: Wait
- 10: PDF Reporting Steps
- 10.1: Report Single
- 10.2: Reports Batch
- 11: Common Step Operations
- 12: Allocation By Assignment Dimension
- 13: Allocation Split
- 14: Rule-Based Tagging
- 15: SAP ECC and S/4HANA Steps
- 15.1: Call SAP Financial Document Attachment
- 15.2: Call SAP General Ledger Posting
- 15.3: Call SAP Master Data Table RFC
- 15.4: Call SAP RFC
- 16: SAP PCM Steps
- 16.1: Create SAP PCM Model
- 16.2: Delete SAP PCM Model
- 16.3: Calculate PCM Model
- 16.4: Copy SAP PCM Model
- 16.5: Copy SAP PCM Period
- 16.6: Copy SAP PCM Version
- 16.7: Rename SAP PCM Model
- 16.8: Run SAP PCM Console Job
- 16.9: Run SAP PCM Hyper Loader
- 16.10: Stop PCM Model Calculation
1 - Workflow Control Steps
1.1 - Create Workflow
Description
Create a new PlaidCloud Analyze workflow.
Workflow to Create
First, select the Project in which the new workflow should be created from the dropdown menu.
Next, type in a workflow name. The name should be unique to the Project.
Examples
No examples yet...
1.2 - Run Workflow
Description
“Run Workflow” runs an existing workflow.
Workflow to Run
First, select the Project which contains the workflow to be run from the Project dropdown menu.
Next, select the particular workflow to be run from the Workflow dropdown menu.
Additionally, there is an option to Wait until processing completes before continuing. Selecting this checkbox will defer execution of the current workflow until the called workflow is completed with its execution. By default, this option is disabled, meaning that the current workflow in which this transform resides will continue processing in parallel along with the called workflow.
Examples
No examples yet...
1.3 - Stop Workflow
Description
“Stop Workflow” stops an existing, running workflow.
Workflow to Stop
First, select the Project which contains the workflow to be stopped from the Project dropdown menu.
Next, select the particular workflow to be stopped from the Workflow dropdown menu.
Examples
No examples yet...
1.4 - Copy Workflow
Description
Make a copy of an existing PlaidCloud Analyze workflow.
Workflow to Copy
First, select the Project which contains the workflow to be copied from the Project dropdown menu.
Next, select the particular workflow to be copied from the Workflow dropdown menu.
Next, enter the new workflow name into the New Workflow field. Remember: the name should be unique to the Project.
Examples
No examples yet...
1.5 - Rename Workflow
Description
Rename an existing PlaidCloud Analyze workflow.
Workflow to Rename
First, select the Project which contains the workflow to be renamed from the Project dropdown menu.
Next, select the particular workflow to be renamed from the Workflow dropdown menu.
Finally, enter the new workflow name in the Rename To field. Remember that the name should be unique to the Project.
Examples
No examples yet...
1.6 - Delete Workflow
Description
Delete an existing PlaidCloud Analyze workflow.
Workflow to Delete
First, select the Project which contains the workflow to be deleted from the Project dropdown menu.
Next, select the particular workflow to be deleted from the Workflow dropdown menu.
Examples
No examples yet...
1.7 - Set Project Variable
Description
“Set Project Variable” sets project variables for use during the workflow. A variable name and value may contain any combination of valid characters, including spaces. Variables are referenced within the workflow by placing them inside curly braces. For example, a_variable is referenced within a transform as {a_variable} so it could be used in something like a formula or field value (e.g., {a_variable} * 2).
Variable List
The table will display the list of registered project variables and the current values. Enter the value for the variable desired. It’s also possible to set variable values without registering the variable first by simply adding the variable to the list.
Examples
No examples yet...
1.8 - Set Workflow Variable
Description
“Set Workflow Variable” sets workflow variables for use during the workflow. A variable name and value may contain any combination of valid characters, including spaces. Variables are referenced within the workflow by placing them inside curly braces. For example, a_variable is referenced within a transform as {a_variable} so it could be used in something like a formula or field value (e.g. {a_variable} * 2).
Variable List
The table will display the list of registered workflow variables and the current values. Enter the value for the variable desired. It’s also possible to set variable values without registering the variable first by simply adding the variable to the list.
Examples
No examples yet...
1.9 - Worklow Loop
Description
Loops over a dataset and runs a specific workflow using the values of the looping dataset as Project variables.
Workflow to Stop
First, select the Project which contains the workflow that will be run on each loop from the Project dropdown menu.
Next, select the particular workflow for running from the Workflow dropdown menu.
Examples
Examples coming soon
1.10 - Raise Workflow Error
Description
Raise an error in a PlaidCloud Analyze workflow.
Raise Workflow Error
Mainly for use with step conditions, the step can be set to execute if conditions are met and raise an error within the workflow
1.11 - Clear Workflow Log
Description
Clear the log from an existing PlaidCloud Analyze workflow.
Workflow Log to Clear
First, select the Project which contains the workflow log to be cleared from the Project dropdown menu.
Next, select the particular workflow log to be cleared from the Workflow dropdown menu.
2 - Import Steps
2.1 - Import Archive
Description
Imports PlaidCloud table archive.
Examples
No examples yet...
Import Parameters
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
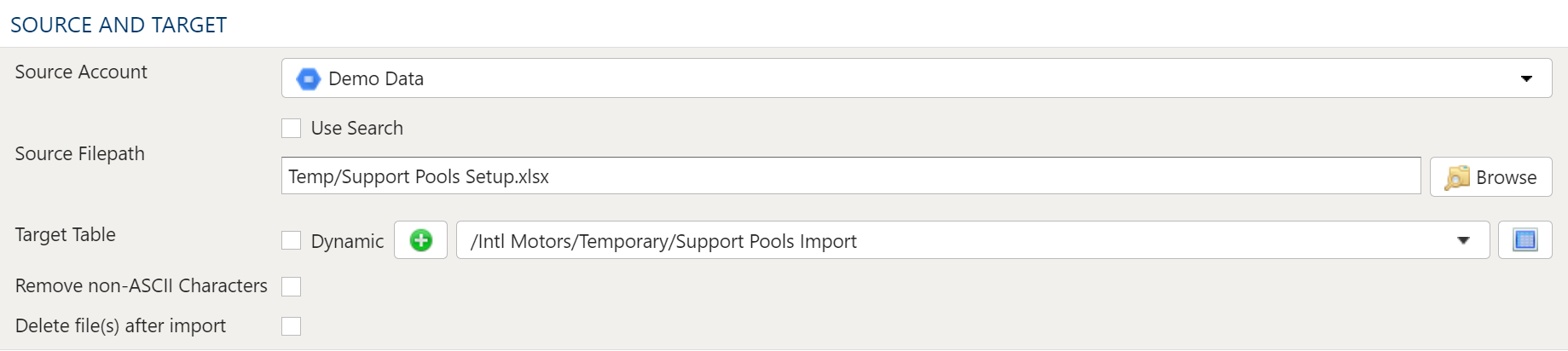
Source Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
Source FilePath
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
2.2 - Import CSV
Description
Import delimited text files from PlaidCloud Document. This includes, but is not limited to, the following delimiter types:
- comma (, )
- pipe (|)
- semicolon (; )
- tab
- space ( )
- at symbol (@)
- tilda (~)
- colon (:)
Examples
No examples yet...
Import Parameters
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Source Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
Source FilePath
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Inspect Selected Source File
By pressing the Guess Settings from Source File button, PlaidCloud will open the file and inspect it to attempt to determine the data format. Always check the guessed settings to make sure they seem correct.
Data Format
Delimiter
As mentioned above, Inspect Source File will attempt to determine the delimiter in the source file. If another delimiter is desired, use this section to specify the delimiter. Users can choose from a list of standard delimiters.
- comma (, )
- pipe (|)
- semicolon (; )
- tab
- space ( )
- at symbol (@)
- tilda (~)
- colon (:)
Header Type
Since CSVs may or may not contain headers, PlaidCloud provides a way to either use the headers, ignore headers, or use column order to determine the column alignment.
- No Header: The CSV file contains no header. Use the source list in the Data Mapper to determine the column alignment
- Has Header - Use Header and Override Field List: The CSV file has a header. Use the header names specified and ignore the source list in the Data Mapper.
- Has Header - Skip Header and Use Field List Instead: The CSV file has a header but it should be ignored. Use the header names specified by the source list in the Data Mapper.
Date Format
This setting is useful if the dates contained in the CSV file are not readily recognizable as dates and times. The import process attempts to convert dates but having a little extra information can help in the import process.
Special Characters
The special character inputs control how PlaidCloud handles the presence of certain characters and what they mean in the context of processing the CSV
- Quote Character: This is the character used to indicate an enclosed set of text that should be processed as a single field
- Escape Character: This is the character used to indicate the following character should be processed as it is and not interpreted as a special character. Useful when field may contain the delimiter.
- Null Character: Since CSVs don't have data types, this character provides a way to indicate that the value should be NULL rather than an empty string or 0.
- Trailing Negatives: Some source systems generate negative numbers with trailing negative symbols instead of prefixing the negative. This setting will process those as negative numbers.
Row Selection
For input files with extraneous records, you can specify a number of rows to skip before processing the data. This is useful if files contain header blocks that must be skipped before arriving at the tabular data.
Table Data Selection
Data Mapper Configuration
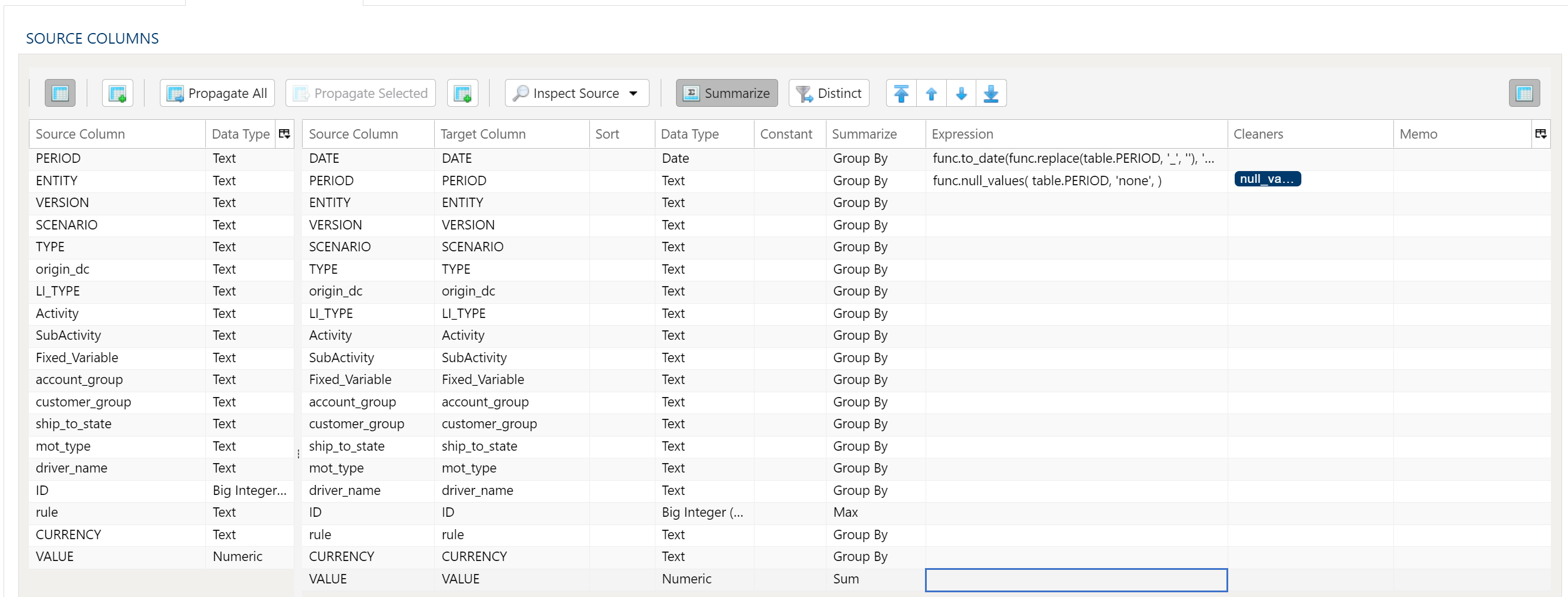
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
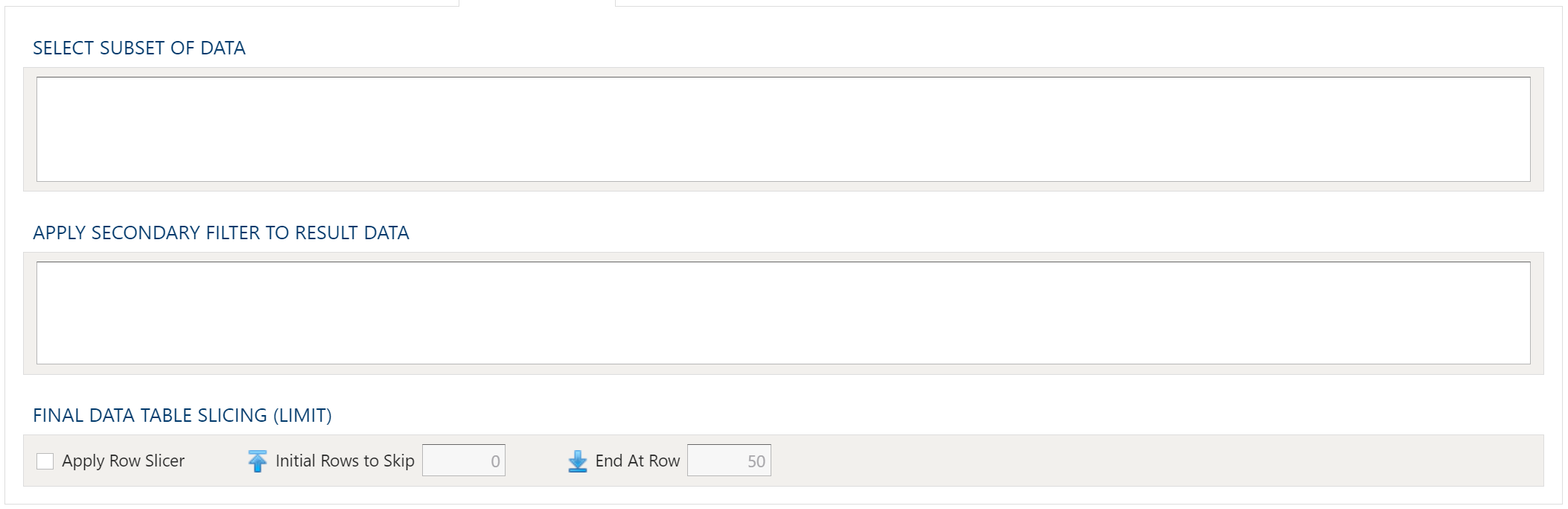
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
2.3 - Import Excel
Description
Import specific worksheets from Microsoft Excel files from PlaidCloud Document. Analyze supports the legacy Excel format (XP/2003) as well as the new format (2007/2010/2013). This includes, but is not limited to, the following file types:
- XLS
- XLSX
- XLSB
- XLSM
Examples
No examples yet...
Import Parameters
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Source Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
Source FilePath
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Header
Since Excel files may or may not contain headers, PlaidCloud provides a way to either use the headers, ignore headers, or use column order to determine the column alignment.
- No Header: The file contains no header. Use the source list in the Data Mapper to determine the column alignment
- Has Header - Use Header and Override Field List: The file has a header. Use the header names specified and ignore the source list in the Data Mapper.
- Has Header - Skip Header and Use Field List Instead: The file has a header but it should be ignored. Use the header names specified by the source list in the Data Mapper.
Row Selection
For input files with extraneous records, you can specify a number of rows to skip before processing the data. This is useful if files contain header blocks that must be skipped before arriving at the tabular data.
Worksheets to Import
Because workbooks may contain many worksheets with different data, it is possible to select which worksheets should be imported in the current import process. The options are:
- All Worksheets
- Worksheets Matching Search
- Selected Worksheets
Using Worksheet Search
The search functionality for worksheets allows inclusion of worksheets matching the search criteria. The search criteria allows for:
- Starts With: The worksheet name starts with the search text
- Contains: The worksheet name contains the search text
- Ends With: The worksheet name ends with the search text
Find Sheets in Selected File
The find sheets button will open the Excel file and list the worksheets available in the table. Mark the checkboxes in the table for the worksheets to be included in the import.
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
2.4 - Import External Database Tables
Description
Includes ability to perform delta loads and map to alternate target table names.
Examples
No examples yet...
Unique Configuration Items
None
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
2.5 - Import Fixed Width
Description
Imports fixed-width files.
Examples
No examples yet…
Import Parameters
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Source Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
Source FilePath
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Header
Since Excel files may or may not contain headers, PlaidCloud provides a way to either use the headers, ignore headers, or use column order to determine the column alignment.
- No Header: The file contains no header. Use the source list in the Data Mapper to determine the column alignment
- Has Header - Use Header and Override Field List: The file has a header. Use the header names specified and ignore the source list in the Data Mapper.
- Has Header - Skip Header and Use Field List Instead: The file has a header but it should be ignored. Use the header names specified by the source list in the Data Mapper.
Row Selection
For input files with extraneous records, you can specify a number of rows to skip before processing the data. This is useful if files contain header blocks that must be skipped before arriving at the tabular data.
Column Widths
Enter the widths of the columns seperated with commas or spaces.
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
2.6 - Import Google BigQuery
Description
Import Google BigQuery files.
Examples
No examples yet...
Unique Configuration Items
Coming soon...
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
2.7 - Import Google Spreadsheet
Description
Import specific worksheets from Google Spreadsheet files.
Examples
No examples yet...
Import Parameters
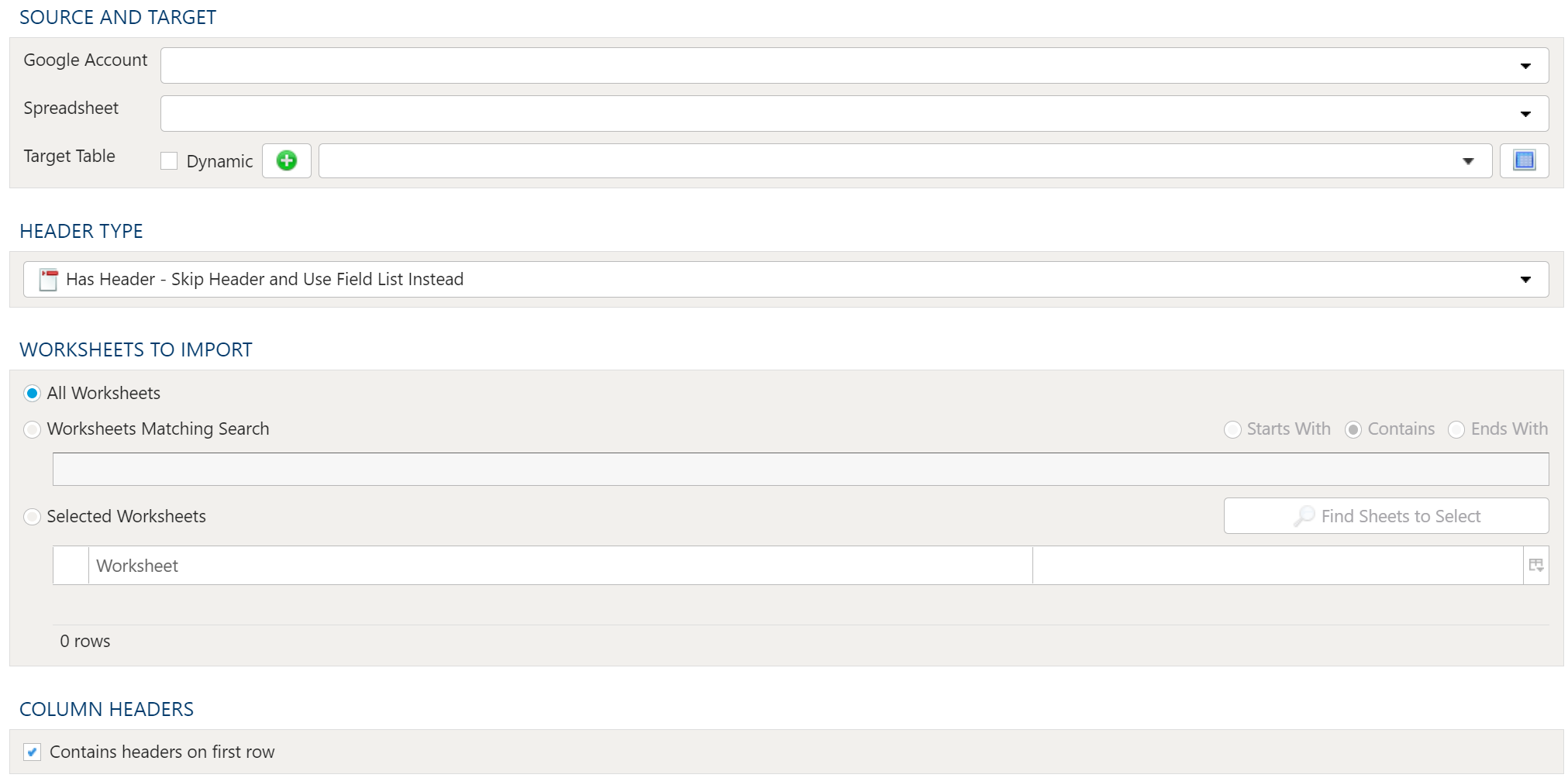
Source And Target
Google Account
Accessing Google Spreadsheet data requires a valid Google user account. This requires set up in Tools. For details on setting up a Google account connection, see here: PlaidCloud Tools – Connection.
Once all necessary accounts have been set up, select the appropriate Google Account from the drop down list.
Spreadsheet
Next, specify the Spreadsheet to import from the dropdown menu containing all available files associated with the specified Google Account.
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Header Type
Since Google Spreadsheets may or may not contain headers, PlaidCloud provides a way to either use the headers, ignore headers, or use column order to determine the column alignment.
- No Header: The file contains no header. Use the source list in the Data Mapper to determine the column alignment
- Has Header - Use Header and Override Field List: The file has a header. Use the header names specified and ignore the source list in the Data Mapper.
- Has Header - Skip Header and Use Field List Instead: The file has a header but it should be ignored. Use the header names specified by the source list in the Data Mapper.
Worksheets to Import
Because workbooks may contain many worksheets with different data, it is possible to select which worksheets should be imported in the current import process. The options are:
- All Worksheets
- Worksheets Matching Search
- Selected Worksheets
Using Worksheet Search
The search functionality for worksheets allows inclusion of worksheets matching the search criteria. The search criteria allows for:
- Starts With: The worksheet name starts with the search text
- Contains: The worksheet name contains the search text
- Ends With: The worksheet name ends with the search text
Find Sheets in Selected File
The find sheets button will open the Excel file and list the worksheets available in the table. Mark the checkboxes in the table for the worksheets to be included in the import.
Column Headers
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
2.8 - Import HDF
Description
Import HDF5 files from PlaidCloud Document.
For more details on HDF5 files, see the HDF Group’s official website here: http://www.hdfgroup.org/HDF5/.
Examples
No examples yet...
Unique Configuration Items
Key Name
HDF files store data in a path structure. A key (path) is needed as the destination for the table within the HDF file. In most situations, this will be table.
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
2.9 - Import HTML
Description
Import HTML table data from the internet.
Examples
No examples yet...
Unique Configuration Items
Select Tables in HTML
Since it is possible to have multiple tables on a web page, the user must specify which table to import. To do so, specify Name and/or Attribute values to match.
For example, consider the following table:
<table border="1" id="import"> <tr> <th>Hello</th><th>World</th> </tr> <tr> <td>1</td><td>2</td> </tr> <tr> <td>3</td><td>4</td> </tr> </table>
To import this table, specify id:import in the Name Match field.
Additionally, there is an option to skip rows at the beginning of the table.
Column Headers
Specify the row to use for header information. By default, the Column Header Row is 0.
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
2.10 - Import JSON
Description
Import JSON text files from PlaidCloud Document.
For more details on JSON files, see the JSON official website here: http://json.org/.
JSON files do not retain column order. The column order in the source file does not necessarily reflect the column order in the imported data table.
Examples
No examples yet...
Unique Configuration Items
JSON Data Orientation
Consider the following data set:
| ID | Name | Gender | State | | 1 | Jack | M | MO | | 2 | Jill | F | MO | | 3 | George | M | VA | | 4 | Abe | M | KY |
JSON files can be imported from one of three data formats:
- Records: Data is stored in Python dictionary sets, with each row stored in {Column -> Value, …} format. For example:
[{ "ID": 1, "Name": "Jack", "Gender": "M", "State": "MO" }, { "ID": 2, "Name": "Jill", "Gender": "F", "State": "MO" }, { "ID": 3, "Name": "George", "Gender": "M", "State": "VA" }, { "ID": 4, "Name": "Abe", "Gender": "M", "State": "KY" }]
- Index: Data is stored in nested Python dictionary sets, with each row stored in {Index -> {Column -> Value, …},…} format. For example:
{ "0": { "ID": 1, "Name": "Jack", "Gender": "M", "State": "MO" }, "1": { "ID": 2, "Name": "Jill", "Gender": "F", "State": "MO" }, "2": { "ID": 3, "Name": "George", "Gender": "M", "State": "VA" }, "3": { "ID": 4, "Name": "Abe", "Gender": "M", "State": "KY" } }
- Split: Data is stored in a single Python dictionary set, values stored in lists. For example:
{ "columns": ["ID", "Name", "Gender", "State"], "index": [0, 1, 2, 3], "data": [ [1, "Jack", "M", "MO"], [2, "Jill", "F", "MO"], [3, "George", "M", "VA"], [4, "Abe", "M", "KY"] ] }
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
2.11 - Import Project Table
Description
Import table data from a different project.
Data Sharing Management

In order to import a table from another project you must first go to both projects Home Tab and allow the projects to share data with each other. To do this select New Data Share and select the project and give them Read access.
Import External Project Table
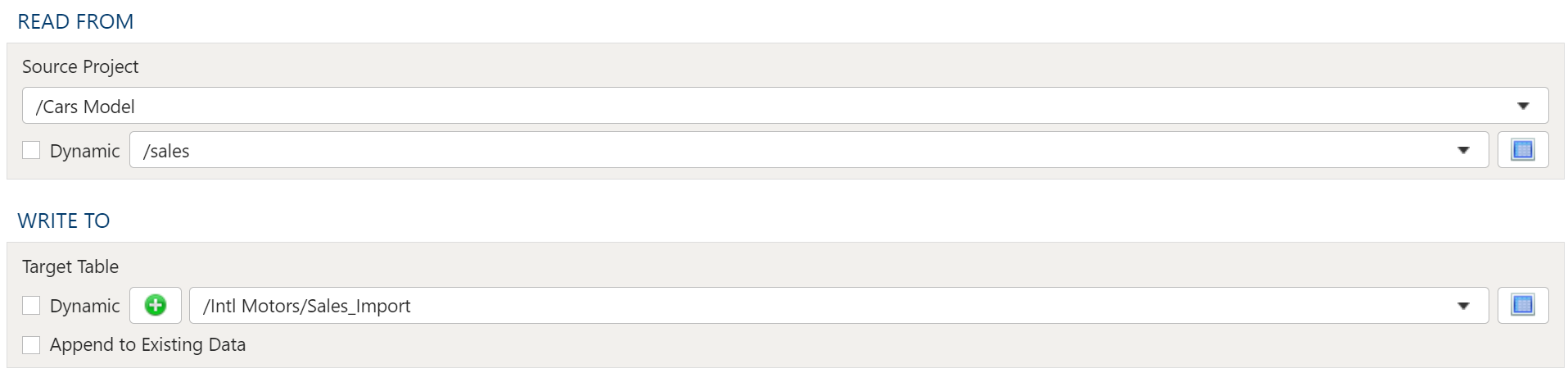
Read From
Select the Source Project and Source Table from the drop downs.
Write To
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
2.12 - Import Quandl
Description
Imports data sets from Quandl’s repository of millions of data sets.
For more details on Quandl data sets, see the Quandl official website here: http://www.quandl.com/.
Examples
No examples yet...
Unique Configuration Items
Source Data Specification
Accessing Quandl data sets requires a user account or a guest account with limited access. This requires set up in Tools. For details on setting up a Quandl account connection, see here: PlaidCloud Tools – Connection.
Once all necessary accounts have been set up, select the appropriate account from the drop down list.
Next, enter criteria for the desired Quandl code. Users can use the Search functionality to search for data sets. Alternatively, data sets can be entered manually. This requires the user to enter the portion of the URL after “http://www.quandl.com”.
For example, to import the data set for Microsoft stock, which can be found here (http://www.quandl.com/GOOG/NASDAQ_MSFT), enter GOOG/NASDAQ_MSFT in the Quandl Code field.
Data Selection
It is possible to slice Quandl data sets upon import. Available options include the following:
- Start Date: Use the date picker to select the desired date.
- End Date: Use the date picker to select the desired date.
- Collapse: Aggregate results on a daily, weekly, monthly, quarterly, or annual basis. There is no aggregation by default.
- Transformation: Summary calculations.
- Limit Rows: The default value of 0 returns all rows. Any other positive integer value will specify the limit of rows to return from the data set.
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
2.13 - Import SAS7BDAT
Description
Import SAS table files from PlaidCloud Document.
Examples
No examples yet...
Unique Configuration Items
None
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
2.14 - Import SPSS
Description
Import SPSS sav and zsav files from PlaidCloud Document.
Examples
No examples yet...
Unique Configuration Items
None
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
2.15 - Import SQL
Description
Import data from a remote SQL database.
Import Parameters
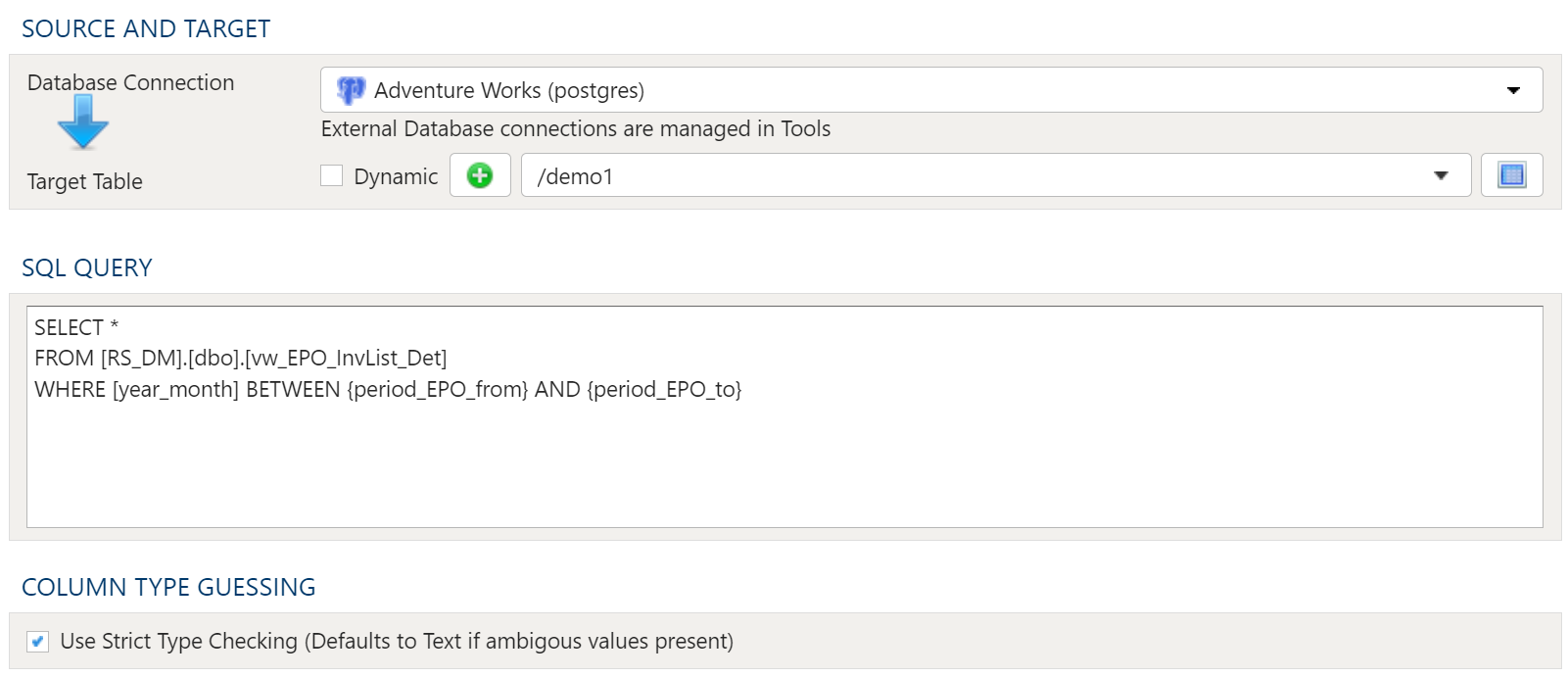
Source And Target
Database Connection
To establish a Database Connection please refer to PlaidCloud Data Connections
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
SQL Query
In this section write the SQL query to return the required data.
Column Type Guessing
SQL Imports have the option of attempting to guess the data type during load, or to set all columns to type Text. Setting the data types dynamically can be quicker if the data is clean, but can cause issues in some circumstances.
For example, if most of the data appears to be numeric but there is some text as well, it may try to set it as numeric causing load issues with mismatched data types. Or there could be issues if there is a numeric product code that is 16 digits, for example. It would crop the leading zeroes resulting in a number instead of a 16 digit code.
Setting the data to all text, however, requires a subsequent Extract step to convert any data types that shouldn't be text to the appropriate type, like dates or numerical values.
2.16 - Import Stata
Description
Import Stata files from PlaidCloud Document.
Examples
No examples yet...
Unique Configuration Items
None
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
2.17 - Import XML
Description
Import XML data as an XML file.
Examples
No examples yet...
Unique Configuration Items
None
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
3 - Export Steps
3.1 - Export to CSV
Description
Export an Analyze data table to PlaidCloud Document as a CSV delimited file.
Export Parameters
Export File Selector

The file selector in this transform allows you to choose a destination store the exported result in a PlaidCloud Document.
You choose a directory and specify a file name for the target file.
Source Table
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to source table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the source for the export, leave the Dynamic box unchecked and select the source table.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory next selection.
Target Directory Path
Select the Browse icon to the right of the Target Directory Path and navigate to the location you want the file saved to.
Target File Name
Specify the name the exported file should be saved as.
Selecting File Compression
All exported files are uncompressed, but the following compression options are available:
- No Compression
- Zip
- GZip
- BZip2
Data Format

Delimiter
The Export CSV transform is used to export data tables into delimited text files saved in PlaidCloud Document. This includes, but is not limited to, the following delimiter types:
Excel CSV (comma separated)
Excel TSV (tab separated)
User Defined Separator –>
- comma (,)
- pipe (|)
- semicolon (;)
- tab
- space ( )
- other/custom (tilde, dash, etc)
To specify a custom delimiter, select User Defined Separator –> and then Other –>, and type the custom delimiter into the text box.
Special Characters
The Special Characters section allows users to specify how to handle data with quotation marks and escape characters. Choose from the following settings:
- Special Characters (QUOTE_MINIMAL): Quote fields with special characters (anything that would confuse a parser configured with the same dialect and options). This is the default setting.
- All (QUOTE_ALL): Quote everything, regardless of type.
- Non-Numeric (QUOTE_NONNUMERIC): Quote all fields that are not integers or floats. When used with the reader, input fields that are not quoted are converted to floats.
- None (QUOTE_NONE): Do not quote anything on output. Quote characters are included in output with the escape character provided by the user. Note that only a single escape character can be provided.
Write Header To First Row
If this checkbox is selected the table headers will be exported to the first row. If it is not there will be no headers in the exported file.
Include Data Types In Headers
If this checkbox is selected the headers of the exported file will contain the data type for the column.
Windows Line Endings
Lastly, the Use Windows Compatible Line Endings checkbox is selected by default to ensure compatibility with Windows systems. It is advisable to leave this setting on unless working in a unix-only environment.
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
3.2 - Export to Excel
Description
Export an Analyze data table to PlaidCloud Document as a Microsoft Excel file. PlaidCloud Analyze supports modern versions of Microsoft Excel (2007-2016) as well as legacy versions (2000/2003).
Export Parameters
Export File Selector
The file selector in this transform allows you to choose a destination store the exported result in a PlaidCloud Document.
You choose a directory and specify a file name for the target file.
Source Table
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to source table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the source for the export, leave the Dynamic box unchecked and select the source table.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory next selection.
Target Directory Path
Select the Browse icon to the right of the Target Directory Path and navigate to the location you want the file saved to.
Target File Name
Specify the name the exported file should be saved as.
Target Sheet Name
Specify the target sheet name, the default is Sheet1
Selecting File Compression
All exported files are uncompressed, but the following compression options are available:
- No Compression
- Zip
- GZip
- BZip2
Write Header To First Row
If this checkbox is selected the table headers will be exported to the first row. If it is not there will be no headers in the exported file.
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
3.3 - Export to External Project Table
Description
Export data from a project table to different project's table.
Data Sharing Management
In order to export a table to another project you must first go to both projects Home Tab and allow the projects to share data with each other. To do this select New Data Share and select the project and give them Read access.
Export External Project Table
Read From
Select the Source Table from the drop down menu.
Write To
Target Project
Select the Target Project from the drop down menu.
Target Table Static
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Target Table Dynamic
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Append to Existing Data
To append the data from the source table to the target table select the Append to Existing Data check box.
3.4 - Export to Google Spreadsheet
Description
Export an Analyze data table to Google Drive as a Google Spreadsheet. A valid Google account is required to use this transform. User credentials must be set up in PlaidCloud Tools prior to using the transform.
Export Parameters
Source and Target
Select the Source Table from PlaidCloud Document using the dropdown menu.
Next, specify the Target Connection information. For details on setting up a Google Docs account connection, see here: PlaidCloud Tools – Connection. Once all necessary accounts have been set up, select the appropriate account from the dropdown list.
Finally, provide the Target Spreadsheet Name and Target Worksheet Name. If desired, select the Append data to existing Worksheet data checkbox to append data to an existing Worksheet. If the target worksheet does not yet exist, it will be created.
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
3.5 - Export to HDF
Description
Export an Analyze data table to PlaidCloud Document as an HDF5 file.
For more details on HDF5 files, see the HDF Group’s official website here: http://www.hdfgroup.org/HDF5/.
Export Parameters
Export File Selector
The file selector in this transform allows you to choose a destination store the exported result in a PlaidCloud Document.
You choose a directory and specify a file name for the target file.
Source Table
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to source table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the source for the export, leave the Dynamic box unchecked and select the source table.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory next selection.
Target Directory Path
Select the Browse icon to the right of the Target Directory Path and navigate to the location you want the file saved to.
Target File Name
Specify the name the exported file should be saved as.
Output File Type
All exported files are uncompressed, but the following compression options are available:
- Zip
- GZip
- BZip2
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
3.6 - Export to HTML
Description
Export an Analyze data table to PlaidCloud Document as an HTML file. The resultant HTML file will simply contain a table.
Export Parameters
Export File Selector
The file selector in this transform allows you to choose a destination store the exported result in a PlaidCloud Document.
You choose a directory and specify a file name for the target file.
Source Table
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to source table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the source for the export, leave the Dynamic box unchecked and select the source table.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory next selection.
Target Directory Path
Select the Browse icon to the right of the Target Directory Path and navigate to the location you want the file saved to.
Target File Name
Specify the name the exported file should be saved as.

Bold Rows
Select this checkbox to make the first row (header row) bold font.
Escape
This option is enabled by default. When the checkbox is selected, the export process will convert the characters <, >, and & to HTML-safe sequences.
Double Precision
See details here:
Output File Type
All exported files are uncompressed, but the following compression options are available:
- Zip
- GZip
- BZip2
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
3.7 - Export to JSON
Description
Export an Analyze data table to PlaidCloud Document as a JSON file. There are several options (shown below) for data orientation.
For more details on JSON files, see the JSON official website here: http://json.org/.
Export Parameters
Export File Selector
The file selector in this transform allows you to choose a destination store the exported result in a PlaidCloud Document.
You choose a directory and specify a file name for the target file.
Source Table
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to source table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the source for the export, leave the Dynamic box unchecked and select the source table.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory next selection.
Target Directory Path
Select the Browse icon to the right of the Target Directory Path and navigate to the location you want the file saved to.
Target File Name
Specify the name the exported file should be saved as.
JSON Orientation
Consider the following data set:
| ID | Name | Gender | State |
|---|---|---|---|
| 1 | Jack | M | MO |
| 2 | Jill | F | MO |
| 3 | George | M | VA |
| 4 | Abe | M | KY |
JSON files can be exported into one of four data formats:
- Records: Data is stored in Python dictionary sets, with each row stored in {Column -> Value, …} format. For example: [{“ID”:1,”Name”:”Jack”,”Gender”:”M”,”State”:”MO”},{“ID”:2,”Name”:”Jill”,”Gender”:”F”,”State”:”MO”},{“ID”:3,”Name”:”George”,”Gender”:”M”,”State”:”VA”},{“ID”:4,”Name”:”Abe”,”Gender”:”M”,”State”:”KY”}]
- Index: Data is stored in nested Python dictionary sets, with each row stored in {Index -> {Column -> Value, …},…} format. For example: {“0”:{“ID”:1,”Name”:”Jack”,”Gender”:”M”,”State”:”MO”},”1”:{“ID”:2,”Name”:”Jill”,”Gender”:”F”,”State”:”MO”},”2”:{“ID”:3,”Name”:”George”,”Gender”:”M”,”State”:”VA”},”3”:{“ID”:4,”Name”:”Abe”,”Gender”:”M”,”State”:”KY”}}
- Split: Data is stored in a single Python dictionary set, values are stored in lists. For example: {“columns”:[“ID”,”Name”,”Gender”,”State”],”index”:[0,1,2,3],”data”:[[1,”Jack”,”M”,”MO”],[2,”Jill”,”F”,”MO”],[3,”George”,”M”,”VA”],[4,”Abe”,”M”,”KY”]]}
- Values: Data is stored in multiple Python lists. For example: [[1,”Jack”,”M”,”MO”],[2,”Jill”,”F”,”MO”],[3,”George”,”M”,”VA”],[4,”Abe”,”M”,”KY”]]
Date Handling
Specify Date Format using the dropdown menu. Choose from the following formats:
- Epoch (Unix Timestamp – Seconds since 1/1/1970)
- ISO 8601 Format (YYYY-MM-DD HH:MM:SS with timeproject offset)
Specify Date Unit using the dropdown menu. Choose from the following formats, listed in order of increasing precision:
- Seconds (s)
- Milliseconds (ms)
- Microseconds (us)
- Nanoseconds (ns)
Force ASCII
Select this checkbox to ensure that all strings are encoded in proper ASCII format. This is enabled by default.
Output File Type
All exported files are uncompressed, but the following compression options are available:
- Zip
- GZip
- BZip2
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
3.8 - Export to Quandl
Description
Export an Analyze data table to Quandl’s database.
Source and Target
Specify the following parameters:
- Source Table: Analyze data table to export
- Quandl Connection: Accessing Quandl data sets requires a user account or a guest account with limited access. This requires set up in Tools. For details on setting up a Quandl account connection, see here: PlaidCloud Tools – Connection
- Quandl Code: Use the Search button to search for data sets. Alternatively, data sets can be entered manually. This requires the user to enter the portion of the URL after “http://www.quandl.com”. For example, to import the data set for Microsoft stock, which can be found here (http://www.quandl.com/GOOG/NASDAQ_MSFT), enter GOOG/NASDAQ_MSFT in the Quandl Code field
- Dataset Name: Name of the dataset to be exported to Quandl
- Dataset Description: Description of dataset to be exported to Quandl
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
3.9 - Export to SQL
Description
Export an Analyze data table to PlaidCloud Document as an SQL.
Examples
No examples yet...
3.10 - Export to Table Archive
Description
Exports PlaidCloud table archive file.
Export Parameters
Export File Selector
The file selector in this transform allows you to choose a destination store the exported result in a PlaidCloud Document.
You choose a directory and specify a file name for the target file.
Source Table
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to source table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the source for the export, leave the Dynamic box unchecked and select the source table.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory next selection.
Target Directory Path
Select the Browse icon to the right of the Target Directory Path and navigate to the location you want the file saved to.
Target File Name
Specify the name the exported file should be saved as.
Examples
No examples yet...
3.11 - Export to XML
Description
Export an Analyze data table to PlaidCloud Document as an XML file.
4 - Table Steps
4.1 - Table Anti Join
Description
Table Anti Join provides the unmatched set of items between two tables. This will return the list of items in the first table without matches in the second table. This can be quite useful for determining which records are present in one table but not another.
This operation could be accomplished by using outer joins and filtering on null values for the join; however, the Anti Join transform will perform this in a more efficient and obvious way.
Table Data Selection
Table Source
Specify the source data table by selecting it from the dropdown menu.
Source Columns
Specify any columns to be included here. Selecting the Inspect Source and Populate Source Mapping Table buttons will make these columns available for the join operation.
Select Subset of Source Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples.
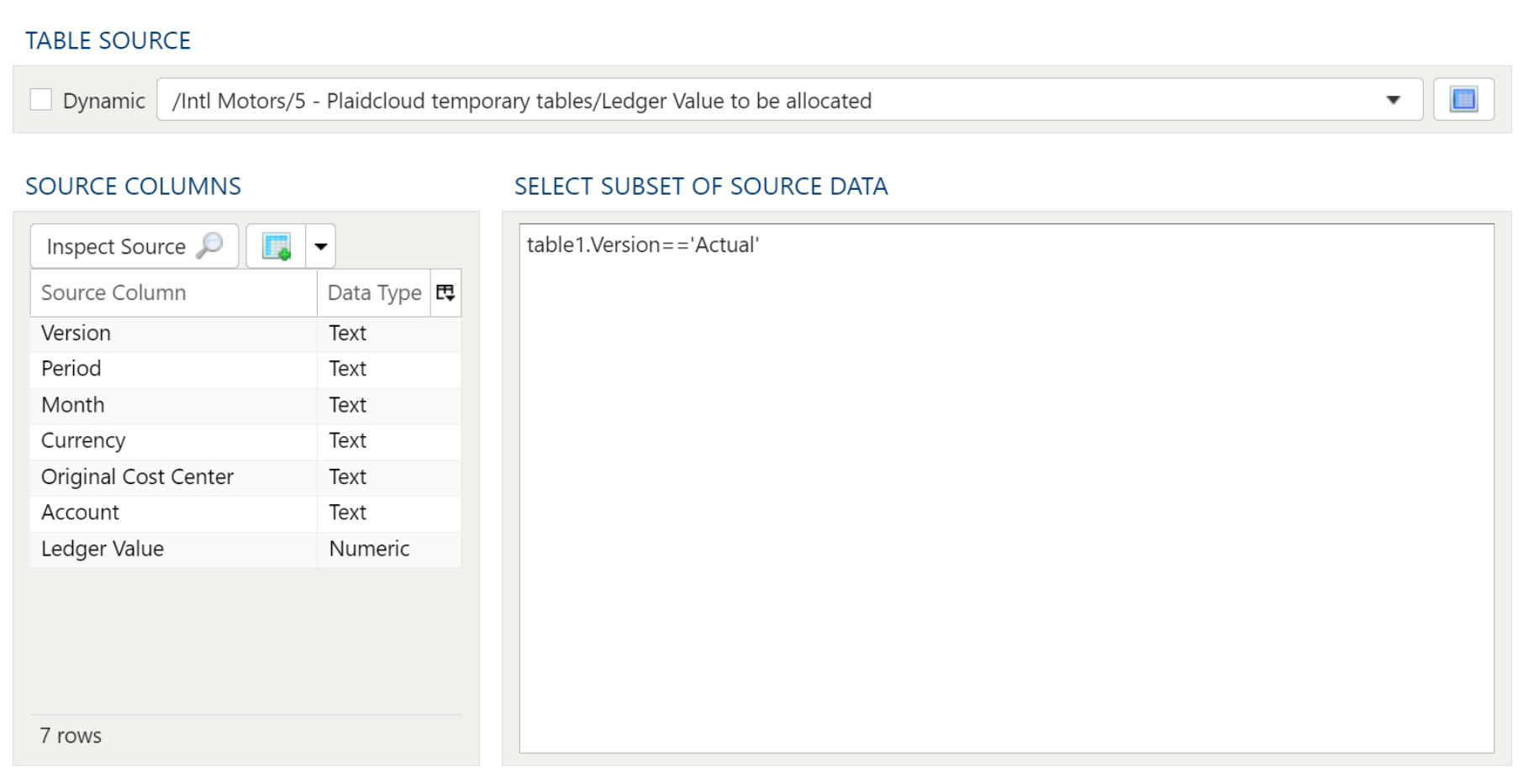
Table Output
Target Table

To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Join Map

Specify join conditions. Using the Guess button will find all matching columns from both Table 1 as well as Table 2. To add additional columns manually, right click anywhere in the section and select either Insert Row or Append Row, to add a row prior to the currently selected row or to add a row at the end, respectively. Then, type the column names to match from Table 1 to Table 2. To remove a field from the Join Map, simply right-click and select Delete.
Target Output Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Output Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
4.2 - Table Append
Description
Used append data to an existing table.
Load Parameters
Source and Target

To establish the source and target tables, first select the data table to be extracted from using the Source Table dropdown menu. Next, select an existing table as the target table using the Target Table dropdown.
Table Data Selection
When configuring the Data Mapper the columns in the source table must be mapped to a column in the target table.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
4.3 - Table Clear
Description
Clear the contents of an existing data table without deleting the actual data table. The end result is a data table with 0 rows.
Table Selection
There are two options for selecting the table or in the second option tables to:
The first option is to use the Specific Table dropdown to select the table.
The second is to use the Tables Matching Search option in which you specify the Search Path and Search Text to select the table or tables that match the search criteria. This option is very useful if you have a workflow that creates a series of commonly named tables that that have been saved appending the date.

4.4 - Table Copy
Description
Create a copy of a data table.
Source and Target
To establish the source and target tables, first select the data table to be extracted from using the Source Table dropdown menu. Next, select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
When performing the copy, Analyze will first check to see if the target data table already exists. If it does, no action will be performed unless the Allow Overwriting Existing Table checkbox is selected. If this is the case, the target table will be overwritten.
Examples
4.5 - Table Cross Join
Description
Use, as you might have expected, to perform a cross join operation on 2 data tables, combining them into a single data table without join key(s).
For more details on cross join methodology, see here: Wikipedia SQL Cross Join
Table Data Selection
Table Source
Specify the source data table by selecting it from the dropdown menu.
Source Columns
Specify any columns to be included here. Selecting the Inspect Source and Populate Source Mapping Table buttons will make these columns available for the join operation.
Select Subset of Source Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples.
Table Output
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Target Output Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Output Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
4.6 - Table Drop
Description
Drop/delete a data table.
Table Selection
Table Selection
There are two options for selecting the table or in the second option tables to:
The first option is to use the Specific Table dropdown to select the table.
The second is to use the Tables Matching Search option in which you specify the Search Path and Search Text to select the table or tables that match the search criteria. This option is very useful if you have a workflow that creates a series of commonly named tables that that have been saved appending the date.
4.7 - Table Extract
Description
Used to extract data from an existing Analyze data table into another data table. Examples include, but are not limited to, the following:
- Sort
- Group
- Summarization
- Filter/Subset Rows
- Drop Extra Columns
- Math Operations
- String Operations
Extract Parameters
Source and Target
To establish the source and target tables, first select the data table to be extracted from using the Source Table dropdown menu. Next, select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
4.8 - Table Faker
Description
Table Faker generates fake data.
Address
| Generator | Optional Arguments | | Building Number | | | City | | | City Suffix | | | Country | | | Country Code | “representation”=”alpha-2” | | Full Address | | | Latitude | | | Longitude | | | Military DPO | | | Postal Code | | | Postal Code Plus 4 | | | State | | | State Abbreviation | | | Street Address | | | Street Name | | | Street Suffix | |
Automotive
| Generator | Optional Arguments | | License Plate | |
Barcode
| Generator | Optional Arguments | | EAN13 | | | EAN8 | |
Colors
| Generator | Optional Arguments | | Color Name | | | Hex Color | | | RGB Color | | | RGB CSS Color | | | Safe Color Name | | | Safe Hex Color | |
Company
| Generator | Optional Arguments | | Company Catch Phrase | | | Company Name | | | Company Suffix | |
Credit Card
| Generator | Optional Arguments | | Expriration Date | “start”=”now”“end”=”+10y”## ‘12/20’ | | Full | “card_type”=null | | Number | “card_type”=null | | Provider | “card_type”=null | | Security Code | “card_type”=null |
Currency
| Generator | Optional Arguments | | Code | |
Date Time
| Generator | Optional Arguments | | AM/PM | | | Century | | | Date | “pattern”:”%Y-%m-%d”“end_datetime”:null | | Date Time | “tzinfo”:null“end_datetime”=null | | Date Time this Century | “before_now”=true“after_now”=false“tzinfo”=null | | Date Time this Decade | “before_now”=true“after_now”=false“tzinfo”=null | | Date Time this Month | “before_now”=true“after_now”=false“tzinfo”=null | | Date Time this Year | “before_now”=true“after_now”=false“tzinfo”=null | | Day of Month | | | Day of Week | | | ISO8601 Date Time | “tzinfo”=null“end_datetime”=null | | Month | | | Month Name | | | Past Date (Last 30 Days) | “start_date”=”-30d”“tzinfo”=null | | Timezone | | | Unix Time | “end_datetime”=null“start_datetime”=null | | Year | |
File
| Generator | Optional Arguments | | File Extension | “category”=null | | File Name | “category”=null“extension”=null | | File Path | “depth”=”1”“category”=null“extension”=null | | Mime Type | “category”=null |
Internet
| Generator | Optional Arguments | | Company Email | | | Domain Name | | | Domain Word | | | Email | | | Free Email | | | Free Email Domain | | | Image URL | “width”=null“height”=null | | IPv4 | “network”=false“address_class”=”no”“private”=null | | IPv6 | “network”=false | | MAC Address | | | Safe Email | | | Slug | | | TLD | | | URI | | | URL | “schemes”=null | | URL Extension | | | URL Page | | | User Name | |
ISBN
| Generator | Optional Arguments | | ISBN10 | “eparator”=”-“ | | ISBN13 | “eparator”=”-“ |
Job
| Generator | Optional Arguments | | Job Name | |
Lorem
| Generator | Optional Arguments | | Paragraph | “nb_sentences”=”3”“variable_nb_sentences”=true“ext_word_list”=null | | Paragraphs | “nb”=”3”“ext_word_list”=null | | Sentence | “nb_words”=”6”“variable_nb_words”=true“ext_word_list”=null | | Sentences | “nb”=”3”“ext_word_list”=null | | Text | “max_nb_chars”=”200”“ext_word_list”=null | | Word | “ext_word_list”=null | | Words | “nb”=”3”“ext_word_list”=null |
Misc
| Generator | Optional Arguments | | Binary | “length”=”1048576” | | Boolean | “chance_of_getting_true”=”50” | | Null Boolean | | | Locale | | | Language Code | | | MD5 | “raw_output”=false | | Password | “length”=”10”“special_chars”=true“digits”=true“upper_case”=true“lower_case”=true | | Random String | | | SHA1 | “raw_output”=false | | SHA256 | “raw_output”=false | | UUID4 | |
Numeric
| Generator | Optional Arguments | | Big Serial (Auto Increment) | | | Random Float | | | Random Float in Range | | | Random Integer | | | Random Integer in Range | | | Random Numeric | | | Random Percentage (0 – 1) | | | Random Percentage (0 – 100) | | | Serial (Auto Increment) | |
Person
| Generator | Optional Arguments | | First Name | | | First Name Female | | | First Name Male | | | Full Name | | | Full Name Female | | | Full Name Male | | | Last Name | | | Last Name Female | | | Last Name Male | | | Prefix | | | Prefix Female | | | Prefix Male | | | Suffix | | | Suffix Female | | | Suffix Male | |
Phone
| Generator | Optional Arguments | | Phone Number | | | ISDN | |
Tax
| Generator | Optional Arguments | | EIN | | | Full SSN | | | ITIN | |
User Agent
| Generator | Optional Arguments | | Chrome | “version_from”=”13”“version_to”=”63”“build_from”=”800”“build_to”=”899” | | Firefox | | | Full User Agent | | | Internet Explorer | | | Linux Platform Token | | | Linux Processor | | | Mac Platform Token | | | Mac Processor | | | Opera | | | Safari | | | Windows Platform Token | |
Special Generators
While these two generators do not have arguments, the options they provide act similarly to arguments.
Pattern Generator:
| Number | Format | Output | Description | | 3.1415926 | {:.2f} | 3.14 | 2 decimal places | | 3.1415926 | {:+.2f} | +3.14 | 2 decimal places with sign | | -1 | {:+.2f} | -1.00 | 2 decimal places with sign | | 2.71828 | {:.0f} | 3 | No decimal places | | 5 | {:0>2d} | 05 | Pad number with zeros (left padding, width 2) | | 5 | {:x<4d} | 5xxx | Pad Number with x’s (right padding, width 4) | | 10 | {:x<4d} | 10xx | Pad number with x’s (right padding, width 4) | | 1000000 | {:,} | 1,000,000 | Number format with comma separator | | 0.25 | {:.2%} | 25.00% | Format percentage | | 1000000000 | {:.2e} | 1.00e+09 | Exponent notation | | 13 | {:10d} | 13 | Right aligned (default, width 10) | | 13 | {:<10d} | 13 | Left aligned (width 10) | | 13 | {:^10d} | 13 | Center aligned (width 10) |
Random Choice:
In order to provide the options for random choice, simply put your options in quotes and seperate each option with a comma. So a string of random choice options would appear like this: “x”,”y”,”z”
Here, the “Key Word Args/Pattern/Choices” column of the “pattern” row contains a sentence with several references. The first reference equation ( {percentage0-100:.2f}% ) points to the “percentage0-100” row which will generate a random equation. Therefore, the random percentage produced by the “percentage0-100” row will be automatically inserted into the sentence. The reference equation {first_name} points to the row titled “first_name” which will randomly generate a first name, and this name will be automatically inserted into the sentence. The last reference equation ( {randomn_choice} ) operates the same as the other two.
With this, when the pattern generator is run, you will recieve the following results.
4.9 - Table In-Place Delete
Description
Performs a delete on the table using the specified filter conditions. The operation is performed on the designated table directly so no additional tables are created. Only the rows that meet the filter criteria are deleted. This may be an effective approach when encountering concerns related to data size.
Delete Parameters
Select the Source table for deleting from the dropdown list. This list includes all Project and Workflow data tables.
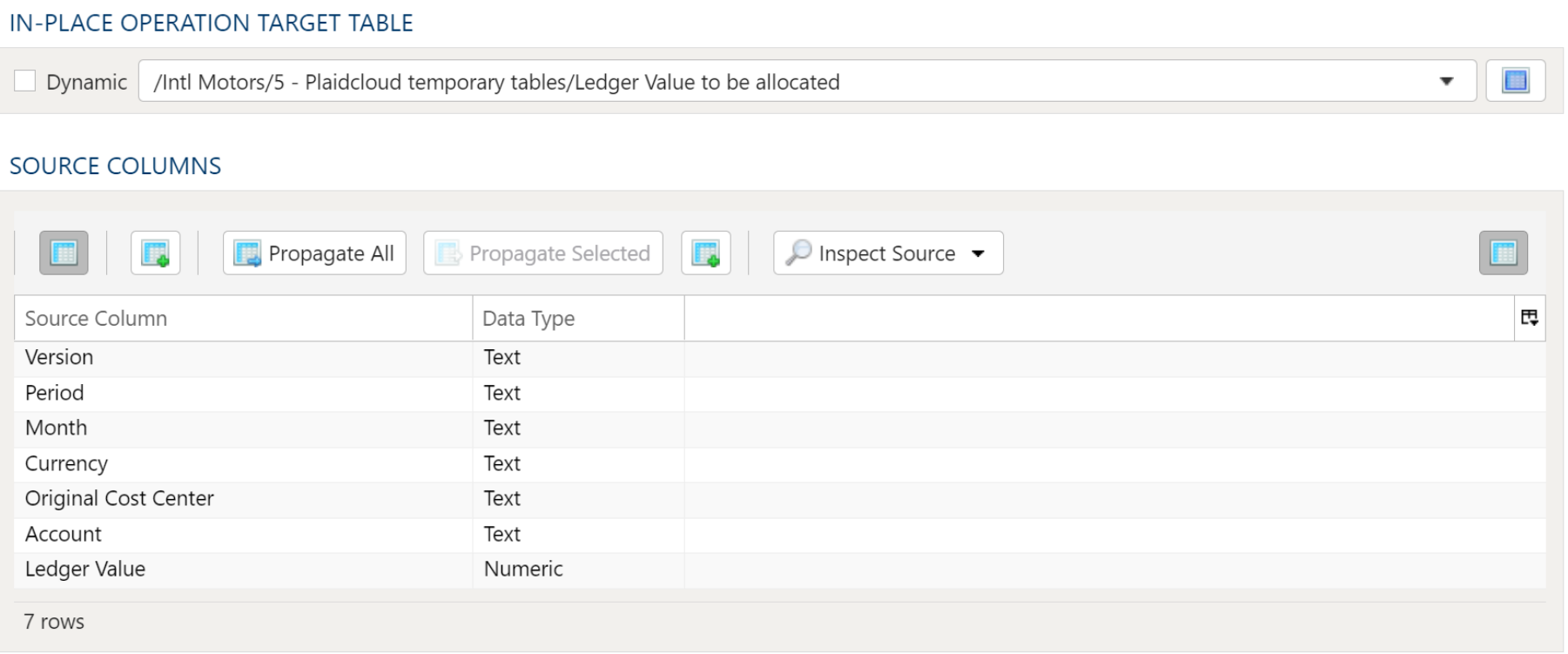
Data Filters for Delete
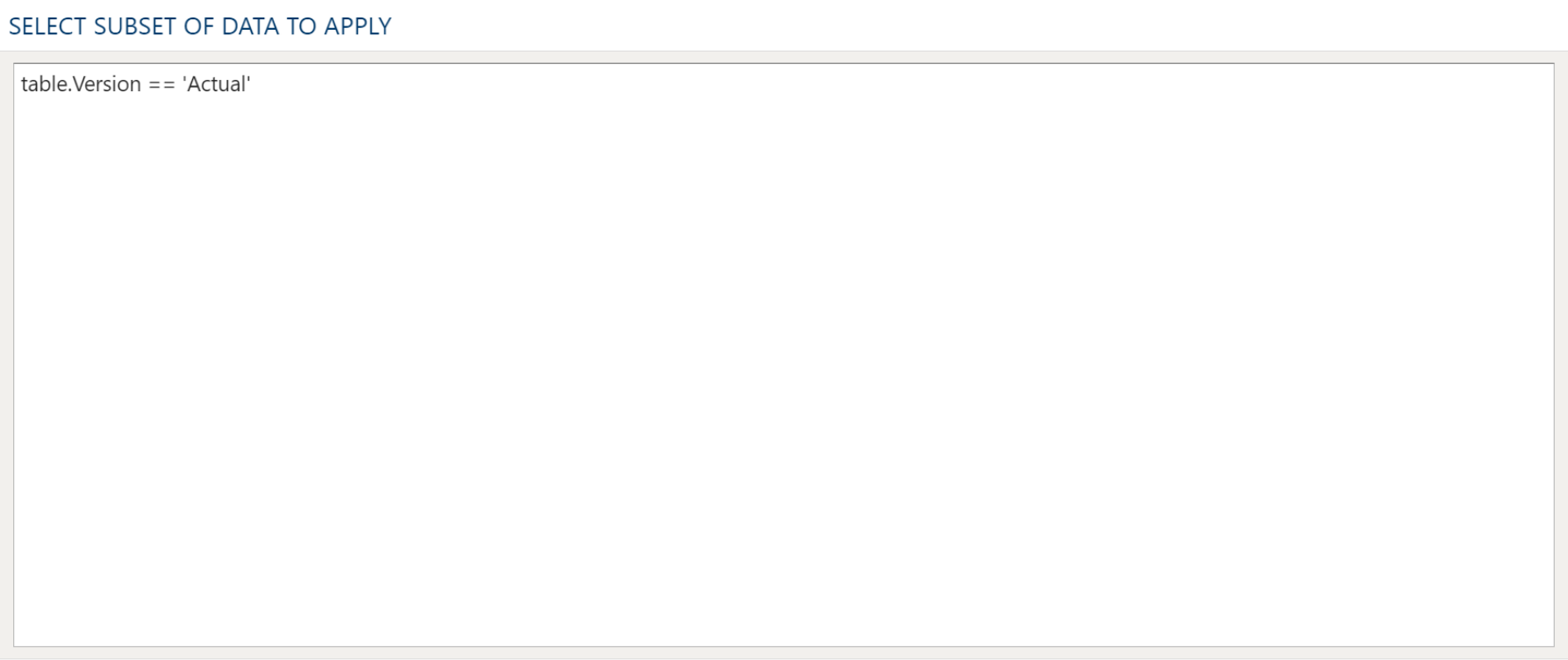
Examples
4.10 - Table In-Place Update
Description
Performs an update on the table using the specified filter conditions and value settings. The operation is performed directly on the designated table, so no additional tables are created. This may be an effective approach when concerns of data size are encountered.
Table Selection
Select the Source table for updating from the dropdown list. This list includes all Project and Workflow data tables.
Examples
In this example the Account will be set to 41000 when the Version is equal to "Actual" in "Ledger Value to be allocated".
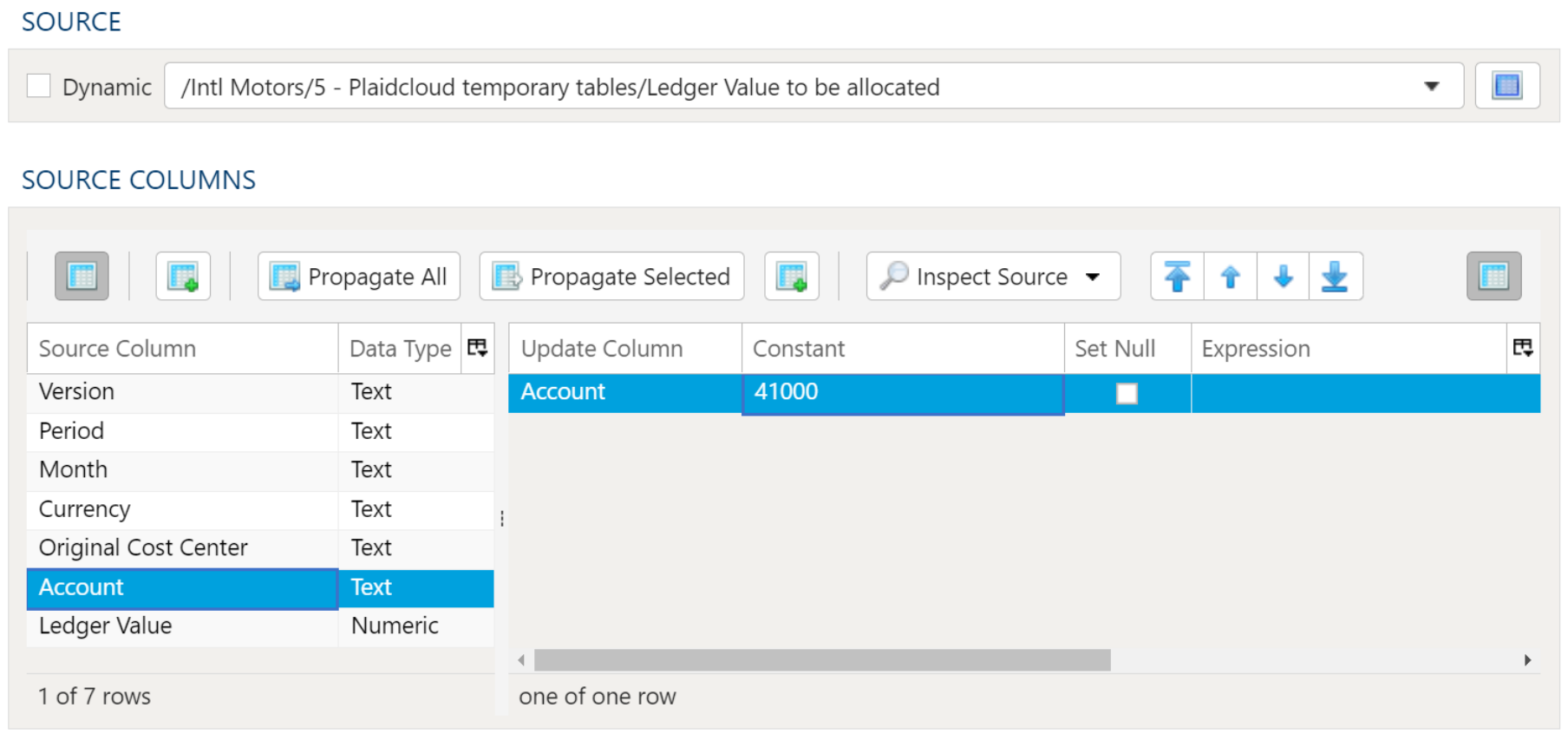
4.11 - Table Inner Join
Description
Use, as you might have expected, to perform an inner join operation on 2 data tables, combining them into a single data table based upon the specified join key(s).
For more details on inner join methodology, see here: Wikipedia SQL Inner Join
Table Data Selection
Table Source
Specify the source data table by selecting it from the dropdown menu.
Source Columns
Specify any columns to be included here. Selecting the Inspect Source and Populate Source Mapping Table buttons will make these columns available for the join operation.
Select Subset of Source Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples.
Table Output
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Join Map
Specify join conditions. Using the Guess button will find all matching columns from both Table 1 as well as Table 2. To add additional columns manually, right click anywhere in the section and select either Insert Row or Append Row, to add a row prior to the currently selected row or to add a row at the end, respectively. Then, type the column names to match from Table 1 to Table 2. To remove a field from the Join Map, simply right-click and select Delete.
Target Output Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Output Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
Join Automobile Manufacturers with Models
In this example, consider the following source data tables. First is a list of automobile manufacturers.
| Mfg_ID | Manufacturer |
|---|---|
| 1 | Aston Martin |
| 2 | Porsche |
| 3 | Lamborghini |
| 4 | Ferrari |
| 5 | Koenigsegg |
Next is a list of automobile models with a manufacturer ID. Note that there are several models with no manufacturer.
| ModelName | Mfg_ID |
|---|---|
| Aventador | 3 |
| Countach | 3 |
| DBS | 1 |
| Enzo | 4 |
| One-77 | 1 |
| Optimus Prime | |
| Batmobile | |
| Agera | 5 |
| Lightning McQueen |
To get a list of models by manufacturer, it makes sense to join on Mfg_ID.
First, specify parameters for Table 1 Data Selection. The source data table is selected and all columns are listed.
Next, specify parameters for Table 2 Data Selection. Once again, the source data table is selected and all columns are listed.
Finally, the join conditions are set in the Table Output tab. Using the Guess button, Analyze properly identifies the Mfg_ID column to use as the Join Key. Lastly, the
Target Output Columns are specified automatically using the Propagate button. This effectively includes all columns from all tables, with all join columns included only a single time. Note that the columns are sorted alphabetically, first by Manufacturer and next by ModelName.
As expected, the final output only includes values which had a match in both tables. As such, Porsche does not show up because it had no models. Likewise, the
Batmobile had no manufacturer (it was a custom job), so it’s not included.
4.12 - Table Lookup
Description
If you are a regular user of the vlookup function in Microsoft Excel, the Table Lookup transform should feel very familiar. It’s used to perform essentially the same function. Unlike the Microsoft Excel version, the PlaidCloud Analyze Table Lookup transform offers greater flexibility, especially allowing for matching on and returning multiple columns.
Table Data Selection
Table Source
Specify the source data table by selecting it from the dropdown menu.
Source Columns
Specify any columns to be included here. Selecting the Inspect Source and Populate Source Mapping Table buttons will make these columns available for the join operation.
Select Subset of Source Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples.
Table Output
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Join Map
Specify join conditions. Using the Guess button will find all matching columns from both Table 1 as well as Table 2. To add additional columns manually, right click anywhere in the section and select either Insert Row or Append Row, to add a row prior to the currently selected row or to add a row at the end, respectively. Then, type the column names to match from Table 1 to Table 2. To remove a field from the Join Map, simply right-click and select Delete.
Target Output Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Output Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
Lookup Product Dimension Information
In this example, the modeler needs information from the product dimension table to make sense of the order fact table. As such, the Import Order Fact table is selected as the Source Table. The Import Product Dim table contains the desired lookup information, so it’s selected as the Lookup Table Source. Although available, no filters are applied to the lookup data table (nor any other data tables, for that matter).
In the Table Data Selection section, all columns are mapped from the source data table to the target data table.
No Data Filters are applied to either source or target data.
Lastly, the source data table is matched to the lookup data table using the Product_ID field found in each table. Only the Product_Description and Unit_Cost columns are appended to the target data table, with Unit_Cost being renamed to Retail_Unit_Cost in the process.
In the resulting target data table, the Product_Description and Retail_Unit_Cost columns have been added, based on matching values in the Product_ID column.
4.13 - Table Melt
Description
Used to convert short, wide data tables into long, narrow data tables. Selected columns are transposed, with the column names converted into values across multiple rows.
Perhaps the easiest example to understand is to think of a data table with months listed as column headers:
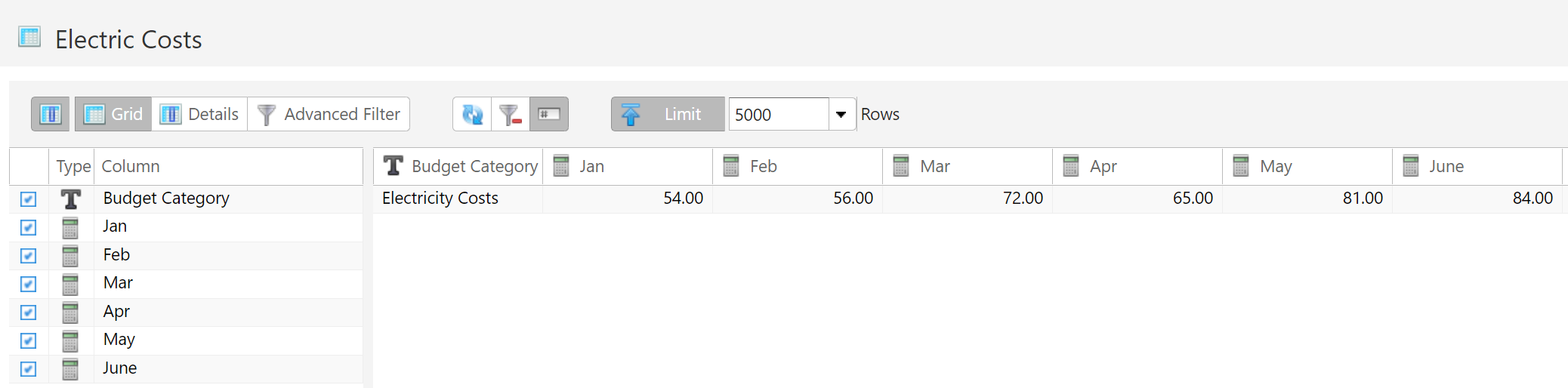
Melting this data table would convert all of the month columns into rows.
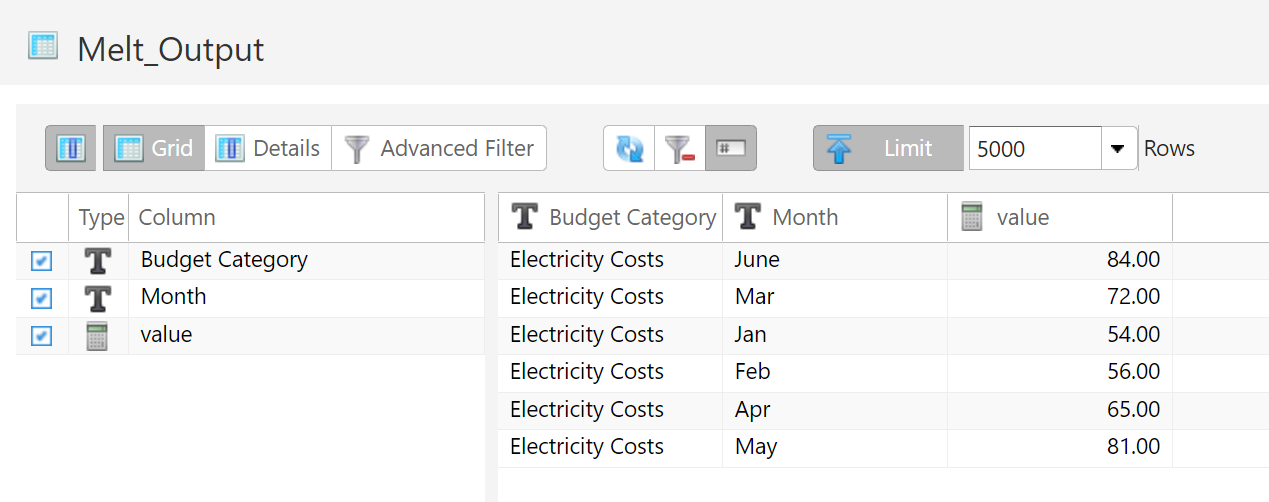
By specifying which columns to transpose and which columns to leave alone, this becomes a powerful tool. Making this conversion in other ETL tools could require a dozen more steps.
Source and Target Parameters
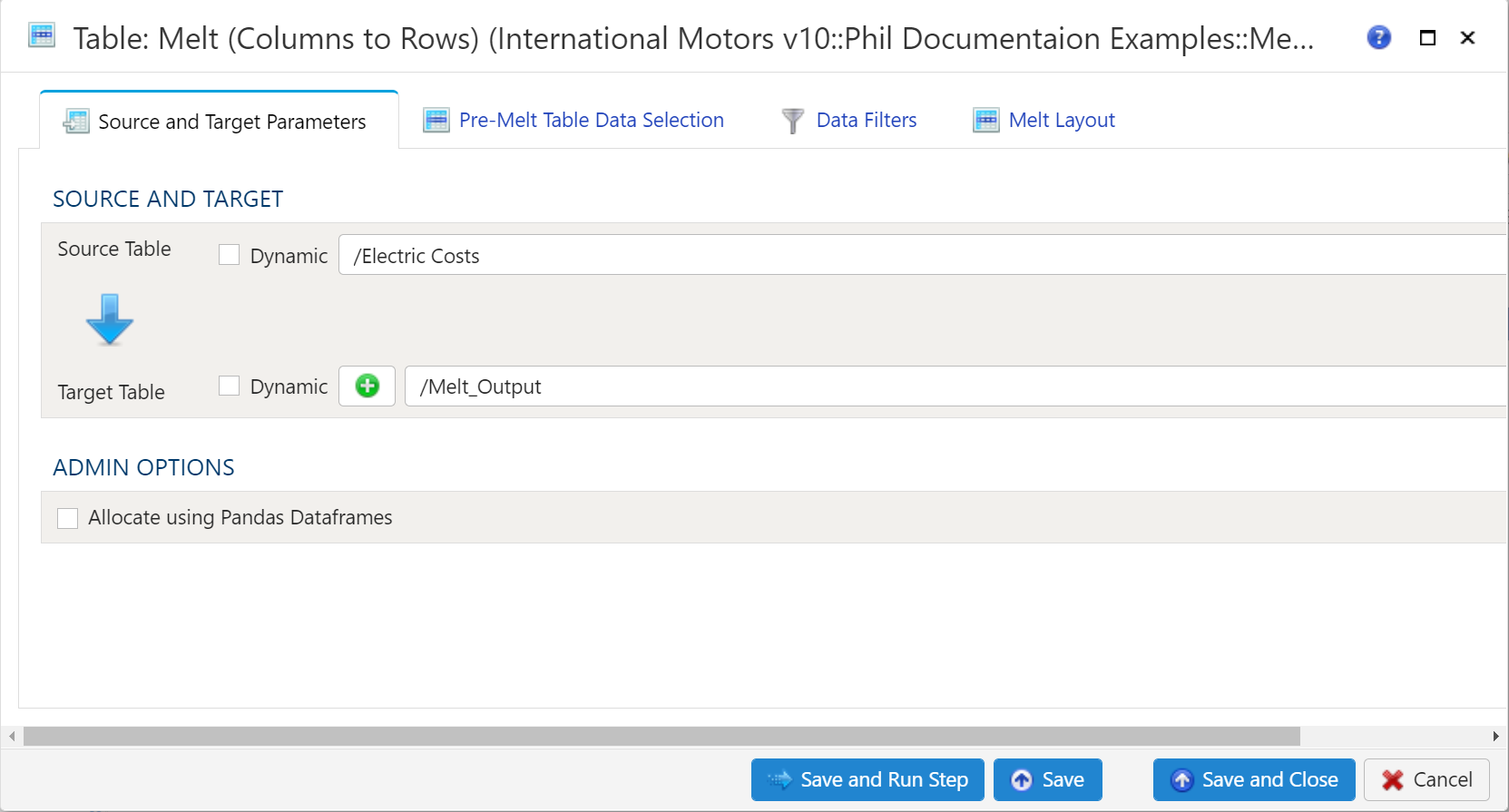
Source and Target
To establish the source and target, first select the data table to be extracted from the Source Table dropdown menu.
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Pre-Melt Table Data Selection
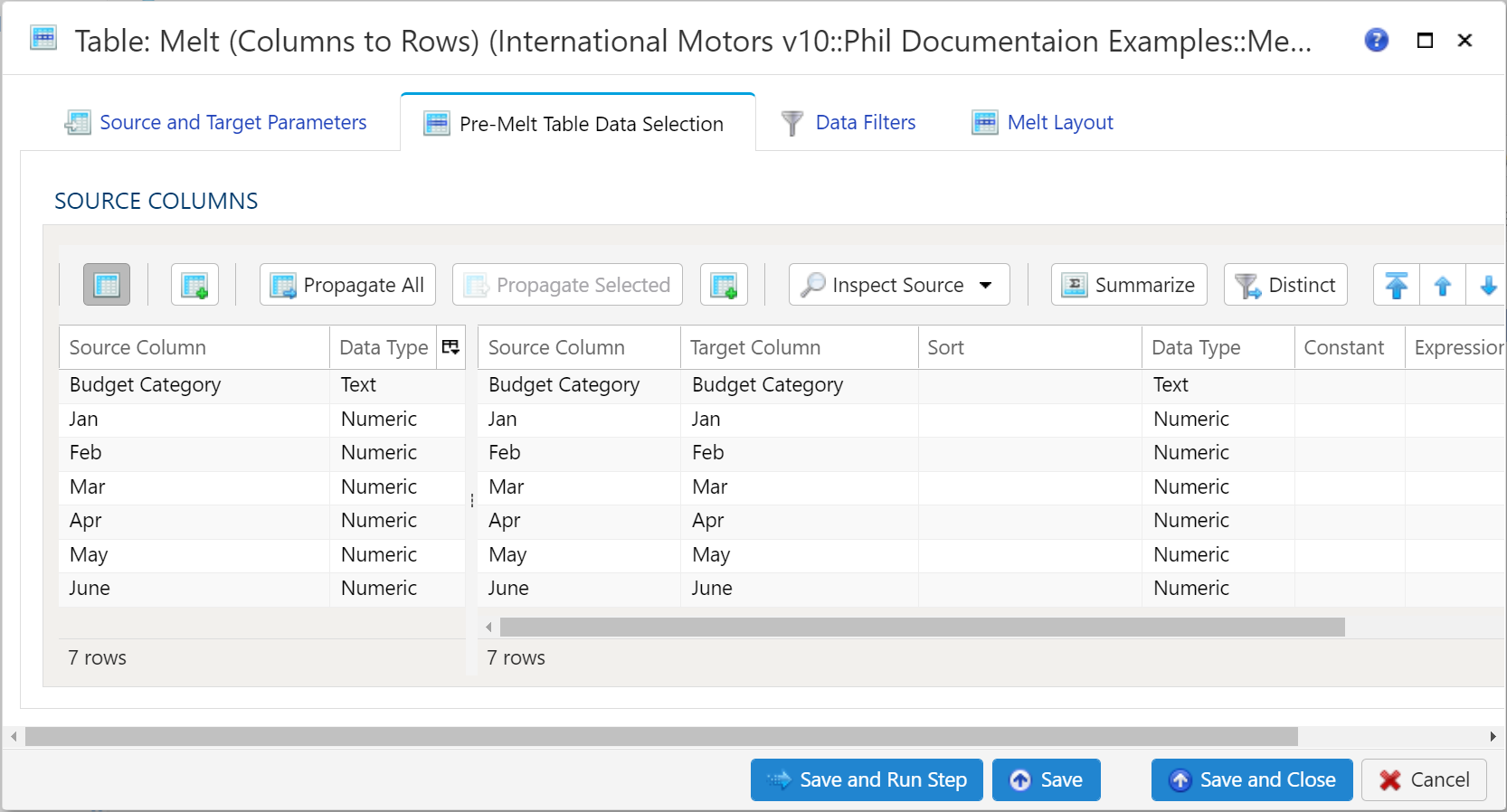
This section is a bit different from the standard Table Data Selection. Basically this is used to specify which columns are to be used in the Melt operation. This includes ID columns and Variable/Value columns.
For more details regarding Table Data Selection, see details here: Table Data Selection
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset of Source Data
Any valid Python expression is acceptable to subset the data. Please see Expressions
for more details and examples.
Apply Secondary Filter To Result Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples
Final Data Table Slicing (Limit)
To limit the data, simply check the Apply Row Slicer box and then specify the following:
- Initial Rows to Skip: Rows of data to skip (column header row is not included in count)
- End at Row: Last row of data to include. This is different from simply counting rows at the end to drop
Melt Layout
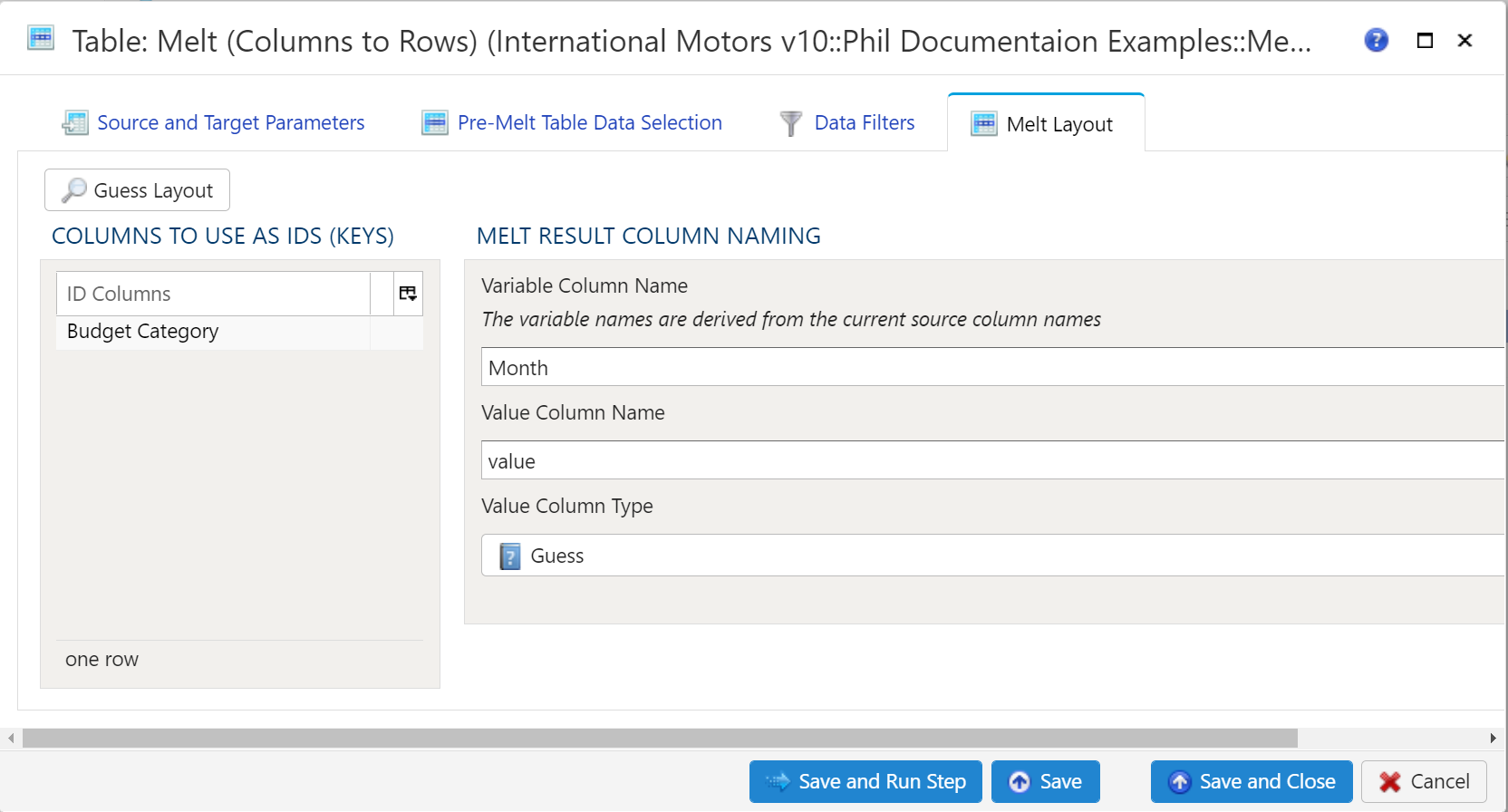
There is a Guess Layout button available to allow Analyze a first crack at specifying ID columns. By default, all text (data type of String) columns are placed in the Keys section. Numeric columns are not placed into Keys by default, but they are allowed to be there based on the model’s needs.
Columns to Use as IDs (Keys)
ID columns are the columns which remain in tact. These columns are effectively repeated for every instance of a variable/value combination. For a monthly table, this would result in 12 repetitions of ID columns.
ID columns can be added automatically or manually. To add the columns automatically, use the aforementioned Guess Layout button. To add additional columns manually, right click anywhere in the section and select either Insert Row or Append Row, to add a row prior to the currently selected row or to add a row at the end, respectively. Then, type the column name to use as an ID.
To remove a field from the IDs, simply right-click and select Delete.
Melt Result Column Naming
There are 2 values to specify. Both of these values will become column names in the target data table.
- Variable Column Name: As specified in the transform, The variable names are derived from the current source column names. Essentially, specify a column name which will represent the data originally represented in the source data table columns.
- Value Column Name: Specify a column name to represent the data represented within the source data table. Typically this will be a numerical unit: Dollars, Pounds, Degrees, Percent, etc.
Examples
In the abouve documentation.
4.14 - Table Outer Join
Description
Use, as you might have expected, to perform a full outer join operation on 2 data tables, combining them into a single data table based upon the join key(s) specified.
For more details on outer join methodology, see here: Wikipedia SQL Full Outer Join
Table Data Selection
Table Source
Specify the source data table by selecting it from the dropdown menu.
Source Columns
Specify any columns to be included here. Selecting the Inspect Source and Populate Source Mapping Table buttons will make these columns available for the join operation.
Select Subset of Source Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples.
Table Output
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Join Map
Specify join conditions. Using the Guess button will find all matching columns from both Table 1 as well as Table 2. To add additional columns manually, right click anywhere in the section and select either Insert Row or Append Row, to add a row prior to the currently selected row or to add a row at the end, respectively. Then, type the column names to match from Table 1 to Table 2. To remove a field from the Join Map, simply right-click and select Delete.
Target Output Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Output Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
Join Automobile Manufacturers with Models
In this example, consider the following source data tables. First is a list of automobile manufacturers.
| Mfg_ID | Manufacturer |
|---|---|
| 1 | Aston Martin |
| 2 | Porsche |
| 3 | Lamborghini |
| 4 | Ferrari |
| 5 | Koenigsegg |
Next is a list of automobile models with a manufacturer ID. Note that there are several models with no manufacturer.
| ModelName | Mfg_ID |
|---|---|
| Aventador | 3 |
| Countach | 3 |
| DBS | 1 |
| Enzo | 4 |
| One-77 | 1 |
| Optimus Prime | |
| Batmobile | |
| Agera | 5 |
| Lightning McQueen |
To get a list of models by manufacturer, it makes sense to join on Mfg_ID. By leveraging outer join concepts, the output will also be able to show those items which do not have any matches.
First, specify parameters for Table 1 Data Selection. The source data table is selected and all columns are listed.
Next, specify parameters for Table 2 Data Selection. Once again, the source data table is selected and all columns are listed.
Finally, the join conditions are set in the Table Output tab. Using the Guess button, Analyze properly identifies the Mfg_ID column to use as the Join Key. Lastly, the
Target Output Columns are specified automatically using the Propagate button. This effectively includes all columns from all tables, with any join columns obviously only being included a single time. Note that the columns are sorted alphabetically, first by Manufacturer and next by ModelName.
As expected, the final output includes all rows from both tables, whether they had a match in both tables or not. As such, this time Porsche does indeed show up despite having no models. Additionally, Batmobile, Lightning McQueen, and Optimus Prime are included in the results even though none of them have a manufacturer. Besides, who can say ‘No’ to them?
4.15 - Table Pivot
Description
Used to convert long, narrow data tables into short, wide data tables. Selected columns are transposed, with the column names converted into values across multiple columns.
Perhaps the easiest example to understand is to think of a data table with months listed as rows:
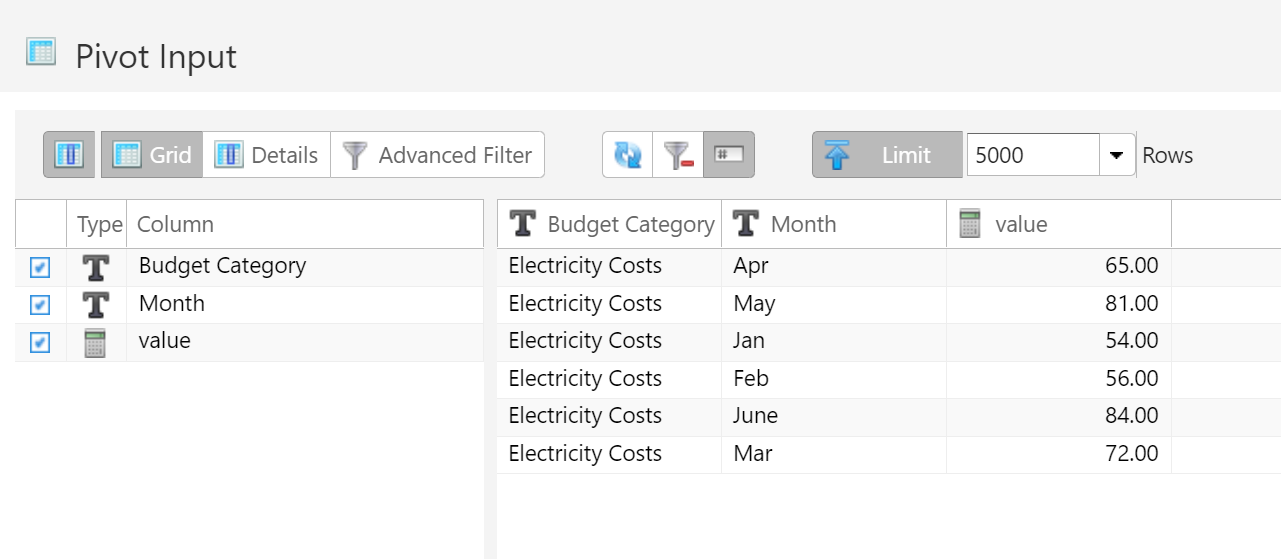
Pivoting this data table would convert all of the month rows into columns.
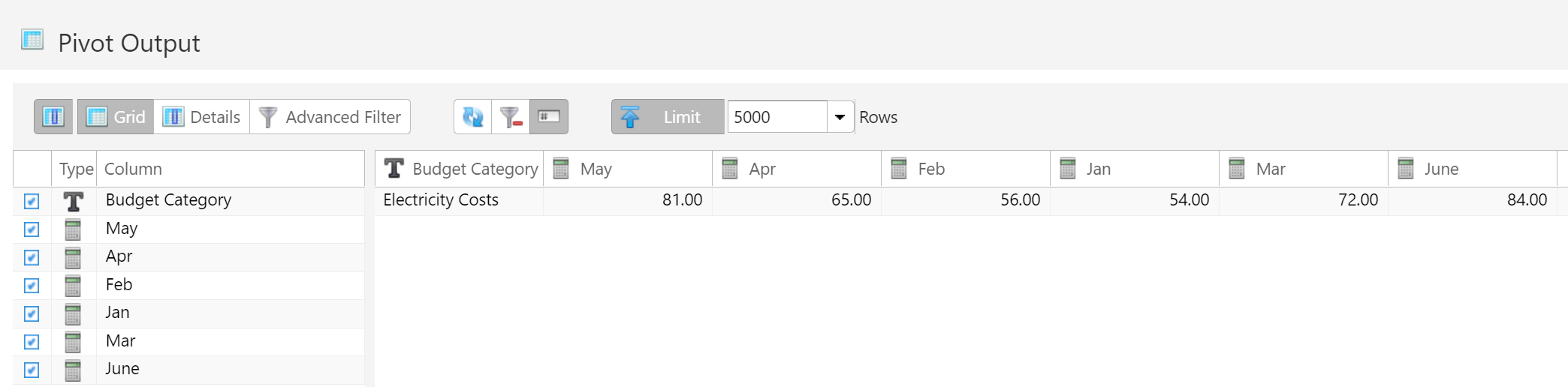
By specifying which columns to transpose and which columns to leave alone, this becomes a powerful tool. Making this conversion in other ETL tools could require a dozen more steps.
Source and Target Parameters
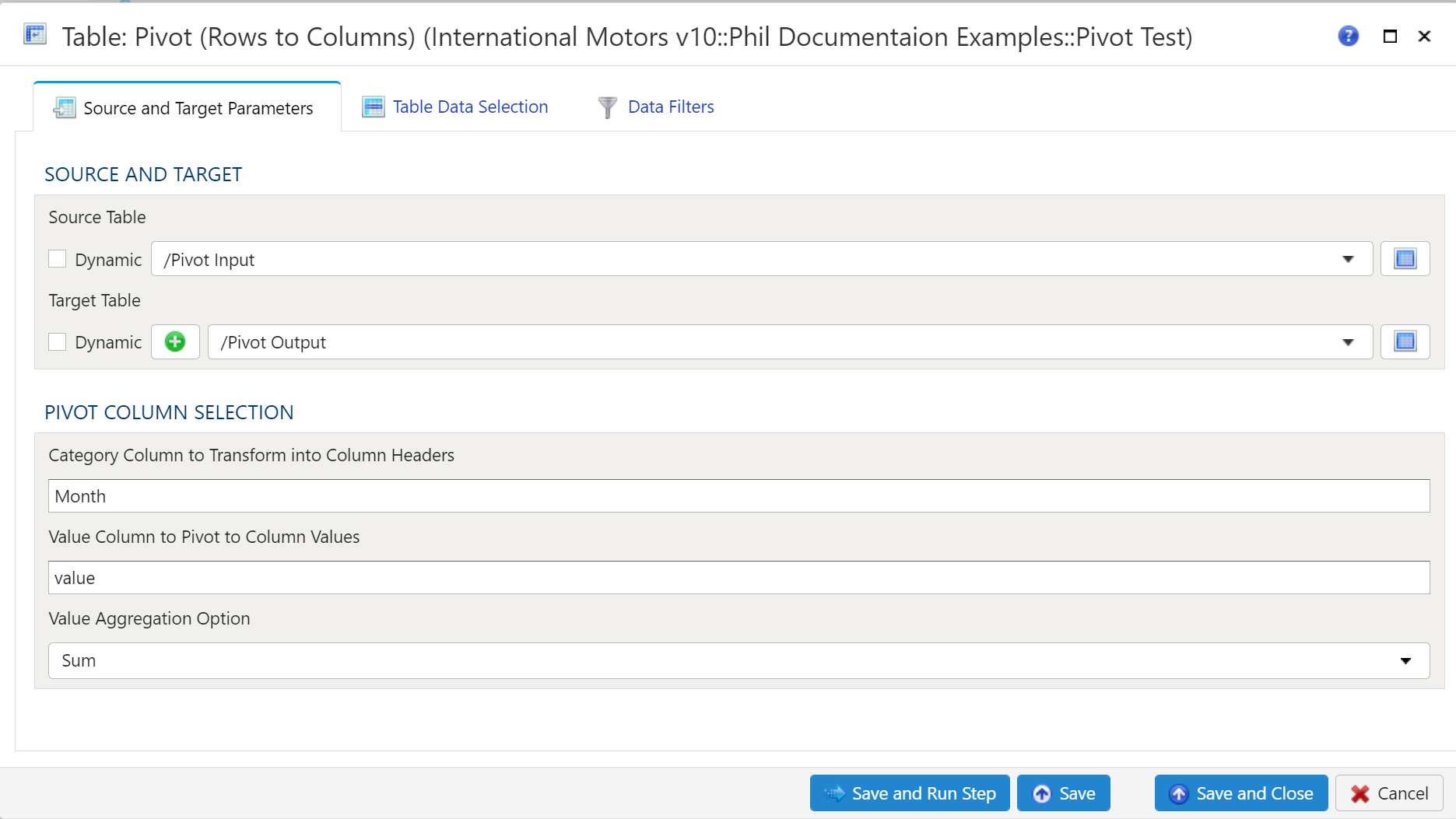
Source Table Selection
To establish the source and target, first select the data table to be extracted from using the dropdown menu.
Traget Table Selection
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Pivot Column Selection
The Category Column to Transform into Column Headers is where you specigy the column in Source Table that will be pivoted to rows. The Value Column ti Pivot to Column Vales is the column that containes the values in the Source Table. The Value Aggregation Option is where you specify how you want the data to aggregate.
Table Data Selection
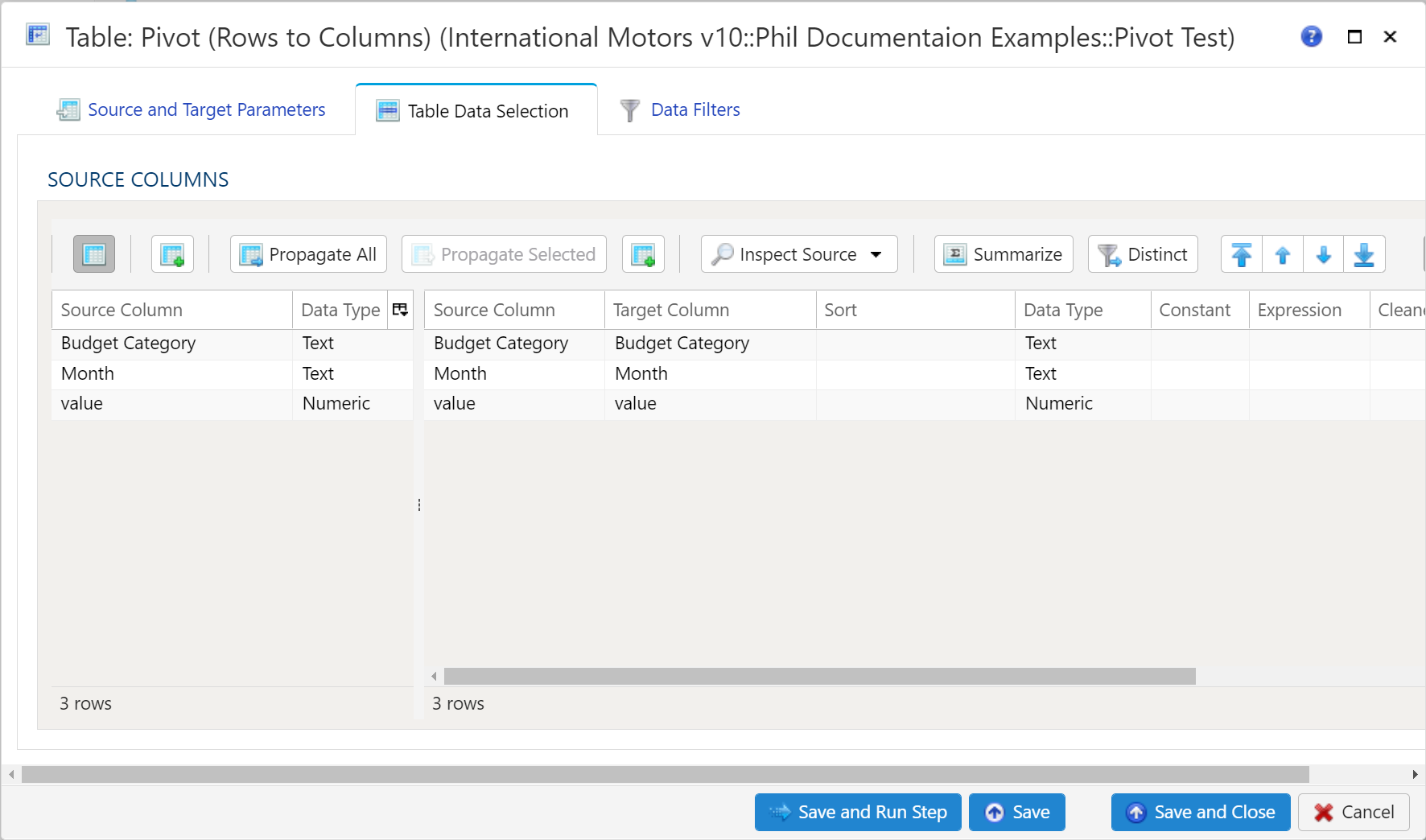
The Table Data Selection tab is used to map columns from the source data table to the target data table. All source columns on the left side of the window are automatically mapped to the target data table depicted on the right side of the window. Using the Inspect Source menu button, there are a few additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
In addition to each of these options, each choice offers the ability to preview the source data.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
To rearrange columns in the target data table, select the desired column(s), then right click and select Move to Top, Move Up, Move Down, or Move to Bottom.
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return distinct results only.
To aggregate results, select the Summarize menu option. This will toggle a set of drop down boxes for each column in the target data table. The following summarization options are available:
- Group by (set as default)
- Sum
- Min
- Max
- First
- Last
- Count
- Mean
- Median
- Mode
- Std Dev
- Variance
- Product
- Absolute Val
- Quantile
- Skew
- Kurtosis
- Mean Abs Dev
- Cumulative Sum
- Cumulative Min
- Cumulative Max
- Cumulative Product
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset of Data
Any valid Python expression is acceptable to subset the data. Please see Expressions
for more details and examples.
Apply Secondary Filter To Result Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples
Final Data Table Slicing (Limit)
To limit the data, simply check the Apply Row Slicer box and then specify the following:
- Initial Rows to Skip: Rows of data to skip (column header row is not included in count)
- End at Row: Last row of data to include. This is different from simply counting rows at the end to drop
4.16 - Table Union All
Description
Use to combine multiple data tables with the same column structure into a single data table. For example, time series data is a prime candidate for this transform. The result is all of the records from the combined tables.
Sources
The Sources section serves as a collection of all data tables to append together. Typically, all of the data tables will have the same (or similar) column structure. There are two buttons available to add a data table to the list:
- Insert Row
- Append Row
Additionally, right-clicking in the Select Source to Edit window will display the same options. Right-clicking on a table already added will also display the Delete option.
To execute the transform properly, there will need to be one entry in the Sources section for every source data table to append together. These entries are listed in the order in which they will be appended. To adjust the order, right-clicking on a table will display the following options:
- Move Down (if applicable)
- Move To Bottom (if applicable)
- Move Up (if applicable)
- Move To Top (if applicable)
By default, each source is named New Table, but the modeler is encouraged to provide descriptive names by double-clicking the name and renaming accordingly.
Target Table
By default, the Target Table is left blank. Before naming, note that data tables must follow Linux naming conventions. As such, we recommend that names only consist of alphanumeric characters. Analyze will automatically scrub any invalid characters from the name. Additionally, it will limit the length to 256 characters, so be concise!
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Table Data Selection Tab
Source Table
Table Selection
There are two options for selecting the table or in the second option tables to:
The first option is to use the Specific Table dropdown to select the table.
The second is to use the Tables Matching Search option in which you specify the Search Path and Search Text to select the table or tables that match the search criteria. This option is very useful if you have a workflow that creates a series of commonly named tables that that have been saved appending the date.
Source Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
4.17 - Table Union Distinct
Description
Use to combine multiple data tables with the same column structure into a single data table. For example, time series data is a prime candidate for this transform. The result is always the distinct set of records after combining the data.
Sources
The Sources section serves as a collection of all data tables to append together. Typically, all of the data tables will have the same (or similar) column structure. There are two buttons available to add a data table to the list:
- Insert Row
- Append Row
Additionally, right-clicking in the Select Source to Edit window will display the same options. Right-clicking on a table already added will also display the Delete option.
To execute the transform properly, there will need to be one entry in the Sources section for every source data table to append together. These entries are listed in the order in which they will be appended. To adjust the order, right-clicking on a table will display the following options:
- Move Down (if applicable)
- Move To Bottom (if applicable)
- Move Up (if applicable)
- Move To Top (if applicable)
By default, each source is named New Table, but the modeler is encouraged to provide descriptive names by double-clicking the name and renaming accordingly.
Target Table
By default, the Target Table is left blank. Before naming, note that data tables must follow Linux naming conventions. As such, we recommend that names only consist of alphanumeric characters. Analyze will automatically scrub any invalid characters from the name. Additionally, it will limit the length to 256 characters, so be concise!
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Table Data Selection Tab
Source Table
Table Selection
There are two options for selecting the table or in the second option tables to:
The first option is to use the Specific Table dropdown to select the table.
The second is to use the Tables Matching Search option in which you specify the Search Path and Search Text to select the table or tables that match the search criteria. This option is very useful if you have a workflow that creates a series of commonly named tables that that have been saved appending the date.
Source Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
4.18 - Table Upsert
Description
Performs an update of existing records and append new ones.
Upsert Parameters
To establish the source and target tables, first select the data table to be extracted from using the Source Table dropdown menu. Next, select an existing table as the target table using the Target Table dropdown.
Source Table Data Selection
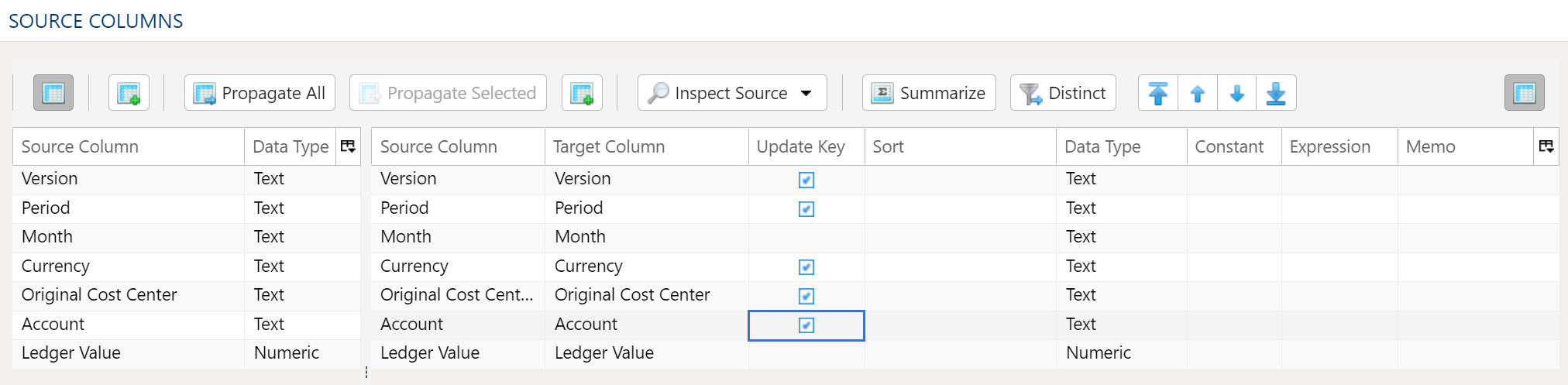
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Update Key
In order for the Upsert to update the existing and append new records you need to select the columns in the data that create a unique key.
Source Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
5 - Dimension Steps
5.1 - Dimension Clear
Description
Clears the contents of a dimension including structure, values, aliases, properties, and alternate hierarchies

Dimension Selection
Specify Dimension Dynamically
If dimensions or paths were created dynamically then same variables can be used to clear them. Using variables in the clear process is useful since it eliminates the need to update the Dimension Clear step manually on a periodic basis.
An example that uses the current_month variable to dynamically clear the Materials dimension:
/Dimensions/{current_month}/Products/Materials
Use Specific Dimension
Use the dropdown menu to select a specific dimension to clear.
5.2 - Dimension Create
Description
Creates a dimension for use and loading
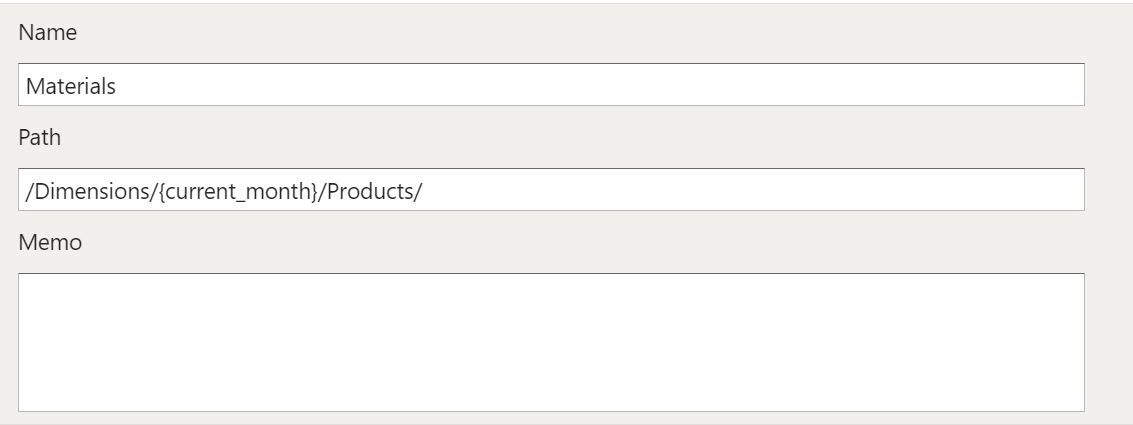
Dimension To Create
Name
You can either use a specific name for the dimension to be created or include variables for dynamic naming.
Variables are useful when dimensions are updated on a periodic basis and retaining the historical view is desired.
An example that uses the current_month variable to dynamically name the dimension:
dimension_name_{current_month}
Path
Paths let you create folder structures that the dimensions are are stored in. You can use variables here as well to make the folder structure dynamic.
An example that uses the current_month variable to dynamically name a folder:
/Dimensions/{current_month}/Product/
Memo
The Memo field is used a place to store comments or notes.
5.3 - Dimension Delete
Description
Deletes a dimension along with all associated structure, values, properties, aliases, and alternate hierarchies
Dimension Selection
Specify Dimension Dynamically
If dimensions or paths were created dynamically then same variables can be used to delete them. Using variables in the delete process is useful since it eliminates the need to update the Dimension Delete step manually on a periodic basis.
An example that uses the current_month variable to dynamically delete the Materials dimension:
/Dimensions/{current_month}/Products/Materials
Use Specific Dimension
Use the dropdown menu to select a specific dimension to delete.
5.4 - Dimension Export
Description
Export dimensions by flattening the data into a PlaidCloud table.
Documentation coming soon...
5.5 - Dimension Load
Description
Load and update dimensions using data from PlaidCloud tables.
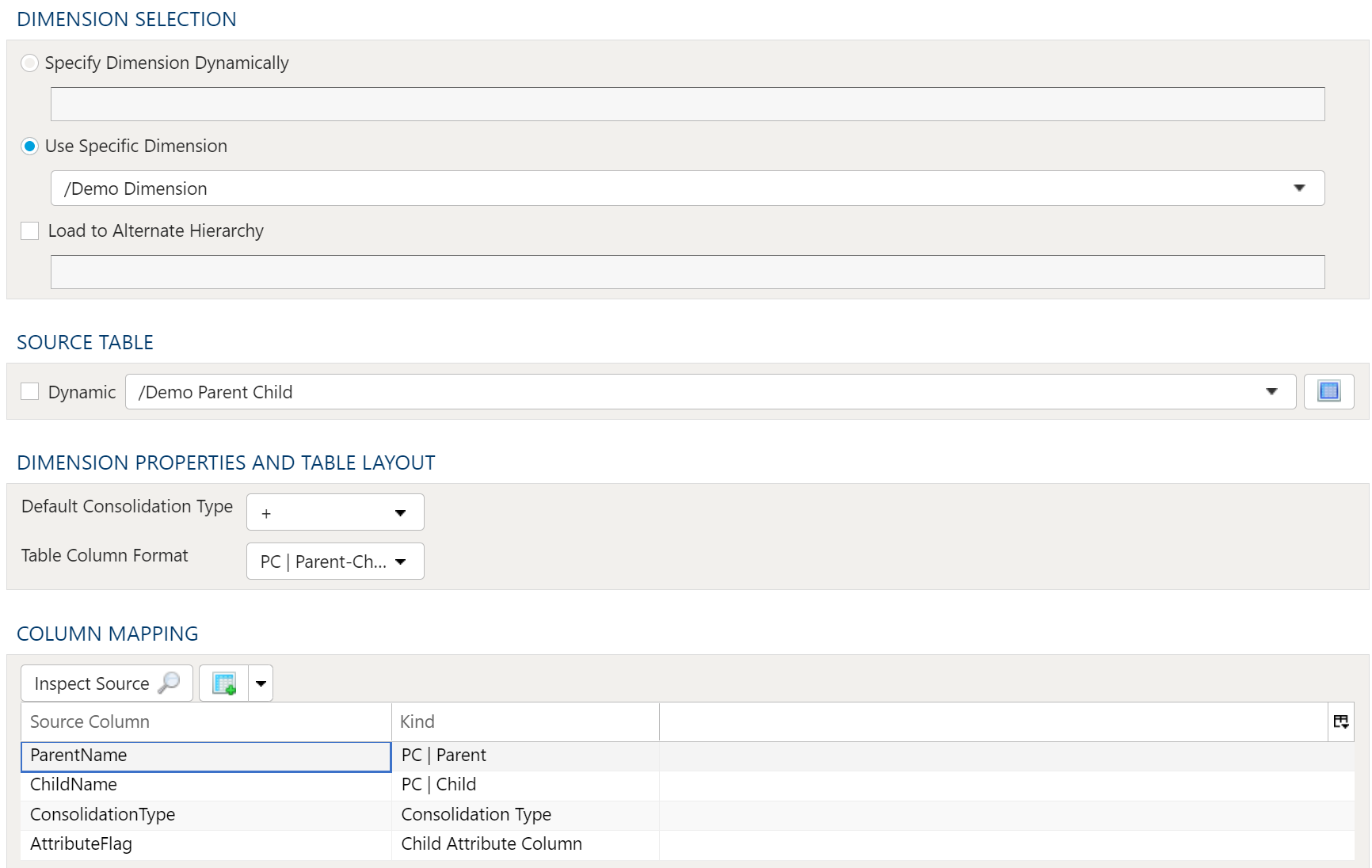
Dimension Selection
Specify Dimension Dynamically
To specify a dimension dynamically you include project and or local variables in the name.
Variables are useful when dimensions are updated on a periodic basis and retaining the historical view is desired.
An example that uses the current_month variable to dynamically load the dimension:
dimension_name_{current_month}
Use Specific Dimension
To use a specific dimension select the dimension using the drop down menu.
Load to Alternate Hierarchy
To load an Alternate Hierarchy fist select the dimension either dynamically or specifically, click the Load to Alternate Hierarchy checkbox and enter the name of the alternate hierarchy to be loaded.
Source Table
Dynamic
To specify the source table dynamically click the Dynamic Checkbox and enter the table name including the project and or local variables in the name.
Static
To use a specific source table select the table using the drop down menu.
Dimension Properties And Table Layout
Default Consolidation Type
There are three options for consolidation types:
- "+": Aggregates values in the dimension.
- "-": Subtracts values in the dimension.
- "~": No aggregation is performed in the dimension.
Table Column Format
There are two options for fomatting the Source Table when loading a dimension.
Parent Child
In a Parent Child table there are two columns that represent the dimensions structure, Parent and Child.
EXAMPLE PARENT CHILD
| PARENT | CHILD | Consolidation Type |
|---|---|---|
| Parent All | Parent 1 | ~ |
| Parnet All | Parent 2 | ~ |
| Parent 1 | Child 1 | + |
| Parent 2 | Child 2 | + |
| Child 1 | Child 3 | + |
| Child 1 | Child 4 | + |
| Child 2 | Child 5 | + |
Flattened Levels
In a Flattend Level table there are an infinte number of columns with each column representing a level of the dimension.
EXAMPLE FLATTENED LEVELS
| Level 1 | Level 2 | Level 3 | Level 4 |
|---|---|---|---|
| Parent All | Parent 1 | Child 1 | Child 3 |
| Parent All | Parent 1 | Child 1 | Child 4 |
| Parent All | Parent 2 | Child 2 | Child 5 |
Column Mapping
Using the Inspect Source menu button populates the Source Column in the data mapper. Once the Source Column has been populated use the Kind drop down menu to map the Source Columns to the appropriate column type.
5.6 - Dimension Sort
Description
Sort dimensions automatically.
Dimension Selection
Specify Dimension Dynamically
If dimensions or paths were created dynamically then same variables can be used to sort them. Using variables in the sort process is useful since it eliminates the need to update the Dimension Sort step manually on a periodic basis.
An example that uses the current_month variable to dynamically sort the Materials dimension:
/Dimensions/{current_month}/Products/Materials
Use Specific Dimension
Use the dropdown menu to select a specific dimension to sort.
6 - Document Steps
6.1 - Compress PDF
Documentation coming soon...
6.2 - Concatenate Files
Documentation coming soon...
6.3 - Convert Document Encoding
Description
Concatenates files to form a single file.
Examples
Create a source input, select the input file and browse for the file within that location. Select the desired output location, and browse to selected the desired location for the file. Save and run.
6.4 - Convert Document Encoding to ASCII
Description
Updates file encoding and converts all characters to ASCII. This is particularly useful if the source of information has mixed encodings or other tools don’t support certain encodings.
Examples
Select the input file and browse for the file within that location. Select the desired output location, and browse to select the desired location for the file. Save and run.
6.5 - Convert Document Encoding to UTF-8
Description
Updates file encoding and converts all characters to UTF-8. This is particularly useful if the information source has mixed encodings or other tools don’t support certain encodings.
Examples
Select the input file and browse for the file within that location. Select the desired output location, and browse then select the desired location for the file. Save and run.
6.6 - Convert Document Encoding to UTF-16
Description
Updates file encoding and converts all characters to UTF-16. This is particularly useful if the information source has mixed encodings or other tools don’t support certain encodings.
Examples
Select the input file and browse for the file within that location. Select the desired output location, and browse then select the desired location for the file. Save and run.
6.7 - Convert Image to PDF
Documentation coming soon...
6.8 - Convert PDF or Image to JPEG
Documentation coming soon...
6.9 - Copy Document Directory
Description
Copy an entire directory within PlaidCloud Document.
Copy Directory
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the directory you’d like to copy.
Select Destination
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the destination for the copied directory.
If desired, the copied directory can be given a new name. To do so, simply check the Rename the Copied Folder to: box and type in a new name.
Examples
No examples yet...
6.10 - Copy Document File
Description
Copy a single file within PlaidCloud Document.
File To Copy
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the file you’d like to copy.
Select Destination
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the destination for the copied file.
By default, Analyze will not allow files to be overwritten. Instead, a numerical suffix will be added to each subsequent copy.
To overwrite the existing file, simply check the Allow Overwriting Existing File box.
To rename the file, check the Rename the copied file to box and type in a new name.
Examples
No examples yet...
6.11 - Create Document Directory
Description
Create a new directory within PlaidCloud Document.
Where to Create New Folder
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the parent directory.
New Folder Name
Type the name for the new directory.
Examples
No examples yet...
6.12 - Crop Image to Headshot
Documentation coming soon...
6.13 - Delete Document Directory
Description
Delete an existing directory from within PlaidCloud Document.
Folder to Delete
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the directory to delete.
Examples
No examples yet...
6.14 - Delete Document File
Description
Delete an existing file from within PlaidCloud Document.
File to Delete
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the file to delete.
Examples
No examples yet...
6.15 - Document Text Substitution
Description
Performs text substitution in the specified file.
Examples
No examples yet...
6.16 - Fix File Extension
Documentation coming soon...
6.17 - Merge Multiple PDFs
Documentation coming soon...
6.18 - Rename Document Directory
Description
Rename an existing directory within PlaidCloud Document.
Folder to Rename
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the directory to be renamed.
Rename To
Type the new name for the directory.
Examples
No examples yet...
6.19 - Rename Document File
Description
Rename an existing file within PlaidCloud Document.
File to Rename
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the file to be renamed.
Rename To
Type the new name for the file.
Examples
No examples yet...
7 - Notification Steps
7.1 - Notify Distribution Group
Description
Send an email notification to a PlaidCloud distribution group. Messages are sent from info@tartansolutions.com. No outbound setup is required.
Select PlaidCloud Distribution List
Select a single distribution list from the drop down menu. Distribution lists can be created using Tools. For details on creating a distribution list, see here: PlaidCloud Tools – Distro.
Message
Specify Subject and Body as desired.
Please note that both Project Variables and Workflow Variables are available for use with this transform, in both the subject line and the message body.
Additionally, standard HTML code is permitted in the body to further customize the look of the email messages.
Examples
In this example, all of the system variables are used. Additionally, there is a small bit of HTML used to format the first line of the body. Executing this transform will send the following email to all members specified in the distribution group:
- FROM: info@tartansolutions.com (remember that all messages come from this address)
- Subject: DEMO Analyze Demo Running
7.2 - Notify Agent
Description
Notify a PlaidCloud Agent.
Examples
No examples yet...
7.3 - Notify Via Email
Description
Send email notifications. Messages are sent from info@tartansolutions.com email account. No outbound setup is required.
Email Addresses
Specify any number of email recipients. Acceptable delimiters include semicolon (;) and comma (,).
Message
Specify Subject and Body as desired.
Please note that both Project Variables and Workflow Variables are available for use with this transform, in both the subject line and the message body.
Additionally, standard HTML code is permitted in the body to further customize the look of the email messages.
Attachments
Attaching files to emails is very simple. Select a file or folder from Document to attach. If a folder is selected, the contents of the folder will be attached as individual files. Variable substitution works with paths for better control of file attachments when sending out personalized emails.
Examples
In this example, all of the system variables are used. Additionally, there is a small bit of HTML used to format the first line of the body. Executing this transform will send the following email:
- TO: info@tartansolutions.com
- FROM: info@tartansolutions.com (remember that all messages come from this address)
- Subject: DEMO – Workflow Analyze Demo Running
7.4 - Notify Via Log
Description
Write a message to the Analyze workflow log.
Message Parameters
Type the desired message to write to the log. Then select one of three severity levels from the following:
- Information
- Warning
- Error
Please note that both Project Variables and Workflow Variables are available for use with this transform.
Examples
In this example, executing this transform will append an Information item to the log, stating Write a message to the workflow log. I believe you have my stapler, Demo.
7.5 - Notify via Microsoft Teams
Adding Microsoft Teams notifications from a workflow is a two part process. The two parts are:
- Create a Microsoft Teams external connection
- Add Microsoft Teams notification steps to your workflows
Add Microsoft Teams Notification Step to Workflow
Adding Microsoft Teams notification steps to the workflow is the same as adding other steps to a workflow. Upon adding the step, open the step configuration, complete the form, and save it. You can now test your Microsoft Teams notification.
Formatting the Microsoft Teams Message
Teams has many formatting options including adding images and mentioning users. Please reference the Teams Message Text Formatting documentation for details.
Create Microsoft Teams External Connection
This is a one-time setup to allow PlaidCloud to send Microsoft Teams notifications on your behalf. Microsoft Teams allows creation of a Webhook App (a generic way to send a notification over the internet). After creating the Webhook App in Microsoft Teams, add the supplied credentials to PlaidCloud to allow its use.
Microsoft Teams Webhook App Creation
These steps will need to be performed by a Microsoft Teams administrator. Follow the steps outlined here for Creating Incoming Webhook (Microsoft Teams Documentation).
PlaidCloud External Connection Setup
These steps will need to be performed by a PlaidCloud workspace administrator with permissions to create External Data Connections. Follow these steps to create the connection:
- Navigate to
Analyze > Tools > External Data Connections - Under the
+ New Connectionselection, pick Microsoft Teams Webhook - Complete the name, description, and paste in the webhook url generated during the webhook creation above. The name provided here will be shown as the selection in the workflow step so it should be descriptive if possible.
- Select the
+ Createbutton
Examples
No examples yet...
7.6 - Notify via Slack
Adding Slack notifications from a workflow is a two part process. The two parts are:
- Create a Slack Webhook external connection
- Add Slack notification steps to your workflows
Add Slack Notification Step to Workflow
Adding Slack notification steps to the workflow is the same as adding other steps to a workflow. Upon adding the step, open the step configuration, complete the form, and save it. You can now test your Slack notification.
Formatting the Slack Message
Slack has many formatting options including adding images and mentioning users. Please reference the Slack Text Formatting documentation for details.
Create Slack Webhook External Connection
This is a one-time setup to allow PlaidCloud to send Slack notifications on your behalf. Slack allows creation of a Webhook App (a generic way to send a notification over the internet). After creating the Webhook App in Slack, add the supplied credentials to PlaidCloud to allow its use.
Slack Webhook App Creation
These steps will need to be performed by a Slack administrator. Follow these steps to create a Slack Webhook App:
- From Slack, open the workspace control menu and select
Settings & administration > Manage Apps - Select
Custom Integrationsfrom the Apps category list - Select
Incoming Webhooksfrom the list of apps - Select the
Add to Slackbutton - On the next screen, select the Slack Channel you wish to post the messages and continue. This is the default channel that will be used but it can be overridden in each notification including sending DMs to specific individuals.
- Copy the webhook URL displayed. This will be used later so keep it in a safe place. It will look something like this:
https://hooks.slack.com/services/T04QZ1435/G02TGBFTOP8/K9GZrR2ThdJz1uSiL9YeZxoR - You can customize the appearance, name, and emoji before saving. These customizations are only the defaults and these can be overridden on each notification step within a PlaidCloud workflow.
PlaidCloud External Connection Setup
These steps will need to be performed by a PlaidCloud workspace administrator with permissions to create External Data Connections. Follow these steps to create the connection:
- Navigate to
Analyze > Tools > External Data Connections - Under the
+ New Connectionselection, pick Slack Webhook - Complete the name, description, and paste in the webhook url provided in step 6 above. The name provided here will be shown as the selection in the workflow step so it should be descriptive if possible.
- Select the
+ Createbutton
Examples
No examples yet...
7.7 - Notify Via SMS
Description
Send an SMS message. Messages are sent from info@tartansolutions.com email account. No outbound setup or data is required.
Carrier and Number
From the Mobile Provider dropdown list, select from hundreds of domestic and international providers. For the convenience of the majority of our customers, USA carriers are listed first, followed by all international options listed alphabetically.
Next, specify a valid phone number. Acceptable formats include the following:
- 5555555555
- 555.555-5555
- 555.555.5555
- 555-555-5555
Message
Specify Subject and Message as desired.
Please note that both Project Variables and Workflow Variables are available for use with this transform, in both the subject line as well as the message body.WARNING: Standard data rates may apply for recipients.
Examples
No examples yet...
7.8 - Notify Via Twitter
Description
Send a Twitter Direct Message (DM) from @plaidcloud.
Twitter Account
Specify the twitter account to receive the DM from @plaidcloud. This user must be following @plaidcloud to receive the message. It is allowable, although not required, to prefix the username with the at sign (@).
Message
Enter the desired message. Analyze will not permit a value longer than 140 characters.
Please note that both Project Variables and Workflow Variables are available for use with this transform.
Examples
In this example, a DM is sent from @PlaidCloud to @tartansolutions. System variables are used in the message. The final message reads, Analyze Demo is running on #PlaidCloud.
7.9 - Notify Via Web Hook
Description
Send a notification via Web Hook (URL).
Examples
No examples yet...
8 - Agent Steps
8.1 - Agent Remote Execution of SQL
Description
Execute specified SQL on a remote database through a PlaidLink Agent connection.
8.2 - Agent Remote Export of SQL Result
Description
Execute specified SQL on a remote database through a PlaidLink Agent connection and export the result for use by PlaidCloud or other downstream systems.
Examples
No examples yet...
8.3 - Agent Remote Import Table into SQL Database
Description
Imports specified data into SQL database on a remote system through a PlaidLink Agent connection.
Examples
No examples yet...
8.4 - Document - Remote Delete File
Description
Deletes a remote file system file using a PlaidLink agent installed within the firewall.
Examples
First, make a selection from the “Agent to Use” dropdown. Next, enter the file or folder path under “File or Folder Path for Delete”. Finally, select “Save and Run Step”.
8.5 - Document - Remote Export File
Description
Exports a file to a remote file system using a PlaidLink agent installed within the firewall.
Examples
First, make a selection from the “Agent to Use” dropdown. Next, browse for the file or folder path under “File or Folder to Export”. Then enter the location under “Export Path Destination”. Finally, select “Save and Run Step”.
8.6 - Document - Remote Import File
Description
Imports a remote file system file using a PlaidLink agent installed within the firewall.
Examples
First, make a selection from the “Agent to Use” dropdown. Next, enter the file or folder path under “File or Folder Path for Import”. Then enter the folder destination under “Folder Destination”. Select the file type from the dropdown. Finally, select “Save and Run Step”.
8.7 - Document - Remote Rename File
Description
Renames or moves a remote file system file using a PlaidLink agent installed within the firewall.
Examples
First, make a selection from the “Agent to Use” dropdown.
Next, enter “Source Path” and “Destination Path”.
Finally, select “Save and Run Step”.
9 - General Steps
9.1 - Pass
Description
The Pass Through transform does not do anything. Its purpose as a placeholder is useful during development or when in need of a separator to section off steps during complex workflows.
9.2 - Run Remote Python
Description
This transform will run a Python file using PlaidLink. The Python file is executed on the remote system.
A set of global variables can be passed from the script execution on the remote system.
Examples
No examples yet...
9.3 - User Defined Transform
Description
The Standard Workflow Transforms that come with PlaidCloud can typically perform nearly every operation you’ll need. Additionally, these Standard Transforms are continuously optimized for performance, and they provide the most robust data. However, when the standard options, used singularly or in groups, are not able to achieve your goals, you can create User Defined Transforms to meet your needs. Standard Python code is permitted.
Coding with Python is required to create a User Defined Transform. For additional information, please visit the Python website.
User Defined Transforms
To create a new User Defined Function (UDF), open the workflow which needs the custom transform, select the User Defined tab, and click the Add User Defined Function button. Specify an ID for the UDF. Once created, select the Edit function logic icon (far left) to open the “Edit User Defined Function” window.
Alternatively, a previously created User Defined function can be imported using the Import button from within the User Defined tab. Simply press that button and then select the appropriate workflow from the dropdown menu (this menu contains all workflows within the current workspace). Next, select the function(s) to be imported and press the Import Selected Functions button.
Once the function has been created/imported, proceed to the Analyze Steps tab of the workflow and add a User Defined Transform step in the appropriate position, just as you would add a Standard Transform. In the config window, select the appropriate User Defined Function from the dropdown menu.
9.4 - Wait
Description
The Wait transform is used to pause processing for a specified duration. This can be especially helpful when waiting for I/O operations from other systems or for debugging workflows during development.
Duration Parameters
Specify a non-negative integer value using the Duration spinner.
Next, specify the unit of time from the dropdown menu. The following units are available for selection:
- Seconds
- Minutes
- Hours
10 - PDF Reporting Steps
10.1 - Report Single
Description
Generates a PDF report based on the defined RML template and input data sources for the report.
Examples
No examples yet...
10.2 - Reports Batch
Description
Generates many PDF reports based on the defined RML template and input data sources for each report.
Examples
No examples yet...
11 - Common Step Operations
11.1 - Advanced Data Mapper Usage
Review
Before jumping into the advanced usage capabilities of the Data Mapper, a brief review of the basic functionality will help.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
Advanced Usage
Aggregation Options
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. The following summarization options are available:
| Function | Description |
|---|---|
| Group By | Groups results by the value |
| Count | Number of non-null observations in group |
| Count (including nulls) | Number of observations in group |
| Sum | Sum of values in group |
| Mean | Mean of values in group |
| Median | Median of values in group |
| Mode | Mode of values in group |
| Min | Minimum of values in group |
| Max | Maximum of values in group |
| First | First value of values in group using the sorted order |
| Last | Last value of values in group using the sorted order |
| Standard Deviation | Unbiased standard deviation in group |
| Sample Standard Deviation | Sample standard deviation in group |
| Population Standard Deviation | Population standard deviation in group |
| Variance | Unbiased variance in group |
| Sample Variance | Sample Variance in group |
| Population Variance | Population Variance in group |
| Advanced Non-Group-By | Special aggregation selection when using window functions |
Pick the appropriate summarization method for the column.
When using a Window Function, select Advanced Non-Group-By as the aggregation method. This special selection is required due to the aggregation inherent in the window function already.
Constants
Specifying a value in the Constant column will override the source column value, if specified, and populate the column with the constant value specified.
Cleaners
The Data Mapper provides a convenient point-and-click cleaner capability to apply conversions to the data within a column.
The cleaning operations include the following categories:
- Text Trimming
- Text Formatting
- Text Transformations
- Converting to and from NULL values
- Number Formatting
- Date Parsing
The result of the cleaner selections are converted into a consolidated expression which is viewable in the Expression information.
Expressions
Expressions in the Data Mapper are one of the most powerful and flexible concepts in PlaidCloud. They provide nearly unlimited flexibility while being exceptionally performant, even on extremely large data.
Expressions are written using Python SQLAlchemy syntax along with a few additional helper functions available in PlaidCloud. This allows PlaidCloud to expose the full set of capabilities of the underlying data warehouse (e.g. Greenplum, SAP HANA, Redshift, etc...) directly. In addition, there are many resources available publicly that provide quick references for use of SQLAlchemy operations. By using standard SQLAlchemy syntax, PlaidCloud avoids the common pitfall of creating yet another domain specific syntax.
The expression editor is opened by double-clicking on the expression cell for the column. Once open, the list of columns are shown on the left while an extensive library of functions are shown on the right.
While it is entirely possible to type the expression directly into the editor, it is normally easier to use the point-and-click function and column selection to get started. The library of functions include the following groups:
- Conditions
- Column Specific Conditions
- Conversions
- Dates
- Math
- Text
- Summarizations
- Window Function Operations
- Arrays
- JSON
- PostGIS (Geospatial)
- Trigonmetry
Once you have completed the expression, save the expression so it will be applied to the column.
View examples and expression functions in the Expressions area.
12 - Allocation By Assignment Dimension
Description
Allocate values based on an assignment dimesion and driver data table.
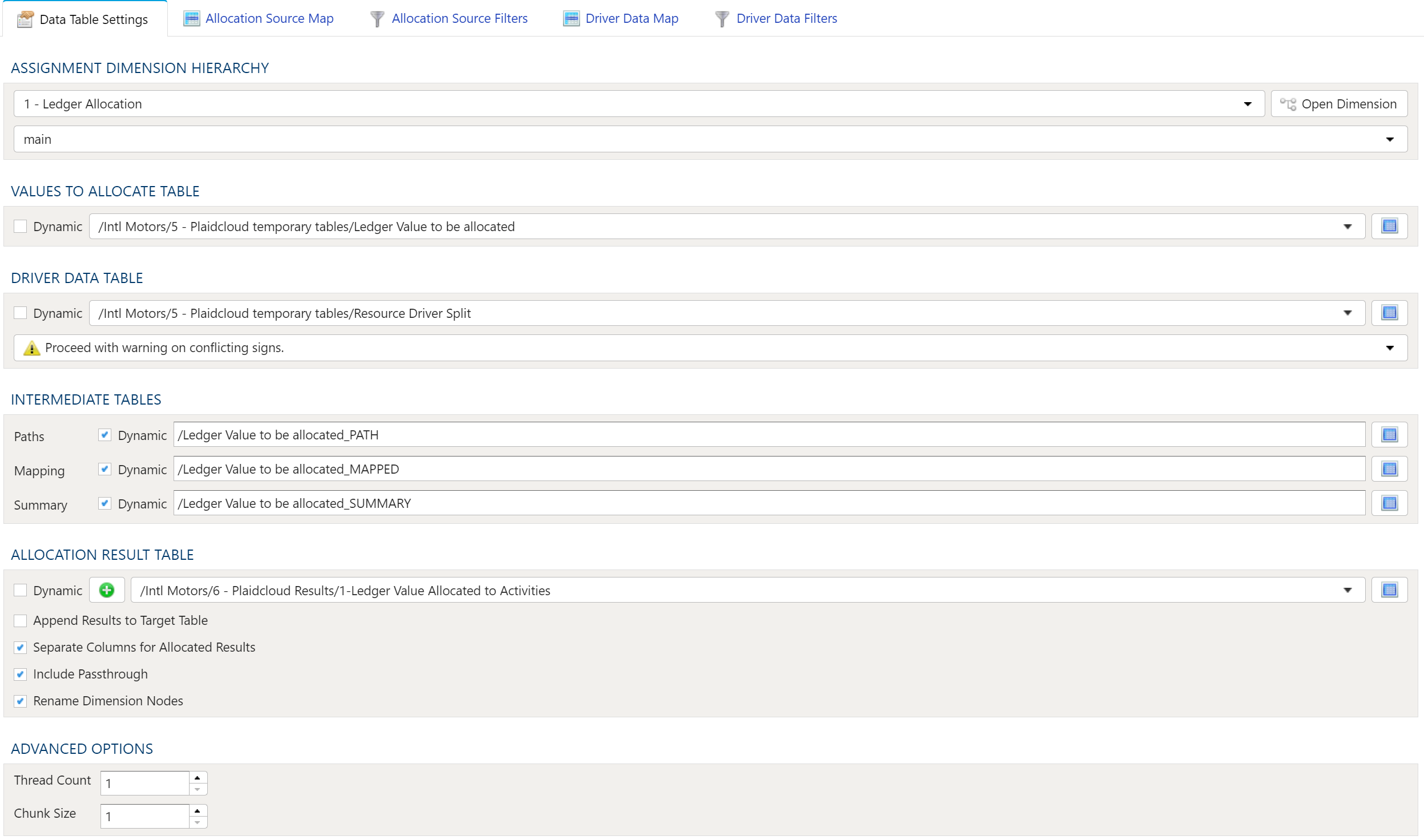
Data Table Settings
Assignment Dimesion Hierarchy
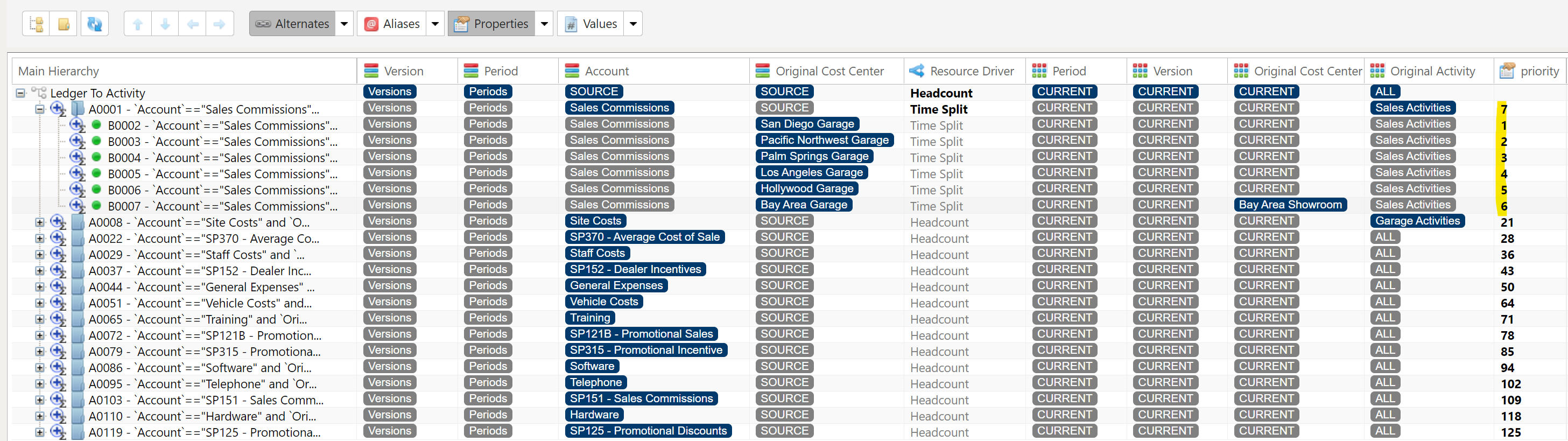
The Assignment Dimension Hierarchy gives the user the ability to point, click and filter either or both the Values To Allocate Table and Driver Data Table to create targeted allocations. The Assignment Dimension Hierarchy is created by combining dimensions that reference the Values To Allocate Table and the Driver Data Table.
Creating An Assignment Dimension Hierarchy
To create the Assignment Dimension Hierarchy you must first create the dimensions you wish to use to as filters for the Values To Allocate Table and the Driver Data Table. The links below will guide you through creating these dimensions.
Creating The Main Hierarchy
Once the dimensions for the Values To Allocate Table and the Driver Data Table have been created the next step is to decide which of the dimensions for the Values To Allocate Table will serve as the Main Hierarchy for the Assignment Dimension Hierarchy.
Copy this dimension by navigating to the Dimensions tab in PlaidCloud, clicking on the dimension and then selecting Actions and Copy Dimension. When you copy the dimension a pop-up will apprear asking you to enter a name for the copied dimension.
Adding Dimensions To The Assignment Hierarchy
Open the newley created Assignment Dimension, click on the down arrow next to Properties and select New Property.
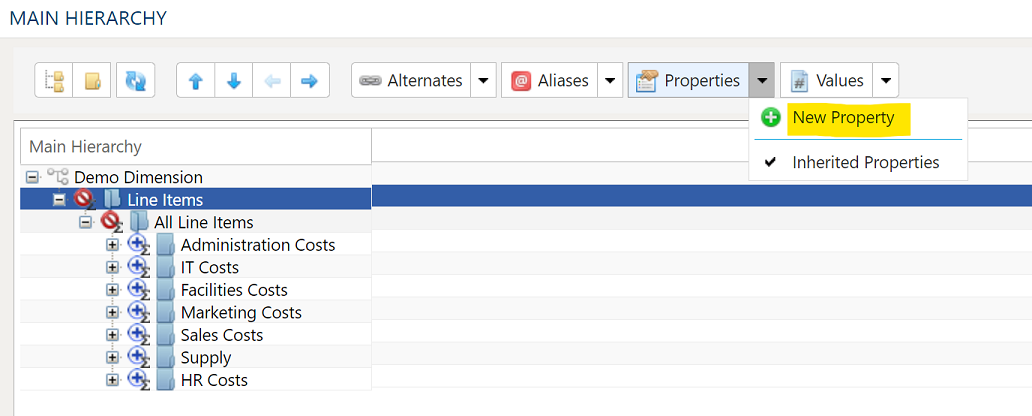
This will open the Property Configuration dialog box:
Property Configuration
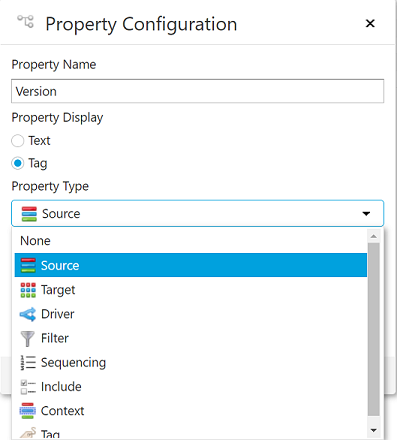
- Property Name - This is normally the name of the dimension that is being added to the Assignment Hierarchy.
- Property Display - This should be set to "Tag".
- Property Type - This property informs the allocation step which table Values To Allocate Table or the Driver Data Table this dimension is related too.
- Source - Is used in conjunction with the Values To Allocate Table.
- Target - Is used in conjunction with the Driver Data Table.
- Driver - Is used to filter Driver Data Table for the specific driver selected.
- Context - When the Values To Allocate Table and the Driver Data Table contain the same dimension then context can be used to specify how the dimensions should relate to one another. Context is often used when both the Values To Allocate Table and the Driver Data Table contain Profit / Cost Centers or Geography.
- Current - Acts as a passthrough and will filter the Driver Data Table based on the settings of the target dimension. An example would be if the Cotext is based on the Profit Center dimension and the Profit Center target dimension is set to ALL then the driver data would filter on all Profit Centers.
- Parent - When selected then the parent of the Profit Center in the Values To Allocate Table will be used to filter the driver values in the Driver Data Table. This is useful when driver values are, at times, not available for a specific Profit Center but often are at the parent level.
- All - When selected then the Profit Center in the Values To Allocate Table will not filter the driver values in the Driver Data Table, driver values for all Profit Centers will be used.Note: When Context is set to ALL or Parent it will override the setting on the target dimension.
- Editor Type - This drop down should be set to Select Dimension.
Once the appropriate properties have been selected for the dimension being added to the Assignment Hierarchy select "Edit Configuration".
Dimension Configuration
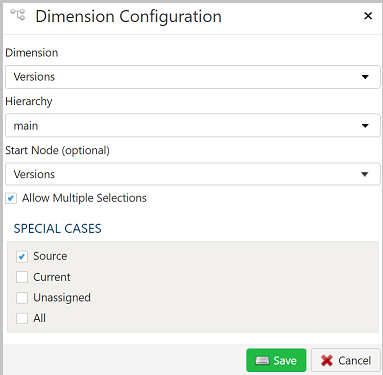
- Dimension - Use the drop down to select the dimension.
- Hierarchy - If the dimension selected has alternate hierarchies, then they will appear and be selectable here as well as the main hierarchy.
- Start Node - If you don't wish the dimension to be displayed from the top node you can select any node within the hierarchy as the node from which the dimension will be displayed.
- Allow Multiple Selections - If checked the user will be able to select multiple nodes in the hierarchy.
- Special Cases - When selected the special cases will be available for selection in the dimension drop down menu. They are typically used in Target dimensions.
- Source - When a dimension is set to Source the allocation will ignore this dimension when it filters the Driver Data Table but the allocated results will include values from the dimension.
- Current - Can be used when a dimension is shared between Source and Target. When the Target dimension is set to Current then the Driver Data Table will be filtered by the current value of the Source dimension as the allocation runs. An example would be if there are multiple periods in the Values To Allocate Table and the Driver Data Table but you want the allocation to allocate within the periods and not acrocss them. It is also common to use Current on Business Units, Cost Centers and Geographies.
- Unassigned - When a dimension is set to Unassigned the allocation will ignore this dimension when it filters the Driver Data Table and the allocation result for this dimension will be a Null value.
- All - When a dimension is set to ALL then the allocation will use all the values in the dimension.
The Values To Allocate Table, Driver Data Table and Allocation Result Table can be selected dynamically or statically.
Dynamic Table Selection
The dynamic table option allows specification of a table using text and variables. This is useful when employing variable driven workflows where the table or view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to a table:
legal_entity/inputs/{current_month}/ledger_values
Static Table Selection
When a specific table is desired as the source, leave the Dynamic box unchecked and select the source table using the dropdown menu.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Values To Allocate Table
This is the table that contains the values that are to be allocated. These are typically cost or revenue values.
Driver Data Table
The driver data table contains the values that the allocation step will use to allocate costs.
Examples:
- For a supply chain to assign costs to customers you might use delivery data with the number of deliveries or the weight of the deliveries as the driver.
- For an IT help desk to assign its costs to the departments it supports the driver data be the number of tickets by cost center.
Driver Data Sign Rule
Driver data can contain both positive and negative values. The Driver Data Sign Rule lets you decide how conflicting signs will be handled.
- Error on conficting signs - Allocation step will produce an error and stop if conflicting signs are encountered.
- Proceed with warning on conflicting signs - Allocation step will use both negative and positive driver values but will display a warning.
- Use only positive driver values - Allocation step will only use positive driver values, will ignore negative values.
- Use only negative driver values - Allocation step will only use negative driver values, will ignore positive values.
- Use absolute values of driver data - Allocation step will use the absolute values of the driver data.
Intermediate Tables
The Intermediate Tables are created each time an allocation step runs and provides a summary of the allocation processing. The Intermediate Tables provide insight into how the alloation process is running an are used to trouble shoot unexpected results.
- Paths - Shows the number of unique allocation paths summarized from the assignment hierarchy.
- Mapping - Shows how each line of the Values To Allocate Table are mapped to the allocation targets.
- Summary - Shows each rule, as a result of the assignment hierachy, and how many of the records from the Values To Allocate Table match it.
Allocation Result Table
Append Results to Target Table
If this box is checked the allocation results will be appended to the allocation result table. If this box is not checked the allocation results table will be overwritten each time the allocation step runs.
Separate Columns for Allocated Results
If this box is checked then the results table will show the amount of each allocated record as well as the amount actually allocated to each driver record.
Rename Dimension Nodes
If this box is checked when the allocation step runs it will rename the dimension node in the Assignment dimension.
Advanced Options
Thread Count
Sets the number of concurrent operations the allocation step will use.
Chunk Size
Set the number of allocation paths within a thread.
Allocation Source Map

The Allocation Source Map is used to map the columns from the Values To Allocate Table that will be used in the allocation step.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Role
Each column in the data mapper must be assigned a role:
- Pass Thought - These columns will appear in the allocation results table.
- Value to Allocate - This is the column that contains the values to be allocated.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Allocation Source Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Driver Data Map

The Allocation Driver Data Map is used to map the columns from the Driver Data Table that will be used in the allocation step.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Role
Each column in the data mapper must be assigned a role:
- Source Relation - These columns have corresponing columns in the Values To Allocate Table.
- Allocation Target - The columns will be the target of the allocation step and will appear in the Allocation Result Table.
- Split Value - This column contains the values that will be used to allocate the values in the Values To Allocate Table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Driver Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
Example 1
Values To Allocate Table
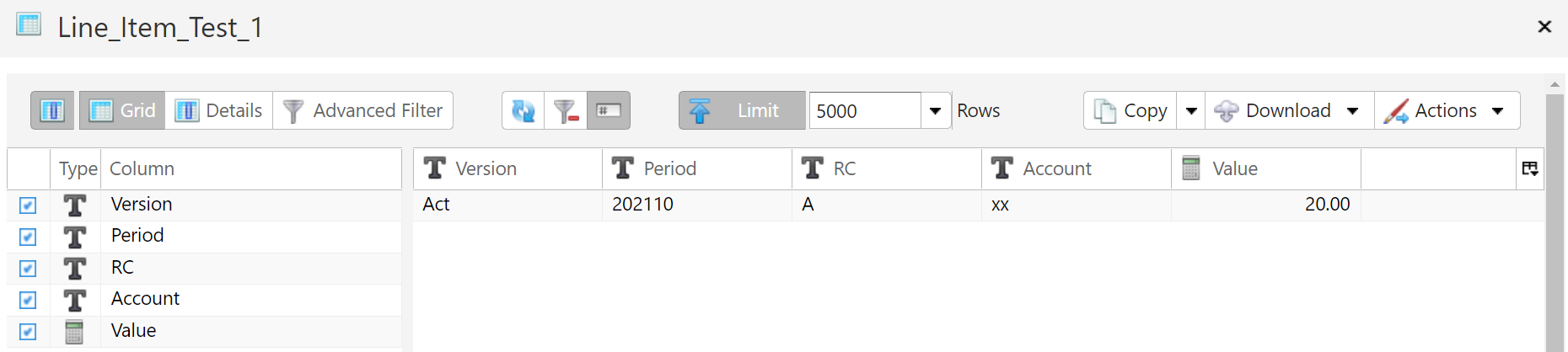
Driver Data Table
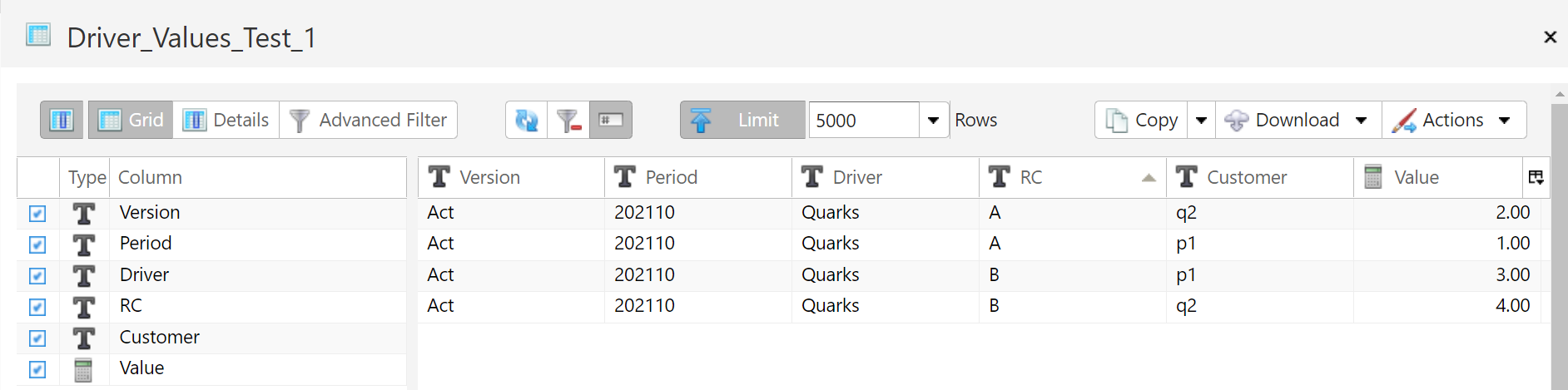
Assignment Dimension Hierarchy
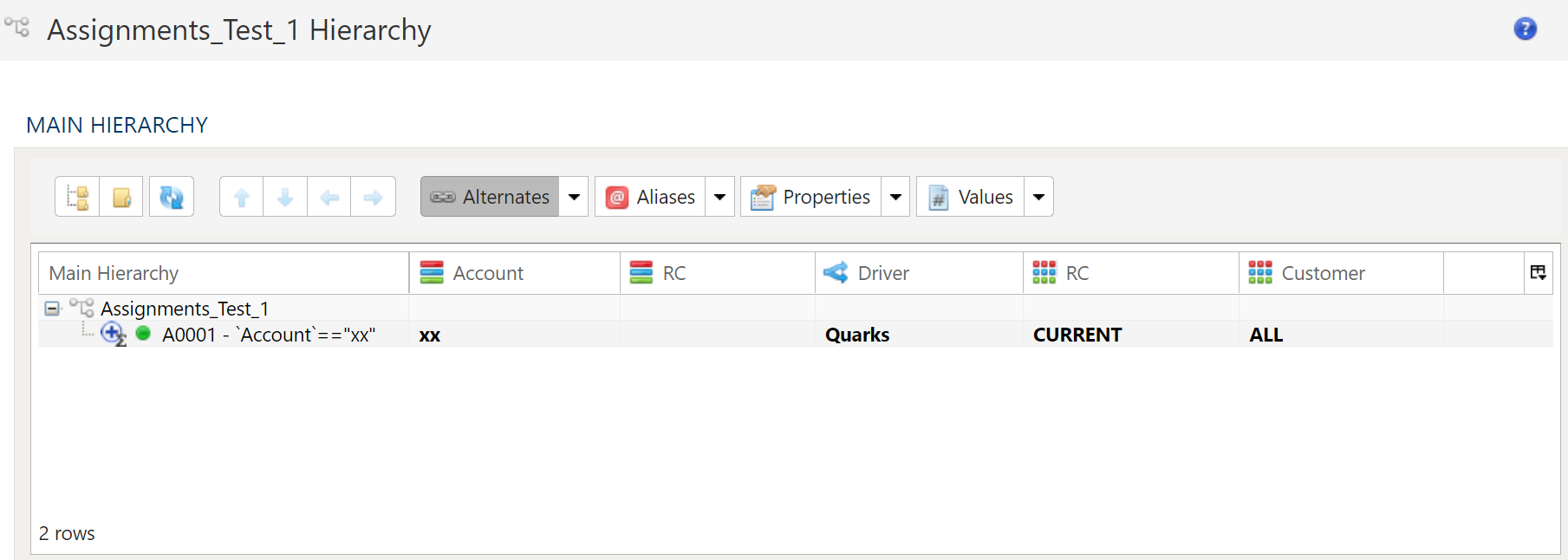
Since the Target RC dimension is set to Current the driver data will be filtered by the Source RC values in the Values To Allocation Table. Since the only value in the Source RC is "A", only the driver value records where RC = A will be used in the allocation step.
Allocation Results Table

Example 2
Values To Allocate Table
Driver Data Table
Assignment Dimension Hierarchy
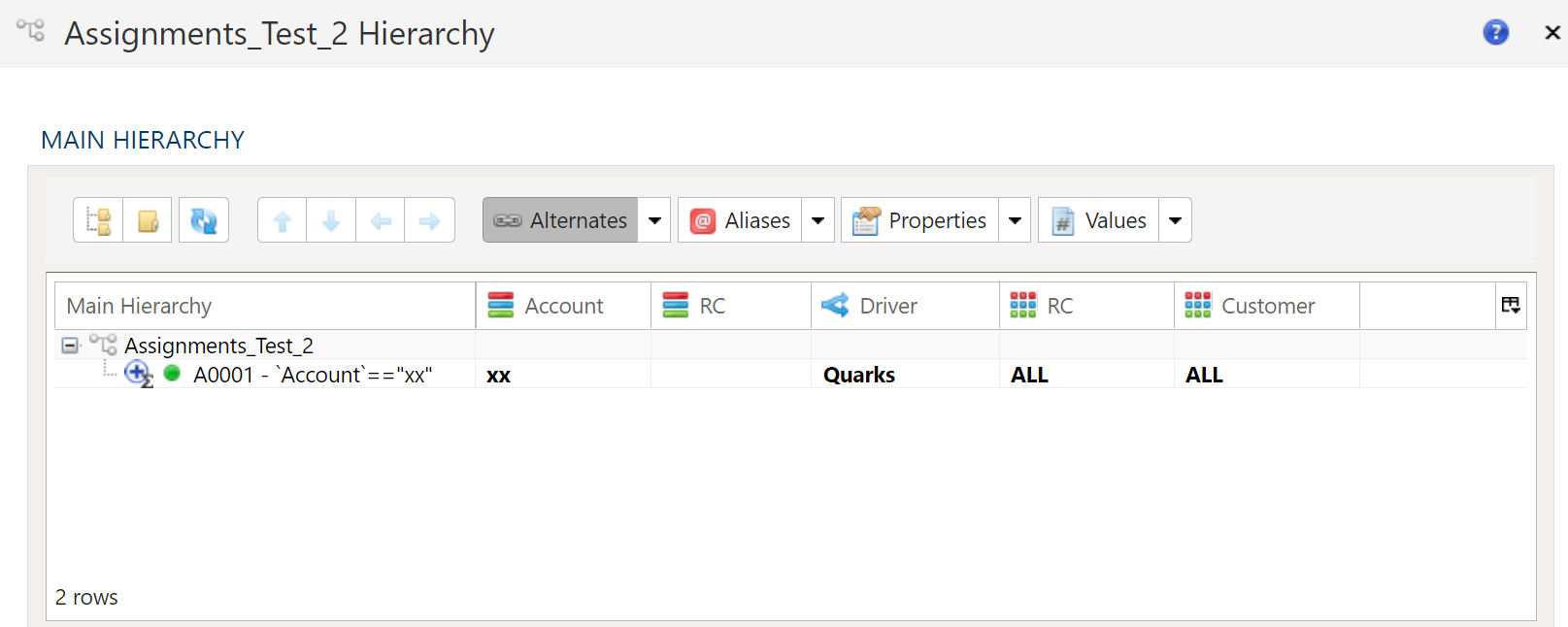
Since the Target RC dimension is set to ALL the driver data will include all RC values as you can see in the RC column in the Allocation Results Table.
Allocation Results Table

Example 3
Values To Allocate Table

Driver Data Table

Assignment Dimension Hierarchy

With the Context RC set to ALL and the Target RC set to Source the driver data will include all the RC in the driver data. The Contect RC will override the setting on the Target RC.
Allocation Results Table

Example 4
Values To Allocate Table
Driver Data Table
Assignment Dimension Hierarchy

With the Context RC set to ALL the driver data will include all the RC in the driver data.
Allocation Results Table

13 - Allocation Split
Description
Allocate values based on driver data.
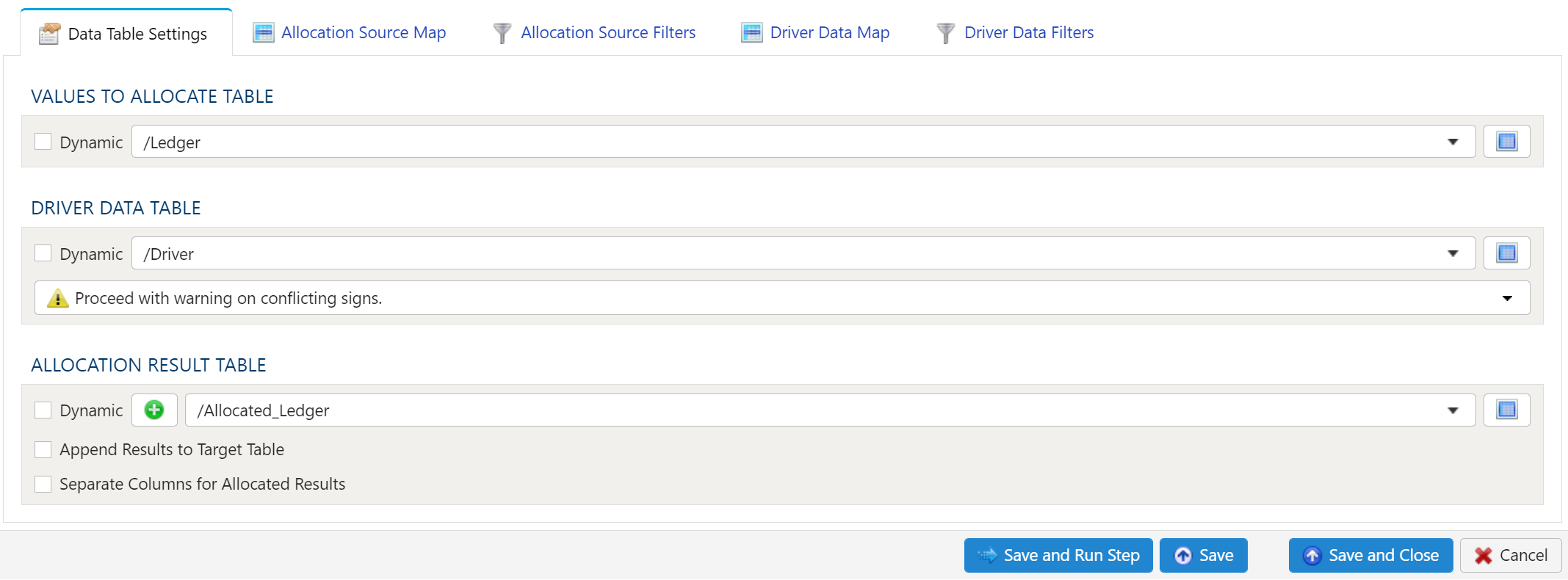
Data Table Settings
The Values To Allocate Table, Driver Data Table and Allocation Result Table can be selected dynamically or statically.
Dynamic Table Selection
The dynamic table option allows specification of a table using text and variables. This is useful when employing variable driven workflows where the table or view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to a table:
legal_entity/inputs/{current_month}/ledger_values
Static Table Selection
When a specific table is desired as the source, leave the Dynamic box unchecked and select the source table using the dropdown menu.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Values To Allocate Table
This is the table that contains the values that are to be allocated. These are typically cost or revenue values.
Driver Data Table
The driver data table contains the values that the allocation step will use to allocate costs.
Examples:
- For a supply chain to assign costs to customers you might use delivery data with the number of deliveries or the weight of the deliveries as the driver.
- For an IT help desk to assign its costs to the departments it supports the driver data be the number of tickets by cost center.
Driver Data Sign Rule
Driver data can contain both positive and negative values. The Driver Data Sign Rule lets you decide how conflicting signs will be handled.
- Error on conficting signs - Allocation step will produce an error and stop if conflicting signs are encountered.
- Proceed with warning on conflicting signs - Allocation step will use both negative and positive driver values but will display a warning.
- Use only positive driver values - Allocation step will only use positive driver values, will ignore negative values.
- Use only negative driver values - Allocation step will only use negative driver values, will ignore positive values.
- Use absolute values of driver data - Allocation step will use the absolute values of the driver data.
Allocation Result Table
Append Results to Target Table
If this box is checked the allocation results will be appended to the allocation result table. If this box is not checked the allocation results table will be overwritten each time the allocation step runs.
Separate Columns for Allocated Results
If this box is checked then the results table will show the amount of each allocated record as well as the amount actually allocated to each driver record.
Allocation Source Map
The Allocation Source Map is used to map the columns from the Values To Allocate Table that will be used in the allocation step.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Role
Each column in the data mapper must be assigned a role:
- Pass Thought - These columns will appear in the allocation results table.
- Value to Allocate - This is the column that contains the values to be allocated.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Allocation Source Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Driver Data Map
The Allocation Driver Data Map is used to map the columns from the Driver Data Table that will be used in the allocation step.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Role
Each column in the data mapper must be assigned a role:
- Source Relation - These columns have corresponing columns in the Values To Allocate Table.
- Allocation Target - The columns will be the target of the allocation step and will appear in the Allocation Result Table.
- Split Value - This column contains the values that will be used to allocate the values in the Values To Allocate Table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Driver Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
14 - Rule-Based Tagging
Description
Rule Based Tagging is used to add attributes contained within a dimesion to a data table.
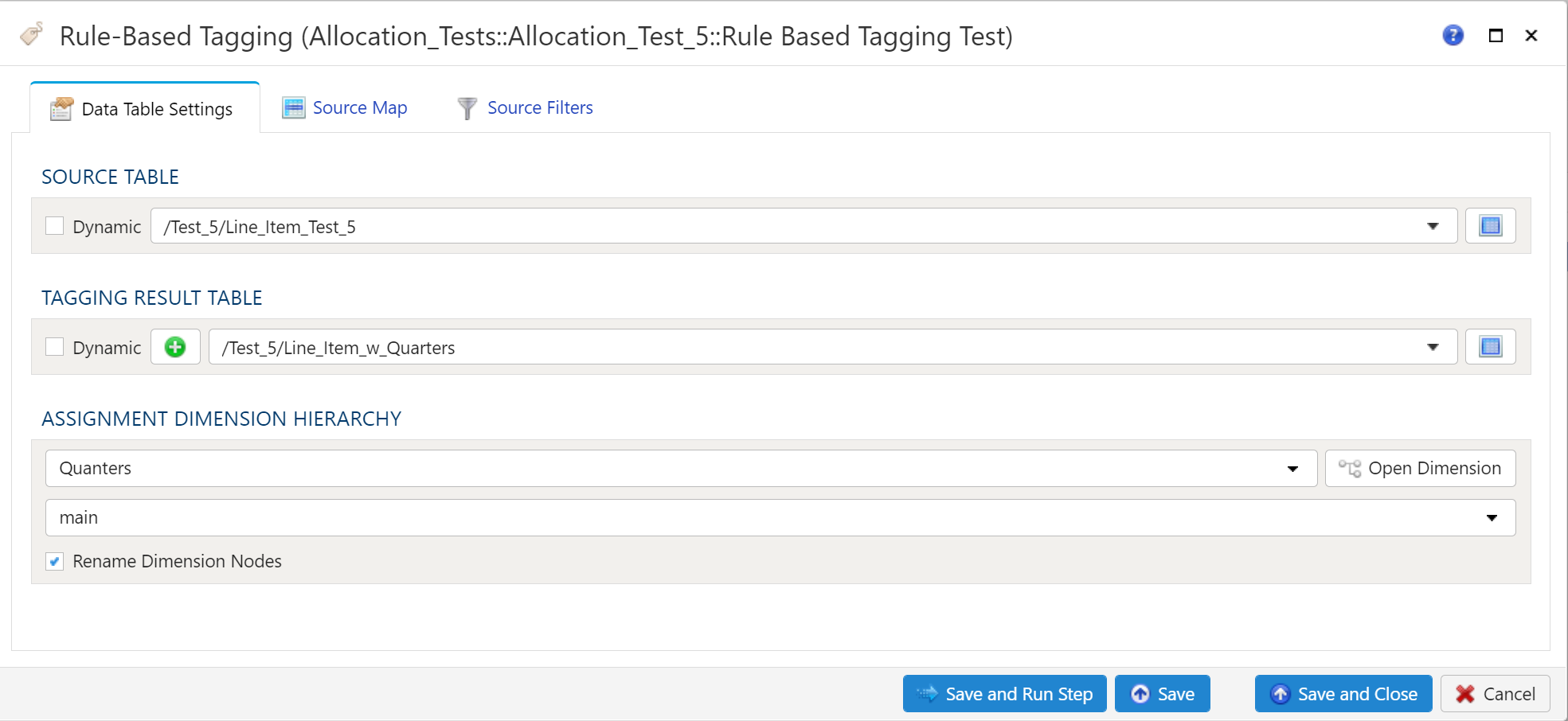
Data Table Settings
The Source Table and Tagging Result Table can be selected dynamically or statically.
Dynamic Table Selection
The dynamic table option allows specification of a table using text and variables. This is useful when employing variable driven workflows where the table or view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to a table:
legal_entity/inputs/{current_month}/ledger_values
Static Table Selection
When a specific table is desired as the source, leave the Dynamic box unchecked and select the source table using the dropdown menu.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Source Table
This is the table that contains the data that you wish to add the attributes from the Assignment Dimension to.
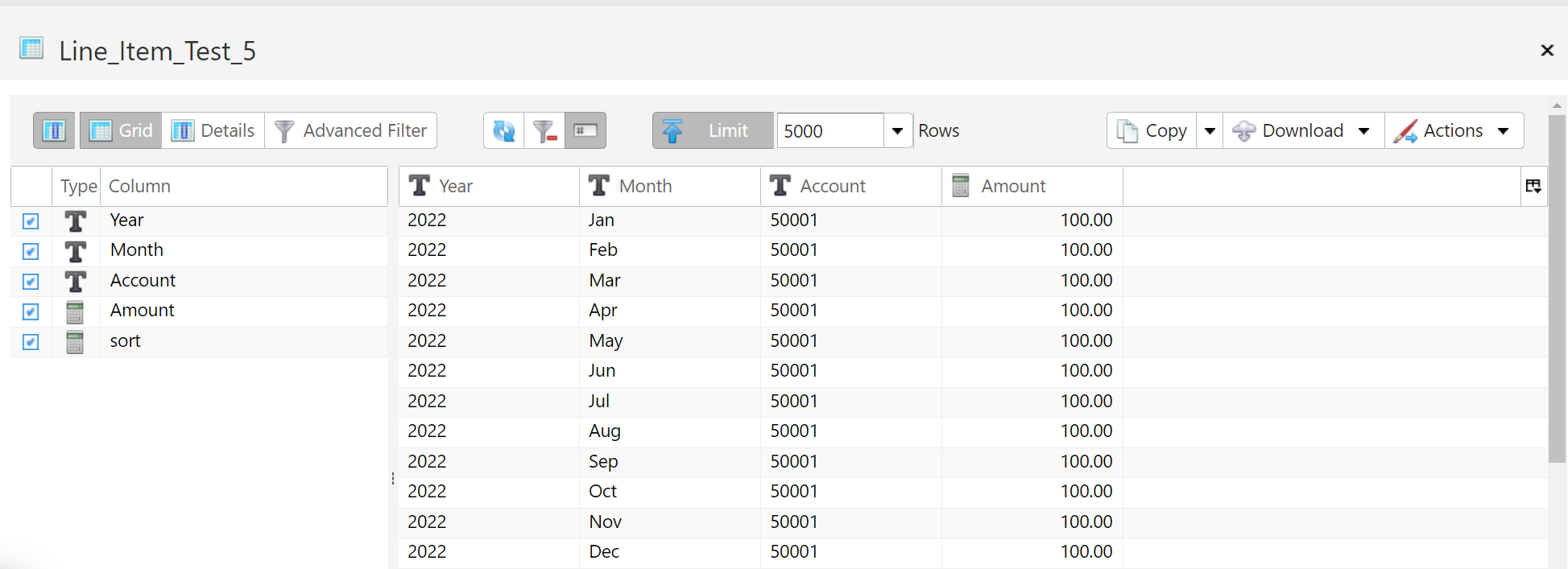
Tagging Result Table
The Tagging Result Table will contain the data from the Source Data Table with the attributes contained in the Assignment Dimension Hierarchy.
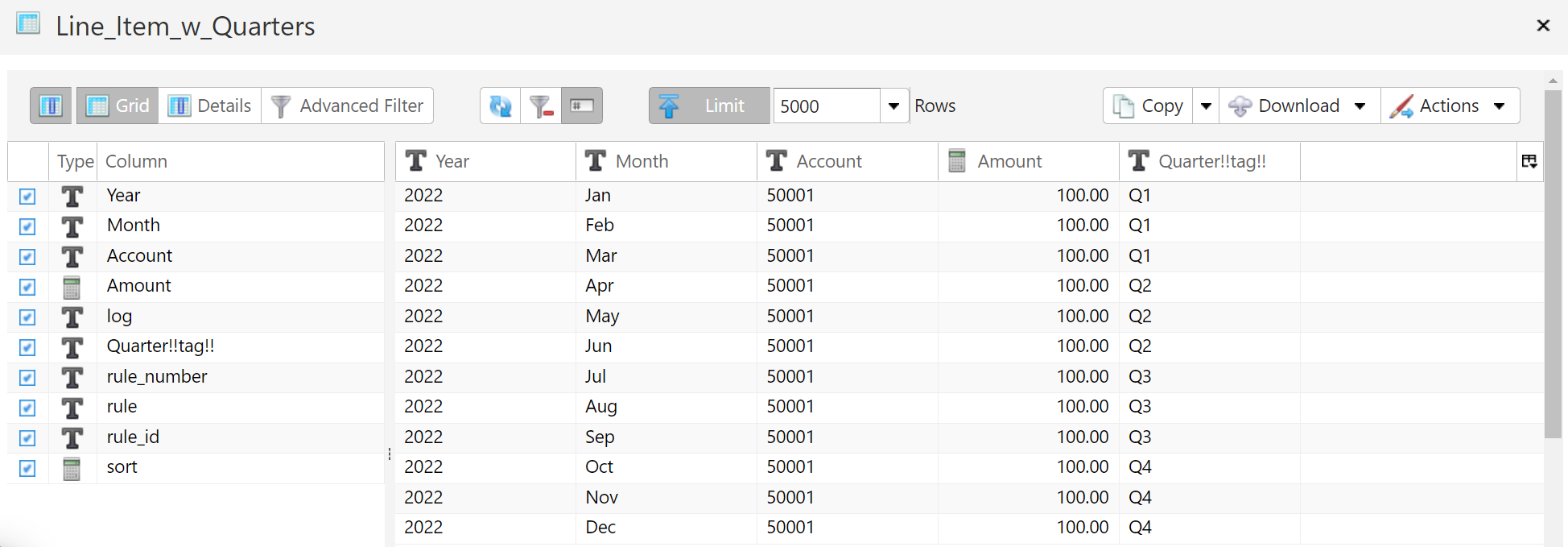
Assignment Dimesion Hierarchy
The Assignment Dimension Hierarchy gives the user the ability to point, click and filter the Source Table to add attributes to the Tagging Result Table. The Assignment Dimension Hierarchy is created by combining dimensions that reference the Source Table.
Creating An Assignment Dimension Hierarchy
To create the Assignment Dimension Hierarchy you must first create the dimensions you wish to use to as filters for the Source Table. The links below will guide you through creating these dimensions.
Creating The Main Hierarchy
Once the dimensions for the Source Table have been created the next step is to decide which of the dimensions for the Source Table will serve as the Main Hierarchy for the Assignment Dimension Hierarchy.
Copy this dimension by navigating to the Dimensions tab in PlaidCloud, clicking on the dimension and then selecting Actions and Copy Dimension. When you copy the dimension a pop-up will apprear asking you to enter a name for the copied dimension.
Adding Dimensions To The Assignment Hierarchy
Open the newley created Assignment Dimension, click on the down arrow next to Properties and select New Property.
This will open the Property Configuration dialog box:
Property Configuration
Property Name - This is normally the name of the dimension that is being added to the Assignment Hierarchy.
Property Display - This should be set to "Tag".
Property Type - For Rule Based Tagging property type should be set to Source.
- Source - Is used in conjunction with the Source Table.
Editor Type - This drop down should be set to Select Dimension.
Once the appropriate properties have been selected for the dimension being added to the Assignment Hierarchy select "Edit Configuration".
Dimension Configuration
- Dimension - Use the drop down to select the dimension.
- Hierarchy - If the dimension selected has alternate hierarchies, then they will appear and be selectable here as well as the main hierarchy.
- Start Node - If you don't wish the dimension to be displayed from the top node you can select any node within the hierarchy as the node from which the dimension will be displayed.
- Allow Multiple Selections - If checked the user will be able to select multiple nodes in the hierarchy.
- Special Cases - Are not used in Rule Based Tagging.
Source Map
The Allocation Source Map is used to map the columns from the Values To Allocate Table that will be used in the allocation step.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Role
Each column in the data mapper must be assigned a role:
- Pass Thought - These columns will appear in the allocation results table.
- Value to Allocate - This is the column that contains the values to be allocated.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Source Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
15 - SAP ECC and S/4HANA Steps
15.1 - Call SAP Financial Document Attachment
Description
Calls an SAP ECC Remote Function Call (RFC) designed to attach a file to specified FI document number.
Examples
RFC Parameters
Select Agent to Use. Select Target Directory from the drop down bar, and browse below for the correct child folder destination for the file. Next, appropriately name the “Target File Name”. Under “Function Call Information”, enter the Function, the Return Value Parameter, and select the parameters.
You can choose to Insert Row or Append Row under the Parameters section, as well as name the parameters and give them values. Choose the Max Concurrent Requests number, and select Wait for RFC to Complete. Save and Run Step.
15.2 - Call SAP General Ledger Posting
Description
Calls an SAP ECC Remote Function Call (RFC) designed to post a journal entry including applicable VAT and Withholding taxes. This may also run in test mode which will perform a posting process but not complete the posting. This allows for the collection of detectable errors such as an account being closed or a customer not existing in the specified company code specified. The error checking is robust with the ability to return multiple detected errors in a single test.
Examples
RFC Parameters
Select Agent to Use. Select Target Directory from the drop down bar, and browse below for the correct child folder destination for the file. Next, appropriately name the “Target File Name”. Under “Function Call Information”, enter the Function, the Return Value Parameter, and select the parameters.
You can choose to Insert Row or Append Row under the Parameters section, as well as name the parameters and give them values. Choose the Max Concurrent Requests number, and select Wait for RFC to Complete. Save and Run Step.
15.3 - Call SAP Master Data Table RFC
Description
Calls an SAP ECC Remote Function Call (RFC) designed to access master data tables and retrieves the data in tabular form. This data is then available for transformation processes in PlaidCloud. It also provides the ability to export the master data table structure to a separate file which includes column names, data types, and column order information.
Examples
RFC Parameters
Select Agent to Use. Select Target Directory from the drop down bar, and browse below for the correct child folder destination for the file. Next, appropriately name the “Target File Name”. Under “Function Call Information”, enter the Function, the Return Value Parameter, and select the parameters.
You can choose to Insert Row or Append Row under the Parameters section, as well as name the parameters and give them values. Choose the Max Concurrent Requests number, and select Wait for RFC to Complete. Save and Run Step.
15.4 - Call SAP RFC
Description
Calls an SAP ECC Remote Function Call (RFC) and retrieves the data in tabular form. This data is then available for transformation processes in PlaidCloud.
Examples
RFC Parameters
Select Agent to Use. Select Target Directory from the drop down bar, and browse below for the correct child folder destination for the file. Next, appropriately name the “Target File Name”. Under “Function Call Information”, enter the Function, the Return Value Parameter, and select the parameters.
You can choose to Insert Row or Append Row under the Parameters section, as well as name the parameters and give them values. Choose the Max Concurrent Requests number, and select Wait for RFC to Complete. Save and Run Step.
Advanced Value Iteration
You can select “No Iterators” at the top of this tab and then select Save and Run Step if desired, or you can specify.
Here, you can select “Specify Argument Values” to Iterate Over and create arguments to then go to the Iteration Value.
Next to Select Iterator Argument to Edit Values, there is the option to Insert Tow, Append Row, Delete Row, Move Down Row, or Move to Bottom Row. Below you can choose Range Iterators using the same drop down menu. The last section is titled “Exclusions for Selected Range Iteration” with the same options per row to add, delete, etc. The excluded values can be entered below. Save and Run Step.
16 - SAP PCM Steps
16.1 - Create SAP PCM Model
Description
Creates a blank SAP Profitability and Cost Management (PCM) model.
Our Credentials
Tartan Solutions is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown. Enter “Model Name” and select “Model type” from the dropdown (both of which are in the “Model Information” section). Check the “Wait for Copy to Complete” check box, then click “Save and Run Step”.
16.2 - Delete SAP PCM Model
Description
Deletes SAP Profitability and Cost Management (PCM) models matching the search criteria. Deleting models using this transform allows deletion of many models without having to monitor the process.
Our Credentials
Tartan Solutions is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select “Agent to Use” from the dropdown. Select your desired “Model Search Method”. For this example, we’ve selected “Exact Match”. Enter “Model Search Text” (what you are looking for) under “Model Name Information” and decide if the search is case sensitive or not (if so, check the check box). Finally, check the “Wait for Deletion to Complete” and click “Save and Run Step”.
16.3 - Calculate PCM Model
Description
Starts SAP Profitability and Cost Management (PCM) model calculation process.
Our Credentials
Tartan Solutions is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown, enter model name in the “Model Name” field, click the “Wait for Calculation to Complete” check box (if desired), then click “Save and Run Step”.
16.4 - Copy SAP PCM Model
Description
Copies an SAP Profitability and Cost Management (PCM) model.
Our Credentials
Tartan Solutions is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Example
Select Agent to Use from the dropdown, enter “From Model Name” and “To Model Name” in the “Model Information” field, click the “Wait for Copy to Complete” check box, then click “Save and Run Step”.
16.5 - Copy SAP PCM Period
Description
Copies an SAP Profitability and Cost Management (PCM) model period within the same model.
Our Credentials
Tartan Solutions is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown, enter “Model Name”, “From Period Name” and “To Period Name” in the “Model Information” field. Click the “Wait for Copy to Complete” check box, then click “Save and Run Step”.
16.6 - Copy SAP PCM Version
Description
Copies an SAP Profitability and Cost Management (PCM) model version within the same model.
Our Credentials
Tartan Solutions is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown, enter “Model Name”, “Origin Period Name”, and “Destination Period Name” in the “Model Information” field. Click the “Wait for Copy to Complete” check box, then click “Save and Run Step”.
16.7 - Rename SAP PCM Model
Description
Renames an SAP Profitability and Cost Management (PCM) model.
Our Credentials
Tartan Solutions is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown, enter “From Model Name” and “To Model Name” in the “Model Information” field, click the “Wait for Copy to Complete” check box, then click “Save and Run Step”.
16.8 - Run SAP PCM Console Job
Description
Launches an SAP Profitability and Cost Management (PCM) Console process on the PCM server.
Our Credentials
Tartan Solutions is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown, enter console file path in the “Console File Path” field, click the “Wait for Console Job to Complete” check box (if desired), then click “Save and Run Step”.
16.9 - Run SAP PCM Hyper Loader
Description
Loads an SAP Profitability and Cost Management (PCM) model using direct table loads. This process is significantly faster than Databridge. The Hyper Loader supports virtually all of the current PCM data, assignment, and structure tables.
This is the current list of available loading targets:
- Activity Aliases
- Activity Dimensional Hierarchy
- Activity Driver Aliases
- Activity Driver Dimensional Hierarchy
- Activity Driver Value
- BOM Default Makeup
- BOM External Unit Rate
- BOM Makeup
- BOM Production Volume
- BOM Units Sold
- Cost Object 1 Aliases
- Cost Object 1 Dimensional Hierarchy
- Cost Object 2 Aliases
- Cost Object 2 Dimensional Hierarchy
- Cost Object 3 Aliases
- Cost Object 3 Dimensional Hierarchy
- Cost Object 4 Aliases
- Cost Object 4 Dimensional Hierarchy
- Cost Object 5 Aliases
- Cost Object 5 Dimensional Hierarchy
- Cost Object Assignment
- Cost Object Driver
- Line Item Aliases
- Line Item Detail Aliases
- Line Item Detail Dimensional Hierarchy
- Line Item Detail Value
- Line Item Dimensional Hierarchy
- Line Item Direct Activity Assignment
- Line Item Resource Driver Assignment
- Line Item Value
- Period Aliases
- Period Dimensional Hierarchy
- Resource Driver Aliases
- Resource Driver Dimensional Hierarchy
- Resource Driver Split
- Resource Driver Value
- Responsibility Center Aliases
- Responsibility Center Dimensional Hierarchy
- Revenue
- Revenue Aliases
- Revenue Dimensional Hierarchy
- Service Aliases
- Service Dimensional Hierarchy
- Spread Aliases
- Spread Dimensional Hierarchy
- Spread Value
- Version Aliases
- Version Dimensional Hierarchy
- Worksheet 1 Aliases
- Worksheet 1 Dimensional Hierarchy
- Worksheet 2 Aliases
- Worksheet 2 Dimensional Hierarchy
- Worksheet Value
Our Credentials
Tartan Solutions is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown. Enter model name and select the load package storage path location, then select the child folder desired from within. Use the Table Data Selection below to select the source table model and the target load table. Inspect source>>propagate both sides of the table will reveal the data. Click “Save and Run Step” when the data is entered and you have added any expressions.
16.10 - Stop PCM Model Calculation
Description
Stops an SAP Profitability and Cost Management (PCM) model calculation process.
Our Credentials
Tartan Solutions is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown, enter “Model Name”, click the “Wait for Copy to Complete” check box, then click “Save and Run Step”.