This is the multi-page printable view of this section. Click here to print.
PlaidCloud
- 1: Analyze
- 1.1: Projects
- 1.1.1: Viewing Projects
- 1.1.2: Managing Projects
- 1.1.3: Managing Tables and Views
- 1.1.4: Managing Hierarchies
- 1.1.5: Managing Data Editors
- 1.1.6: Archive a Project
- 1.1.7: Viewing the Project Log
- 1.2: Data Management
- 1.2.1: Using Tables and Views
- 1.2.2: Table Explorer
- 1.2.3: Using Dimensions (Hierarchies)
- 1.2.4: Publishing Tables
- 1.3: Workflows
- 1.3.1: Where are the Workflows
- 1.3.2: Workflow Explorer
- 1.3.3: Create Workflow
- 1.3.4: Duplicate a Workflow
- 1.3.5: Copy & Paste steps
- 1.3.6: Change the order of steps in a workflow
- 1.3.7: Run a workflow
- 1.3.8: Running one step in a workflow
- 1.3.9: Running a range of steps in a workflow
- 1.3.10: Managing Step Errors
- 1.3.11: Continue on Error
- 1.3.12: Skip steps in a workflow
- 1.3.13: Conditional Step Execution
- 1.3.14: Controlling Parallel Execution
- 1.3.15: Manage Workflow Variables
- 1.3.16: Viewing Workflow Log
- 1.3.17: View Workflow Report
- 1.3.18: View a dependency audit
- 1.4: Workflow Steps
- 1.4.1: Workflow Control Steps
- 1.4.1.1: Create Workflow
- 1.4.1.2: Run Workflow
- 1.4.1.3: Stop Workflow
- 1.4.1.4: Copy Workflow
- 1.4.1.5: Rename Workflow
- 1.4.1.6: Delete Workflow
- 1.4.1.7: Set Project Variable
- 1.4.1.8: Set Workflow Variable
- 1.4.1.9: Worklow Loop
- 1.4.1.10: Raise Workflow Error
- 1.4.1.11: Clear Workflow Log
- 1.4.2: Import Steps
- 1.4.2.1: Import Archive
- 1.4.2.2: Import CSV
- 1.4.2.3: Import Excel
- 1.4.2.4: Import External Database Tables
- 1.4.2.5: Import Fixed Width
- 1.4.2.6: Import Google BigQuery
- 1.4.2.7: Import Google Spreadsheet
- 1.4.2.8: Import HDF
- 1.4.2.9: Import HTML
- 1.4.2.10: Import JSON
- 1.4.2.11: Import Project Table
- 1.4.2.12: Import Quandl
- 1.4.2.13: Import SAS7BDAT
- 1.4.2.14: Import SPSS
- 1.4.2.15: Import SQL
- 1.4.2.16: Import Stata
- 1.4.2.17: Import XML
- 1.4.3: Export Steps
- 1.4.3.1: Export to CSV
- 1.4.3.2: Export to Excel
- 1.4.3.3: Export to External Project Table
- 1.4.3.4: Export to Google Spreadsheet
- 1.4.3.5: Export to HDF
- 1.4.3.6: Export to HTML
- 1.4.3.7: Export to JSON
- 1.4.3.8: Export to Quandl
- 1.4.3.9: Export to SQL
- 1.4.3.10: Export to Table Archive
- 1.4.3.11: Export to XML
- 1.4.4: Table Steps
- 1.4.4.1: Table Anti Join
- 1.4.4.2: Table Append
- 1.4.4.3: Table Clear
- 1.4.4.4: Table Copy
- 1.4.4.5: Table Cross Join
- 1.4.4.6: Table Drop
- 1.4.4.7: Table Extract
- 1.4.4.8: Table Faker
- 1.4.4.9: Table In-Place Delete
- 1.4.4.10: Table In-Place Update
- 1.4.4.11: Table Inner Join
- 1.4.4.12: Table Lookup
- 1.4.4.13: Table Melt
- 1.4.4.14: Table Outer Join
- 1.4.4.15: Table Pivot
- 1.4.4.16: Table Union All
- 1.4.4.17: Table Union Distinct
- 1.4.4.18: Table Upsert
- 1.4.5: Dimension Steps
- 1.4.5.1: Dimension Clear
- 1.4.5.2: Dimension Create
- 1.4.5.3: Dimension Delete
- 1.4.5.4: Dimension Export
- 1.4.5.5: Dimension Load
- 1.4.5.6: Dimension Sort
- 1.4.6: Document Steps
- 1.4.6.1: Compress PDF
- 1.4.6.2: Concatenate Files
- 1.4.6.3: Convert Document Encoding
- 1.4.6.4: Convert Document Encoding to ASCII
- 1.4.6.5: Convert Document Encoding to UTF-8
- 1.4.6.6: Convert Document Encoding to UTF-16
- 1.4.6.7: Convert Image to PDF
- 1.4.6.8: Convert PDF or Image to JPEG
- 1.4.6.9: Copy Document Directory
- 1.4.6.10: Copy Document File
- 1.4.6.11: Create Document Directory
- 1.4.6.12: Crop Image to Headshot
- 1.4.6.13: Delete Document Directory
- 1.4.6.14: Delete Document File
- 1.4.6.15: Document Text Substitution
- 1.4.6.16: Fix File Extension
- 1.4.6.17: Merge Multiple PDFs
- 1.4.6.18: Rename Document Directory
- 1.4.6.19: Rename Document File
- 1.4.7: Notification Steps
- 1.4.7.1: Notify Distribution Group
- 1.4.7.2: Notify Agent
- 1.4.7.3: Notify Via Email
- 1.4.7.4: Notify Via Log
- 1.4.7.5: Notify via Microsoft Teams
- 1.4.7.6: Notify via Slack
- 1.4.7.7: Notify Via SMS
- 1.4.7.8: Notify Via Twitter
- 1.4.7.9: Notify Via Web Hook
- 1.4.8: Agent Steps
- 1.4.8.1: Agent Remote Execution of SQL
- 1.4.8.2: Agent Remote Export of SQL Result
- 1.4.8.3: Agent Remote Import Table into SQL Database
- 1.4.8.4: Document - Remote Delete File
- 1.4.8.5: Document - Remote Export File
- 1.4.8.6: Document - Remote Import File
- 1.4.8.7: Document - Remote Rename File
- 1.4.9: General Steps
- 1.4.9.1: Pass
- 1.4.9.2: Run Remote Python
- 1.4.9.3: User Defined Transform
- 1.4.9.4: Wait
- 1.4.10: PDF Reporting Steps
- 1.4.10.1: Report Single
- 1.4.10.2: Reports Batch
- 1.4.11: Common Step Operations
- 1.4.11.1: Advanced Data Mapper Usage
- 1.4.12: Allocation By Assignment Dimension
- 1.4.13: Allocation Split
- 1.4.14: Rule-Based Tagging
- 1.4.15: SAP ECC and S/4HANA Steps
- 1.4.15.1: Call SAP Financial Document Attachment
- 1.4.15.2: Call SAP General Ledger Posting
- 1.4.15.3: Call SAP Master Data Table RFC
- 1.4.15.4: Call SAP RFC
- 1.4.16: SAP PCM Steps
- 1.4.16.1: Create SAP PCM Model
- 1.4.16.2: Delete SAP PCM Model
- 1.4.16.3: Calculate PCM Model
- 1.4.16.4: Copy SAP PCM Model
- 1.4.16.5: Copy SAP PCM Period
- 1.4.16.6: Copy SAP PCM Version
- 1.4.16.7: Rename SAP PCM Model
- 1.4.16.8: Run SAP PCM Console Job
- 1.4.16.9: Run SAP PCM Hyper Loader
- 1.4.16.10: Stop PCM Model Calculation
- 1.5: Scheduled Workflows
- 1.5.1: Event Scheduler
- 1.6: Data Connectors
- 1.6.1: Cloud Service Connections
- 1.6.1.1: Quandl Connector
- 1.6.2: Database and Data Lake Connections
- 1.6.2.1: Amazon Athena
- 1.6.2.2: Amazon Redshift
- 1.6.2.3: Apache Doris
- 1.6.2.4: Apache Hive
- 1.6.2.5: Apache Spark
- 1.6.2.6: Azure Databricks
- 1.6.2.7: Databend
- 1.6.2.8: Exasol
- 1.6.2.9: Greenplum
- 1.6.2.10: IBM DB2
- 1.6.2.11: IBM Informix
- 1.6.2.12: Microsoft Fabric
- 1.6.2.13: Microsoft SQL Server
- 1.6.2.14: MySQL
- 1.6.2.15: ODBC
- 1.6.2.16: Oracle
- 1.6.2.17: PlaidCloud Lakehouse
- 1.6.2.18: PostgreSQL
- 1.6.2.19: Presto
- 1.6.2.20: SAP HANA
- 1.6.2.21: Snowflake
- 1.6.2.22: StarRocks
- 1.6.2.23: Trino
- 1.6.3: ERP System Connections
- 1.6.3.1: Infor Connector
- 1.6.3.2: JD Edwards (Legacy) Connector
- 1.6.3.3: Oracle EBS Connector
- 1.6.3.4: Oracle Fusion Connector
- 1.6.3.5: SAP Analytics Cloud Connector
- 1.6.3.6: SAP ECC Connector
- 1.6.3.7: SAP Profitability and Cost Management (PCM) Connector
- 1.6.3.8: SAP Profitability and Performance Management (PaPM) Connector
- 1.6.3.9: SAP S/4HANA Connector
- 1.6.4: Git Repository Connections
- 1.6.4.1: AWS CodeCommit Repository Connector
- 1.6.4.2: Azure Repos Repository Connector
- 1.6.4.3: BitBucket Repository Connector
- 1.6.4.4: GitHub Repository Connector
- 1.6.4.5: GitLab Repository Connector
- 1.6.5: Google Service Connections
- 1.6.5.1: Google BigQuery Connector
- 1.6.5.2: Google Sheets
- 1.6.6: Open Table Format Connections
- 1.6.6.1: Apache Hive Open Table Format
- 1.6.6.2: Apache Hudi Open Table Format
- 1.6.6.3: Apache Iceberg Open Table Format
- 1.6.6.4: Delta Lake Open Table Format (Databricks Catalog)
- 1.6.7: REST Connections
- 1.6.7.1: Gusto REST Connector
- 1.6.7.2: Microsoft Dynamics 365 REST Connector
- 1.6.7.3: Mulesoft REST Connector
- 1.6.7.4: Netsuite REST Connector
- 1.6.7.5: Paycor REST Connector
- 1.6.7.6: Quickbooks REST Connector
- 1.6.7.7: Ramp REST Connector
- 1.6.7.8: Sage Intacct REST Connector
- 1.6.7.9: Salesforce REST Connector
- 1.6.7.10: Stripe REST Connector
- 1.6.7.11: Workday REST Connector
- 1.6.8: Team Collaboration Connections
- 1.6.8.1: Microsoft Teams Connector
- 1.6.8.2: Slack Connector
- 1.7: Allocation Assignments
- 1.7.1: Getting Started
- 1.7.1.1: Allocations Quick Start
- 1.7.1.2: Rule Based Tagging
- 1.7.1.3: Why are Allocations Useful
- 1.7.2: Configure Allocations
- 1.7.2.1: Configure an Allocation
- 1.7.2.2: Recursive Allocations
- 1.7.3: Results and Troubleshooting
- 1.7.3.1: Allocation Results
- 1.7.3.2: Troubleshooting Allocations
- 1.8: Dimensions
- 1.8.1: Dimension Functions for Expressions and Aggregations
- 1.8.2: Loading and Unloading Dimensions
- 1.8.3: Using Dimensions (Hierarchies)
- 1.9: Data Lakehouse Service
- 1.9.1: Getting Started
- 1.9.2: Pricing
- 2: Dashboards
- 2.1: Learning About Dashboards
- 2.2: Using Dashboards
- 2.3: Formatting Numbers and Other Data Types
- 2.4: Example Calculated Columns
- 2.5: Example Metrics
- 3: Panel Apps
- 4: Document Management
- 4.1: Adding New Document Accounts
- 4.1.1: Add AWS S3 Account
- 4.1.2: Add Google Cloud Storage Account
- 4.1.3: Add Wasabi Hot Storage Account
- 4.2: Account and Access Management
- 4.2.1: Control Document Account Access
- 4.2.2: Document Temporary Storage
- 4.2.3: Managing Document Account Backups
- 4.2.4: Managing Document Account Owners
- 4.2.5: Using Start Paths in Document Accounts
- 4.3: Using Document Accounts
- 5: Expressions
- 5.1: Aggregate Functions
- 5.1.1: ANY
- 5.1.2: APPROX_COUNT_DISTINCT
- 5.1.3: ARG_MAX
- 5.1.4: ARG_MIN
- 5.1.5: ARRAY_AGG
- 5.1.6: AVG
- 5.1.7: AVG_IF
- 5.1.8: COUNT
- 5.1.9: COUNT_DISTINCT
- 5.1.10: COUNT_IF
- 5.1.11: COVAR_POP
- 5.1.12: COVAR_SAMP
- 5.1.13: GROUP_ARRAY_MOVING_AVG
- 5.1.14: GROUP_ARRAY_MOVING_SUM
- 5.1.15: HISTOGRAM
- 5.1.16: JSON_ARRAY_AGG
- 5.1.17: JSON_OBJECT_AGG
- 5.1.18: KURTOSIS
- 5.1.19: MAX
- 5.1.20: MAX_IF
- 5.1.21: MEDIAN
- 5.1.22: MEDIAN_TDIGEST
- 5.1.23: MIN
- 5.1.24: MIN_IF
- 5.1.25: QUANTILE_CONT
- 5.1.26: QUANTILE_DISC
- 5.1.27: QUANTILE_TDIGEST
- 5.1.28: QUANTILE_TDIGEST_WEIGHTED
- 5.1.29: RETENTION
- 5.1.30: SKEWNESS
- 5.1.31: STDDEV_POP
- 5.1.32: STDDEV_SAMP
- 5.1.33: STRING_AGG
- 5.1.34: SUM
- 5.1.35: SUM_IF
- 5.1.36: WINDOW_FUNNEL
- 5.2: AI Functions
- 5.2.1: AI_EMBEDDING_VECTOR
- 5.2.2: AI_TEXT_COMPLETION
- 5.2.3: AI_TO_SQL
- 5.2.4: COSINE_DISTANCE
- 5.3: Array Functions
- 5.3.1: ARRAY_AGGREGATE
- 5.3.2: ARRAY_APPEND
- 5.3.3: ARRAY_APPLY
- 5.3.4: ARRAY_CONCAT
- 5.3.5: ARRAY_CONTAINS
- 5.3.6: ARRAY_DISTINCT
- 5.3.7: ARRAY_FILTER
- 5.3.8: ARRAY_FLATTEN
- 5.3.9: ARRAY_GET
- 5.3.10: ARRAY_INDEXOF
- 5.3.11: ARRAY_LENGTH
- 5.3.12: ARRAY_PREPEND
- 5.3.13: ARRAY_REDUCE
- 5.3.14: ARRAY_REMOVE_FIRST
- 5.3.15: ARRAY_REMOVE_LAST
- 5.3.16: ARRAY_SIZE
- 5.3.17: ARRAY_SLICE
- 5.3.18: ARRAY_SORT
- 5.3.19: ARRAY_TO_STRING
- 5.3.20: ARRAY_TRANSFORM
- 5.3.21: ARRAY_UNIQUE
- 5.3.22: ARRAYS_ZIP
- 5.3.23: CONTAINS
- 5.3.24: GET
- 5.3.25: RANGE
- 5.3.26: SLICE
- 5.3.27: UNNEST
- 5.4: Bitmap Functions
- 5.4.1: BITMAP_AND
- 5.4.2: BITMAP_AND_COUNT
- 5.4.3: BITMAP_AND_NOT
- 5.4.4: BITMAP_CARDINALITY
- 5.4.5: BITMAP_CONTAINS
- 5.4.6: BITMAP_COUNT
- 5.4.7: BITMAP_HAS_ALL
- 5.4.8: BITMAP_HAS_ANY
- 5.4.9: BITMAP_INTERSECT
- 5.4.10: BITMAP_MAX
- 5.4.11: BITMAP_MIN
- 5.4.12: BITMAP_NOT
- 5.4.13: BITMAP_NOT_COUNT
- 5.4.14: BITMAP_OR
- 5.4.15: BITMAP_OR_COUNT
- 5.4.16: BITMAP_SUBSET_IN_RANGE
- 5.4.17: BITMAP_SUBSET_LIMIT
- 5.4.18: BITMAP_UNION
- 5.4.19: BITMAP_XOR
- 5.4.20: BITMAP_XOR_COUNT
- 5.4.21: INTERSECT_COUNT
- 5.4.22: SUB_BITMAP
- 5.5: Conditional Functions
- 5.5.1: [ NOT ] BETWEEN
- 5.5.2: [ NOT ] IN
- 5.5.3: AND
- 5.5.4: CASE
- 5.5.5: COALESCE
- 5.5.6: Comparison Methods
- 5.5.7: ERROR_OR
- 5.5.8: GREATEST
- 5.5.9: IF
- 5.5.10: IFNULL
- 5.5.11: IS [ NOT ] DISTINCT FROM
- 5.5.12: IS_ERROR
- 5.5.13: IS_NOT_ERROR
- 5.5.14: IS_NOT_NULL
- 5.5.15: IS_NULL
- 5.5.16: LEAST
- 5.5.17: NULLIF
- 5.5.18: NVL
- 5.5.19: NVL2
- 5.5.20: OR
- 5.6: Context Functions
- 5.6.1: CONNECTION_ID
- 5.6.2: CURRENT_CATALOG
- 5.6.3: CURRENT_USER
- 5.6.4: DATABASE
- 5.6.5: LAST_QUERY_ID
- 5.6.6: VERSION
- 5.7: Conversion Functions
- 5.7.1: BUILD_BITMAP
- 5.7.2: CAST, ::
- 5.7.3: TO_BINARY
- 5.7.4: TO_BITMAP
- 5.7.5: TO_BOOLEAN
- 5.7.6: TO_FLOAT32
- 5.7.7: TO_FLOAT64
- 5.7.8: TO_HEX
- 5.7.9: TO_INT16
- 5.7.10: TO_INT32
- 5.7.11: TO_INT64
- 5.7.12: TO_INT8
- 5.7.13: TO_STRING
- 5.7.14: TO_TEXT
- 5.7.15: TO_UINT16
- 5.7.16: TO_UINT32
- 5.7.17: TO_UINT64
- 5.7.18: TO_UINT8
- 5.7.19: TO_VARCHAR
- 5.7.20: TO_VARIANT
- 5.7.21: TRY_CAST
- 5.7.22: TRY_TO_BINARY
- 5.8: Date & Time Functions
- 5.8.1: ADD TIME INTERVAL
- 5.8.2: CURRENT_TIMESTAMP
- 5.8.3: DATE
- 5.8.4: DATE DIFF
- 5.8.5: DATE_ADD
- 5.8.6: DATE_FORMAT
- 5.8.7: DATE_PART
- 5.8.8: DATE_SUB
- 5.8.9: DATE_TRUNC
- 5.8.10: DAY
- 5.8.11: EXTRACT
- 5.8.12: LAST_DAY
- 5.8.13: MONTH
- 5.8.14: MONTHS_BETWEEN
- 5.8.15: NEXT_DAY
- 5.8.16: NOW
- 5.8.17: PREVIOUS_DAY
- 5.8.18: QUARTER
- 5.8.19: STR_TO_DATE
- 5.8.20: STR_TO_TIMESTAMP
- 5.8.21: SUBTRACT TIME INTERVAL
- 5.8.22: TIME_SLOT
- 5.8.23: TIMESTAMP_DIFF
- 5.8.24: TIMEZONE
- 5.8.25: TO_DATE
- 5.8.26: TO_DATETIME
- 5.8.27: TO_DAY_OF_MONTH
- 5.8.28: TO_DAY_OF_WEEK
- 5.8.29: TO_DAY_OF_YEAR
- 5.8.30: TO_HOUR
- 5.8.31: TO_MINUTE
- 5.8.32: TO_MONDAY
- 5.8.33: TO_MONTH
- 5.8.34: TO_QUARTER
- 5.8.35: TO_SECOND
- 5.8.36: TO_START_OF_DAY
- 5.8.37: TO_START_OF_FIFTEEN_MINUTES
- 5.8.38: TO_START_OF_FIVE_MINUTES
- 5.8.39: TO_START_OF_HOUR
- 5.8.40: TO_START_OF_ISO_YEAR
- 5.8.41: TO_START_OF_MINUTE
- 5.8.42: TO_START_OF_MONTH
- 5.8.43: TO_START_OF_QUARTER
- 5.8.44: TO_START_OF_SECOND
- 5.8.45: TO_START_OF_TEN_MINUTES
- 5.8.46: TO_START_OF_WEEK
- 5.8.47: TO_START_OF_YEAR
- 5.8.48: TO_TIMESTAMP
- 5.8.49: TO_UNIX_TIMESTAMP
- 5.8.50: TO_WEEK_OF_YEAR
- 5.8.51: TO_YEAR
- 5.8.52: TO_YYYYMM
- 5.8.53: TO_YYYYMMDD
- 5.8.54: TO_YYYYMMDDHH
- 5.8.55: TO_YYYYMMDDHHMMSS
- 5.8.56: TODAY
- 5.8.57: TOMORROW
- 5.8.58: TRY_TO_DATETIME
- 5.8.59: TRY_TO_TIMESTAMP
- 5.8.60: WEEK
- 5.8.61: WEEKOFYEAR
- 5.8.62: YEAR
- 5.8.63: YESTERDAY
- 5.9: Dictionary Functions
- 5.9.1: DICT_GET
- 5.10: Geography Functions
- 5.10.1: GEO_TO_H3
- 5.10.2: GEOHASH_DECODE
- 5.10.3: GEOHASH_ENCODE
- 5.10.4: H3_CELL_AREA_M2
- 5.10.5: H3_CELL_AREA_RADS2
- 5.10.6: H3_DISTANCE
- 5.10.7: H3_EDGE_ANGLE
- 5.10.8: H3_EDGE_LENGTH_KM
- 5.10.9: H3_EDGE_LENGTH_M
- 5.10.10: H3_EXACT_EDGE_LENGTH_KM
- 5.10.11: H3_EXACT_EDGE_LENGTH_M
- 5.10.12: H3_EXACT_EDGE_LENGTH_RADS
- 5.10.13: H3_GET_BASE_CELL
- 5.10.14: H3_GET_DESTINATION_INDEX_FROM_UNIDIRECTIONAL_EDGE
- 5.10.15: H3_GET_FACES
- 5.10.16: H3_GET_INDEXES_FROM_UNIDIRECTIONAL_EDGE
- 5.10.17: H3_GET_ORIGIN_INDEX_FROM_UNIDIRECTIONAL_EDGE
- 5.10.18: H3_GET_RESOLUTION
- 5.10.19: H3_GET_UNIDIRECTIONAL_EDGE
- 5.10.20: H3_GET_UNIDIRECTIONAL_EDGE_BOUNDARY
- 5.10.21: H3_GET_UNIDIRECTIONAL_EDGES_FROM_HEXAGON
- 5.10.22: H3_HEX_AREA_KM2
- 5.10.23: H3_HEX_AREA_M2
- 5.10.24: H3_HEX_RING
- 5.10.25: H3_INDEXES_ARE_NEIGHBORS
- 5.10.26: H3_IS_PENTAGON
- 5.10.27: H3_IS_RES_CLASS_III
- 5.10.28: H3_IS_VALID
- 5.10.29: H3_K_RING
- 5.10.30: H3_LINE
- 5.10.31: H3_NUM_HEXAGONS
- 5.10.32: H3_TO_CENTER_CHILD
- 5.10.33: H3_TO_CHILDREN
- 5.10.34: H3_TO_GEO
- 5.10.35: H3_TO_GEO_BOUNDARY
- 5.10.36: H3_TO_PARENT
- 5.10.37: H3_TO_STRING
- 5.10.38: H3_UNIDIRECTIONAL_EDGE_IS_VALID
- 5.10.39: POINT_IN_POLYGON
- 5.10.40: STRING_TO_H3
- 5.11: Geometry Functions
- 5.11.1: HAVERSINE
- 5.11.2: ST_ASBINARY
- 5.11.3: ST_ASEWKB
- 5.11.4: ST_ASEWKT
- 5.11.5: ST_ASGEOJSON
- 5.11.6: ST_ASTEXT
- 5.11.7: ST_ASWKB
- 5.11.8: ST_ASWKT
- 5.11.9: ST_CONTAINS
- 5.11.10: ST_DIMENSION
- 5.11.11: ST_DISTANCE
- 5.11.12: ST_ENDPOINT
- 5.11.13: ST_GEOHASH
- 5.11.14: ST_GEOM_POINT
- 5.11.15: ST_GEOMETRYFROMEWKB
- 5.11.16: ST_GEOMETRYFROMEWKT
- 5.11.17: ST_GEOMETRYFROMTEXT
- 5.11.18: ST_GEOMETRYFROMWKB
- 5.11.19: ST_GEOMETRYFROMWKT
- 5.11.20: ST_GEOMFROMEWKB
- 5.11.21: ST_GEOMFROMEWKT
- 5.11.22: ST_GEOMFROMGEOHASH
- 5.11.23: ST_GEOMFROMTEXT
- 5.11.24: ST_GEOMFROMWKB
- 5.11.25: ST_GEOMFROMWKT
- 5.11.26: ST_GEOMPOINTFROMGEOHASH
- 5.11.27: ST_LENGTH
- 5.11.28: ST_MAKE_LINE
- 5.11.29: ST_MAKEGEOMPOINT
- 5.11.30: ST_MAKELINE
- 5.11.31: ST_MAKEPOLYGON
- 5.11.32: ST_NPOINTS
- 5.11.33: ST_NUMPOINTS
- 5.11.34: ST_POINTN
- 5.11.35: ST_POLYGON
- 5.11.36: ST_SETSRID
- 5.11.37: ST_SRID
- 5.11.38: ST_STARTPOINT
- 5.11.39: ST_TRANSFORM
- 5.11.40: ST_X
- 5.11.41: ST_XMAX
- 5.11.42: ST_XMIN
- 5.11.43: ST_Y
- 5.11.44: ST_YMAX
- 5.11.45: ST_YMIN
- 5.11.46: TO_GEOMETRY
- 5.11.47: TO_STRING
- 5.12: Hash Functions
- 5.12.1: BLAKE3
- 5.12.2: CITY64WITHSEED
- 5.12.3: MD5
- 5.12.4: SHA
- 5.12.5: SHA1
- 5.12.6: SHA2
- 5.12.7: SIPHASH
- 5.12.8: SIPHASH64
- 5.12.9: XXHASH32
- 5.12.10: XXHASH64
- 5.13: Interval Functions
- 5.13.1: EPOCH
- 5.13.2: TO_CENTURIES
- 5.13.3: TO_DAYS
- 5.13.4: TO_DECADES
- 5.13.5: TO_HOURS
- 5.13.6: TO_MICROSECONDS
- 5.13.7: TO_MILLENNIA
- 5.13.8: TO_MILLISECONDS
- 5.13.9: TO_MINUTES
- 5.13.10: TO_MONTHS
- 5.13.11: TO_SECONDS
- 5.13.12: TO_WEEKS
- 5.13.13: TO_YEARS
- 5.14: IP Address Functions
- 5.14.1: INET_ATON
- 5.14.2: INET_NTOA
- 5.14.3: IPV4_NUM_TO_STRING
- 5.14.4: IPV4_STRING_TO_NUM
- 5.14.5: TRY_INET_ATON
- 5.14.6: TRY_INET_NTOA
- 5.14.7: TRY_IPV4_NUM_TO_STRING
- 5.14.8: TRY_IPV4_STRING_TO_NUM
- 5.15: Map Functions
- 5.15.1: MAP_CAT
- 5.15.2: MAP_CONTAINS_KEY
- 5.15.3: MAP_DELETE
- 5.15.4: MAP_FILTER
- 5.15.5: MAP_INSERT
- 5.15.6: MAP_KEYS
- 5.15.7: MAP_PICK
- 5.15.8: MAP_SIZE
- 5.15.9: MAP_TRANSFORM_KEYS
- 5.15.10: MAP_TRANSFORM_VALUES
- 5.15.11: MAP_VALUES
- 5.16: Numeric Functions
- 5.16.1: ABS
- 5.16.2: ACOS
- 5.16.3: ADD
- 5.16.4: ASIN
- 5.16.5: ATAN
- 5.16.6: ATAN2
- 5.16.7: CBRT
- 5.16.8: CEIL
- 5.16.9: CEILING
- 5.16.10: COS
- 5.16.11: COT
- 5.16.12: CRC32
- 5.16.13: DEGREES
- 5.16.14: DIV
- 5.16.15: DIV0
- 5.16.16: DIVNULL
- 5.16.17: EXP
- 5.16.18: FACTORIAL
- 5.16.19: FLOOR
- 5.16.20: INTDIV
- 5.16.21: LN
- 5.16.22: LOG(b, x)
- 5.16.23: LOG(x)
- 5.16.24: LOG10
- 5.16.25: LOG2
- 5.16.26: MINUS
- 5.16.27: MOD
- 5.16.28: MODULO
- 5.16.29: NEG
- 5.16.30: NEGATE
- 5.16.31: PI
- 5.16.32: PLUS
- 5.16.33: POW
- 5.16.34: POWER
- 5.16.35: RADIANS
- 5.16.36: RAND()
- 5.16.37: RAND(n)
- 5.16.38: ROUND
- 5.16.39: SIGN
- 5.16.40: SIN
- 5.16.41: SQRT
- 5.16.42: SUBTRACT
- 5.16.43: TAN
- 5.16.44: TRUNCATE
- 5.17: Other Functions
- 5.17.1: ASSUME_NOT_NULL
- 5.17.2: EXISTS
- 5.17.3: GROUPING
- 5.17.4: HUMANIZE_NUMBER
- 5.17.5: HUMANIZE_SIZE
- 5.17.6: IGNORE
- 5.17.7: REMOVE_NULLABLE
- 5.17.8: TO_NULLABLE
- 5.17.9: TYPEOF
- 5.18: Search Functions
- 5.19: Semi-Structured Functions
- 5.19.1: AS_<type>
- 5.19.2: CHECK_JSON
- 5.19.3: FLATTEN
- 5.19.4: GET
- 5.19.5: GET_IGNORE_CASE
- 5.19.6: GET_PATH
- 5.19.7: IS_ARRAY
- 5.19.8: IS_BOOLEAN
- 5.19.9: IS_FLOAT
- 5.19.10: IS_INTEGER
- 5.19.11: IS_NULL_VALUE
- 5.19.12: IS_OBJECT
- 5.19.13: IS_STRING
- 5.19.14: JQ
- 5.19.15: JSON_ARRAY
- 5.19.16: JSON_ARRAY_APPLY
- 5.19.17: JSON_ARRAY_DISTINCT
- 5.19.18: JSON_ARRAY_ELEMENTS
- 5.19.19: JSON_ARRAY_EXCEPT
- 5.19.20: JSON_ARRAY_FILTER
- 5.19.21: JSON_ARRAY_INSERT
- 5.19.22: JSON_ARRAY_INTERSECTION
- 5.19.23: JSON_ARRAY_MAP
- 5.19.24: JSON_ARRAY_OVERLAP
- 5.19.25: JSON_ARRAY_REDUCE
- 5.19.26: JSON_ARRAY_TRANSFORM
- 5.19.27: JSON_EACH
- 5.19.28: JSON_EXTRACT_PATH_TEXT
- 5.19.29: JSON_MAP_FILTER
- 5.19.30: JSON_MAP_TRANSFORM_KEYS
- 5.19.31: JSON_MAP_TRANSFORM_VALUES
- 5.19.32: JSON_OBJECT_DELETE
- 5.19.33: JSON_OBJECT_INSERT
- 5.19.34: JSON_OBJECT_KEEP_NULL
- 5.19.35: JSON_OBJECT_KEYS
- 5.19.36: JSON_OBJECT_PICK
- 5.19.37: JSON_PATH_EXISTS
- 5.19.38: JSON_PATH_MATCH
- 5.19.39: JSON_PATH_QUERY
- 5.19.40: JSON_PATH_QUERY_ARRAY
- 5.19.41: JSON_PATH_QUERY_FIRST
- 5.19.42: JSON_PRETTY
- 5.19.43: JSON_STRIP_NULLS
- 5.19.44: JSON_TO_STRING
- 5.19.45: JSON_TYPEOF
- 5.19.46: OBJECT_KEYS
- 5.19.47: PARSE_JSON
- 5.20: Sequence Functions
- 5.20.1: NEXTVAL
- 5.21: String Functions
- 5.21.1: ASCII
- 5.21.2: BIN
- 5.21.3: BIT_LENGTH
- 5.21.4: CHAR
- 5.21.5: CHAR_LENGTH
- 5.21.6: CHARACTER_LENGTH
- 5.21.7: CONCAT
- 5.21.8: CONCAT_WS
- 5.21.9: FROM_BASE64
- 5.21.10: FROM_HEX
- 5.21.11: HEX
- 5.21.12: INSERT
- 5.21.13: INSTR
- 5.21.14: JARO_WINKLER
- 5.21.15: LCASE
- 5.21.16: LEFT
- 5.21.17: LENGTH
- 5.21.18: LENGTH_UTF8
- 5.21.19: LIKE
- 5.21.20: LOCATE
- 5.21.21: LOWER
- 5.21.22: LPAD
- 5.21.23: LTRIM
- 5.21.24: MID
- 5.21.25: NOT LIKE
- 5.21.26: NOT REGEXP
- 5.21.27: NOT RLIKE
- 5.21.28: OCT
- 5.21.29: OCTET_LENGTH
- 5.21.30: ORD
- 5.21.31: POSITION
- 5.21.32: QUOTE
- 5.21.33: REGEXP
- 5.21.34: REGEXP_INSTR
- 5.21.35: REGEXP_LIKE
- 5.21.36: REGEXP_REPLACE
- 5.21.37: REGEXP_SUBSTR
- 5.21.38: REPEAT
- 5.21.39: REPLACE
- 5.21.40: REVERSE
- 5.21.41: RIGHT
- 5.21.42: RLIKE
- 5.21.43: RPAD
- 5.21.44: RTRIM
- 5.21.45: SOUNDEX
- 5.21.46: SOUNDS LIKE
- 5.21.47: SPACE
- 5.21.48: SPLIT
- 5.21.49: SPLIT_PART
- 5.21.50: STRCMP
- 5.21.51: SUBSTR
- 5.21.52: SUBSTRING
- 5.21.53: TO_BASE64
- 5.21.54: TRANSLATE
- 5.21.55: TRIM
- 5.21.56: TRIM_BOTH
- 5.21.57: TRIM_LEADING
- 5.21.58: TRIM_TRAILING
- 5.21.59: UCASE
- 5.21.60: UNHEX
- 5.21.61: UPPER
- 5.22: System Functions
- 5.22.1: CLUSTERING_INFORMATION
- 5.22.2: FUSE_BLOCK
- 5.22.3: FUSE_COLUMN
- 5.22.4: FUSE_ENCODING
- 5.22.5: FUSE_SEGMENT
- 5.22.6: FUSE_SNAPSHOT
- 5.22.7: FUSE_STATISTIC
- 5.22.8: FUSE_TIME_TRAVEL_SIZE
- 5.23: Table Functions
- 5.23.1: GENERATE_SERIES
- 5.23.2: INFER_SCHEMA
- 5.23.3: INSPECT_PARQUET
- 5.23.4: LIST_STAGE
- 5.23.5: RESULT_SCAN
- 5.23.6: SHOW_GRANTS
- 5.23.7: STREAM_STATUS
- 5.23.8: TASK_HISTORY
- 5.24: Test Functions
- 5.24.1: SLEEP
- 5.25: UUID Functions
- 5.25.1: GEN_RANDOM_UUID
- 5.25.2: UUID
- 5.26: Window Functions
- 5.26.1: CUME_DIST
- 5.26.2: DENSE_RANK
- 5.26.3: FIRST
- 5.26.4: FIRST_VALUE
- 5.26.5: LAG
- 5.26.6: LAST
- 5.26.7: LAST_VALUE
- 5.26.8: LEAD
- 5.26.9: NTH_VALUE
- 5.26.10: NTILE
- 5.26.11: PERCENT_RANK
- 5.26.12: RANK
- 5.26.13: ROW_NUMBER
- 6: Custom App Sandbox
- 7: PySpark and Spark Compute Clusters
- 8: How To
1 - Analyze
1.1 - Projects
1.1.1 - Viewing Projects
Description
Within Analyze, the Projects function provides a level of compartmentalization that makes controlling access and modifying privileges much easier. Projects are what provide the primary segregation of data within a workspace tab.
While Projects fall under Analyze, workflows fall under Projects, meaning that Projects contain workflows. Workflows, simply put, perform a wide range of tasks including data transformation pipelines, data analysis, and even ETL processes. More information on workflows can be found under the “Workflows” section.
Accessing Projects
To access Projects:
- Open Analyze
- Select “Projects” from the top menu bar
This displays the Projects Hierarchy. From here, you will see a hierarchy of projects for which you have access. There may be additional projects within the workspace, but, if you are not an owner or assigned to the project, they will not be visible to you.
1.1.2 - Managing Projects
Searching
Searching for projects is accomplished by using the filter box in the lower left of the hierarchy. The search filter will search project names and labels for matches and show the results in the hierarchy above.
Creating New Projects
To create a new project:
- Open Analyze
- Select “Projects” from the top menu bar
- Click the “New Project” button
- Complete the form information including the “Access Control” section
- Click “Create”
The project is now ready for updating access permissions, adding owners, and creating workflows.
Automatic Change Tracking
All changes to a project, including workflows, data editors, hierarchies, table structures, and UDFs are tracked and allow point-in-time recovery of the state. This allows for easy recovery from user introduced problems or simply copying a different point-in-time to another project for comparison.
In addition to overall tracking, projects and their elements also allow for versioning. Not only is creating a version easy, you can also merge changes from one version to another. This provides a simple way to keep track of snapshots or to create a version for development and then be able to merge those changes into the non-development version when you want.
Managing Project Access
Types of Access
Project security has been simplified into three types of access:
- All Workspace Members
- Specific Members Only
- Specific Security Groups Only
Setting the project security is easy to do:
- Open Analyze
- Select “Projects”
- Click the edit icon of the project you want to restrict
- Choose desired restriction under “Access Control”
- Click “Update”
All Workspace Members
“All Workspace Members” access is the most simple option since it provides access to all members of the workspace and does not require any additional assignment of members.
Specific Members Only
“The Specific Members Only” access setting requires assignment of each member to the project.To assign members to a project:
- Open Analyze
- Select “Projects” from the top menu bar
- Click the members icon
- Grant access to members by selecting the check box next to their name in the “Access” column
- Click “Update”
For clouds with large numbers of members, this approach can often require more effort than desired, which is where security groups become useful.
Specific Security Groups Only
The “Specific Security Groups Only” option enables assigning specific security groups permission to access the account. With access restrictions relying on association with a security group or groups, the administration of account access for larger groups is much simpler. This is particularly useful when combined with single sign-on automatic group association. By using single sign-on to set member group assignments, these groups can also enable and disable access to projects implicitly.
To edit assigned groups:
- Open Analyze
- Select “Projects” from the top menu bar
- Click the security groups icon
- Grant access to security groups by selecting the check box next to their name in the “Access” column
- Click “Update”
Setting Different Viewing Roles
Many times a project may require several transformations and tables to complete intermediate steps while the end result may end up only consisting of a few tables. Members do not always require viewing of all the elements of the project, sometimes just the final product. PlaidCloud offers you the ability to set different viewing roles to easily declutter and control the visibility of each member.
There are three built-in viewing roles: Architect, Manager, and Explorer
The Architect role is the most simple because it allows full visibility and control of projects, workflows, tables, variables, data editors, hierarchies, and user defined functions.
The Manager and Explorer roles have no specific access privileges but can be custom-defined. In other words, you can choose which items are visible to each group.
You can make everyone an Architect if you feel visibility of everything within the project is needed; otherwise, you can designate members as Manager and/or Explorer project members and control visibility that way.
To set the different role:
- Open Analyze
- Select “Projects”
- Click the members icon
- Select the member you whose role you would like to change
- Double click their current role in the “Role” column
- Select the desired role
- Click “Update”
Managing Project Variables
When running a project or workflow it may be useful to set variables for recurring tasks in order to decrease clutter and save time. These variables operate just like a normal algebraic variable by allowing you to set what the variable represents and what operation should follow it. PlaidCloud allows you to set these variables at the project level, which will effect all the workflows within that project, or at the workflow level, which will only effect that specific workflow.
To set a project level variable:
- Open Analyze
- Select “Projects”
- Click the Manage Project Variables icon
From the Variables Table you can view the variables and view/edit the current values. You can also add new or delete existing variables by clicking the “New Project Variable” button.
Cloning a Project
When a project is cloned, there may be project related references, such as workflow steps, that run within the project. PlaidCloud offers two options for performing a full duplication:
- Duplicate with updating project references
- Duplicate without updating project references
Duplicating with updating project references means all the related references point to the newly duplicated project.
To duplicate with updating project references:
- Open Analyze
- Select “Projects”
- Select the project you would like to duplicate
- Click the “Actions” button
- Select the “Duplicate with project reference updates” option
To duplicate without updating project references means to have all of the related references continue pointing to the original project.
To duplicate without updating project references:
- Open Analyze
- Select “Projects”
- Select the project you would like to duplicate
- Click the “Actions” button
- Select the “Duplicate without project reference updates” option
Viewing the Project Report
When a project or workflow is dynamic, maintaining detailed documentation becomes a challenge. To help solve this problem, PlaidCloud provides the ability to generate a project-level report that gives detailed documentation of workflows, workflow steps, user defined transforms, variables, and tables. This report is generated on-demand and reflects the current state of the project.
To download the report:
- Open Analyze
- Select “Projects”
- Click the report icon
1.1.3 - Managing Tables and Views
PlaidCloud offers the ability to organize and manage tables, including labels. Tables are available to all workflows within a project and have many tools and options.
In addition to tables, PlaidCloud also offers Views based on table data. Using Views allows for instant updates when underlying table changes occur, as well as saving data storage space.
Options include:
- The same table can exist on multiple paths in the hierarchy (alternate hierarchies)
- Tables are taggable for easier search and inclusion in PlaidCloud processes
- Tables can be versioned
- Tables can be published so they are available for Dashboard Visualizations
PlaidCloud uses a path-based system to organize tables, like you would use to navigate a series of folders, allowing for a more flexible and logical organization of tables. Using this system, tables can be moved within a hierarchy, or multiple references to one table from different locations in the hierarchy (alternate hierarchies), can be created. The ability to manage tables using this method allows the structure to reflect operational needs, reporting, and control.
Searching
Searching for tables is accomplished by using the filter box in the lower left of hierarchy. The search filter will search table names and labels for matches and show the results in the hierarchy above.
Move
To move a table:
- Drag it into the folder where you wish it to be located
Rename
To rename a table:
- Right click on the table
- Select the rename option
- Type in the new name and save it
- The table is now renamed, but it retains its original unique identifier.
Clear
To clear a table:
- Select the tables in the hierarchy ‘
- Click the clear button on the top toolbar.
Note: You can clear a single table or multiple tables
Delete
To delete a table:
- Select the tables in the hierarchy
- Click the delete button on the top toolbar
- The deleted operation will check to see if the table is in use by workflow steps or Views. If so, you will be asked to remove those associations before deletion can occur.
Note: You can also force delete the table(s). Force deletion of the table(s) will leave references broken, so this should be used sparingly.
Create New Directory Structure
To add a new folder:
- Click the New Folder button on the toolbar
To add a folder to an existing folder:
- Right-click on the folder
- Select New Folder
View Data (Table Explorer)
Table data is viewed using the Data Explorer. The Data Explorer provides a grid view of the data as well as a column by column summary of values and statistics. Point-and-click filtering and exporting to familiar file formats are both available. The filter selections can also be saved as an Extract step usable in a workflow.
Publish Table for Reporting
Dashboard Visualizations are purposely limited to tables that have been published. When publishing a table, you can provide a unique name that may distinguish the data. This may be useful when the table has a more obscure name on part of the workflow that generated it, but it needs a clearer name for those building dashboards.
Published tables do not have paths associated with them. They will appear as a list of tables for use in the dashboards area.
Mark Table for Viewing Roles
The viewing of tables by various roles can be controlled by clicking the Explorer or Manager checkboxes. If multiple tables need to be updated, select the tables in the hierarchy and select the desired viewing role from the Actions menu on the top toolbar.
Memos to Describe Table Contents
Add a memo to a table to help understand the data.
View Table Shape, Size, and Last Updated Time
The number of rows, columns, and the data size for each table is shown in the table hierarchy. For very large tables (multi-million rows) the row count may be estimated and an indicator for approximate row count will be shown.
View Additional Table Attributes
To view and edit other table attributes:
- Select a table
- Click the view the table context form on the right.
Duplicate a Table
To duplicate a table:
- Selecting the table
- Click on the duplicate button on the top toolbar.
1.1.4 - Managing Hierarchies
PlaidCloud offers the ability to organize and manage hierarchies, including labels. Hierarchies are available to all workflows within a project.
PlaidCloud uses a path-based system to organize hierarchies, like you would use to navigate a series of folders, allowing for a more flexible and logical organization (control hierarchy) of the hierarchies. Using this system, hierarchies can be moved within a control hierarchy, or multiple references to one hierarchy, from different locations in the control hierarchy (alternate hierarchies) can be created. The ability to manage hierarchies using this method allows the structure to reflect operational needs, reporting, and control.
Searching
To search for hierarchies:
- Use the filter box in the lower left of the control hierarchy
- The search filter will search hierarchy names and labels for matches and show the results in the control hierarchy above
Move
To move a hierarchy within the control hierarchy:
- Drag it into the folder where you wish to place it
Rename
To Rename a Hierarchy:
- Right click on the hierarchy
- Select the rename option
- Type in the new name and save it
- The hierarchy is now renamed, but it will retain its original unique identifier
Clear
You can clear a single hierarchy or multiple hierarchies.
To clear a hierarchy:
- Select the hierarchies in the control hierarchy
- Click the clear button on the top toolbar
Delete
You can delete a single hierarchy or multiple hierarchies.
To delete a hierarchy:
- Select the hierarchies in the control hierarchy
- Click the delete button on the top toolbar
The delete operation will check to see if the hierarchy is in use by workflow steps, tables, or views. If so, you will be asked to remove those associations.
Create New Directory Structure
To create a new folder:
- Clicking the New Folder button on the toolbar
To add a folder to an existing folder:
- Right-click on the folder
- Select New Folder.
Mark Hierarchy for Viewing Roles
To view hierarchies by roles:
- Click in the Explorer or Manager checkboxes
To view hierarchies that need to be updated:
- Select the hierarchies in the control hierarchy
- Select the desired viewing role from the Actions menu on the top toolbar
Memos to Describe Table Contents
To add a memo to a hierarchy:
- Select the hierarchy
- Update the memo in the right context form
View Additional Hierarchy Attributes
To view and edit additional hierarchy attributes:
- Select a hierarchy
- View the hierarchy context form on the right
Duplicate a Hierarchy
To duplicate a hierarchy:
Select the hieracrhy
Click the duplicate button on the top toolbar
1.1.5 - Managing Data Editors
PlaidCloud offers the ability to organize and manage data editors, including labels. Data Editors allow editing table data or creating data by user interaction.
PlaidCloud uses a path-based system to organize data editors, like you would use to navigate a series of folders, allowing for a more flexible and logical organization (control hierarchy) of the data editors. Using this system, data editors can move within a control hierarchy. Multiple references to one data editor from different locations in the control hierarchy (alternate hierarchies) can be created. The ability to manage data editors using this method allows the structure to reflect operational needs, reporting, and control.
Searching
To search for data editors:
- Use the filter box in the lower left of the control hierarchy
The search filter will search data editors’ names and labels for matches and show the results in the control hierarchy above.
Move
To move a data editor within the control hierarchy:
- Drag it into the folder where you wish to place it
Rename
To rename a data editor:
- Right click on the data editor
- Select the rename option
- Type in the new name and save it
The data editor will now be renamed but retain its original unique identifier.
Delete
You can delete a single data editor or multiple data editors.
To delete a data editor:
- Select the data editors in the control hierarchy
- Click the delete button on the top toolbar
Create New Directory Structure
To add a new folder to the control hierarchy:
- Click the New Folder button on the toolbar
To add a folder to an existing folder:
- Right-click on the folder
- Select New Folder
Mark Hierarchy for Viewing Roles
The viewing of data editors by various roles:
- Click in the Explorer or Manager checkboxes
To update multiple data editors:
- Select the data editors in the control hierarchy
- Select the desired viewing role from the Actions menu on the top toolbar
Memos to Describe Table Contents
To add a memo to a data editor:
- Select the data editor
- Update the memo in the right context form
View Additional Hierarchy Attributes
To view and edit additional data editor attributes:
- Select the data editor and view the data editor context form on the right
Duplicate a Data Editor
To duplicate a data editor:
- Select the data editor
- Click on the Duplicate button on the top toolbar
1.1.6 - Archive a Project
Creating an Archive
Projects normally contain critical processes and logic, which are important to archive. If you ever need to restore the project to a specific state, having archives is essential.
PlaidCloud allows you to archive projects at any point in time. Creation of archives complements the built-in point-in-time tracking of PlaidCloud by allowing for specific points in time to be captured. This might be particularly useful before a major change or to capture the exact state of a production environment for posterity.
Full backup: This includes all the data tables included in a project. The archive may be quite large, depending on the volume of data in the project.
Partial backup: This can be used if all of the project data can be derived from other sources. If this is the case, it is not necessary to archive the data in the project and have it remain elsewhere. Partial archives save time and storage space when creating the archive.
To archive a project:
- Open Analyze
- Select the “Projects” tab
Restoring an Archive
Once you have an archive, you may want to restore it. You can restore an archive into a new project or into an existing project.
To restore an archive:
- Open Analyze
- Select the “Projects” tab
Archiving Schedule
Archives can also serve as a periodic backup of your project. PlaidCloud allows you to manage the backup schedule and set the retention period of the backup archives to whatever is most convenient or desired.
Since all changes to a project are automatically tracked, archiving is not necessary for rollback purposes. However, it does provide specific snapshots of the project state, which is often useful for control purposes and/or having the ability to recover to a known point.
To set an archiving schedule:
- Open Analyze
- Select the “Projects” tab
- Click the backup icon
- Choose a directory destination in a Document account
- Choose the backup frequency and retention
- Choose which items to backup
- Click “Update”
1.1.7 - Viewing the Project Log
Viewing and Sorting the Project Log
As actions occur within a project, such as assigning new members or running workflows, the Project Log stores the events. The Project Log consolidates the view of all individual workflow logs in order to provide a more comprehensive view of project activities. PlaidCloud also enables the viewer to sort and filter a Project Log and view details of a particular log entry.
To view the Project Log:
- Open Analyze
- Select “Projects”
- Click the log icon
To sort and filter the Project Log:
- Click the small icon to the right of the log and to the left of the “log message”
- Select desired guidelines
To view details of a particular log entry:
- Right click on the desired log entry
- View the “Log Message” box for details
Clearing the Project Log
Clearing the Project Log may be desirable from time to time
To clear the Project Log:
- Open Analyze
- Select “Projects”
- Click the log icon
- Click the “Clear Log” button
1.2 - Data Management
1.2.1 - Using Tables and Views
Tabular data and information in PlaidCloud is stored in Greenplum data warehouses. This provides massive scalability and performance while using well understood and mature technology to minimize risk of data loss or corruption.
In addition, utilizing a data warehouse that operates with a common syntax allows 3rd party tools to connect and explore data directly. Essentially, this makes the PlaidCloud data ecosystem open and explorable while also ensuring industry leading security and access controls.
Tables
Tables hold the physical tabular data throughout PlaidCloud. Individual tables can hold many terabytes of data if needed. Data is stored across many physical servers and is automatically mirrored to ensure data integrity and high availability.
Tables consist of columns of various data types. Using an appropriate data type can help with performance and especially the storage size of your data. PlaidCloud can do a better job of compressing the data if the data is using the most appropriate data type too. This is usually guessed by PlaidCloud but it is also possible to change the data types using the column mappers in workflow steps.
Views
Views act just like tables but don't hold any physical data. They are logical representations of tables derived through a query. Using views can save on storage.
There are some limitations to the use of views though. Just be aware of the following:
- View Stacking Performance - View stacking (view of a view of a view...etc) can impact performance on very large tables or complex calculations. It might be necessary to create intermediate tables to improve performance.
- Dashboard Performance - While perfectly fine to publish a view for Dashboard use, for very large tables you may want to publish a table rather than a view for optimal user experience.
- Dynamic Data - The data in a view changes when the underlying referenced table data changes. This can be both a benefit (everything updates automatically) or an unexpected headache if the desire was a static set of data.
1.2.2 - Table Explorer
Table Explorer provides a powerful and readily accessible data exploration tool with built in filtering, summarization, and other features to make life easy for people working with large and complex data.
Table Explorer supports exploration on any size dataset so you can use the same tool no matter how much your data grows. It also provides point-and-click filtering along with advanced filter capabilities to zero in on the data you need. The best part is that anywhere in PlaidCloud with tables or views, you can click on those tables and views to explore with Table Explorer. By being fully integrated, data access is only a click away.
The Grid view provides a tabular view of the data. The Details view provides a summary of each column, a count of unique values, and summary statistics for numeric columns.
Data can be exported directly from a filtered set as well as being able to save and share filters with others. Finally, the filters and column settings
can be saved directly as a workflow Extract step.
The Grid View
The Grid view provides a tabular view of the data.
Setting the row limit
By default, the row limit is set to 5,000 rows. However, this can be adjusted or disabled entirely.
The rows shown along with the total size of the dataset are shown at the bottom of the table. The information provides three key pieces of information:
- The current row count shown based on the row limit applied
- The size of the global data after filters are applied
- The size of the unfiltered global data
Sorting locally versus globally
The Grid view provides the ability to click on the column header and sort the data based on that column. However, this method is only sorting the dataset that has already been retrieved and is not sorting based on the full dataset. If your retrieved data contains the entire dataset this distinction is immaterial however if your full dataset is larger than what appears in the browser, this may not be the desired sort result.
If you desire to sort the global dataset before retrieving the limited data that will appear in your browser those sorts can be applied to the columns in the Details view by clicking on the Sort icon at the top of each column. An additional benefit of using the global sort approach is that you can apply multiple sorts along with a mix of sort directions.
Quick reference column list
All of the columns in the table or view are shown on the left of the Table Explorer window by default. This column list can be toggled on and off using the column list toggle button.
The column list provides a number of quick access and useful features including:
- Double clicking an item jumps to the column in the
GridorDetailsview - Control visibility of the column through the visibility checkbox
- Use multi-select and right-click to include or exclude many columns at once
- Quickly view the data type of each column using the data type icons
- View the total column count
The Details View
The Details view provides an efficient way to view the data at a high level and exposes tools to quickly filter down to information
with point-and-click operations.
Column data and unique counts
Each column is shown, provided it is currently marked as visible. The column summary displays the top 1,000 unique values by count. The number
of unique values shown can be adjusted by selecting the Detailed Rows Displayed selection for a different value.
Managing point-and-click filters
Each column provides for point-and-click filtering by activating the filter toggle at the top of the column. Select the items in the column that you would like to include in the resulting data. Multi-select is supported.
Once you apply a filter, there may be items you wish to remove or to clear the entire column filter without clearing all filters. This is accomplished by selecting the dropdown on the column filter button and unchecking columns or selecting the clear all option at the top.
Managing Summarization
Summarization of the data can be applied by toggling the Summarize button to On. When the Summarize button is activated, each column will display
a summarization type to apply. Adjust the summarization type desired for each column.
When the desired summarizations are complete, refresh the data and the summarizations will be applied.
Examples of summarization types are Min, Max, Sum, Count, and Count Distinct.
Finding Distinct Values
Activating the Distinct button will help reduce the data to only a set of unique records. When the Distinct button is active, a Distinct checkbox will appear on each column. Uncheck the columns that DO NOT define uniqueness of the column to the dataset. For example, if you want to find the unique set of customers in a customer order table, you would only want to select the customer column rather than including the customer order number too.
Summary statistics for numeric columns
Integer and numeric columns automatically display summary statistics at the bottom of the column information. This includes:
- Min
- Max
- Mean
- Sum
- Standard Deviation
- Variance
These statistics are calculated on the full filtered dataset.
Copying Data
It is sometimes useful to allow for copying of selected data from PlaidCloud so that it can be pasted into other applications such as a spreadsheet.
From the Copy button in the upper right, there are several copy options available for the data:
- Copy All - Copies all of the data to the clipboard
- Copy Selection - Copies the selected data to the clipboard
- Copy Cell - Copies only the contents of a single cell to the clipboard
- Copy Column - Copies the full contents of the column to the clipboard
Exporting Data
Exporting data from the Table Explorer interface allows exporting of the filtered data with only the columns visible. You can export in the following formats:
- Microsoft Excel (xlsx)
- CSV (Comma)
- TSV (Tab)
- PSV (Pipe)
The Download menu also offers the ability to download only the rows visible in the browser. This is based on using the row limit specified.
Additional Actions
Additional useful actions are available under the Actions menu.
Save as Extract Step
When exploring data, it is often in the context of determining how to filter it for a data pipeline process. This often consists of applying multiple filters including advanced filters to zero in on the desired result.
Instead of attempting to replicate all the filters, columns, summarizations, and sorts in an Extract Step, you can simply save the existing Table Explorer settings as a new Extract Step.
Save as View
Similar to saving the current Table Explorer settings as an Extract Step above, you can also save the settings directly as a view.
This can be particularly useful when trying to construct slices of data for reporting or other downstream processes that don't require a a data pipeline.
Manage Saved Filters
You never have to lose your filter work. You can save your Table Explorer settings as a saved filter. Saved filters also include column visibility, summarizations, columns filters, advanced filters, and sorts.
You can also let others use a saved filter by checking the Public checkbox when saving the filter.
From the Actions menu you can also choose to delete and rename saved filters.
Advanced Filters
While point-and-click column filters allow for quick application of filters to zero in on the desired results, sometimes filter conditions are complex and need more advanced specifications.
The advanced filter area provides both a pre-aggregation filter as well as a post-aggregation filter, if Summarize is enabled.
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples.
1.2.3 - Using Dimensions (Hierarchies)
PlaidCloud natively manages dimension (i.e. hierarchical) data through our proprietary hierarchy storage system. We decided to construct our own from purpose-built solution because other commercial and open-source solutions seem to present limitations that were not easily overcome.
The hierarchy storage supports not only hierarchical relationships but also properties, aliases, attributes, and values. It is also designed to operate on large structures and perform operations quickly including complex branch and leaf navigation.
Dimensions are managed in the Dimensions tab within each PlaidCloud project configuration area.
Main Hierarchy
Each dimension (i.e. hierarchical dataset) always consists of a main hierarchy. Every member of the hierarchy is represented here.
Having a main hierarchy helps establish the complete set of leaf nodes in the dimension.
Alternate or Attribute Hierarchies
Alternate hierarchies are different representations of the main hierarchy leaf nodes. Alternate hierarchies can consist of a subset of both
leaf nodes and roll-up (i.e. folders) in the main hierarchy as well as its own set of unique roll-ups.
This provides for the maximum amount of flexibility by automatically updating alternate hierarchies when children of a roll-up change or to strictly control the alternate hierarchy members by specifying only the leaf nodes required.
main hierarchy have attribute labels showing alternate hierarchies for which they also belongManaging Dimensions
Creating a Dimension
From the New button in the toolbar, select New Dimension. Enter in the desired name, directory, and a descriptive memo.
Once you press the Create button the dimension will be created and ready for immediate use.
You can also create a dimension from a workflow using the Dimension Create workflow step.
Deleting a Dimension
To delete an existing dimension, select the dimension record and open the Actions menu in the upper right. Select Delete Dimension.
This will delete the dimension and all underlying data.
You can also delete a dimension from a workflow using the Dimension Delete workflow step.
It is also possible to clear the dimension of all structure, values, aliases, properties, and alternate hierarchies without deleting the dimension by using the Dimension Clear workflow step.
Copying a Dimension
To copy an existing dimension, select the dimension record and open the Actions menu in the upper right. Select Copy Dimension.
This will open a dialog where you can specify the name of the copy. Click the Create Copy button to make a copy of the dimension
including values, aliases, properties, and alternate hierarchies.
Sorting a Dimension
The dimension management area makes it easy to move hierarchy members up and down as well as changing parents. It also makes it easy to create and delete members.
However, it can get tedious when manually moving hierarchy items around so you can sort a dimension from a workflow using the Dimension Sort workflow step. This can be a big time saver especially after data loads or major changes.
Loading Dimensions
Since dimensions represent hierarchical data structures, the load process must convey the relationships in the data. PlaidCloud supports two different data structures for loading dimensions:
- Parent-Child - The data is organized vertically with a Parent column and Child column defining each parent of a child throughout the structure
- Levels - The data is organized horizontally with each column representing a level in the hierarchy from left to right
In addition to structure, other dimension information can be included in the load process such as values, aliases, and properties.
See the Workflow Step for Dimension Load for more information.
Dimension Property Inheritance
A dimension may inherit a property from an ancestor. To enable inheritance, click the dropdown next to Properties and select Inherited Properties. All child nodes in the dimension will now inherit the propties of its parents.
Usage Notes:
- Inheritance will happen for all properties in a dimension. You cannot set inheritance on one property but not another.
- If you change and then delete the value of a child property, it will default back to the parent value. You cannot have a null value when the parent has a value.
- If you set the value of a child property, its children will inherit the child property instead of the parent.
- Inheritance will go all the way down to the leaf node.
1.2.4 - Publishing Tables
Since data pipelines can generate many intermediate tables and views useful for validation and process checks but not suitable for final results reporting,
PlaidCloud provides a Publish process to help reduce the noise when building Dashboards or pulling data in PlaidXL. The Publish process helps clarify
which tables and views are final and reliable for reporting purposes.
Publish
From the Tables tab in a PlaidCloud project configuration, find the table you wish to publish for use in dashboards and PlaidXL. Right-click on the
table record and select Set Published Table Reporting Name from the menu.
This will open a dialog where you can specify a unique published name. This name does not need to be the same as the table or view name. Enabling a different name is often useful when referencing data sources in dashboards and PlaidXL because it can provide a friendlier name to users.
Once the table or view is published, its published name will appear in the Published As column in the Tables view.
Unpublish
Unpublishing a table or view is similar to the publish process. From the Tables tab in a PlaidCloud project configuration, find the table you wish
to publish for use in dashboards and PlaidXL. Right-click on the table record and select Set Published Table Reporting Name from the menu.
When the dialog appears to set the published name, select the Unpublish button. This will remove the table from Dashboard and PlaidXL usage.
The published name will no longer appear in the Published As column.
Renaming
Renaming a table or view is similar to the publish process. From the Tables tab in a PlaidCloud project configuration, find the table you wish
to publish for use in dashboards and PlaidXL. Right-click on the table record and select Set Published Table Reporting Name from the menu.
When the dialog appears change the publish name to the new desired name. Press the Publish button to update the name.
The updated name will now appear in the Published As column as well as in Dashboard and PlaidXL.
1.3 - Workflows
1.3.1 - Where are the Workflows
Workflows exist within a Project. From the top menu in the Analyze menu click on the Projects menu item. This will open the Projects hierarchy showing the list of projects. Open the project and navigate to the Workflows tab to see the workflows in the project. Workflows are organized in a hierarchy.
The list of projects you can see is determined by your access security for each project and your Viewing Role within the project (i.e. Architect, Manager, or Explorer). If you are expecting to see a project and it is not present, it could be that you have not been granted access to the project by one of the project owners. If you are expecting to see certain workflows, but you are not an Architect on the project, then they might be hidden from your viewing role.
The status of the workflow will be displayed if it is running, has a warning or error, or was completed normally. The creation and update dates are also shown along with who created or updated the workflow.
The Workflow Explorer can be opened by double clicking on a workflow. You can then view the steps, execute a workflow or a part of a workflow, and so on.
1.3.2 - Workflow Explorer
To view the details within a workflow, find it in the project and then double click on it to open up the workflow in the explorer.
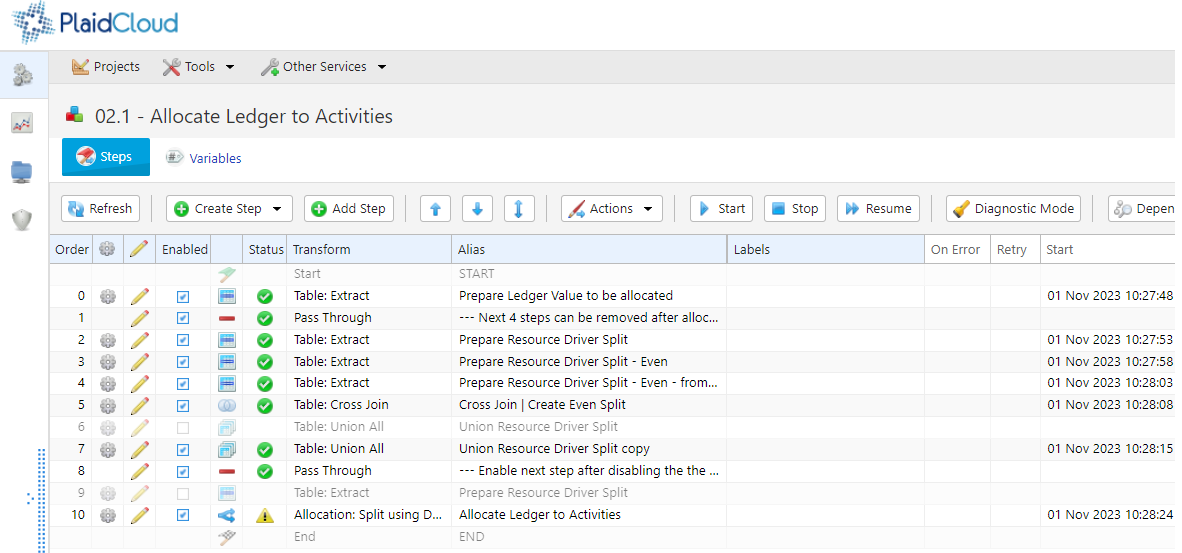
From here, you can manage Workflow Steps including creating or modifying existing workflow steps, changing the order, executing steps, and so on.
1.3.3 - Create Workflow
Once you navigate to the Workflows tab in a project, click on the New Workflow button. This will open a form where you can enter in the details of the workflow including the name and memo.
In addition, you can set a remediation workflow to run if the workflow ends in an error. A remediation workflow does not need to be set but can be useful for sending notifications or triggering other processes that may automatically remediate failures.
Once the form is complete, click on the Create button and the new workflow will be added to the project.
1.3.4 - Duplicate a Workflow
It may be useful to copy a workflow when planning to make major changes or to replicate the process with different options. Duplicating an entire workflow is very easy in PlaidCloud. Simply select the workflows you would like to duplicate in the Workflows table of a selected project and click the Duplicate Selected Workflows button at the top of the table. This will copy the workflows and append the word Copy to the name.
Once the duplication process is complete, the workflow is fully functional. Copied workflows are completely separate from the original and can be modified without impacting the original workflow.
1.3.5 - Copy & Paste steps
Copy Steps
It is often useful to copy steps instead of starting from scratch each time. PlaidCloud allows copying steps within workflows as well as between workflows, and even in other projects. You can select multiple steps to copy at once. Select the workflow steps within the hierarchy and click the Copy Selected Steps button at the top of the table.
This will place the selected steps in the clipboard and allow pasting within the current workflow or another one.
Copying a step will make a duplicate step within the project. If you want to place the same step in more than one location in a workflow, use the Add Step menu option to add a reference to the same step rather than a clone of the original step.
Paste Steps
After selecting steps to copy and placing them on the clipboard, you can paste those steps into the same workflow or another workflow, even in another project. There are two options when pasting the steps into the workflow:
- Append to the end of the workflow
- Insert after last selected row
The append option will simply append the steps to the end of the selected workflow. The insert option will insert the copied steps after the selected row. Note that if multiple steps have been copied to the clipboard from multiple areas in a workflow, that pasting them will paste them in order but will not have any nested hierarchy information from when they were copied. The pasting will be a flat list of steps to insert only. This might be unexpected but is safer than creating all of the directory structure in the target workflow that existed in the source workflow.
1.3.6 - Change the order of steps in a workflow
There are two ways to update the order of steps in the workflow. The first way is to use the up and down arrows present in the Workflows table to move the step up or down. The second way is to use the Step Move option which allows you to move the step much easier if large changes are necessary. The step move option allows you to move the step to the top, bottom, or after a specific step in one operation.
1.3.7 - Run a workflow
You can trigger a full workflow run by either clicking on the run icon from the Workflows hierarchy or by selecting Run All from the Actions menu within a specific workflow.
You can also click on the Toggle Start/Stop button at the top of the workflow table. This toggle button will stop a running workflow or start a workflow.
1.3.8 - Running one step in a workflow
During initial workflow development, testing, or troubleshooting, it is often useful to run steps individually. To run a single step in isolation, right click on the step and select Run Step from the context menu.
1.3.9 - Running a range of steps in a workflow
While running individual steps is useful, it also may be useful to run subsets of an entire workflow for development, testing, or troubleshooting. To run a subset of steps, select all the steps you would like to run and select Run Selected from the Actions menu at the top of the workflow steps hierarchy. This will trigger a normal workflow processing but start the workflow at the beginning of the selected steps and stop once the last selected step is complete.
1.3.10 - Managing Step Errors
If a workflow experiences an error during processing, an error indicator is displayed on both the workflow and the step that had the error. PlaidCloud can retry a failed step multiple times. This is often useful if the step is accessing remote systems or data that may not be highly available or intermittently fail for unknown reasons. The retry capability can be set to retry many times as well as add a delay between retries from seconds to hours.
If no retry is selected or the maximum number of retries is exceeded, then the step will be marked as an error. PlaidCloud provides three levels of error handling in that case:
- Stop the workflow when an error occurs
- Mark the step as an error but keep processing the workflow
- Mark the step as an error and trigger a remediation workflow process instead of continuing the current workflow
Stop the Workflow
Stopping the workflow when a step errors is the most common approach since workflows generally should run without errors. This will stop the workflow and present the error indicator on both the step and the workflow. The error will also be displayed in the activity monitor but no further action is taken.
Keep Processing
Each step can be set to continue on error in the step form. If this checkbox is enabled, then any step will be marked with an error if it occurs, but the workflow will treat the error as a completion of the step and continue on. This is often useful if there are steps that perform tasks that can error when there is missing data but are harmless to the overall processes.
Since the workflow is continuing on error under this scenario the workflow will not display an error indicator and continue to show a running indicator.
Trigger Remediation Workflow
With the ability to set a remediation workflow as part of the workflow setup, a workflow error will immediately stop the processing of the current workflow and start processing the remediation workflow. Note that if a step is marked to continue on error that a failure will not trigger the remediation workflow. Only steps that fail that would also cause the entire workflow to stop will trigger the remediation process.
A remediation workflow may be useful for simply notifying people that a failure has occurred or it can perform other complex processing to attempt an automatic correction of any underlying reasons the original workflow failed.
1.3.11 - Continue on Error
Workflow steps can be set to continue processing even when there is an error. This might be useful in workflow start-up conditions or where data may be available intermittently. If the step errors, it will be recorded as an error but the workflow will continue to process.
To set this option, click on the step edit option, the pencil icon in the workflow table, to open the edit form. Check the checkbox for Continue On Error. After saving the updated step, any errors with the step will not cause the workflow to stop.
Steps that have been set to continue on error will have a special indicator in the workflow steps hierarchy table.
1.3.12 - Skip steps in a workflow
Steps in the workflow can be set to skip during the workflow run. This may be useful if there are debugging steps or old steps that you are not prepared to completely remove from the workflow yet. To set this option, you have two options:
- Edit the step form
- Uncheck the enabled checkbox in the workflow hierarchy
To edit the step form, click on the step edit option, the pencil icon in the workflow table, to open the edit form. Uncheck the enabled checkbox. After saving the updated step it will no longer run as part of the workflow but can still be run using the single step run process.
Steps that have been set to disabled will have a disabled indicator in the workflow steps hierarchy table.
1.3.13 - Conditional Step Execution
Overview
Workflow steps normally execute in the defined order for the workflow. However, it is often useful to have certain steps only execute if predefined conditions are met. By using the step conditions capability you can control execution based on the following options:
- Variable values
- Table has rows or is empty
- A document or folder exists in Document
- A document or folder is missing in Document
- Table query result
- Date and time conditions are met
For variables or table query result comparisons you can use the following comparisons:
- Equal
- Does not equal
- Contains
- Does not contain
- Starts with
- Ends with
- Greater than
- Less than
- Greater than or equal
- Less than or equal
What is also important to note is that you can have multiple conditions that must be met in order for the step to execute. This provides a powerful tool for controlling exactly when a step should execute.
Adding and Controlling Conditions
To activate and add conditions on a step:
- Find the step you want to add a condition on
- Click the Edit Step Details (pencil) icon
- Select the Conditions tab.
- Check the Check Conditions Before Running checkbox to enable the dialog and add conditions.
- In the Condition Checks section on the left, select the "+" to add a New Condition
- Add a condition from the tabbed section on the right
- Repeat steps 5,6 as needed to add all your conditions
Managing Conditions
You can add as many conditions as necessary in the Conditions Check section. As you add them, it is a good idea to give them a useful name so you can find the conditions easily in the future.
Once you add a condition, select it on the left and the condition evaluation criteria will be editable on the right.
Variable Conditions
When checking variable conditions, the Value Check Parameters section must be completed so a comparison can be made.
In the Variable or Table Field fill in the variable name. Select a comparison type and enter a comparison value.
Basic Table Conditions
If the condition is checking whether a table has rows or is empty, you will also need to define the table in the Table Data Selection tab.
Advanced Table Conditions
When using Advanced Table conditions, the Value Check Parameters section must be completed so a comparison can be made.
In the Variable or Table Field fill in the field name from the table selection. Select a comparison type and enter a comparison value.
In the Table Data Selection tab, select the table and complete the data mapping section with at least the field referenced for the condition comparison.
Document Path Conditions
If the condition is checking whether a document or folder exists, this requires picking the Document account and specifying the document path to check in the Document Path tab.
Date and Time Conditions
For Date or Time selections you can add multiple conditions if a combination of conditions is necessary. For example, if you only wanted a step to run on Mondays at 2:05am, you would create three conditions:
- Day of the week condition set to Monday (1)
- Hour of the day set to 2
- Minute of the hour set to 5
For "Use Financial Close Workday", set that to the xth day of the month that your close happens on. For example, if your close happens on the 5th day of the month, have "5".
1.3.14 - Controlling Parallel Execution
Workflows in PlaidCloud can be executed as a combination of serial steps and parallel operations. To set a group of steps to run in parallel, place the steps in a group within the workflow hierarchy. Right click on the group folder and select the Execute in Parallel option. This will allow all the steps in the group to trigger simultaneously and execute in parallel. Once all steps in the group complete, the next step or group in the workflow after the group will activate.
1.3.15 - Manage Workflow Variables
PlaidCloud allows variables at both the project scope and workflow scope. This allows for setting project wide variables or being able to pass information easily between workflows. The variables and values are viewed by clicking on the variables icon in the Workflows hierarchy.
From the variables table you can view the variables, the current values, and edit the values. You can also add new variables or delete existing ones.
1.3.16 - Viewing Workflow Log
Viewing the Workflow Log
As things happen within a workflow, such as steps running or warnings occurring, those events are logged to the workflow log. This log is viewable from the Project area under the Log tab. The workflow log is also present in the project log in case you would like to see a more comprehensive view of logs across multiple workflows.
The log viewer allows for sorting and filtering the log as well as viewing the details of a particular log entry.
Clearing the Workflow Log
Clearing the workflow log may be desirable from time to time. From the log viewer, select the Clear Log button. This will clear the log based on the workflow selected which will also remove the log entries from the project level log too.
1.3.17 - View Workflow Report
Maintaining detailed documentation to support both statutory and management requirements is challenging when the projects and workflows may be dynamic. To help solve this problem, PlaidCloud provides a Workflow level report that provides detailed documentation of workflows, workflow steps, user defined functions, and variables.
The report is generated on-demand and reflects the current state of the workflow. To download the report click on the Report icon in the Workflows hierarchy.
1.3.18 - View a dependency audit
The Workflow Dependency Audit is a very helpful tool to understand data and workflow dependencies in complex interconnected workflows. Over time, as workflow processes become more complex, it may become challenging to ensure all dependencies are in the correct order. When data already exists in tables, steps will run and appear correct in many cases but may actually have a dependency issue if the data is populated out of order.
This tool will provide a dependency audit and identify issues with data dependency relationships.
1.4 - Workflow Steps
1.4.1 - Workflow Control Steps
1.4.1.1 - Create Workflow
Description
Create a new PlaidCloud Analyze workflow.
Workflow to Create
First, select the Project in which the new workflow should be created from the dropdown menu.
Next, type in a workflow name. The name should be unique to the Project.
Examples
No examples yet...
1.4.1.2 - Run Workflow
Description
“Run Workflow” runs an existing workflow.
Workflow to Run
First, select the Project which contains the workflow to be run from the Project dropdown menu.
Next, select the particular workflow to be run from the Workflow dropdown menu.
Additionally, there is an option to Wait until processing completes before continuing. Selecting this checkbox will defer execution of the current workflow until the called workflow is completed with its execution. By default, this option is disabled, meaning that the current workflow in which this transform resides will continue processing in parallel along with the called workflow.
Examples
No examples yet...
1.4.1.3 - Stop Workflow
Description
“Stop Workflow” stops an existing, running workflow.
Workflow to Stop
First, select the Project which contains the workflow to be stopped from the Project dropdown menu.
Next, select the particular workflow to be stopped from the Workflow dropdown menu.
Examples
No examples yet...
1.4.1.4 - Copy Workflow
Description
Make a copy of an existing PlaidCloud Analyze workflow.
Workflow to Copy
First, select the Project which contains the workflow to be copied from the Project dropdown menu.
Next, select the particular workflow to be copied from the Workflow dropdown menu.
Next, enter the new workflow name into the New Workflow field. Remember: the name should be unique to the Project.
Examples
No examples yet...
1.4.1.5 - Rename Workflow
Description
Rename an existing PlaidCloud Analyze workflow.
Workflow to Rename
First, select the Project which contains the workflow to be renamed from the Project dropdown menu.
Next, select the particular workflow to be renamed from the Workflow dropdown menu.
Finally, enter the new workflow name in the Rename To field. Remember that the name should be unique to the Project.
Examples
No examples yet...
1.4.1.6 - Delete Workflow
Description
Delete an existing PlaidCloud Analyze workflow.
Workflow to Delete
First, select the Project which contains the workflow to be deleted from the Project dropdown menu.
Next, select the particular workflow to be deleted from the Workflow dropdown menu.
Examples
No examples yet...
1.4.1.7 - Set Project Variable
Description
“Set Project Variable” sets project variables for use during the workflow. A variable name and value may contain any combination of valid characters, including spaces. Variables are referenced within the workflow by placing them inside curly braces. For example, a_variable is referenced within a transform as {a_variable} so it could be used in something like a formula or field value (e.g., {a_variable} * 2).
Variable List
The table will display the list of registered project variables and the current values. Enter the value for the variable desired. It’s also possible to set variable values without registering the variable first by simply adding the variable to the list.
Examples
No examples yet...
1.4.1.8 - Set Workflow Variable
Description
“Set Workflow Variable” sets workflow variables for use during the workflow. A variable name and value may contain any combination of valid characters, including spaces. Variables are referenced within the workflow by placing them inside curly braces. For example, a_variable is referenced within a transform as {a_variable} so it could be used in something like a formula or field value (e.g. {a_variable} * 2).
Variable List
The table will display the list of registered workflow variables and the current values. Enter the value for the variable desired. It’s also possible to set variable values without registering the variable first by simply adding the variable to the list.
Examples
No examples yet...
1.4.1.9 - Worklow Loop
Description
Loops over a dataset and runs a specific workflow using the values of the looping dataset as Project variables.
Workflow to Stop
First, select the Project which contains the workflow that will be run on each loop from the Project dropdown menu.
Next, select the particular workflow for running from the Workflow dropdown menu.
Examples
Examples coming soon
1.4.1.10 - Raise Workflow Error
Description
Raise an error in a PlaidCloud Analyze workflow.
Raise Workflow Error
Mainly for use with step conditions, the step can be set to execute if conditions are met and raise an error within the workflow
1.4.1.11 - Clear Workflow Log
Description
Clear the log from an existing PlaidCloud Analyze workflow.
Workflow Log to Clear
First, select the Project which contains the workflow log to be cleared from the Project dropdown menu.
Next, select the particular workflow log to be cleared from the Workflow dropdown menu.
1.4.2 - Import Steps
1.4.2.1 - Import Archive
Description
Imports PlaidCloud table archive.
Examples
No examples yet...
Import Parameters
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Source Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
Source FilePath
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
1.4.2.2 - Import CSV
Description
Import delimited text files from PlaidCloud Document. This includes, but is not limited to, the following delimiter types:
- comma (, )
- pipe (|)
- semicolon (; )
- tab
- space ( )
- at symbol (@)
- tilda (~)
- colon (:)
Examples
No examples yet...
Import Parameters
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Source Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
Source FilePath
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Inspect Selected Source File
By pressing the Guess Settings from Source File button, PlaidCloud will open the file and inspect it to attempt to determine the data format. Always check the guessed settings to make sure they seem correct.
Data Format
Delimiter
As mentioned above, Inspect Source File will attempt to determine the delimiter in the source file. If another delimiter is desired, use this section to specify the delimiter. Users can choose from a list of standard delimiters.
- comma (, )
- pipe (|)
- semicolon (; )
- tab
- space ( )
- at symbol (@)
- tilda (~)
- colon (:)
Header Type
Since CSVs may or may not contain headers, PlaidCloud provides a way to either use the headers, ignore headers, or use column order to determine the column alignment.
- No Header: The CSV file contains no header. Use the source list in the Data Mapper to determine the column alignment
- Has Header - Use Header and Override Field List: The CSV file has a header. Use the header names specified and ignore the source list in the Data Mapper.
- Has Header - Skip Header and Use Field List Instead: The CSV file has a header but it should be ignored. Use the header names specified by the source list in the Data Mapper.
Date Format
This setting is useful if the dates contained in the CSV file are not readily recognizable as dates and times. The import process attempts to convert dates but having a little extra information can help in the import process.
Special Characters
The special character inputs control how PlaidCloud handles the presence of certain characters and what they mean in the context of processing the CSV
- Quote Character: This is the character used to indicate an enclosed set of text that should be processed as a single field
- Escape Character: This is the character used to indicate the following character should be processed as it is and not interpreted as a special character. Useful when field may contain the delimiter.
- Null Character: Since CSVs don't have data types, this character provides a way to indicate that the value should be NULL rather than an empty string or 0.
- Trailing Negatives: Some source systems generate negative numbers with trailing negative symbols instead of prefixing the negative. This setting will process those as negative numbers.
Row Selection
For input files with extraneous records, you can specify a number of rows to skip before processing the data. This is useful if files contain header blocks that must be skipped before arriving at the tabular data.
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.2.3 - Import Excel
Description
Import specific worksheets from Microsoft Excel files from PlaidCloud Document. Analyze supports the legacy Excel format (XP/2003) as well as the new format (2007/2010/2013). This includes, but is not limited to, the following file types:
- XLS
- XLSX
- XLSB
- XLSM
Examples
No examples yet...
Import Parameters
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Source Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
Source FilePath
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Header
Since Excel files may or may not contain headers, PlaidCloud provides a way to either use the headers, ignore headers, or use column order to determine the column alignment.
- No Header: The file contains no header. Use the source list in the Data Mapper to determine the column alignment
- Has Header - Use Header and Override Field List: The file has a header. Use the header names specified and ignore the source list in the Data Mapper.
- Has Header - Skip Header and Use Field List Instead: The file has a header but it should be ignored. Use the header names specified by the source list in the Data Mapper.
Row Selection
For input files with extraneous records, you can specify a number of rows to skip before processing the data. This is useful if files contain header blocks that must be skipped before arriving at the tabular data.
Worksheets to Import
Because workbooks may contain many worksheets with different data, it is possible to select which worksheets should be imported in the current import process. The options are:
- All Worksheets
- Worksheets Matching Search
- Selected Worksheets
Using Worksheet Search
The search functionality for worksheets allows inclusion of worksheets matching the search criteria. The search criteria allows for:
- Starts With: The worksheet name starts with the search text
- Contains: The worksheet name contains the search text
- Ends With: The worksheet name ends with the search text
Find Sheets in Selected File
The find sheets button will open the Excel file and list the worksheets available in the table. Mark the checkboxes in the table for the worksheets to be included in the import.
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.2.4 - Import External Database Tables
Description
Includes ability to perform delta loads and map to alternate target table names.
Examples
No examples yet...
Unique Configuration Items
None
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.2.5 - Import Fixed Width
Description
Imports fixed-width files.
Examples
No examples yet…
Import Parameters
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Source Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
Source FilePath
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Header
Since Excel files may or may not contain headers, PlaidCloud provides a way to either use the headers, ignore headers, or use column order to determine the column alignment.
- No Header: The file contains no header. Use the source list in the Data Mapper to determine the column alignment
- Has Header - Use Header and Override Field List: The file has a header. Use the header names specified and ignore the source list in the Data Mapper.
- Has Header - Skip Header and Use Field List Instead: The file has a header but it should be ignored. Use the header names specified by the source list in the Data Mapper.
Row Selection
For input files with extraneous records, you can specify a number of rows to skip before processing the data. This is useful if files contain header blocks that must be skipped before arriving at the tabular data.
Column Widths
Enter the widths of the columns seperated with commas or spaces.
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.2.6 - Import Google BigQuery
Description
Import Google BigQuery files.
Examples
No examples yet...
Unique Configuration Items
Coming soon...
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.2.7 - Import Google Spreadsheet
Description
Import specific worksheets from Google Spreadsheet files.
Examples
No examples yet...
Import Parameters
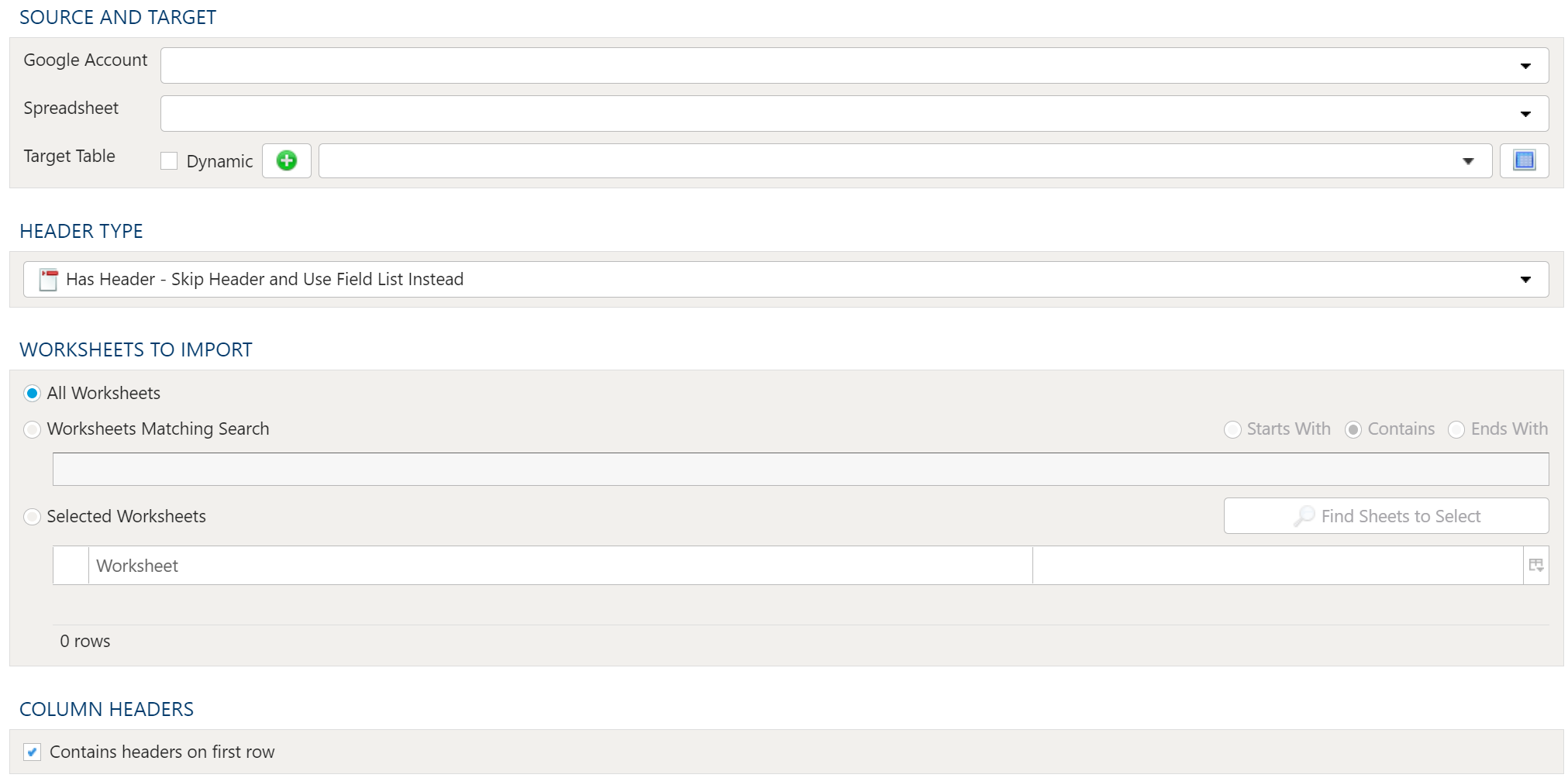
Source And Target
Google Account
Accessing Google Spreadsheet data requires a valid Google user account. This requires set up in Tools. For details on setting up a Google account connection, see here: PlaidCloud Tools – Connection.
Once all necessary accounts have been set up, select the appropriate Google Account from the drop down list.
Spreadsheet
Next, specify the Spreadsheet to import from the dropdown menu containing all available files associated with the specified Google Account.
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Header Type
Since Google Spreadsheets may or may not contain headers, PlaidCloud provides a way to either use the headers, ignore headers, or use column order to determine the column alignment.
- No Header: The file contains no header. Use the source list in the Data Mapper to determine the column alignment
- Has Header - Use Header and Override Field List: The file has a header. Use the header names specified and ignore the source list in the Data Mapper.
- Has Header - Skip Header and Use Field List Instead: The file has a header but it should be ignored. Use the header names specified by the source list in the Data Mapper.
Worksheets to Import
Because workbooks may contain many worksheets with different data, it is possible to select which worksheets should be imported in the current import process. The options are:
- All Worksheets
- Worksheets Matching Search
- Selected Worksheets
Using Worksheet Search
The search functionality for worksheets allows inclusion of worksheets matching the search criteria. The search criteria allows for:
- Starts With: The worksheet name starts with the search text
- Contains: The worksheet name contains the search text
- Ends With: The worksheet name ends with the search text
Find Sheets in Selected File
The find sheets button will open the Excel file and list the worksheets available in the table. Mark the checkboxes in the table for the worksheets to be included in the import.
Column Headers
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.2.8 - Import HDF
Description
Import HDF5 files from PlaidCloud Document.
For more details on HDF5 files, see the HDF Group’s official website here: http://www.hdfgroup.org/HDF5/.
Examples
No examples yet...
Unique Configuration Items
Key Name
HDF files store data in a path structure. A key (path) is needed as the destination for the table within the HDF file. In most situations, this will be table.
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.2.9 - Import HTML
Description
Import HTML table data from the internet.
Examples
No examples yet...
Unique Configuration Items
Select Tables in HTML
Since it is possible to have multiple tables on a web page, the user must specify which table to import. To do so, specify Name and/or Attribute values to match.
For example, consider the following table:
<table border="1" id="import"> <tr> <th>Hello</th><th>World</th> </tr> <tr> <td>1</td><td>2</td> </tr> <tr> <td>3</td><td>4</td> </tr> </table>
To import this table, specify id:import in the Name Match field.
Additionally, there is an option to skip rows at the beginning of the table.
Column Headers
Specify the row to use for header information. By default, the Column Header Row is 0.
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.2.10 - Import JSON
Description
Import JSON text files from PlaidCloud Document.
For more details on JSON files, see the JSON official website here: http://json.org/.
JSON files do not retain column order. The column order in the source file does not necessarily reflect the column order in the imported data table.
Examples
No examples yet...
Unique Configuration Items
JSON Data Orientation
Consider the following data set:
| ID | Name | Gender | State | | 1 | Jack | M | MO | | 2 | Jill | F | MO | | 3 | George | M | VA | | 4 | Abe | M | KY |
JSON files can be imported from one of three data formats:
- Records: Data is stored in Python dictionary sets, with each row stored in {Column -> Value, …} format. For example:
[{ "ID": 1, "Name": "Jack", "Gender": "M", "State": "MO" }, { "ID": 2, "Name": "Jill", "Gender": "F", "State": "MO" }, { "ID": 3, "Name": "George", "Gender": "M", "State": "VA" }, { "ID": 4, "Name": "Abe", "Gender": "M", "State": "KY" }]
- Index: Data is stored in nested Python dictionary sets, with each row stored in {Index -> {Column -> Value, …},…} format. For example:
{ "0": { "ID": 1, "Name": "Jack", "Gender": "M", "State": "MO" }, "1": { "ID": 2, "Name": "Jill", "Gender": "F", "State": "MO" }, "2": { "ID": 3, "Name": "George", "Gender": "M", "State": "VA" }, "3": { "ID": 4, "Name": "Abe", "Gender": "M", "State": "KY" } }
- Split: Data is stored in a single Python dictionary set, values stored in lists. For example:
{ "columns": ["ID", "Name", "Gender", "State"], "index": [0, 1, 2, 3], "data": [ [1, "Jack", "M", "MO"], [2, "Jill", "F", "MO"], [3, "George", "M", "VA"], [4, "Abe", "M", "KY"] ] }
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.2.11 - Import Project Table
Description
Import table data from a different project.
Data Sharing Management

In order to import a table from another project you must first go to both projects Home Tab and allow the projects to share data with each other. To do this select New Data Share and select the project and give them Read access.
Import External Project Table
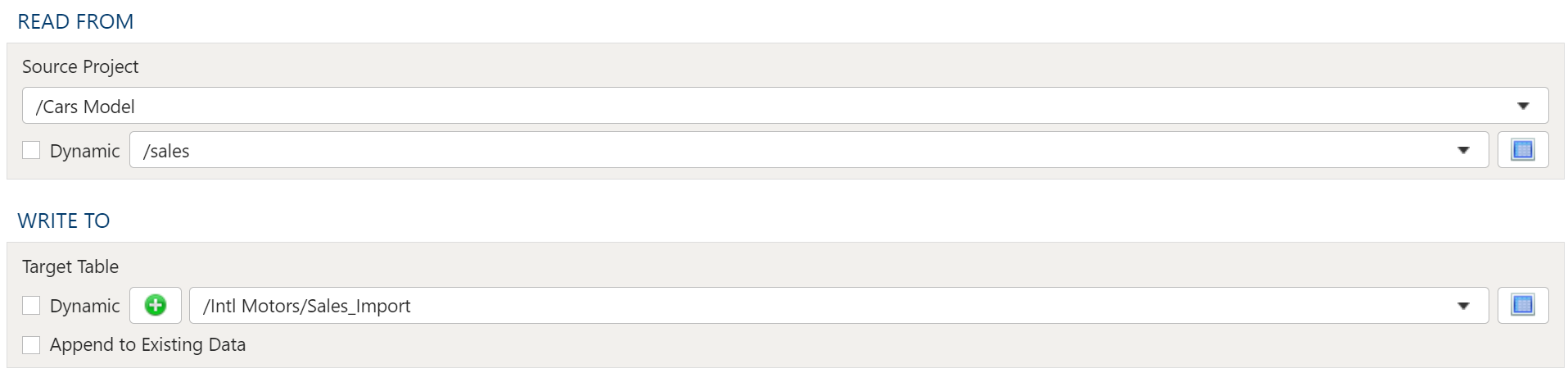
Read From
Select the Source Project and Source Table from the drop downs.
Write To
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
1.4.2.12 - Import Quandl
Description
Imports data sets from Quandl’s repository of millions of data sets.
For more details on Quandl data sets, see the Quandl official website here: http://www.quandl.com/.
Examples
No examples yet...
Unique Configuration Items
Source Data Specification
Accessing Quandl data sets requires a user account or a guest account with limited access. This requires set up in Tools. For details on setting up a Quandl account connection, see here: PlaidCloud Tools – Connection.
Once all necessary accounts have been set up, select the appropriate account from the drop down list.
Next, enter criteria for the desired Quandl code. Users can use the Search functionality to search for data sets. Alternatively, data sets can be entered manually. This requires the user to enter the portion of the URL after “http://www.quandl.com”.
For example, to import the data set for Microsoft stock, which can be found here (http://www.quandl.com/GOOG/NASDAQ_MSFT), enter GOOG/NASDAQ_MSFT in the Quandl Code field.
Data Selection
It is possible to slice Quandl data sets upon import. Available options include the following:
- Start Date: Use the date picker to select the desired date.
- End Date: Use the date picker to select the desired date.
- Collapse: Aggregate results on a daily, weekly, monthly, quarterly, or annual basis. There is no aggregation by default.
- Transformation: Summary calculations.
- Limit Rows: The default value of 0 returns all rows. Any other positive integer value will specify the limit of rows to return from the data set.
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.2.13 - Import SAS7BDAT
Description
Import SAS table files from PlaidCloud Document.
Examples
No examples yet...
Unique Configuration Items
None
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.2.14 - Import SPSS
Description
Import SPSS sav and zsav files from PlaidCloud Document.
Examples
No examples yet...
Unique Configuration Items
None
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.2.15 - Import SQL
Description
Import data from a remote SQL database.
Import Parameters
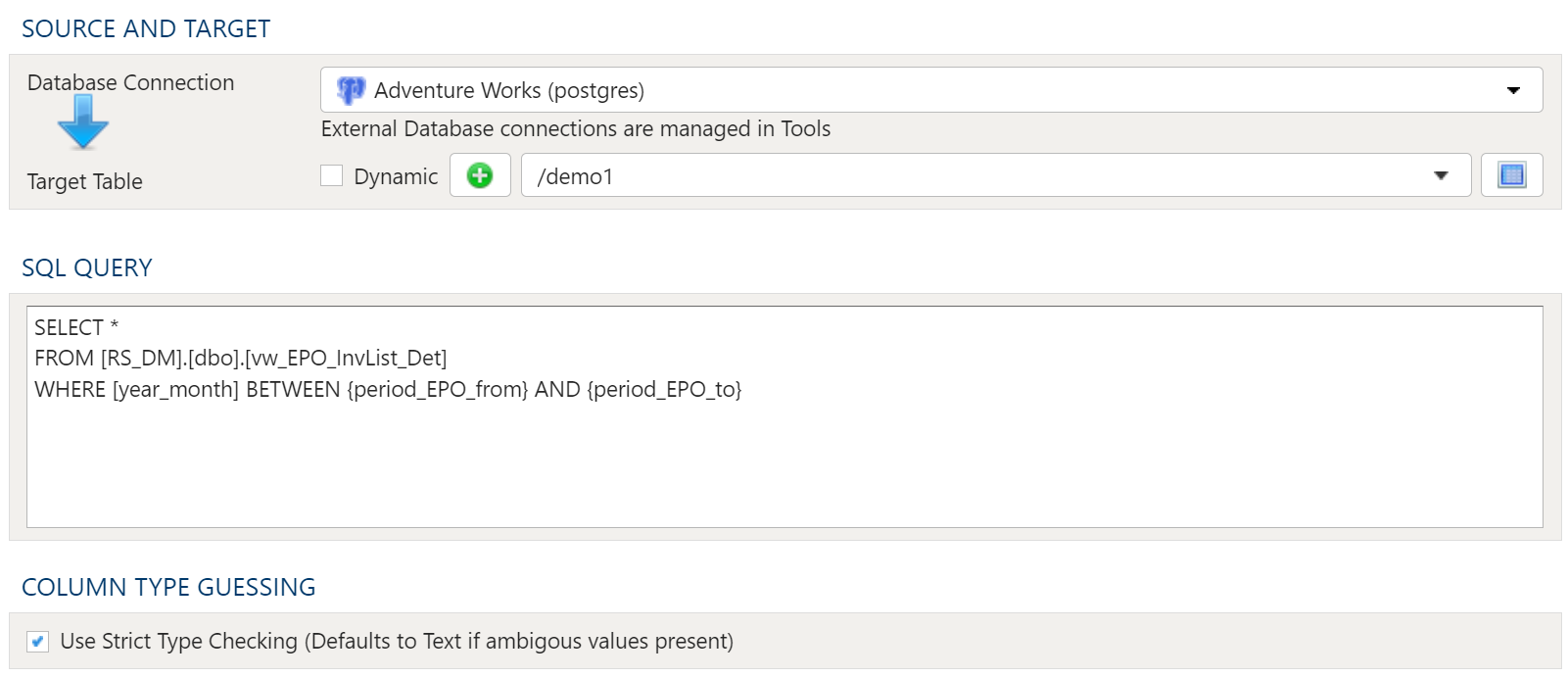
Source And Target
Database Connection
To establish a Database Connection please refer to PlaidCloud Data Connections
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
SQL Query
In this section write the SQL query to return the required data.
Column Type Guessing
SQL Imports have the option of attempting to guess the data type during load, or to set all columns to type Text. Setting the data types dynamically can be quicker if the data is clean, but can cause issues in some circumstances.
For example, if most of the data appears to be numeric but there is some text as well, it may try to set it as numeric causing load issues with mismatched data types. Or there could be issues if there is a numeric product code that is 16 digits, for example. It would crop the leading zeroes resulting in a number instead of a 16 digit code.
Setting the data to all text, however, requires a subsequent Extract step to convert any data types that shouldn't be text to the appropriate type, like dates or numerical values.
1.4.2.16 - Import Stata
Description
Import Stata files from PlaidCloud Document.
Examples
No examples yet...
Unique Configuration Items
None
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.2.17 - Import XML
Description
Import XML data as an XML file.
Examples
No examples yet...
Unique Configuration Items
None
Common Configuration Items
Remove non-ASCII Characters Option
By selecting this option, the import will remove any content that is not ASCII. While PlaidCloud fully supports Unicode (UTF-8), real-world files can contain all sorts of encodings and stray characters that make them challenging to process.
If the content of the file is expected to be ASCII only, checking this box will help ensure the import process runs smoothly.
Delete Files After Import Option
This option will allow the import process to delete the file from the PlaidCloud Document account after a successful import has completed.
This can be useful if the import files are generated can be recreated from a system of record or there is no reason to retain the raw input files once they have been processed.
Import File Selector
The file selector in this transform allows you to choose a file stored in a PlaidCloud Document location for import.
You can also choose a directory to import and all files within that directory will be imported as part of the transform run.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory or file in the next selection.
Search Option
The Search option allows for finding all matching files below a specified directory path to import. This can be particularly useful if many files need to be included but they are stored in nested directories or are mixed in with other files within the same directory which you do not want to import.
The search path selected is the starting directory to search under. The search process will look for all files within that directory as well as sub-directories that match the search conditions specified. Ensure the search criteria can be applied to the files within the sub-directories too.
The search can be applied using the following conditions:
- Exact: Match the search text exactly
- Starts With: Match any file that starts with the search text
- Contains: Match any file that contains the search text
- Ends With: Match any file that ends with the search text
File or Directory Selection Option
When a specific file or directory of files are required for import, picking the file or directory is a better option than using search.
To select the file or directory, simply use the browse button to pick the path for the Document account selected above.
Variable Substition
For both the search option and specific file/directory option, variables can be used with in the path, search text, and file names.
An example that uses the current_month variable to dynamically point to the correct file:
legal_entity/inputs/{current_month}/ledger_values.csv
Target Table
The target selection for imports is limited to tables only since views do not contain underlying data.
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the target for the import, leave the Dynamic box unchecked and select the target Table.
If the target Table does not exist, select the Create new table button to create the table in the desired location.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.3 - Export Steps
1.4.3.1 - Export to CSV
Description
Export an Analyze data table to PlaidCloud Document as a CSV delimited file.
Export Parameters
Export File Selector

The file selector in this transform allows you to choose a destination store the exported result in a PlaidCloud Document.
You choose a directory and specify a file name for the target file.
Source Table
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to source table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the source for the export, leave the Dynamic box unchecked and select the source table.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory next selection.
Target Directory Path
Select the Browse icon to the right of the Target Directory Path and navigate to the location you want the file saved to.
Target File Name
Specify the name the exported file should be saved as.
Selecting File Compression
All exported files are uncompressed, but the following compression options are available:
- No Compression
- Zip
- GZip
- BZip2
Data Format

Delimiter
The Export CSV transform is used to export data tables into delimited text files saved in PlaidCloud Document. This includes, but is not limited to, the following delimiter types:
Excel CSV (comma separated)
Excel TSV (tab separated)
User Defined Separator –>
- comma (,)
- pipe (|)
- semicolon (;)
- tab
- space ( )
- other/custom (tilde, dash, etc)
To specify a custom delimiter, select User Defined Separator –> and then Other –>, and type the custom delimiter into the text box.
Special Characters
The Special Characters section allows users to specify how to handle data with quotation marks and escape characters. Choose from the following settings:
- Special Characters (QUOTE_MINIMAL): Quote fields with special characters (anything that would confuse a parser configured with the same dialect and options). This is the default setting.
- All (QUOTE_ALL): Quote everything, regardless of type.
- Non-Numeric (QUOTE_NONNUMERIC): Quote all fields that are not integers or floats. When used with the reader, input fields that are not quoted are converted to floats.
- None (QUOTE_NONE): Do not quote anything on output. Quote characters are included in output with the escape character provided by the user. Note that only a single escape character can be provided.
Write Header To First Row
If this checkbox is selected the table headers will be exported to the first row. If it is not there will be no headers in the exported file.
Include Data Types In Headers
If this checkbox is selected the headers of the exported file will contain the data type for the column.
Windows Line Endings
Lastly, the Use Windows Compatible Line Endings checkbox is selected by default to ensure compatibility with Windows systems. It is advisable to leave this setting on unless working in a unix-only environment.
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
1.4.3.2 - Export to Excel
Description
Export an Analyze data table to PlaidCloud Document as a Microsoft Excel file. PlaidCloud Analyze supports modern versions of Microsoft Excel (2007-2016) as well as legacy versions (2000/2003).
Export Parameters
Export File Selector
The file selector in this transform allows you to choose a destination store the exported result in a PlaidCloud Document.
You choose a directory and specify a file name for the target file.
Source Table
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to source table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the source for the export, leave the Dynamic box unchecked and select the source table.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory next selection.
Target Directory Path
Select the Browse icon to the right of the Target Directory Path and navigate to the location you want the file saved to.
Target File Name
Specify the name the exported file should be saved as.
Target Sheet Name
Specify the target sheet name, the default is Sheet1
Selecting File Compression
All exported files are uncompressed, but the following compression options are available:
- No Compression
- Zip
- GZip
- BZip2
Write Header To First Row
If this checkbox is selected the table headers will be exported to the first row. If it is not there will be no headers in the exported file.
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
1.4.3.3 - Export to External Project Table
Description
Export data from a project table to different project's table.
Data Sharing Management
In order to export a table to another project you must first go to both projects Home Tab and allow the projects to share data with each other. To do this select New Data Share and select the project and give them Read access.
Export External Project Table
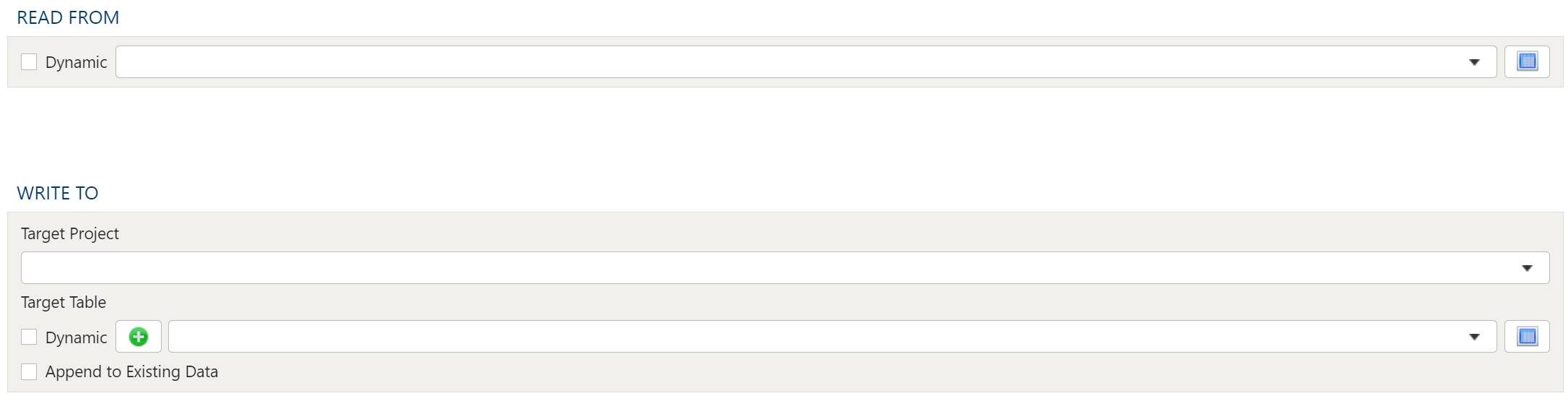
Read From
Select the Source Table from the drop down menu.
Write To
Target Project
Select the Target Project from the drop down menu.
Target Table Static
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Target Table Dynamic
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to target table:
legal_entity/inputs/{current_month}/ledger_values
Append to Existing Data
To append the data from the source table to the target table select the Append to Existing Data check box.
1.4.3.4 - Export to Google Spreadsheet
Description
Export an Analyze data table to Google Drive as a Google Spreadsheet. A valid Google account is required to use this transform. User credentials must be set up in PlaidCloud Tools prior to using the transform.
Export Parameters
Source and Target
Select the Source Table from PlaidCloud Document using the dropdown menu.
Next, specify the Target Connection information. For details on setting up a Google Docs account connection, see here: PlaidCloud Tools – Connection. Once all necessary accounts have been set up, select the appropriate account from the dropdown list.
Finally, provide the Target Spreadsheet Name and Target Worksheet Name. If desired, select the Append data to existing Worksheet data checkbox to append data to an existing Worksheet. If the target worksheet does not yet exist, it will be created.
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
1.4.3.5 - Export to HDF
Description
Export an Analyze data table to PlaidCloud Document as an HDF5 file.
For more details on HDF5 files, see the HDF Group’s official website here: http://www.hdfgroup.org/HDF5/.
Export Parameters
Export File Selector
The file selector in this transform allows you to choose a destination store the exported result in a PlaidCloud Document.
You choose a directory and specify a file name for the target file.
Source Table
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to source table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the source for the export, leave the Dynamic box unchecked and select the source table.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory next selection.
Target Directory Path
Select the Browse icon to the right of the Target Directory Path and navigate to the location you want the file saved to.
Target File Name
Specify the name the exported file should be saved as.
Output File Type
All exported files are uncompressed, but the following compression options are available:
- Zip
- GZip
- BZip2
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
1.4.3.6 - Export to HTML
Description
Export an Analyze data table to PlaidCloud Document as an HTML file. The resultant HTML file will simply contain a table.
Export Parameters
Export File Selector
The file selector in this transform allows you to choose a destination store the exported result in a PlaidCloud Document.
You choose a directory and specify a file name for the target file.
Source Table
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to source table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the source for the export, leave the Dynamic box unchecked and select the source table.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory next selection.
Target Directory Path
Select the Browse icon to the right of the Target Directory Path and navigate to the location you want the file saved to.
Target File Name
Specify the name the exported file should be saved as.

Bold Rows
Select this checkbox to make the first row (header row) bold font.
Escape
This option is enabled by default. When the checkbox is selected, the export process will convert the characters <, >, and & to HTML-safe sequences.
Double Precision
See details here:
Output File Type
All exported files are uncompressed, but the following compression options are available:
- Zip
- GZip
- BZip2
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
1.4.3.7 - Export to JSON
Description
Export an Analyze data table to PlaidCloud Document as a JSON file. There are several options (shown below) for data orientation.
For more details on JSON files, see the JSON official website here: http://json.org/.
Export Parameters
Export File Selector
The file selector in this transform allows you to choose a destination store the exported result in a PlaidCloud Document.
You choose a directory and specify a file name for the target file.
Source Table
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to source table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the source for the export, leave the Dynamic box unchecked and select the source table.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory next selection.
Target Directory Path
Select the Browse icon to the right of the Target Directory Path and navigate to the location you want the file saved to.
Target File Name
Specify the name the exported file should be saved as.
JSON Orientation
Consider the following data set:
| ID | Name | Gender | State |
|---|---|---|---|
| 1 | Jack | M | MO |
| 2 | Jill | F | MO |
| 3 | George | M | VA |
| 4 | Abe | M | KY |
JSON files can be exported into one of four data formats:
- Records: Data is stored in Python dictionary sets, with each row stored in {Column -> Value, …} format. For example: [{“ID”:1,”Name”:”Jack”,”Gender”:”M”,”State”:”MO”},{“ID”:2,”Name”:”Jill”,”Gender”:”F”,”State”:”MO”},{“ID”:3,”Name”:”George”,”Gender”:”M”,”State”:”VA”},{“ID”:4,”Name”:”Abe”,”Gender”:”M”,”State”:”KY”}]
- Index: Data is stored in nested Python dictionary sets, with each row stored in {Index -> {Column -> Value, …},…} format. For example: {“0”:{“ID”:1,”Name”:”Jack”,”Gender”:”M”,”State”:”MO”},”1”:{“ID”:2,”Name”:”Jill”,”Gender”:”F”,”State”:”MO”},”2”:{“ID”:3,”Name”:”George”,”Gender”:”M”,”State”:”VA”},”3”:{“ID”:4,”Name”:”Abe”,”Gender”:”M”,”State”:”KY”}}
- Split: Data is stored in a single Python dictionary set, values are stored in lists. For example: {“columns”:[“ID”,”Name”,”Gender”,”State”],”index”:[0,1,2,3],”data”:[[1,”Jack”,”M”,”MO”],[2,”Jill”,”F”,”MO”],[3,”George”,”M”,”VA”],[4,”Abe”,”M”,”KY”]]}
- Values: Data is stored in multiple Python lists. For example: [[1,”Jack”,”M”,”MO”],[2,”Jill”,”F”,”MO”],[3,”George”,”M”,”VA”],[4,”Abe”,”M”,”KY”]]
Date Handling
Specify Date Format using the dropdown menu. Choose from the following formats:
- Epoch (Unix Timestamp – Seconds since 1/1/1970)
- ISO 8601 Format (YYYY-MM-DD HH:MM:SS with timeproject offset)
Specify Date Unit using the dropdown menu. Choose from the following formats, listed in order of increasing precision:
- Seconds (s)
- Milliseconds (ms)
- Microseconds (us)
- Nanoseconds (ns)
Force ASCII
Select this checkbox to ensure that all strings are encoded in proper ASCII format. This is enabled by default.
Output File Type
All exported files are uncompressed, but the following compression options are available:
- Zip
- GZip
- BZip2
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
1.4.3.8 - Export to Quandl
Description
Export an Analyze data table to Quandl’s database.
Source and Target
Specify the following parameters:
- Source Table: Analyze data table to export
- Quandl Connection: Accessing Quandl data sets requires a user account or a guest account with limited access. This requires set up in Tools. For details on setting up a Quandl account connection, see here: PlaidCloud Tools – Connection
- Quandl Code: Use the Search button to search for data sets. Alternatively, data sets can be entered manually. This requires the user to enter the portion of the URL after “http://www.quandl.com”. For example, to import the data set for Microsoft stock, which can be found here (http://www.quandl.com/GOOG/NASDAQ_MSFT), enter GOOG/NASDAQ_MSFT in the Quandl Code field
- Dataset Name: Name of the dataset to be exported to Quandl
- Dataset Description: Description of dataset to be exported to Quandl
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
No examples yet...
1.4.3.9 - Export to SQL
Description
Export an Analyze data table to PlaidCloud Document as an SQL.
Examples
No examples yet...
1.4.3.10 - Export to Table Archive
Description
Exports PlaidCloud table archive file.
Export Parameters
Export File Selector
The file selector in this transform allows you to choose a destination store the exported result in a PlaidCloud Document.
You choose a directory and specify a file name for the target file.
Source Table
Dynamic Option
The Dynamic option allows specification of a table using text, including variables. This is useful when employing variable driven workflows where table and view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to source table:
legal_entity/inputs/{current_month}/ledger_values
Static Option
When a specific table is desired as the source for the export, leave the Dynamic box unchecked and select the source table.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Selecting a Document Account
Choose a PlaidCloud Document account for which you have access. This will provide you with the ability to select a directory next selection.
Target Directory Path
Select the Browse icon to the right of the Target Directory Path and navigate to the location you want the file saved to.
Target File Name
Specify the name the exported file should be saved as.
Examples
No examples yet...
1.4.3.11 - Export to XML
Description
Export an Analyze data table to PlaidCloud Document as an XML file.
1.4.4 - Table Steps
1.4.4.1 - Table Anti Join
Description
Table Anti Join provides the unmatched set of items between two tables. This will return the list of items in the first table without matches in the second table. This can be quite useful for determining which records are present in one table but not another.
This operation could be accomplished by using outer joins and filtering on null values for the join; however, the Anti Join transform will perform this in a more efficient and obvious way.
Table Data Selection
Table Source
Specify the source data table by selecting it from the dropdown menu.
Source Columns
Specify any columns to be included here. Selecting the Inspect Source and Populate Source Mapping Table buttons will make these columns available for the join operation.
Select Subset of Source Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples.
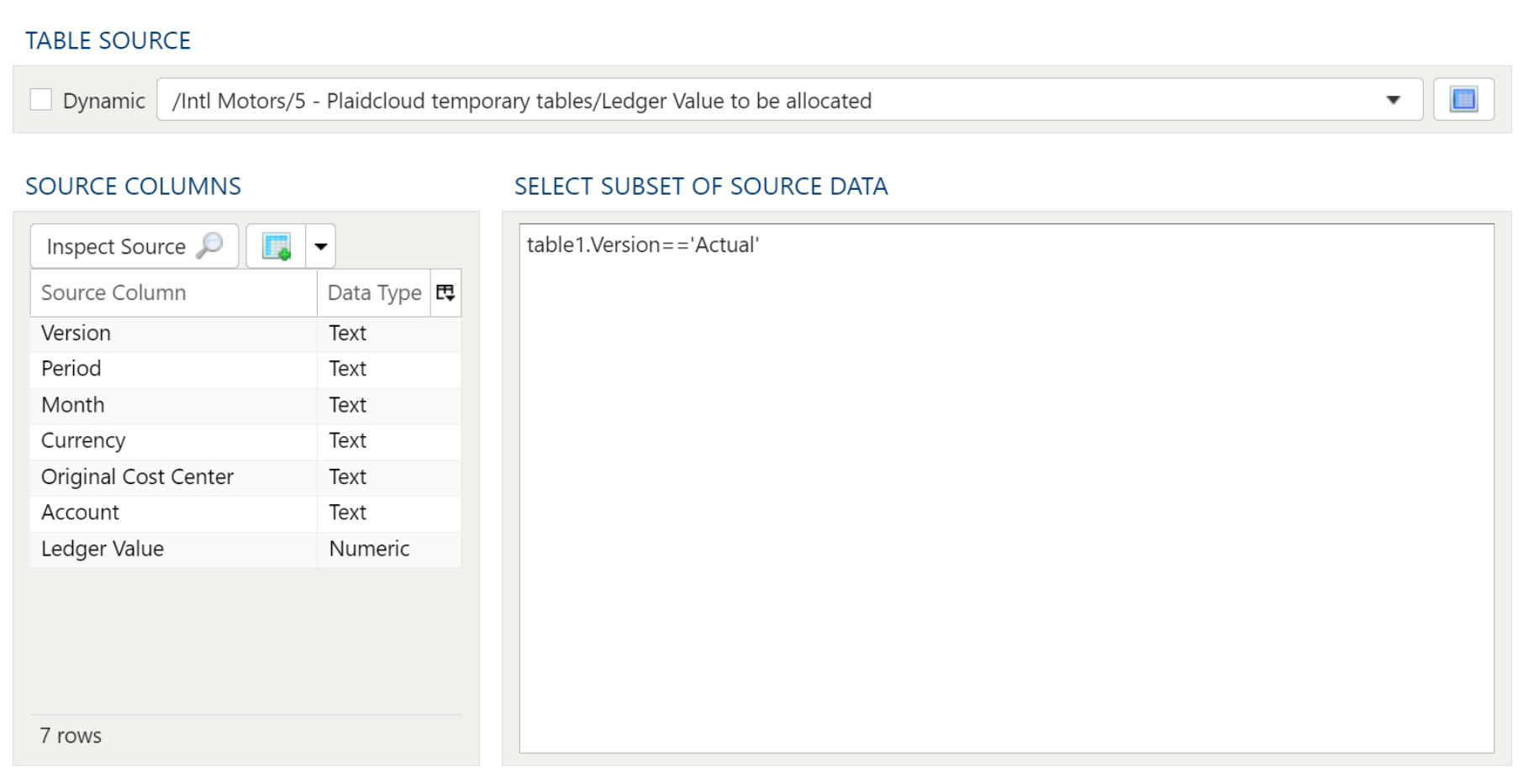
Table Output
Target Table

To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Join Map

Specify join conditions. Using the Guess button will find all matching columns from both Table 1 as well as Table 2. To add additional columns manually, right click anywhere in the section and select either Insert Row or Append Row, to add a row prior to the currently selected row or to add a row at the end, respectively. Then, type the column names to match from Table 1 to Table 2. To remove a field from the Join Map, simply right-click and select Delete.
Target Output Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Output Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.4.2 - Table Append
Description
Used append data to an existing table.
Load Parameters
Source and Target

To establish the source and target tables, first select the data table to be extracted from using the Source Table dropdown menu. Next, select an existing table as the target table using the Target Table dropdown.
Table Data Selection
When configuring the Data Mapper the columns in the source table must be mapped to a column in the target table.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
1.4.4.3 - Table Clear
Description
Clear the contents of an existing data table without deleting the actual data table. The end result is a data table with 0 rows.
Table Selection
There are two options for selecting the table or in the second option tables to:
The first option is to use the Specific Table dropdown to select the table.
The second is to use the Tables Matching Search option in which you specify the Search Path and Search Text to select the table or tables that match the search criteria. This option is very useful if you have a workflow that creates a series of commonly named tables that that have been saved appending the date.

1.4.4.4 - Table Copy
Description
Create a copy of a data table.
Source and Target
To establish the source and target tables, first select the data table to be extracted from using the Source Table dropdown menu. Next, select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
When performing the copy, Analyze will first check to see if the target data table already exists. If it does, no action will be performed unless the Allow Overwriting Existing Table checkbox is selected. If this is the case, the target table will be overwritten.
Examples
1.4.4.5 - Table Cross Join
Description
Use, as you might have expected, to perform a cross join operation on 2 data tables, combining them into a single data table without join key(s).
For more details on cross join methodology, see here: Wikipedia SQL Cross Join
Table Data Selection
Table Source
Specify the source data table by selecting it from the dropdown menu.
Source Columns
Specify any columns to be included here. Selecting the Inspect Source and Populate Source Mapping Table buttons will make these columns available for the join operation.
Select Subset of Source Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples.
Table Output
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Target Output Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Output Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.4.6 - Table Drop
Description
Drop/delete a data table.
Table Selection
Table Selection
There are two options for selecting the table or in the second option tables to:
The first option is to use the Specific Table dropdown to select the table.
The second is to use the Tables Matching Search option in which you specify the Search Path and Search Text to select the table or tables that match the search criteria. This option is very useful if you have a workflow that creates a series of commonly named tables that that have been saved appending the date.
1.4.4.7 - Table Extract
Description
Used to extract data from an existing Analyze data table into another data table. Examples include, but are not limited to, the following:
- Sort
- Group
- Summarization
- Filter/Subset Rows
- Drop Extra Columns
- Math Operations
- String Operations
Extract Parameters
Source and Target
To establish the source and target tables, first select the data table to be extracted from using the Source Table dropdown menu. Next, select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Table Data Selection
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
1.4.4.8 - Table Faker
Description
Table Faker generates fake data.
Address
| Generator | Optional Arguments | | Building Number | | | City | | | City Suffix | | | Country | | | Country Code | “representation”=”alpha-2” | | Full Address | | | Latitude | | | Longitude | | | Military DPO | | | Postal Code | | | Postal Code Plus 4 | | | State | | | State Abbreviation | | | Street Address | | | Street Name | | | Street Suffix | |
Automotive
| Generator | Optional Arguments | | License Plate | |
Barcode
| Generator | Optional Arguments | | EAN13 | | | EAN8 | |
Colors
| Generator | Optional Arguments | | Color Name | | | Hex Color | | | RGB Color | | | RGB CSS Color | | | Safe Color Name | | | Safe Hex Color | |
Company
| Generator | Optional Arguments | | Company Catch Phrase | | | Company Name | | | Company Suffix | |
Credit Card
| Generator | Optional Arguments | | Expriration Date | “start”=”now”“end”=”+10y”## ‘12/20’ | | Full | “card_type”=null | | Number | “card_type”=null | | Provider | “card_type”=null | | Security Code | “card_type”=null |
Currency
| Generator | Optional Arguments | | Code | |
Date Time
| Generator | Optional Arguments | | AM/PM | | | Century | | | Date | “pattern”:”%Y-%m-%d”“end_datetime”:null | | Date Time | “tzinfo”:null“end_datetime”=null | | Date Time this Century | “before_now”=true“after_now”=false“tzinfo”=null | | Date Time this Decade | “before_now”=true“after_now”=false“tzinfo”=null | | Date Time this Month | “before_now”=true“after_now”=false“tzinfo”=null | | Date Time this Year | “before_now”=true“after_now”=false“tzinfo”=null | | Day of Month | | | Day of Week | | | ISO8601 Date Time | “tzinfo”=null“end_datetime”=null | | Month | | | Month Name | | | Past Date (Last 30 Days) | “start_date”=”-30d”“tzinfo”=null | | Timezone | | | Unix Time | “end_datetime”=null“start_datetime”=null | | Year | |
File
| Generator | Optional Arguments | | File Extension | “category”=null | | File Name | “category”=null“extension”=null | | File Path | “depth”=”1”“category”=null“extension”=null | | Mime Type | “category”=null |
Internet
| Generator | Optional Arguments | | Company Email | | | Domain Name | | | Domain Word | | | Email | | | Free Email | | | Free Email Domain | | | Image URL | “width”=null“height”=null | | IPv4 | “network”=false“address_class”=”no”“private”=null | | IPv6 | “network”=false | | MAC Address | | | Safe Email | | | Slug | | | TLD | | | URI | | | URL | “schemes”=null | | URL Extension | | | URL Page | | | User Name | |
ISBN
| Generator | Optional Arguments | | ISBN10 | “eparator”=”-“ | | ISBN13 | “eparator”=”-“ |
Job
| Generator | Optional Arguments | | Job Name | |
Lorem
| Generator | Optional Arguments | | Paragraph | “nb_sentences”=”3”“variable_nb_sentences”=true“ext_word_list”=null | | Paragraphs | “nb”=”3”“ext_word_list”=null | | Sentence | “nb_words”=”6”“variable_nb_words”=true“ext_word_list”=null | | Sentences | “nb”=”3”“ext_word_list”=null | | Text | “max_nb_chars”=”200”“ext_word_list”=null | | Word | “ext_word_list”=null | | Words | “nb”=”3”“ext_word_list”=null |
Misc
| Generator | Optional Arguments | | Binary | “length”=”1048576” | | Boolean | “chance_of_getting_true”=”50” | | Null Boolean | | | Locale | | | Language Code | | | MD5 | “raw_output”=false | | Password | “length”=”10”“special_chars”=true“digits”=true“upper_case”=true“lower_case”=true | | Random String | | | SHA1 | “raw_output”=false | | SHA256 | “raw_output”=false | | UUID4 | |
Numeric
| Generator | Optional Arguments | | Big Serial (Auto Increment) | | | Random Float | | | Random Float in Range | | | Random Integer | | | Random Integer in Range | | | Random Numeric | | | Random Percentage (0 – 1) | | | Random Percentage (0 – 100) | | | Serial (Auto Increment) | |
Person
| Generator | Optional Arguments | | First Name | | | First Name Female | | | First Name Male | | | Full Name | | | Full Name Female | | | Full Name Male | | | Last Name | | | Last Name Female | | | Last Name Male | | | Prefix | | | Prefix Female | | | Prefix Male | | | Suffix | | | Suffix Female | | | Suffix Male | |
Phone
| Generator | Optional Arguments | | Phone Number | | | ISDN | |
Tax
| Generator | Optional Arguments | | EIN | | | Full SSN | | | ITIN | |
User Agent
| Generator | Optional Arguments | | Chrome | “version_from”=”13”“version_to”=”63”“build_from”=”800”“build_to”=”899” | | Firefox | | | Full User Agent | | | Internet Explorer | | | Linux Platform Token | | | Linux Processor | | | Mac Platform Token | | | Mac Processor | | | Opera | | | Safari | | | Windows Platform Token | |
Special Generators
While these two generators do not have arguments, the options they provide act similarly to arguments.
Pattern Generator:
| Number | Format | Output | Description | | 3.1415926 | {:.2f} | 3.14 | 2 decimal places | | 3.1415926 | {:+.2f} | +3.14 | 2 decimal places with sign | | -1 | {:+.2f} | -1.00 | 2 decimal places with sign | | 2.71828 | {:.0f} | 3 | No decimal places | | 5 | {:0>2d} | 05 | Pad number with zeros (left padding, width 2) | | 5 | {:x<4d} | 5xxx | Pad Number with x’s (right padding, width 4) | | 10 | {:x<4d} | 10xx | Pad number with x’s (right padding, width 4) | | 1000000 | {:,} | 1,000,000 | Number format with comma separator | | 0.25 | {:.2%} | 25.00% | Format percentage | | 1000000000 | {:.2e} | 1.00e+09 | Exponent notation | | 13 | {:10d} | 13 | Right aligned (default, width 10) | | 13 | {:<10d} | 13 | Left aligned (width 10) | | 13 | {:^10d} | 13 | Center aligned (width 10) |
Random Choice:
In order to provide the options for random choice, simply put your options in quotes and seperate each option with a comma. So a string of random choice options would appear like this: “x”,”y”,”z”
Here, the “Key Word Args/Pattern/Choices” column of the “pattern” row contains a sentence with several references. The first reference equation ( {percentage0-100:.2f}% ) points to the “percentage0-100” row which will generate a random equation. Therefore, the random percentage produced by the “percentage0-100” row will be automatically inserted into the sentence. The reference equation {first_name} points to the row titled “first_name” which will randomly generate a first name, and this name will be automatically inserted into the sentence. The last reference equation ( {randomn_choice} ) operates the same as the other two.
With this, when the pattern generator is run, you will recieve the following results.
1.4.4.9 - Table In-Place Delete
Description
Performs a delete on the table using the specified filter conditions. The operation is performed on the designated table directly so no additional tables are created. Only the rows that meet the filter criteria are deleted. This may be an effective approach when encountering concerns related to data size.
Delete Parameters
Select the Source table for deleting from the dropdown list. This list includes all Project and Workflow data tables.
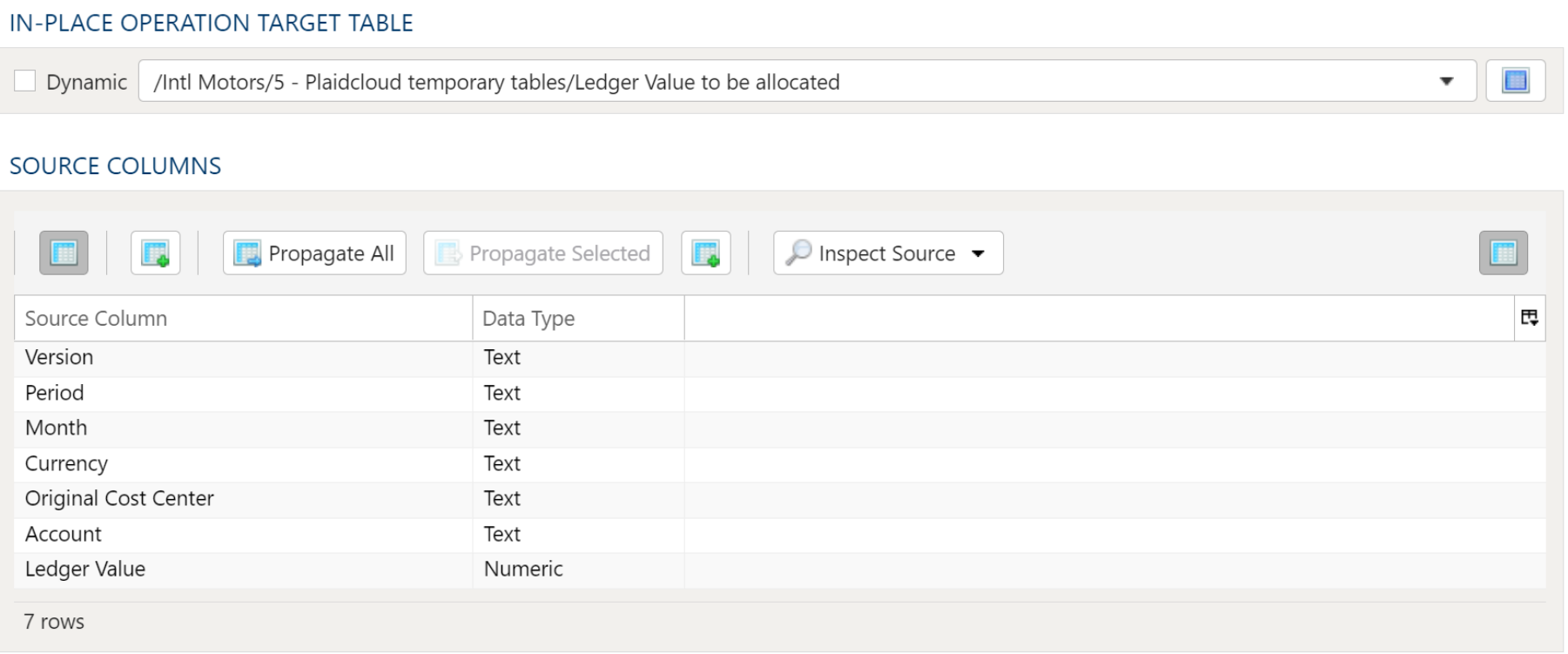
Data Filters for Delete
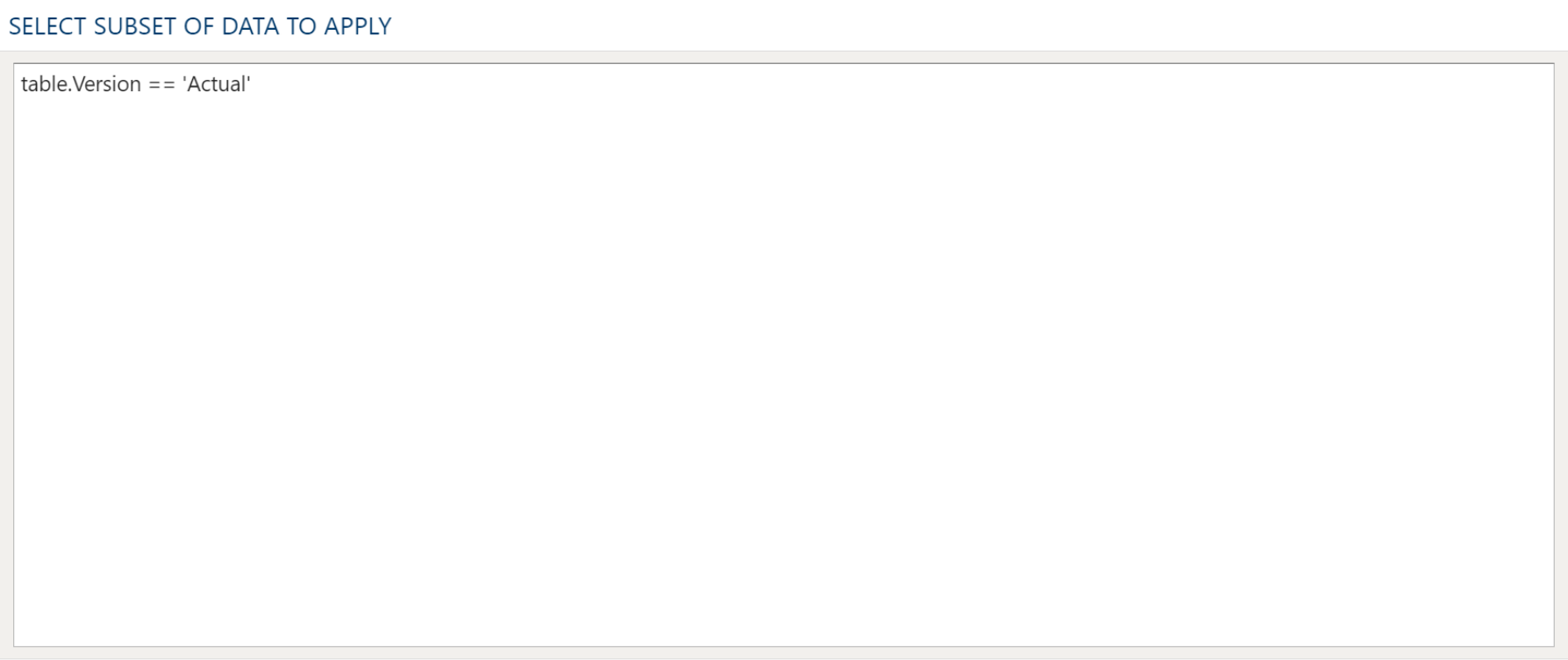
Examples
1.4.4.10 - Table In-Place Update
Description
Performs an update on the table using the specified filter conditions and value settings. The operation is performed directly on the designated table, so no additional tables are created. This may be an effective approach when concerns of data size are encountered.
Table Selection
Select the Source table for updating from the dropdown list. This list includes all Project and Workflow data tables.
Examples
In this example the Account will be set to 41000 when the Version is equal to "Actual" in "Ledger Value to be allocated".
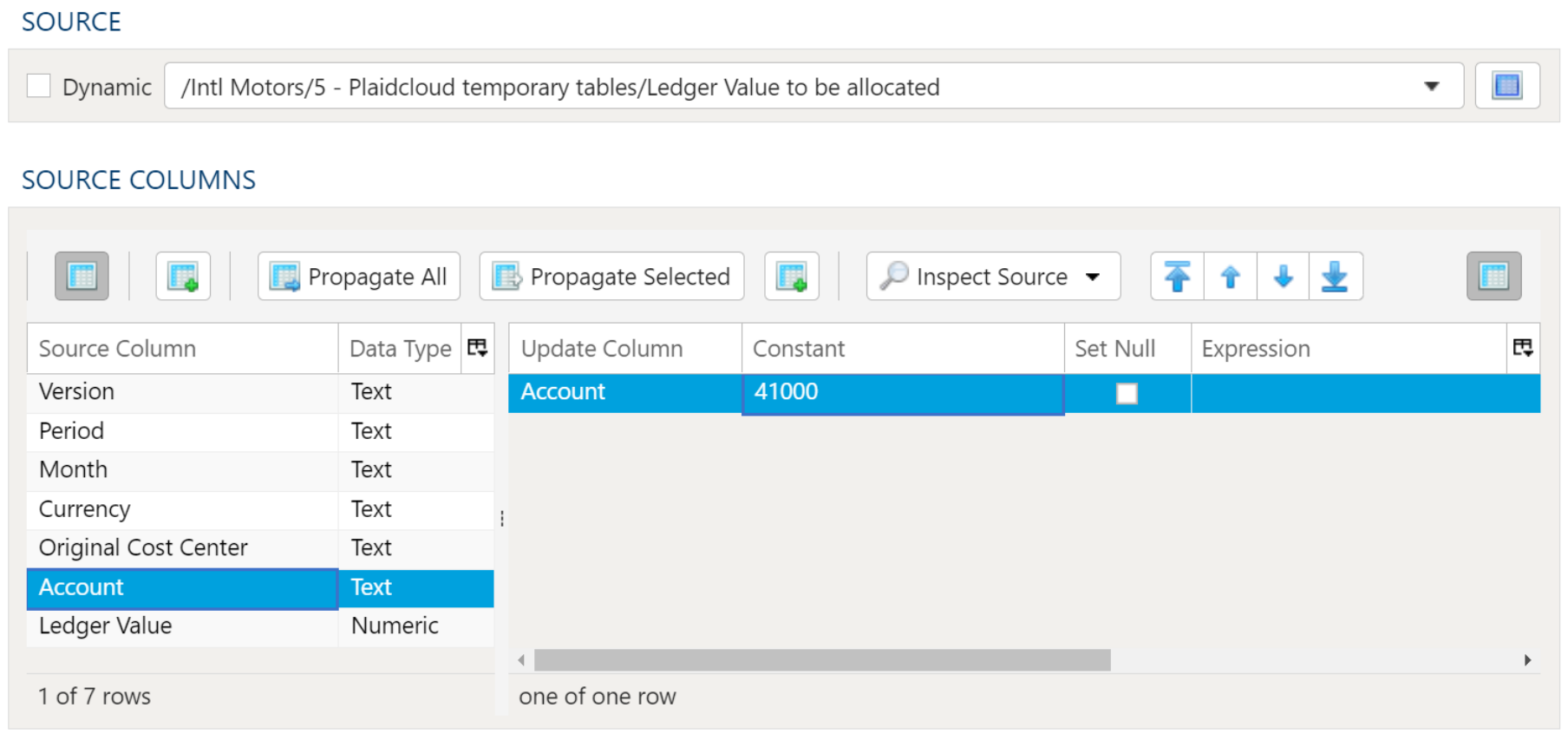
1.4.4.11 - Table Inner Join
Description
Use, as you might have expected, to perform an inner join operation on 2 data tables, combining them into a single data table based upon the specified join key(s).
For more details on inner join methodology, see here: Wikipedia SQL Inner Join
Table Data Selection
Table Source
Specify the source data table by selecting it from the dropdown menu.
Source Columns
Specify any columns to be included here. Selecting the Inspect Source and Populate Source Mapping Table buttons will make these columns available for the join operation.
Select Subset of Source Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples.
Table Output
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Join Map
Specify join conditions. Using the Guess button will find all matching columns from both Table 1 as well as Table 2. To add additional columns manually, right click anywhere in the section and select either Insert Row or Append Row, to add a row prior to the currently selected row or to add a row at the end, respectively. Then, type the column names to match from Table 1 to Table 2. To remove a field from the Join Map, simply right-click and select Delete.
Target Output Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Output Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
Join Automobile Manufacturers with Models
In this example, consider the following source data tables. First is a list of automobile manufacturers.
| Mfg_ID | Manufacturer |
|---|---|
| 1 | Aston Martin |
| 2 | Porsche |
| 3 | Lamborghini |
| 4 | Ferrari |
| 5 | Koenigsegg |
Next is a list of automobile models with a manufacturer ID. Note that there are several models with no manufacturer.
| ModelName | Mfg_ID |
|---|---|
| Aventador | 3 |
| Countach | 3 |
| DBS | 1 |
| Enzo | 4 |
| One-77 | 1 |
| Optimus Prime | |
| Batmobile | |
| Agera | 5 |
| Lightning McQueen |
To get a list of models by manufacturer, it makes sense to join on Mfg_ID.
First, specify parameters for Table 1 Data Selection. The source data table is selected and all columns are listed.
Next, specify parameters for Table 2 Data Selection. Once again, the source data table is selected and all columns are listed.
Finally, the join conditions are set in the Table Output tab. Using the Guess button, Analyze properly identifies the Mfg_ID column to use as the Join Key. Lastly, the
Target Output Columns are specified automatically using the Propagate button. This effectively includes all columns from all tables, with all join columns included only a single time. Note that the columns are sorted alphabetically, first by Manufacturer and next by ModelName.
As expected, the final output only includes values which had a match in both tables. As such, Porsche does not show up because it had no models. Likewise, the
Batmobile had no manufacturer (it was a custom job), so it’s not included.
1.4.4.12 - Table Lookup
Description
If you are a regular user of the vlookup function in Microsoft Excel, the Table Lookup transform should feel very familiar. It’s used to perform essentially the same function. Unlike the Microsoft Excel version, the PlaidCloud Analyze Table Lookup transform offers greater flexibility, especially allowing for matching on and returning multiple columns.
Table Data Selection
Table Source
Specify the source data table by selecting it from the dropdown menu.
Source Columns
Specify any columns to be included here. Selecting the Inspect Source and Populate Source Mapping Table buttons will make these columns available for the join operation.
Select Subset of Source Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples.
Table Output
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Join Map
Specify join conditions. Using the Guess button will find all matching columns from both Table 1 as well as Table 2. To add additional columns manually, right click anywhere in the section and select either Insert Row or Append Row, to add a row prior to the currently selected row or to add a row at the end, respectively. Then, type the column names to match from Table 1 to Table 2. To remove a field from the Join Map, simply right-click and select Delete.
Target Output Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Output Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
Lookup Product Dimension Information
In this example, the modeler needs information from the product dimension table to make sense of the order fact table. As such, the Import Order Fact table is selected as the Source Table. The Import Product Dim table contains the desired lookup information, so it’s selected as the Lookup Table Source. Although available, no filters are applied to the lookup data table (nor any other data tables, for that matter).
In the Table Data Selection section, all columns are mapped from the source data table to the target data table.
No Data Filters are applied to either source or target data.
Lastly, the source data table is matched to the lookup data table using the Product_ID field found in each table. Only the Product_Description and Unit_Cost columns are appended to the target data table, with Unit_Cost being renamed to Retail_Unit_Cost in the process.
In the resulting target data table, the Product_Description and Retail_Unit_Cost columns have been added, based on matching values in the Product_ID column.
1.4.4.13 - Table Melt
Description
Used to convert short, wide data tables into long, narrow data tables. Selected columns are transposed, with the column names converted into values across multiple rows.
Perhaps the easiest example to understand is to think of a data table with months listed as column headers:
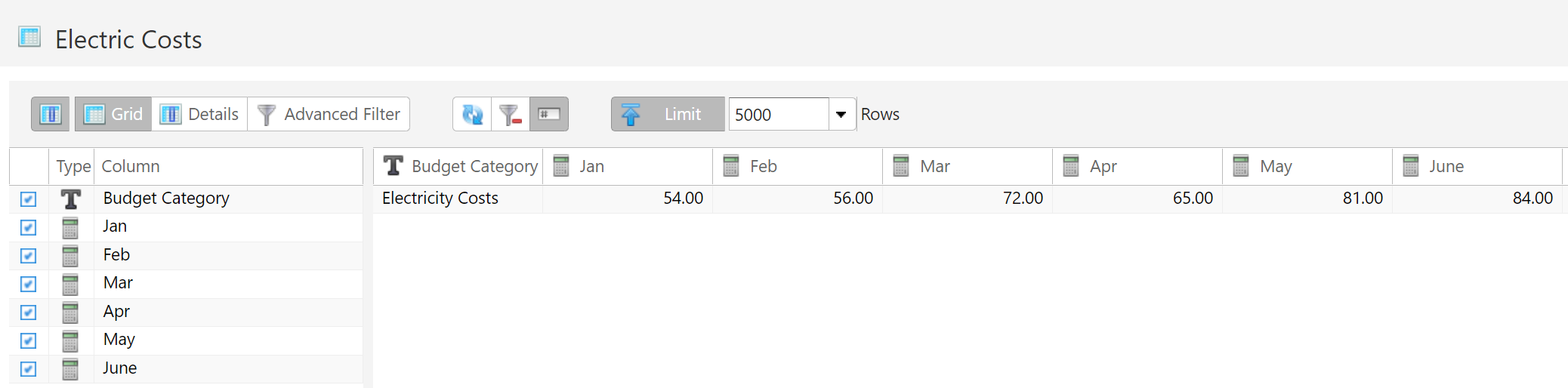
Melting this data table would convert all of the month columns into rows.
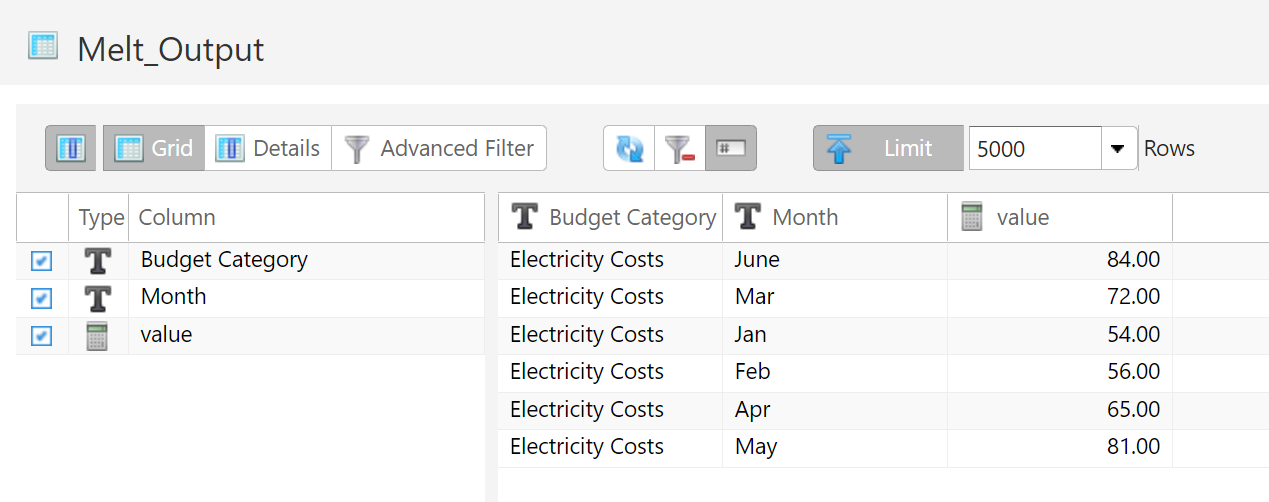
By specifying which columns to transpose and which columns to leave alone, this becomes a powerful tool. Making this conversion in other ETL tools could require a dozen more steps.
Source and Target Parameters
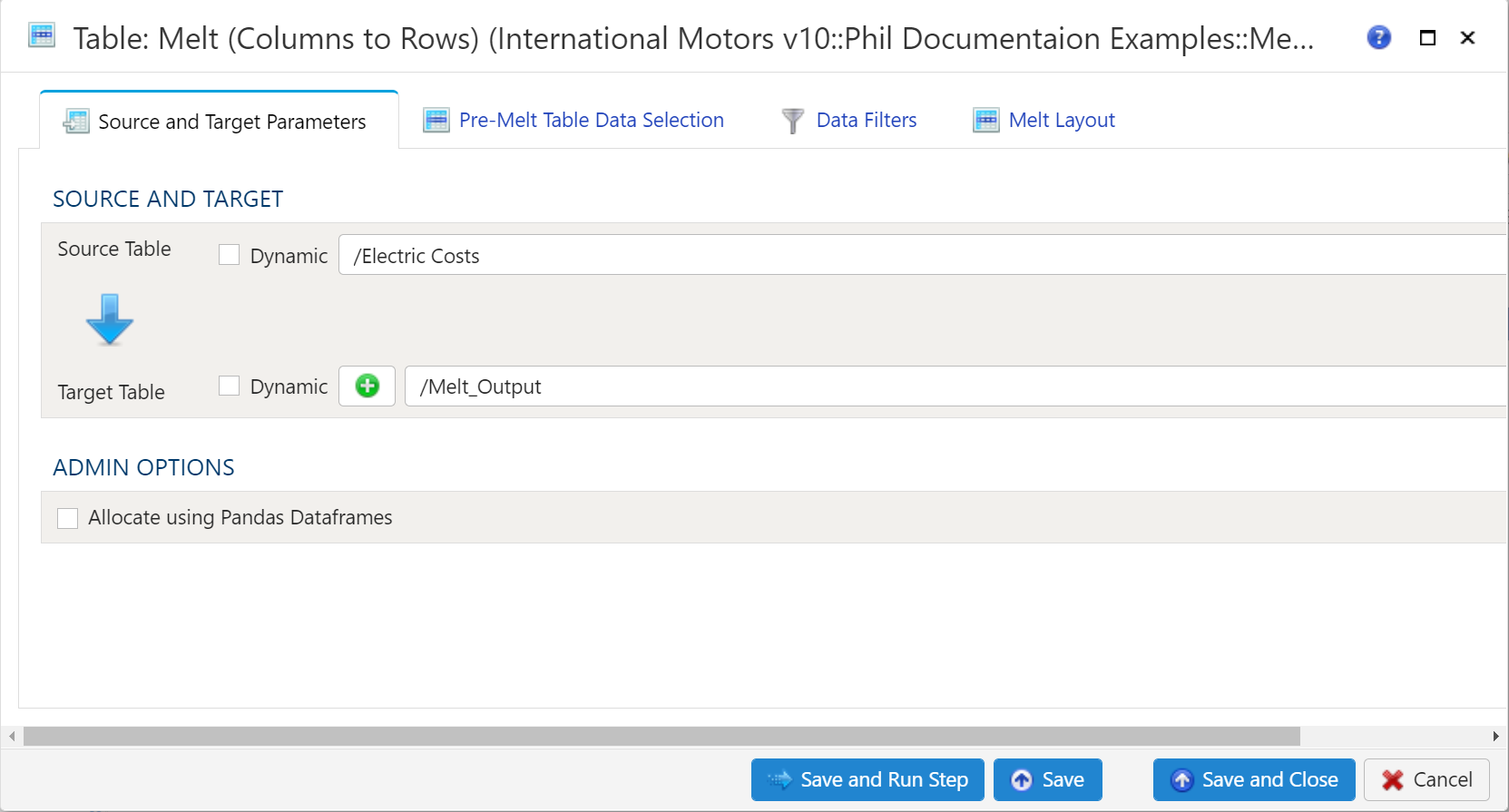
Source and Target
To establish the source and target, first select the data table to be extracted from the Source Table dropdown menu.
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Pre-Melt Table Data Selection
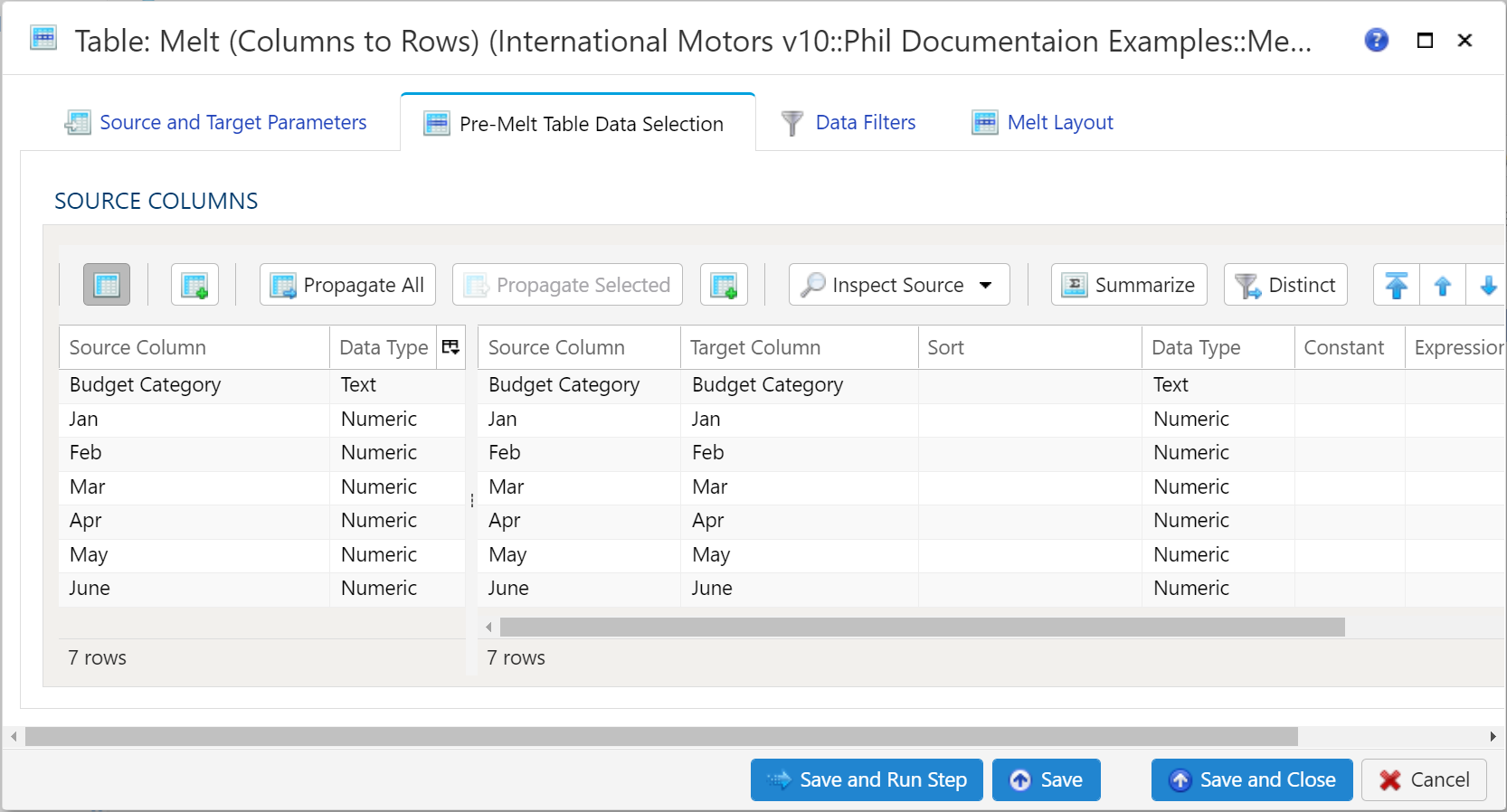
This section is a bit different from the standard Table Data Selection. Basically this is used to specify which columns are to be used in the Melt operation. This includes ID columns and Variable/Value columns.
For more details regarding Table Data Selection, see details here: Table Data Selection
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset of Source Data
Any valid Python expression is acceptable to subset the data. Please see Expressions
for more details and examples.
Apply Secondary Filter To Result Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples
Final Data Table Slicing (Limit)
To limit the data, simply check the Apply Row Slicer box and then specify the following:
- Initial Rows to Skip: Rows of data to skip (column header row is not included in count)
- End at Row: Last row of data to include. This is different from simply counting rows at the end to drop
Melt Layout
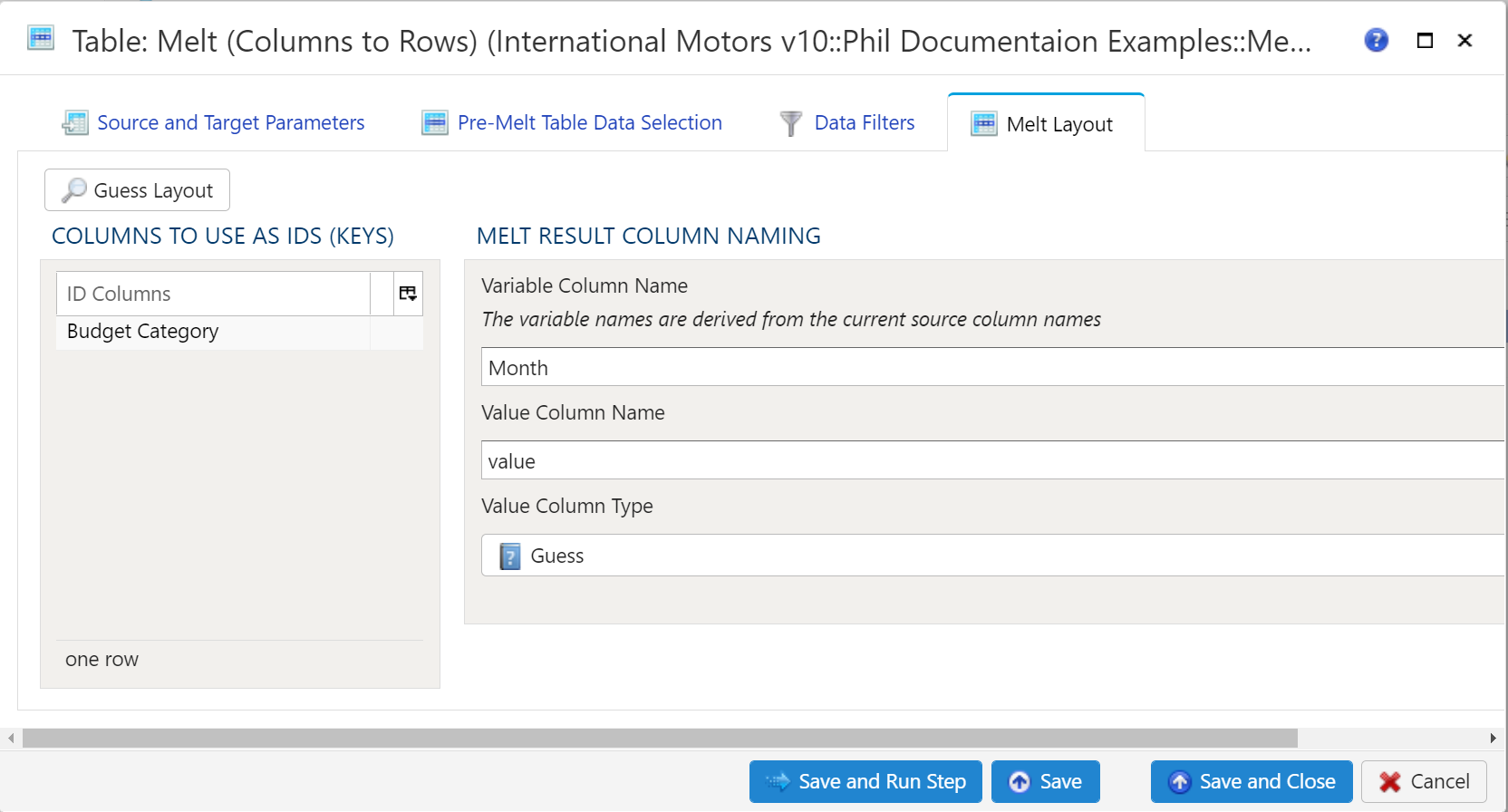
There is a Guess Layout button available to allow Analyze a first crack at specifying ID columns. By default, all text (data type of String) columns are placed in the Keys section. Numeric columns are not placed into Keys by default, but they are allowed to be there based on the model’s needs.
Columns to Use as IDs (Keys)
ID columns are the columns which remain in tact. These columns are effectively repeated for every instance of a variable/value combination. For a monthly table, this would result in 12 repetitions of ID columns.
ID columns can be added automatically or manually. To add the columns automatically, use the aforementioned Guess Layout button. To add additional columns manually, right click anywhere in the section and select either Insert Row or Append Row, to add a row prior to the currently selected row or to add a row at the end, respectively. Then, type the column name to use as an ID.
To remove a field from the IDs, simply right-click and select Delete.
Melt Result Column Naming
There are 2 values to specify. Both of these values will become column names in the target data table.
- Variable Column Name: As specified in the transform, The variable names are derived from the current source column names. Essentially, specify a column name which will represent the data originally represented in the source data table columns.
- Value Column Name: Specify a column name to represent the data represented within the source data table. Typically this will be a numerical unit: Dollars, Pounds, Degrees, Percent, etc.
Examples
In the abouve documentation.
1.4.4.14 - Table Outer Join
Description
Use, as you might have expected, to perform a full outer join operation on 2 data tables, combining them into a single data table based upon the join key(s) specified.
For more details on outer join methodology, see here: Wikipedia SQL Full Outer Join
Table Data Selection
Table Source
Specify the source data table by selecting it from the dropdown menu.
Source Columns
Specify any columns to be included here. Selecting the Inspect Source and Populate Source Mapping Table buttons will make these columns available for the join operation.
Select Subset of Source Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples.
Table Output
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Join Map
Specify join conditions. Using the Guess button will find all matching columns from both Table 1 as well as Table 2. To add additional columns manually, right click anywhere in the section and select either Insert Row or Append Row, to add a row prior to the currently selected row or to add a row at the end, respectively. Then, type the column names to match from Table 1 to Table 2. To remove a field from the Join Map, simply right-click and select Delete.
Target Output Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Output Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
Join Automobile Manufacturers with Models
In this example, consider the following source data tables. First is a list of automobile manufacturers.
| Mfg_ID | Manufacturer |
|---|---|
| 1 | Aston Martin |
| 2 | Porsche |
| 3 | Lamborghini |
| 4 | Ferrari |
| 5 | Koenigsegg |
Next is a list of automobile models with a manufacturer ID. Note that there are several models with no manufacturer.
| ModelName | Mfg_ID |
|---|---|
| Aventador | 3 |
| Countach | 3 |
| DBS | 1 |
| Enzo | 4 |
| One-77 | 1 |
| Optimus Prime | |
| Batmobile | |
| Agera | 5 |
| Lightning McQueen |
To get a list of models by manufacturer, it makes sense to join on Mfg_ID. By leveraging outer join concepts, the output will also be able to show those items which do not have any matches.
First, specify parameters for Table 1 Data Selection. The source data table is selected and all columns are listed.
Next, specify parameters for Table 2 Data Selection. Once again, the source data table is selected and all columns are listed.
Finally, the join conditions are set in the Table Output tab. Using the Guess button, Analyze properly identifies the Mfg_ID column to use as the Join Key. Lastly, the
Target Output Columns are specified automatically using the Propagate button. This effectively includes all columns from all tables, with any join columns obviously only being included a single time. Note that the columns are sorted alphabetically, first by Manufacturer and next by ModelName.
As expected, the final output includes all rows from both tables, whether they had a match in both tables or not. As such, this time Porsche does indeed show up despite having no models. Additionally, Batmobile, Lightning McQueen, and Optimus Prime are included in the results even though none of them have a manufacturer. Besides, who can say ‘No’ to them?
1.4.4.15 - Table Pivot
Description
Used to convert long, narrow data tables into short, wide data tables. Selected columns are transposed, with the column names converted into values across multiple columns.
Perhaps the easiest example to understand is to think of a data table with months listed as rows:
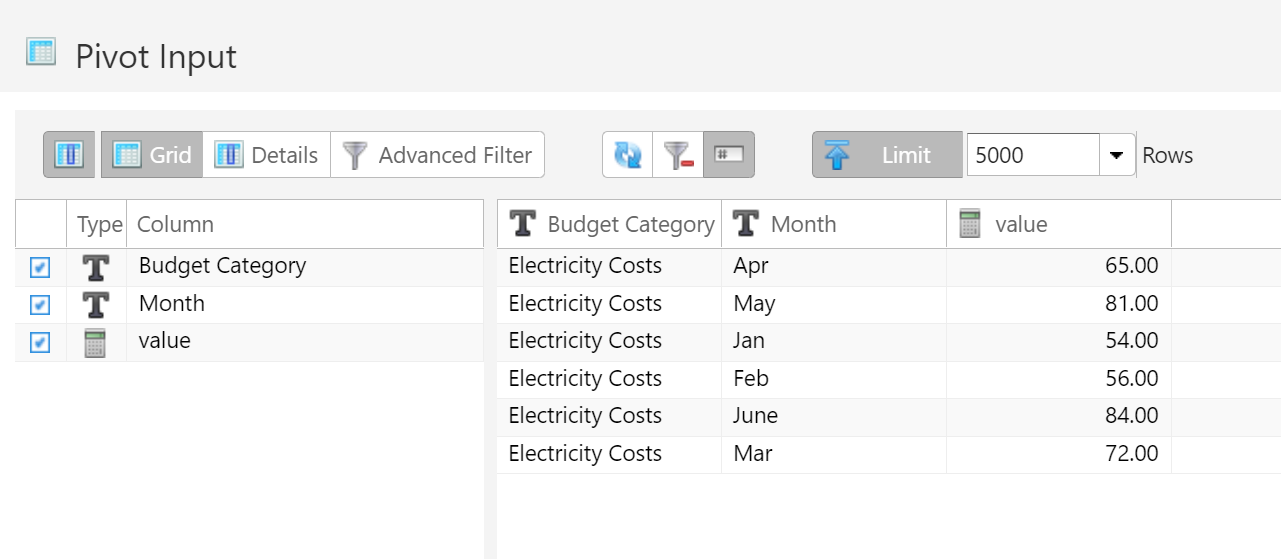
Pivoting this data table would convert all of the month rows into columns.
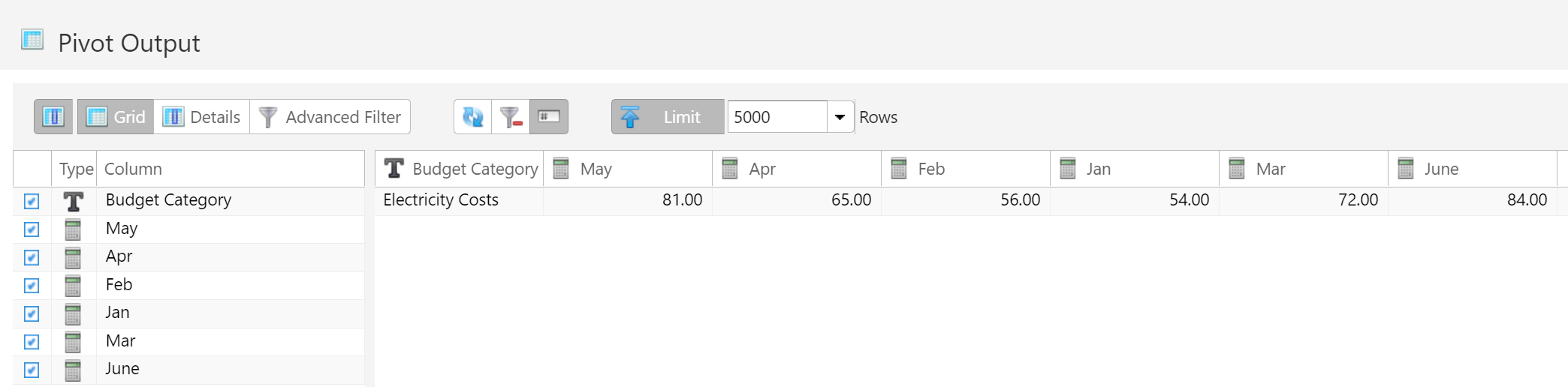
By specifying which columns to transpose and which columns to leave alone, this becomes a powerful tool. Making this conversion in other ETL tools could require a dozen more steps.
Source and Target Parameters
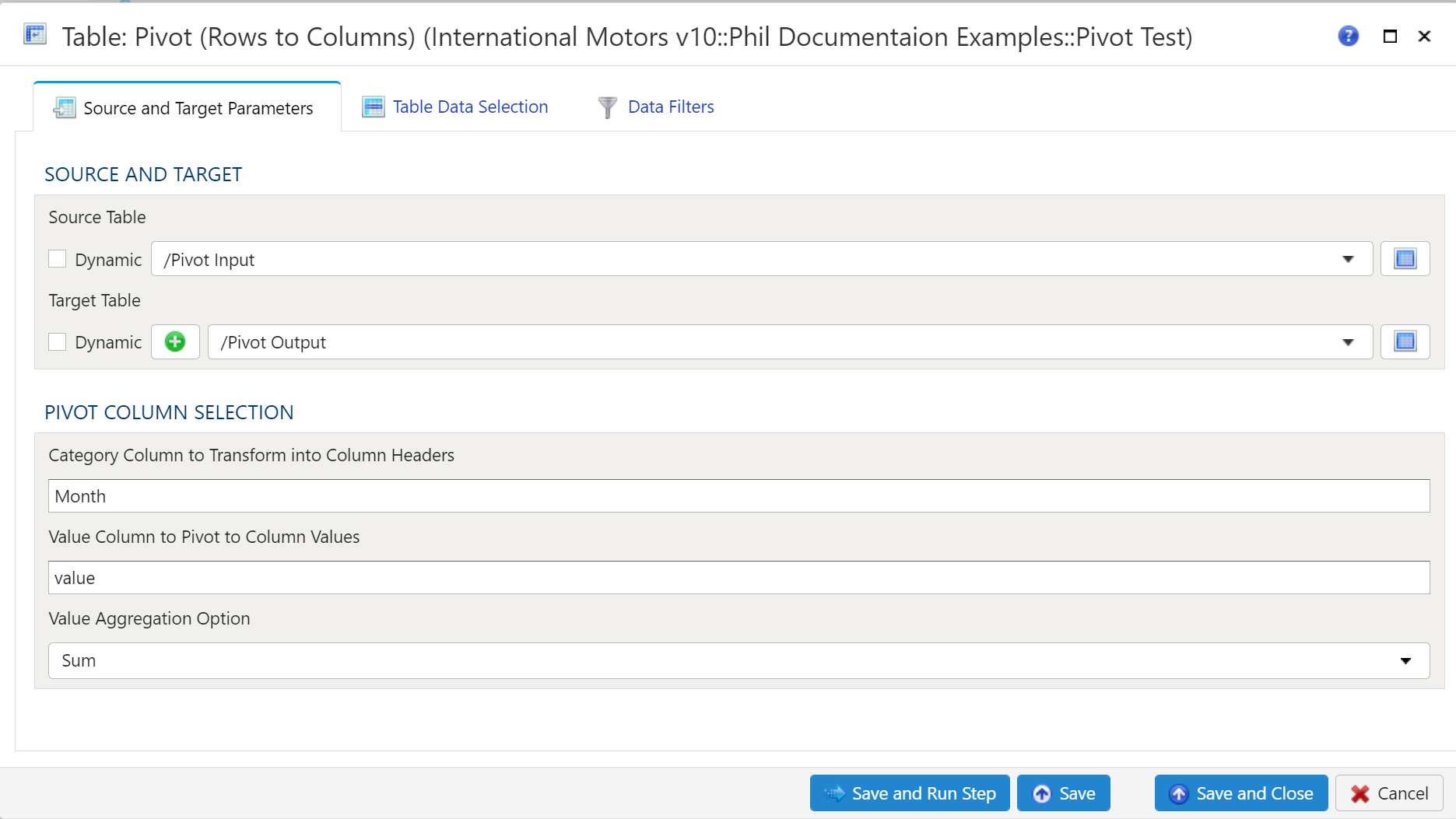
Source Table Selection
To establish the source and target, first select the data table to be extracted from using the dropdown menu.
Traget Table Selection
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Pivot Column Selection
The Category Column to Transform into Column Headers is where you specigy the column in Source Table that will be pivoted to rows. The Value Column ti Pivot to Column Vales is the column that containes the values in the Source Table. The Value Aggregation Option is where you specify how you want the data to aggregate.
Table Data Selection
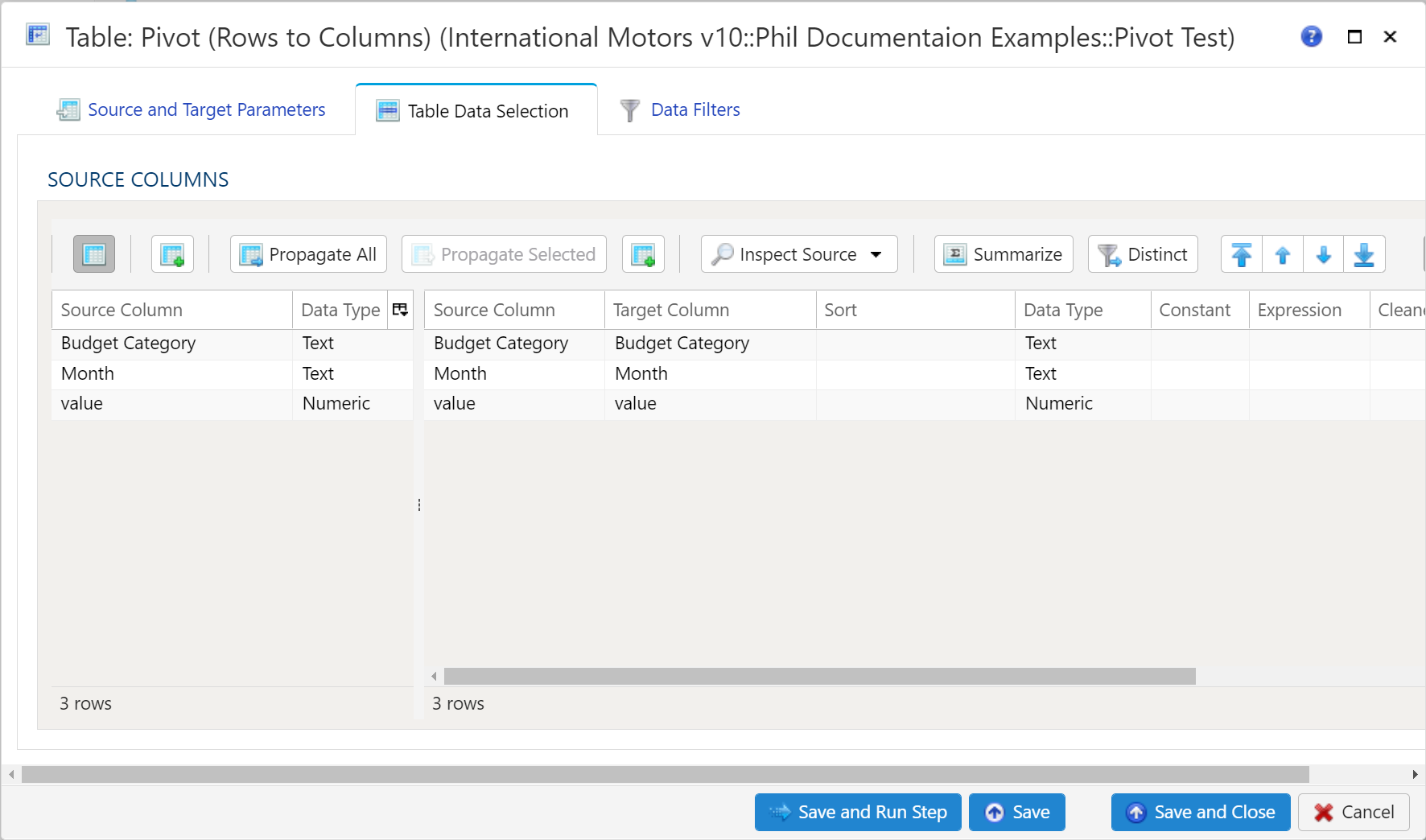
The Table Data Selection tab is used to map columns from the source data table to the target data table. All source columns on the left side of the window are automatically mapped to the target data table depicted on the right side of the window. Using the Inspect Source menu button, there are a few additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
In addition to each of these options, each choice offers the ability to preview the source data.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
To rearrange columns in the target data table, select the desired column(s), then right click and select Move to Top, Move Up, Move Down, or Move to Bottom.
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return distinct results only.
To aggregate results, select the Summarize menu option. This will toggle a set of drop down boxes for each column in the target data table. The following summarization options are available:
- Group by (set as default)
- Sum
- Min
- Max
- First
- Last
- Count
- Mean
- Median
- Mode
- Std Dev
- Variance
- Product
- Absolute Val
- Quantile
- Skew
- Kurtosis
- Mean Abs Dev
- Cumulative Sum
- Cumulative Min
- Cumulative Max
- Cumulative Product
For more aggregation details, see the Analyze overview page here.
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset of Data
Any valid Python expression is acceptable to subset the data. Please see Expressions
for more details and examples.
Apply Secondary Filter To Result Data
Any valid Python expression is acceptable to subset the data. Please see Expressions for more details and examples
Final Data Table Slicing (Limit)
To limit the data, simply check the Apply Row Slicer box and then specify the following:
- Initial Rows to Skip: Rows of data to skip (column header row is not included in count)
- End at Row: Last row of data to include. This is different from simply counting rows at the end to drop
1.4.4.16 - Table Union All
Description
Use to combine multiple data tables with the same column structure into a single data table. For example, time series data is a prime candidate for this transform. The result is all of the records from the combined tables.
Sources
The Sources section serves as a collection of all data tables to append together. Typically, all of the data tables will have the same (or similar) column structure. There are two buttons available to add a data table to the list:
- Insert Row
- Append Row
Additionally, right-clicking in the Select Source to Edit window will display the same options. Right-clicking on a table already added will also display the Delete option.
To execute the transform properly, there will need to be one entry in the Sources section for every source data table to append together. These entries are listed in the order in which they will be appended. To adjust the order, right-clicking on a table will display the following options:
- Move Down (if applicable)
- Move To Bottom (if applicable)
- Move Up (if applicable)
- Move To Top (if applicable)
By default, each source is named New Table, but the modeler is encouraged to provide descriptive names by double-clicking the name and renaming accordingly.
Target Table
By default, the Target Table is left blank. Before naming, note that data tables must follow Linux naming conventions. As such, we recommend that names only consist of alphanumeric characters. Analyze will automatically scrub any invalid characters from the name. Additionally, it will limit the length to 256 characters, so be concise!
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Table Data Selection Tab
Source Table
Table Selection
There are two options for selecting the table or in the second option tables to:
The first option is to use the Specific Table dropdown to select the table.
The second is to use the Tables Matching Search option in which you specify the Search Path and Search Text to select the table or tables that match the search criteria. This option is very useful if you have a workflow that creates a series of commonly named tables that that have been saved appending the date.
Source Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.4.17 - Table Union Distinct
Description
Use to combine multiple data tables with the same column structure into a single data table. For example, time series data is a prime candidate for this transform. The result is always the distinct set of records after combining the data.
Sources
The Sources section serves as a collection of all data tables to append together. Typically, all of the data tables will have the same (or similar) column structure. There are two buttons available to add a data table to the list:
- Insert Row
- Append Row
Additionally, right-clicking in the Select Source to Edit window will display the same options. Right-clicking on a table already added will also display the Delete option.
To execute the transform properly, there will need to be one entry in the Sources section for every source data table to append together. These entries are listed in the order in which they will be appended. To adjust the order, right-clicking on a table will display the following options:
- Move Down (if applicable)
- Move To Bottom (if applicable)
- Move Up (if applicable)
- Move To Top (if applicable)
By default, each source is named New Table, but the modeler is encouraged to provide descriptive names by double-clicking the name and renaming accordingly.
Target Table
By default, the Target Table is left blank. Before naming, note that data tables must follow Linux naming conventions. As such, we recommend that names only consist of alphanumeric characters. Analyze will automatically scrub any invalid characters from the name. Additionally, it will limit the length to 256 characters, so be concise!
Target Table
To establish the target table select either an existing table as the target table using the Target Table dropdown or click on the green "+" sign to create a new table as the target.
Table Creation
When creating a new table you will have the option to either create it as a View or as a Table.
Views:
Views are useful in that the time required for a step to execute is significantly less than when a table is used. The downside of views is they are not a useful for data exploration in the table Details mode.
Tables:
When using a table as the target a step will take longer to execute but data exploration in the Details mode is much quicker than with a view.
Table Data Selection Tab
Source Table
Table Selection
There are two options for selecting the table or in the second option tables to:
The first option is to use the Specific Table dropdown to select the table.
The second is to use the Tables Matching Search option in which you specify the Search Path and Search Text to select the table or tables that match the search criteria. This option is very useful if you have a workflow that creates a series of commonly named tables that that have been saved appending the date.
Source Columns
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.4.18 - Table Upsert
Description
Performs an update of existing records and append new ones.
Upsert Parameters
To establish the source and target tables, first select the data table to be extracted from using the Source Table dropdown menu. Next, select an existing table as the target table using the Target Table dropdown.
Source Table Data Selection
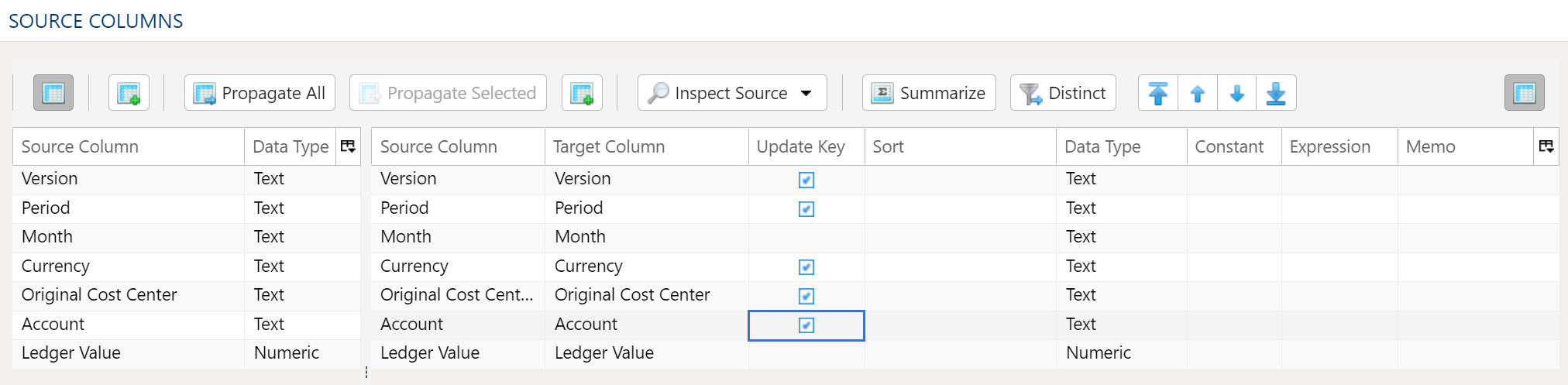
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Update Key
In order for the Upsert to update the existing and append new records you need to select the columns in the data that create a unique key.
Source Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.5 - Dimension Steps
1.4.5.1 - Dimension Clear
Description
Clears the contents of a dimension including structure, values, aliases, properties, and alternate hierarchies

Dimension Selection
Specify Dimension Dynamically
If dimensions or paths were created dynamically then same variables can be used to clear them. Using variables in the clear process is useful since it eliminates the need to update the Dimension Clear step manually on a periodic basis.
An example that uses the current_month variable to dynamically clear the Materials dimension:
/Dimensions/{current_month}/Products/Materials
Use Specific Dimension
Use the dropdown menu to select a specific dimension to clear.
1.4.5.2 - Dimension Create
Description
Creates a dimension for use and loading
Dimension To Create
Name
You can either use a specific name for the dimension to be created or include variables for dynamic naming.
Variables are useful when dimensions are updated on a periodic basis and retaining the historical view is desired.
An example that uses the current_month variable to dynamically name the dimension:
dimension_name_{current_month}
Path
Paths let you create folder structures that the dimensions are are stored in. You can use variables here as well to make the folder structure dynamic.
An example that uses the current_month variable to dynamically name a folder:
/Dimensions/{current_month}/Product/
Memo
The Memo field is used a place to store comments or notes.
1.4.5.3 - Dimension Delete
Description
Deletes a dimension along with all associated structure, values, properties, aliases, and alternate hierarchies
Dimension Selection
Specify Dimension Dynamically
If dimensions or paths were created dynamically then same variables can be used to delete them. Using variables in the delete process is useful since it eliminates the need to update the Dimension Delete step manually on a periodic basis.
An example that uses the current_month variable to dynamically delete the Materials dimension:
/Dimensions/{current_month}/Products/Materials
Use Specific Dimension
Use the dropdown menu to select a specific dimension to delete.
1.4.5.4 - Dimension Export
Description
Export dimensions by flattening the data into a PlaidCloud table.
Documentation coming soon...
1.4.5.5 - Dimension Load
Description
Load and update dimensions using data from PlaidCloud tables.
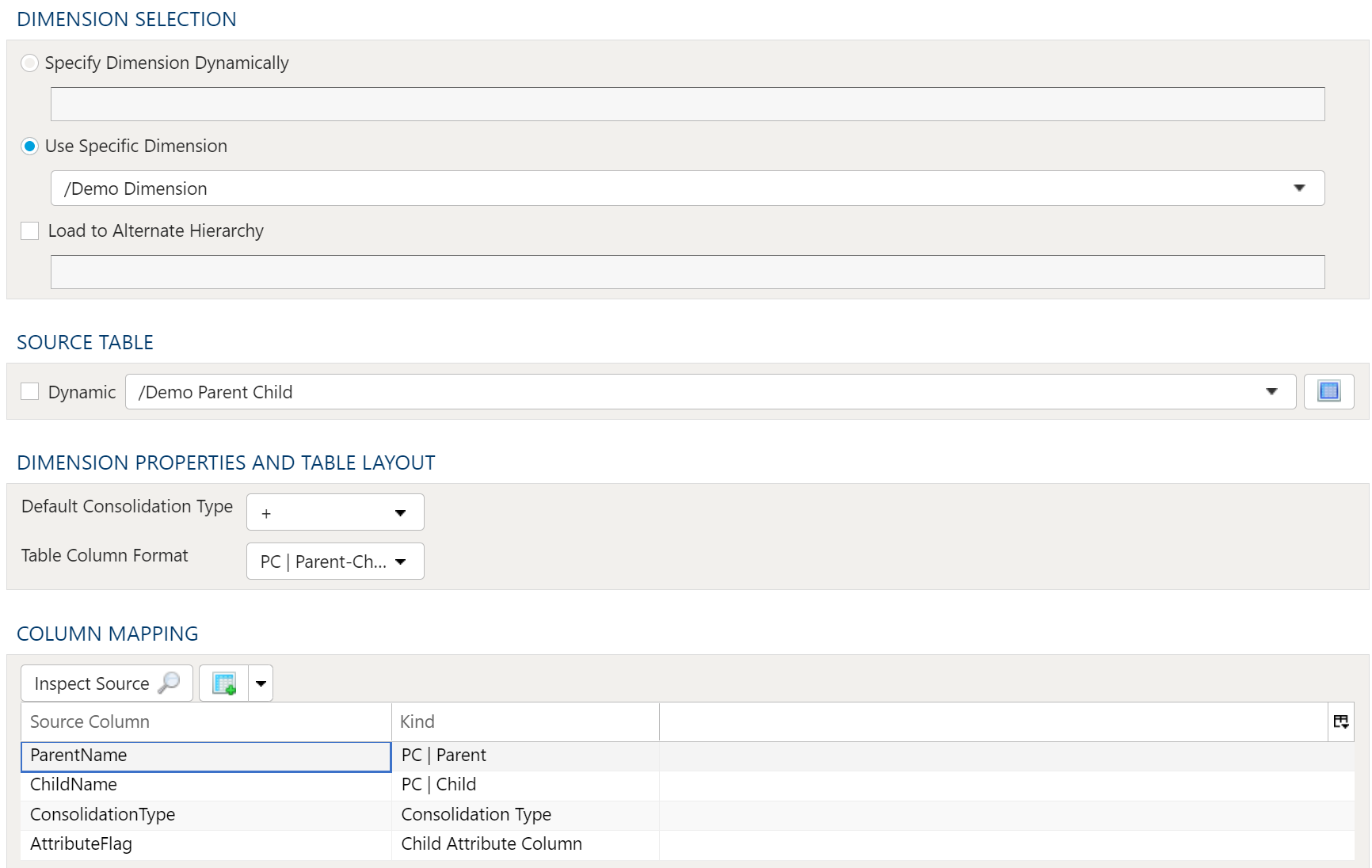
Dimension Selection
Specify Dimension Dynamically
To specify a dimension dynamically you include project and or local variables in the name.
Variables are useful when dimensions are updated on a periodic basis and retaining the historical view is desired.
An example that uses the current_month variable to dynamically load the dimension:
dimension_name_{current_month}
Use Specific Dimension
To use a specific dimension select the dimension using the drop down menu.
Load to Alternate Hierarchy
To load an Alternate Hierarchy fist select the dimension either dynamically or specifically, click the Load to Alternate Hierarchy checkbox and enter the name of the alternate hierarchy to be loaded.
Source Table
Dynamic
To specify the source table dynamically click the Dynamic Checkbox and enter the table name including the project and or local variables in the name.
Static
To use a specific source table select the table using the drop down menu.
Dimension Properties And Table Layout
Default Consolidation Type
There are three options for consolidation types:
- "+": Aggregates values in the dimension.
- "-": Subtracts values in the dimension.
- "~": No aggregation is performed in the dimension.
Table Column Format
There are two options for fomatting the Source Table when loading a dimension.
Parent Child
In a Parent Child table there are two columns that represent the dimensions structure, Parent and Child.
EXAMPLE PARENT CHILD
| PARENT | CHILD | Consolidation Type |
|---|---|---|
| Parent All | Parent 1 | ~ |
| Parnet All | Parent 2 | ~ |
| Parent 1 | Child 1 | + |
| Parent 2 | Child 2 | + |
| Child 1 | Child 3 | + |
| Child 1 | Child 4 | + |
| Child 2 | Child 5 | + |
Flattened Levels
In a Flattend Level table there are an infinte number of columns with each column representing a level of the dimension.
EXAMPLE FLATTENED LEVELS
| Level 1 | Level 2 | Level 3 | Level 4 |
|---|---|---|---|
| Parent All | Parent 1 | Child 1 | Child 3 |
| Parent All | Parent 1 | Child 1 | Child 4 |
| Parent All | Parent 2 | Child 2 | Child 5 |
Column Mapping
Using the Inspect Source menu button populates the Source Column in the data mapper. Once the Source Column has been populated use the Kind drop down menu to map the Source Columns to the appropriate column type.
1.4.5.6 - Dimension Sort
Description
Sort dimensions automatically.
Dimension Selection
Specify Dimension Dynamically
If dimensions or paths were created dynamically then same variables can be used to sort them. Using variables in the sort process is useful since it eliminates the need to update the Dimension Sort step manually on a periodic basis.
An example that uses the current_month variable to dynamically sort the Materials dimension:
/Dimensions/{current_month}/Products/Materials
Use Specific Dimension
Use the dropdown menu to select a specific dimension to sort.
1.4.6 - Document Steps
1.4.6.1 - Compress PDF
Documentation coming soon...
1.4.6.2 - Concatenate Files
Documentation coming soon...
1.4.6.3 - Convert Document Encoding
Description
Concatenates files to form a single file.
Examples
Create a source input, select the input file and browse for the file within that location. Select the desired output location, and browse to selected the desired location for the file. Save and run.
1.4.6.4 - Convert Document Encoding to ASCII
Description
Updates file encoding and converts all characters to ASCII. This is particularly useful if the source of information has mixed encodings or other tools don’t support certain encodings.
Examples
Select the input file and browse for the file within that location. Select the desired output location, and browse to select the desired location for the file. Save and run.
1.4.6.5 - Convert Document Encoding to UTF-8
Description
Updates file encoding and converts all characters to UTF-8. This is particularly useful if the information source has mixed encodings or other tools don’t support certain encodings.
Examples
Select the input file and browse for the file within that location. Select the desired output location, and browse then select the desired location for the file. Save and run.
1.4.6.6 - Convert Document Encoding to UTF-16
Description
Updates file encoding and converts all characters to UTF-16. This is particularly useful if the information source has mixed encodings or other tools don’t support certain encodings.
Examples
Select the input file and browse for the file within that location. Select the desired output location, and browse then select the desired location for the file. Save and run.
1.4.6.7 - Convert Image to PDF
Documentation coming soon...
1.4.6.8 - Convert PDF or Image to JPEG
Documentation coming soon...
1.4.6.9 - Copy Document Directory
Description
Copy an entire directory within PlaidCloud Document.
Copy Directory
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the directory you’d like to copy.
Select Destination
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the destination for the copied directory.
If desired, the copied directory can be given a new name. To do so, simply check the Rename the Copied Folder to: box and type in a new name.
Examples
No examples yet...
1.4.6.10 - Copy Document File
Description
Copy a single file within PlaidCloud Document.
File To Copy
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the file you’d like to copy.
Select Destination
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the destination for the copied file.
By default, Analyze will not allow files to be overwritten. Instead, a numerical suffix will be added to each subsequent copy.
To overwrite the existing file, simply check the Allow Overwriting Existing File box.
To rename the file, check the Rename the copied file to box and type in a new name.
Examples
No examples yet...
1.4.6.11 - Create Document Directory
Description
Create a new directory within PlaidCloud Document.
Where to Create New Folder
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the parent directory.
New Folder Name
Type the name for the new directory.
Examples
No examples yet...
1.4.6.12 - Crop Image to Headshot
Documentation coming soon...
1.4.6.13 - Delete Document Directory
Description
Delete an existing directory from within PlaidCloud Document.
Folder to Delete
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the directory to delete.
Examples
No examples yet...
1.4.6.14 - Delete Document File
Description
Delete an existing file from within PlaidCloud Document.
File to Delete
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the file to delete.
Examples
No examples yet...
1.4.6.15 - Document Text Substitution
Description
Performs text substitution in the specified file.
Examples
No examples yet...
1.4.6.16 - Fix File Extension
Documentation coming soon...
1.4.6.17 - Merge Multiple PDFs
Documentation coming soon...
1.4.6.18 - Rename Document Directory
Description
Rename an existing directory within PlaidCloud Document.
Folder to Rename
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the directory to be renamed.
Rename To
Type the new name for the directory.
Examples
No examples yet...
1.4.6.19 - Rename Document File
Description
Rename an existing file within PlaidCloud Document.
File to Rename
First, select the appropriate account from the dropdown menu.
Next, press the Browse button to select the file to be renamed.
Rename To
Type the new name for the file.
Examples
No examples yet...
1.4.7 - Notification Steps
1.4.7.1 - Notify Distribution Group
Description
Send an email notification to a PlaidCloud distribution group. Messages are sent from info@tartansolutions.com. No outbound setup is required.
Select PlaidCloud Distribution List
Select a single distribution list from the drop down menu. Distribution lists can be created using Tools. For details on creating a distribution list, see here: PlaidCloud Tools – Distro.
Message
Specify Subject and Body as desired.
Please note that both Project Variables and Workflow Variables are available for use with this transform, in both the subject line and the message body.
Additionally, standard HTML code is permitted in the body to further customize the look of the email messages.
Examples
In this example, all of the system variables are used. Additionally, there is a small bit of HTML used to format the first line of the body. Executing this transform will send the following email to all members specified in the distribution group:
- FROM: info@tartansolutions.com (remember that all messages come from this address)
- Subject: DEMO Analyze Demo Running
1.4.7.2 - Notify Agent
Description
Notify a PlaidCloud Agent.
Examples
No examples yet...
1.4.7.3 - Notify Via Email
Description
Send email notifications. Messages are sent from info@tartansolutions.com email account. No outbound setup is required.
Email Addresses
Specify any number of email recipients. Acceptable delimiters include semicolon (;) and comma (,).
Message
Specify Subject and Body as desired.
Please note that both Project Variables and Workflow Variables are available for use with this transform, in both the subject line and the message body.
Additionally, standard HTML code is permitted in the body to further customize the look of the email messages.
Attachments
Attaching files to emails is very simple. Select a file or folder from Document to attach. If a folder is selected, the contents of the folder will be attached as individual files. Variable substitution works with paths for better control of file attachments when sending out personalized emails.
Examples
In this example, all of the system variables are used. Additionally, there is a small bit of HTML used to format the first line of the body. Executing this transform will send the following email:
- TO: info@tartansolutions.com
- FROM: info@tartansolutions.com (remember that all messages come from this address)
- Subject: DEMO – Workflow Analyze Demo Running
1.4.7.4 - Notify Via Log
Description
Write a message to the Analyze workflow log.
Message Parameters
Type the desired message to write to the log. Then select one of three severity levels from the following:
- Information
- Warning
- Error
Please note that both Project Variables and Workflow Variables are available for use with this transform.
Examples
In this example, executing this transform will append an Information item to the log, stating Write a message to the workflow log. I believe you have my stapler, Demo.
1.4.7.5 - Notify via Microsoft Teams
Adding Microsoft Teams notifications from a workflow is a two part process. The two parts are:
- Create a Microsoft Teams external connection
- Add Microsoft Teams notification steps to your workflows
Add Microsoft Teams Notification Step to Workflow
Adding Microsoft Teams notification steps to the workflow is the same as adding other steps to a workflow. Upon adding the step, open the step configuration, complete the form, and save it. You can now test your Microsoft Teams notification.
Formatting the Microsoft Teams Message
Teams has many formatting options including adding images and mentioning users. Please reference the Teams Message Text Formatting documentation for details.
Create Microsoft Teams External Connection
This is a one-time setup to allow PlaidCloud to send Microsoft Teams notifications on your behalf. Microsoft Teams allows creation of a Webhook App (a generic way to send a notification over the internet). After creating the Webhook App in Microsoft Teams, add the supplied credentials to PlaidCloud to allow its use.
Microsoft Teams Webhook App Creation
These steps will need to be performed by a Microsoft Teams administrator. Follow the steps outlined here for Creating Incoming Webhook (Microsoft Teams Documentation).
PlaidCloud External Connection Setup
These steps will need to be performed by a PlaidCloud workspace administrator with permissions to create External Data Connections. Follow these steps to create the connection:
- Navigate to
Analyze > Tools > External Data Connections - Under the
+ New Connectionselection, pick Microsoft Teams Webhook - Complete the name, description, and paste in the webhook url generated during the webhook creation above. The name provided here will be shown as the selection in the workflow step so it should be descriptive if possible.
- Select the
+ Createbutton
Examples
No examples yet...
1.4.7.6 - Notify via Slack
Adding Slack notifications from a workflow is a two part process. The two parts are:
- Create a Slack Webhook external connection
- Add Slack notification steps to your workflows
Add Slack Notification Step to Workflow
Adding Slack notification steps to the workflow is the same as adding other steps to a workflow. Upon adding the step, open the step configuration, complete the form, and save it. You can now test your Slack notification.
Formatting the Slack Message
Slack has many formatting options including adding images and mentioning users. Please reference the Slack Text Formatting documentation for details.
Create Slack Webhook External Connection
This is a one-time setup to allow PlaidCloud to send Slack notifications on your behalf. Slack allows creation of a Webhook App (a generic way to send a notification over the internet). After creating the Webhook App in Slack, add the supplied credentials to PlaidCloud to allow its use.
Slack Webhook App Creation
These steps will need to be performed by a Slack administrator. Follow these steps to create a Slack Webhook App:
- From Slack, open the workspace control menu and select
Settings & administration > Manage Apps - Select
Custom Integrationsfrom the Apps category list - Select
Incoming Webhooksfrom the list of apps - Select the
Add to Slackbutton - On the next screen, select the Slack Channel you wish to post the messages and continue. This is the default channel that will be used but it can be overridden in each notification including sending DMs to specific individuals.
- Copy the webhook URL displayed. This will be used later so keep it in a safe place. It will look something like this:
https://hooks.slack.com/services/T04QZ1435/G02TGBFTOP8/K9GZrR2ThdJz1uSiL9YeZxoR - You can customize the appearance, name, and emoji before saving. These customizations are only the defaults and these can be overridden on each notification step within a PlaidCloud workflow.
PlaidCloud External Connection Setup
These steps will need to be performed by a PlaidCloud workspace administrator with permissions to create External Data Connections. Follow these steps to create the connection:
- Navigate to
Analyze > Tools > External Data Connections - Under the
+ New Connectionselection, pick Slack Webhook - Complete the name, description, and paste in the webhook url provided in step 6 above. The name provided here will be shown as the selection in the workflow step so it should be descriptive if possible.
- Select the
+ Createbutton
Examples
No examples yet...
1.4.7.7 - Notify Via SMS
Description
Send an SMS message. Messages are sent from info@tartansolutions.com email account. No outbound setup or data is required.
Carrier and Number
From the Mobile Provider dropdown list, select from hundreds of domestic and international providers. For the convenience of the majority of our customers, USA carriers are listed first, followed by all international options listed alphabetically.
Next, specify a valid phone number. Acceptable formats include the following:
- 5555555555
- 555.555-5555
- 555.555.5555
- 555-555-5555
Message
Specify Subject and Message as desired.
Please note that both Project Variables and Workflow Variables are available for use with this transform, in both the subject line as well as the message body.WARNING: Standard data rates may apply for recipients.
Examples
No examples yet...
1.4.7.8 - Notify Via Twitter
Description
Send a Twitter Direct Message (DM) from @plaidcloud.
Twitter Account
Specify the twitter account to receive the DM from @plaidcloud. This user must be following @plaidcloud to receive the message. It is allowable, although not required, to prefix the username with the at sign (@).
Message
Enter the desired message. Analyze will not permit a value longer than 140 characters.
Please note that both Project Variables and Workflow Variables are available for use with this transform.
Examples
In this example, a DM is sent from @PlaidCloud to @tartansolutions. System variables are used in the message. The final message reads, Analyze Demo is running on #PlaidCloud.
1.4.7.9 - Notify Via Web Hook
Description
Send a notification via Web Hook (URL).
Examples
No examples yet...
1.4.8 - Agent Steps
1.4.8.1 - Agent Remote Execution of SQL
Description
Execute specified SQL on a remote database through a PlaidLink Agent connection.
1.4.8.2 - Agent Remote Export of SQL Result
Description
Execute specified SQL on a remote database through a PlaidLink Agent connection and export the result for use by PlaidCloud or other downstream systems.
Examples
No examples yet...
1.4.8.3 - Agent Remote Import Table into SQL Database
Description
Imports specified data into SQL database on a remote system through a PlaidLink Agent connection.
Examples
No examples yet...
1.4.8.4 - Document - Remote Delete File
Description
Deletes a remote file system file using a PlaidLink agent installed within the firewall.
Examples
First, make a selection from the “Agent to Use” dropdown. Next, enter the file or folder path under “File or Folder Path for Delete”. Finally, select “Save and Run Step”.
1.4.8.5 - Document - Remote Export File
Description
Exports a file to a remote file system using a PlaidLink agent installed within the firewall.
Examples
First, make a selection from the “Agent to Use” dropdown. Next, browse for the file or folder path under “File or Folder to Export”. Then enter the location under “Export Path Destination”. Finally, select “Save and Run Step”.
1.4.8.6 - Document - Remote Import File
Description
Imports a remote file system file using a PlaidLink agent installed within the firewall.
Examples
First, make a selection from the “Agent to Use” dropdown. Next, enter the file or folder path under “File or Folder Path for Import”. Then enter the folder destination under “Folder Destination”. Select the file type from the dropdown. Finally, select “Save and Run Step”.
1.4.8.7 - Document - Remote Rename File
Description
Renames or moves a remote file system file using a PlaidLink agent installed within the firewall.
Examples
First, make a selection from the “Agent to Use” dropdown.
Next, enter “Source Path” and “Destination Path”.
Finally, select “Save and Run Step”.
1.4.9 - General Steps
1.4.9.1 - Pass
Description
The Pass Through transform does not do anything. Its purpose as a placeholder is useful during development or when in need of a separator to section off steps during complex workflows.
1.4.9.2 - Run Remote Python
Description
This transform will run a Python file using PlaidLink. The Python file is executed on the remote system.
A set of global variables can be passed from the script execution on the remote system.
Examples
No examples yet...
1.4.9.3 - User Defined Transform
Description
The Standard Workflow Transforms that come with PlaidCloud can typically perform nearly every operation you’ll need. Additionally, these Standard Transforms are continuously optimized for performance, and they provide the most robust data. However, when the standard options, used singularly or in groups, are not able to achieve your goals, you can create User Defined Transforms to meet your needs. PlaidCloud enables use of standard Python code including many advanced packages.
Coding with Python is required to create a User Defined Transform. For additional information, please visit the Python website.
User Defined Transforms
There are two ways to create User Defined Functions (UDF):
- Write and maintain the logic directly in PlaidCloud
- Connect to a Git repository and point to a file
In addition to using standard python, all PlaidCloud API functions are readily available to natively interact with PlaidCloud. Advanced analytics packages such as SciPy, PySpark, Pandas, and many more are ready for import.
Write and Maintain PlaidCloud Stored UDF
To create a new User Defined Function (UDF), open the workflow which needs the custom transform, select the User Defined tab, and click the Add User Defined Function button. Specify an ID for the UDF. Once created, select the Edit function logic icon (far left) to open the “Edit User Defined Function” window.
Alternatively, a previously created User Defined function can be imported using the Import button from within the User Defined tab. Simply press that button and then select the appropriate workflow from the dropdown menu (this menu contains all workflows within the current workspace). Next, select the function(s) to be imported and press the Import Selected Functions button.
Once the function has been created/imported, proceed to the Analyze Steps tab of the workflow and add a User Defined Transform step in the appropriate position, just as you would add a Standard Transform. In the config window, select the Analyze UDF as the type and then select the appropriate User Defined Function from the dropdown menu.
Reference UDF in Git Repository
First, you will need to create a connection to the Git repository (e.g. Github, Gitlab, etc...) in the External Data Connections area.
Once the Git repository connection is available proceed to the Analyze Steps tab of the workflow and add a User Defined Transform step in the appropriate position, just as you would add a Standard Transform. In the config window, select External Source Code Repository as the type and then select the Connection, Branch, and File path to the UDF. The Branch selection also supports selecting tags to enable standard release processes.
Changes to the files in Git will automatically be reflected the next time the UDF is executed.
Configuration of Source and Target Tables
While it possible to directly access tables in a UDF without defining them in the UDF Transform configuration, table dependencies will not be available. Therefore, it is recommended that all table sources and targets used in the UDF are defined in the configuration. Defining tables in the configuration also makes them readily available for use within the UDF in a more straightforward way (see below).
Additional Variable Specification
Both Project and Workflow level variables are available with in the UDF using standard API methods, however, often there are additional, step specific, variables that are useful. These can be defined in the Other Variables section of the configuration.
Variable values can be manually set or dynamically defined using combinations of Project and Workflow variables.
Python UDF Examples
Common Imports with PlaidCloud API Connection Setup
### COMMON PYTHON IMPORTS
# import os
# import pandas as pd
# import numpy as np
### COMMON PLAIDCLOUD IMPORTS
from plaidcloud.utilities.connect import PlaidConnection
from plaidcloud.utilities import frame_manager as fm
# from plaidcloud.utilities import data_helpers as dh
conn = PlaidConnection()
Set Log Messages in the Application Log
conn.logger.info('Sample Info Log Message')
conn.logger.warn('Sample Warning Log Message')
conn.logger.error('Sample Error Log Message')
Accessing Project and Workflow Variables
workflow_vars = conn.analyze.workflow.variable_values(project_id=conn.project_id, workflow_id=conn.workflow_id)
variable_1 = workflow_vars.get('my_wf_var_1')
project_vars = conn.analyze.project.variable_values(project_id=conn.project_id)
variable_2 = project_vars.get('my_prj_var_2')
Saving Data to a Table
This example assumes the data exists in a Pandas dataframe.
fm.save(dfImport, name='/path_to_table/OUTBOUND_TABLE_NAME', append=False)
Reading Data from a Table
To use a table, you first need to obtain the table object. Once you have the object you can query it using the get_data() method. The get_data() method also supports SQLAlchemy syntax to enable advanced query building capabilities. The result of the query is a Pandas dataframe object.
tbl_object = conn.get_table('INBOUND_TABLE_NAME')
dfImport = conn.get_data(tbl_object)
dfImportQuery = conn.get_data(
tblImport.select().with_only_columns(
[tblImport.c.Col1, tblImport.c.Col2]
).where(
tblImport.c.Col1 == 'FilterValue'
)
)
Accessing Data From Defined Source and Target Tables
When using defined source and target tables that were configured in the step configuration, the initial object fetching (i.e. get_table()) is performed automatically. Utilizing the pre-configured tables uses the following process:
# Source Tables as a dict
my_source = conn.udf.source_by_name('my_table')
# All sources as a list
my_sources = conn.udf.sources()
# Target Tables as a dict
my_target = conn.udf.target_by_name('my_table')
# All targets as a list
my_targets = conn.udf.targets()
Accessing Step Variables
Accessing the variables defined in the step configuration is completed using the following process:
# Access variables by name
my_var = conn.udf.variable_by_name('my_var')
# All variables as a list
my_vars = conn.udf.variables()
Reading Files from Document
Accessing files in Document is also straightforward using the PlaidCloud connection. This is an example of a function that gets the contents of the file and saves it to a local path in the run-time container.
def get_from_document(conn, document_account, remote_path, local_file_path):
# accounts = conn.document.view.shared_accounts()
remote_file = base64.b64decode(
conn.document.view.download(
account_id=document_account,
path=remote_path,
)
)
with open(local_file_path, 'wb') as output_file:
output_file.write(remote_file)
return local_file_path
1.4.9.4 - Wait
Description
The Wait transform is used to pause processing for a specified duration. This can be especially helpful when waiting for I/O operations from other systems or for debugging workflows during development.
Duration Parameters
Specify a non-negative integer value using the Duration spinner.
Next, specify the unit of time from the dropdown menu. The following units are available for selection:
- Seconds
- Minutes
- Hours
1.4.10 - PDF Reporting Steps
1.4.10.1 - Report Single
Description
Generates a PDF report based on the defined RML template and input data sources for the report.
Examples
No examples yet...
1.4.10.2 - Reports Batch
Description
Generates many PDF reports based on the defined RML template and input data sources for each report.
Examples
No examples yet...
1.4.11 - Common Step Operations
1.4.11.1 - Advanced Data Mapper Usage
Review
Before jumping into the advanced usage capabilities of the Data Mapper, a brief review of the basic functionality will help.
Data Mapper Configuration
The Data Mapper is used to map columns from the source data to the target data table.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
Advanced Usage
Aggregation Options
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. The following summarization options are available:
| Function | Description |
|---|---|
| Group By | Groups results by the value |
| Count | Number of non-null observations in group |
| Count (including nulls) | Number of observations in group |
| Sum | Sum of values in group |
| Mean | Mean of values in group |
| Median | Median of values in group |
| Mode | Mode of values in group |
| Min | Minimum of values in group |
| Max | Maximum of values in group |
| First | First value of values in group using the sorted order |
| Last | Last value of values in group using the sorted order |
| Standard Deviation | Unbiased standard deviation in group |
| Sample Standard Deviation | Sample standard deviation in group |
| Population Standard Deviation | Population standard deviation in group |
| Variance | Unbiased variance in group |
| Sample Variance | Sample Variance in group |
| Population Variance | Population Variance in group |
| Advanced Non-Group-By | Special aggregation selection when using window functions |
Pick the appropriate summarization method for the column.
When using a Window Function, select Advanced Non-Group-By as the aggregation method. This special selection is required due to the aggregation inherent in the window function already.
Constants
Specifying a value in the Constant column will override the source column value, if specified, and populate the column with the constant value specified.
Cleaners
The Data Mapper provides a convenient point-and-click cleaner capability to apply conversions to the data within a column.
The cleaning operations include the following categories:
- Text Trimming
- Text Formatting
- Text Transformations
- Converting to and from NULL values
- Number Formatting
- Date Parsing
The result of the cleaner selections are converted into a consolidated expression which is viewable in the Expression information.
Expressions
Expressions in the Data Mapper are one of the most powerful and flexible concepts in PlaidCloud. They provide nearly unlimited flexibility while being exceptionally performant, even on extremely large data.
Expressions are written using Python SQLAlchemy syntax along with a few additional helper functions available in PlaidCloud. This allows PlaidCloud to expose the full set of capabilities of the underlying data warehouse (e.g. Greenplum, SAP HANA, Redshift, etc...) directly. In addition, there are many resources available publicly that provide quick references for use of SQLAlchemy operations. By using standard SQLAlchemy syntax, PlaidCloud avoids the common pitfall of creating yet another domain specific syntax.
The expression editor is opened by double-clicking on the expression cell for the column. Once open, the list of columns are shown on the left while an extensive library of functions are shown on the right.
While it is entirely possible to type the expression directly into the editor, it is normally easier to use the point-and-click function and column selection to get started. The library of functions include the following groups:
- Conditions
- Column Specific Conditions
- Conversions
- Dates
- Math
- Text
- Summarizations
- Window Function Operations
- Arrays
- JSON
- PostGIS (Geospatial)
- Trigonmetry
Once you have completed the expression, save the expression so it will be applied to the column.
View examples and expression functions in the Expressions area.
1.4.12 - Allocation By Assignment Dimension
Description
Allocate values based on an assignment dimesion and driver data table.
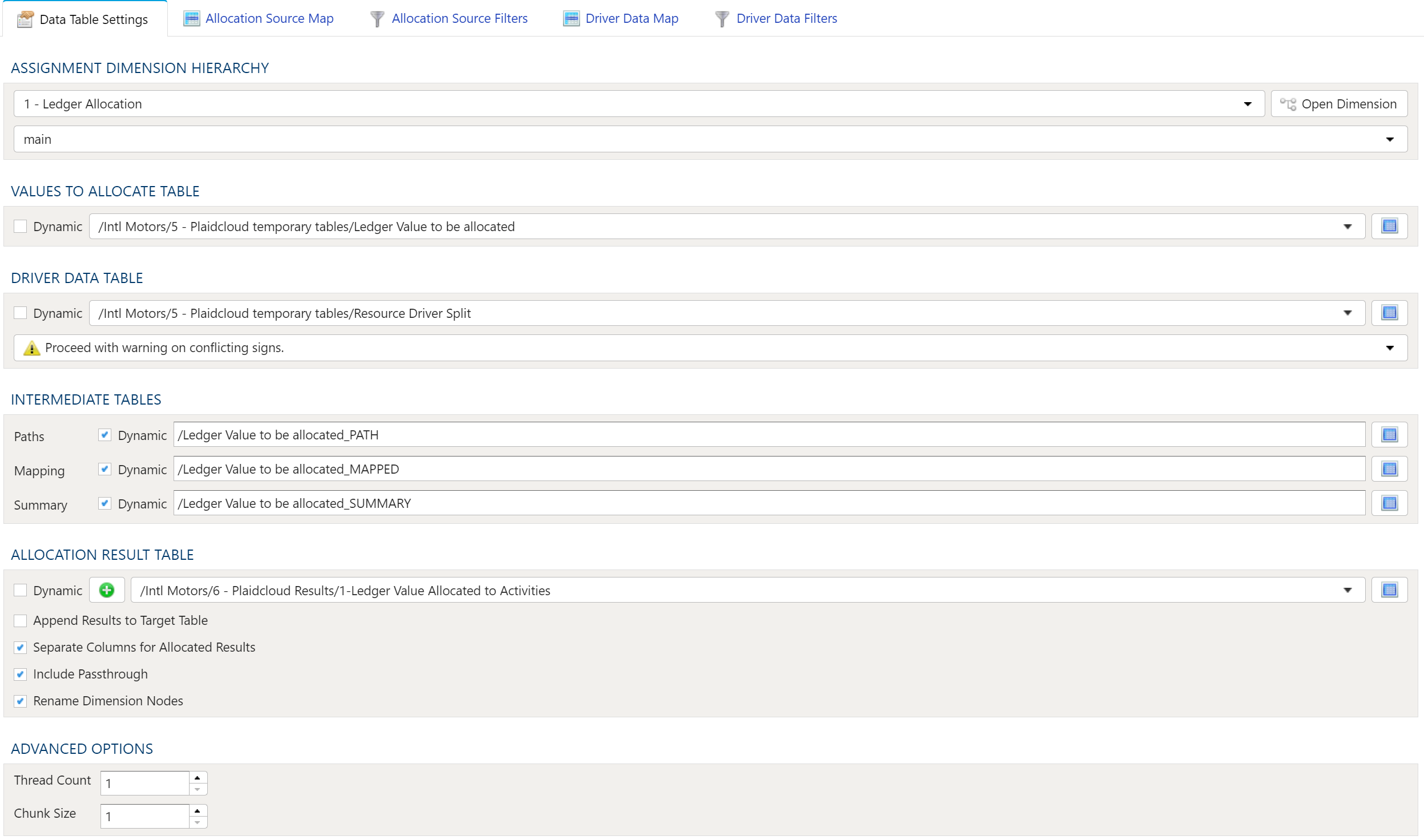
Data Table Settings
Assignment Dimesion Hierarchy
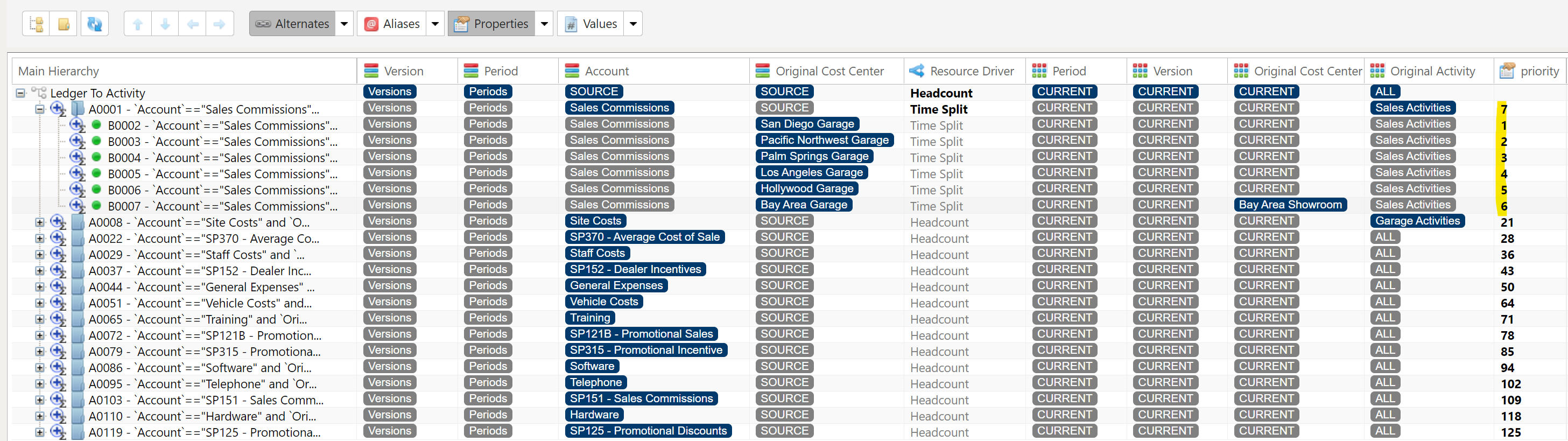
The Assignment Dimension Hierarchy gives the user the ability to point, click and filter either or both the Values To Allocate Table and Driver Data Table to create targeted allocations. The Assignment Dimension Hierarchy is created by combining dimensions that reference the Values To Allocate Table and the Driver Data Table.
Creating An Assignment Dimension Hierarchy
To create the Assignment Dimension Hierarchy you must first create the dimensions you wish to use to as filters for the Values To Allocate Table and the Driver Data Table. The links below will guide you through creating these dimensions.
Creating The Main Hierarchy
Once the dimensions for the Values To Allocate Table and the Driver Data Table have been created the next step is to decide which of the dimensions for the Values To Allocate Table will serve as the Main Hierarchy for the Assignment Dimension Hierarchy.
Copy this dimension by navigating to the Dimensions tab in PlaidCloud, clicking on the dimension and then selecting Actions and Copy Dimension. When you copy the dimension a pop-up will apprear asking you to enter a name for the copied dimension.
Adding Dimensions To The Assignment Hierarchy
Open the newley created Assignment Dimension, click on the down arrow next to Properties and select New Property.
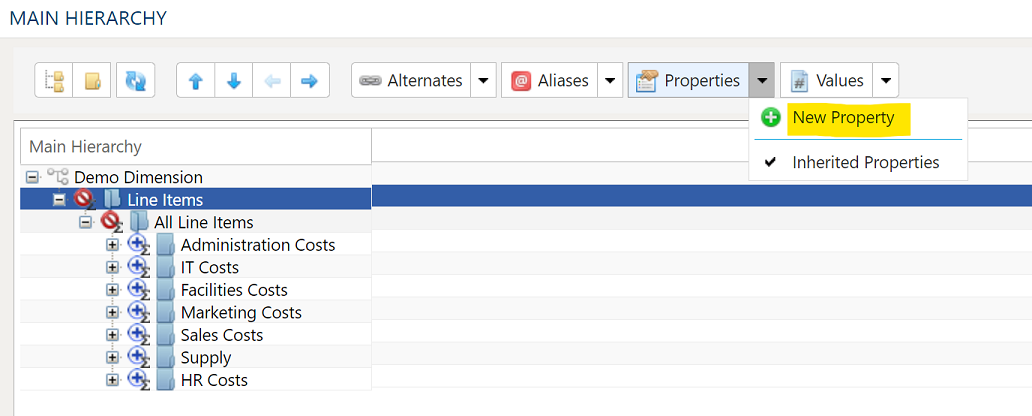
This will open the Property Configuration dialog box:
Property Configuration
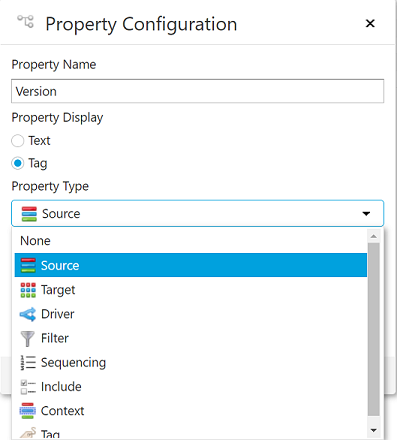
- Property Name - This is normally the name of the dimension that is being added to the Assignment Hierarchy.
- Property Display - This should be set to "Tag".
- Property Type - This property informs the allocation step which table Values To Allocate Table or the Driver Data Table this dimension is related too.
- Source - Is used in conjunction with the Values To Allocate Table.
- Target - Is used in conjunction with the Driver Data Table.
- Driver - Is used to filter Driver Data Table for the specific driver selected.
- Context - When the Values To Allocate Table and the Driver Data Table contain the same dimension then context can be used to specify how the dimensions should relate to one another. Context is often used when both the Values To Allocate Table and the Driver Data Table contain Profit / Cost Centers or Geography.
- Current - Acts as a passthrough and will filter the Driver Data Table based on the settings of the target dimension. An example would be if the Cotext is based on the Profit Center dimension and the Profit Center target dimension is set to ALL then the driver data would filter on all Profit Centers.
- Parent - When selected then the parent of the Profit Center in the Values To Allocate Table will be used to filter the driver values in the Driver Data Table. This is useful when driver values are, at times, not available for a specific Profit Center but often are at the parent level.
- All - When selected then the Profit Center in the Values To Allocate Table will not filter the driver values in the Driver Data Table, driver values for all Profit Centers will be used.Note: When Context is set to ALL or Parent it will override the setting on the target dimension.
- Editor Type - This drop down should be set to Select Dimension.
Once the appropriate properties have been selected for the dimension being added to the Assignment Hierarchy select "Edit Configuration".
Dimension Configuration
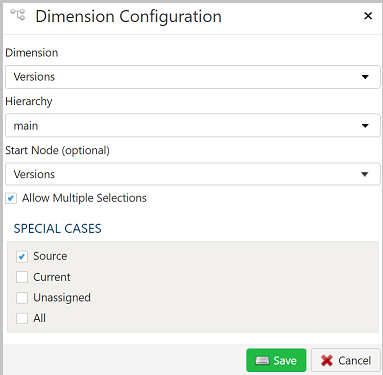
- Dimension - Use the drop down to select the dimension.
- Hierarchy - If the dimension selected has alternate hierarchies, then they will appear and be selectable here as well as the main hierarchy.
- Start Node - If you don't wish the dimension to be displayed from the top node you can select any node within the hierarchy as the node from which the dimension will be displayed.
- Allow Multiple Selections - If checked the user will be able to select multiple nodes in the hierarchy.
- Special Cases - When selected the special cases will be available for selection in the dimension drop down menu. They are typically used in Target dimensions.
- Source - When a dimension is set to Source the allocation will ignore this dimension when it filters the Driver Data Table but the allocated results will include values from the dimension.
- Current - Can be used when a dimension is shared between Source and Target. When the Target dimension is set to Current then the Driver Data Table will be filtered by the current value of the Source dimension as the allocation runs. An example would be if there are multiple periods in the Values To Allocate Table and the Driver Data Table but you want the allocation to allocate within the periods and not acrocss them. It is also common to use Current on Business Units, Cost Centers and Geographies.
- Unassigned - When a dimension is set to Unassigned the allocation will ignore this dimension when it filters the Driver Data Table and the allocation result for this dimension will be a Null value.
- All - When a dimension is set to ALL then the allocation will use all the values in the dimension.
The Values To Allocate Table, Driver Data Table and Allocation Result Table can be selected dynamically or statically.
Dynamic Table Selection
The dynamic table option allows specification of a table using text and variables. This is useful when employing variable driven workflows where the table or view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to a table:
legal_entity/inputs/{current_month}/ledger_values
Static Table Selection
When a specific table is desired as the source, leave the Dynamic box unchecked and select the source table using the dropdown menu.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Values To Allocate Table
This is the table that contains the values that are to be allocated. These are typically cost or revenue values.
Driver Data Table
The driver data table contains the values that the allocation step will use to allocate costs.
Examples:
- For a supply chain to assign costs to customers you might use delivery data with the number of deliveries or the weight of the deliveries as the driver.
- For an IT help desk to assign its costs to the departments it supports the driver data be the number of tickets by cost center.
Driver Data Sign Rule
Driver data can contain both positive and negative values. The Driver Data Sign Rule lets you decide how conflicting signs will be handled.
- Error on conficting signs - Allocation step will produce an error and stop if conflicting signs are encountered.
- Proceed with warning on conflicting signs - Allocation step will use both negative and positive driver values but will display a warning.
- Use only positive driver values - Allocation step will only use positive driver values, will ignore negative values.
- Use only negative driver values - Allocation step will only use negative driver values, will ignore positive values.
- Use absolute values of driver data - Allocation step will use the absolute values of the driver data.
Intermediate Tables
The Intermediate Tables are created each time an allocation step runs and provides a summary of the allocation processing. The Intermediate Tables provide insight into how the alloation process is running an are used to trouble shoot unexpected results.
- Paths - Shows the number of unique allocation paths summarized from the assignment hierarchy.
- Mapping - Shows how each line of the Values To Allocate Table are mapped to the allocation targets.
- Summary - Shows each rule, as a result of the assignment hierachy, and how many of the records from the Values To Allocate Table match it.
Allocation Result Table
Append Results to Target Table
If this box is checked the allocation results will be appended to the allocation result table. If this box is not checked the allocation results table will be overwritten each time the allocation step runs.
Separate Columns for Allocated Results
If this box is checked then the results table will show the amount of each allocated record as well as the amount actually allocated to each driver record.
Rename Dimension Nodes
If this box is checked when the allocation step runs it will rename the dimension node in the Assignment dimension.
Advanced Options
Thread Count
Sets the number of concurrent operations the allocation step will use.
Chunk Size
Set the number of allocation paths within a thread.
Allocation Source Map

The Allocation Source Map is used to map the columns from the Values To Allocate Table that will be used in the allocation step.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Role
Each column in the data mapper must be assigned a role:
- Pass Thought - These columns will appear in the allocation results table.
- Value to Allocate - This is the column that contains the values to be allocated.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Allocation Source Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Driver Data Map

The Allocation Driver Data Map is used to map the columns from the Driver Data Table that will be used in the allocation step.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Role
Each column in the data mapper must be assigned a role:
- Source Relation - These columns have corresponing columns in the Values To Allocate Table.
- Allocation Target - The columns will be the target of the allocation step and will appear in the Allocation Result Table.
- Split Value - This column contains the values that will be used to allocate the values in the Values To Allocate Table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Driver Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Examples
Example 1
Values To Allocate Table
Driver Data Table
Assignment Dimension Hierarchy
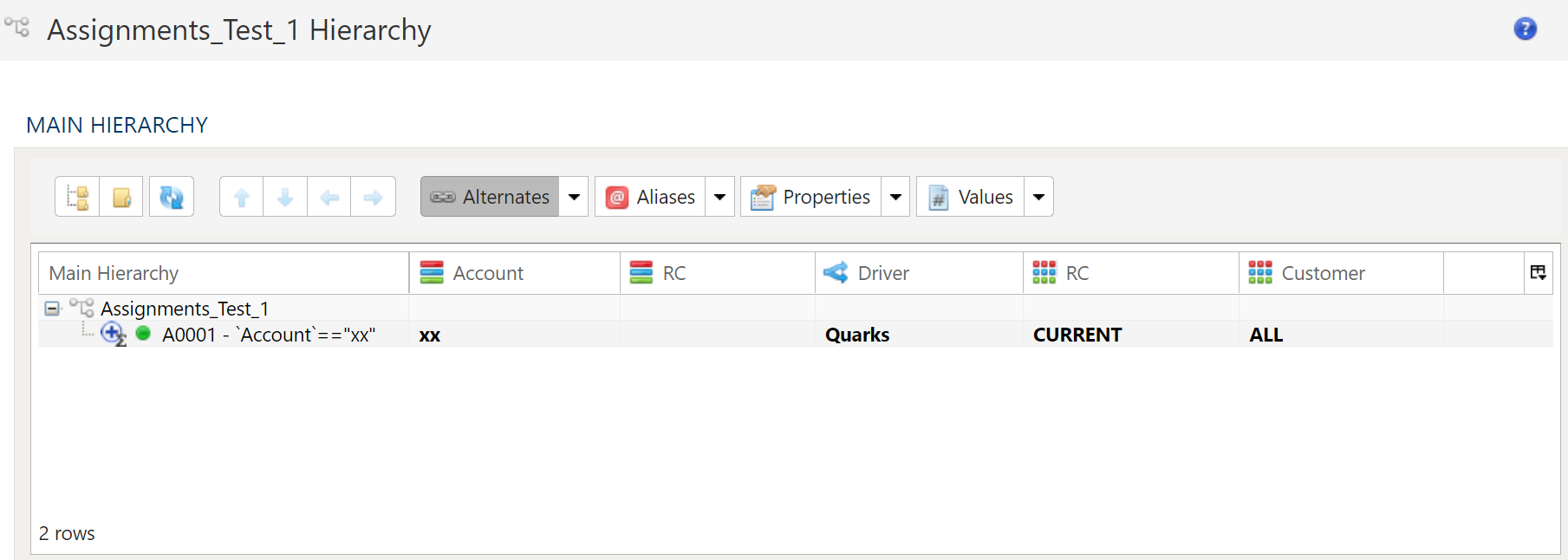
Since the Target RC dimension is set to Current the driver data will be filtered by the Source RC values in the Values To Allocation Table. Since the only value in the Source RC is "A", only the driver value records where RC = A will be used in the allocation step.
Allocation Results Table

Example 2
Values To Allocate Table
Driver Data Table
Assignment Dimension Hierarchy
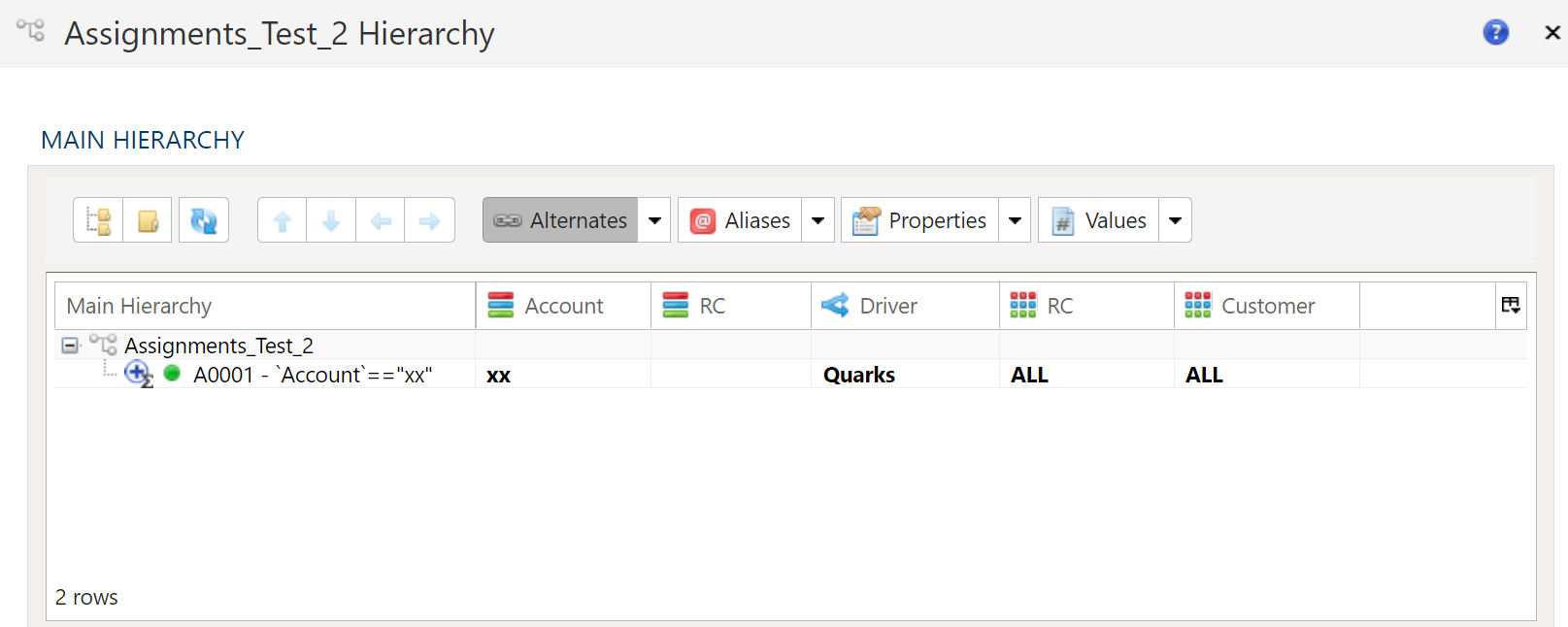
Since the Target RC dimension is set to ALL the driver data will include all RC values as you can see in the RC column in the Allocation Results Table.
Allocation Results Table

Example 3
Values To Allocate Table

Driver Data Table

Assignment Dimension Hierarchy

With the Context RC set to ALL and the Target RC set to Source the driver data will include all the RC in the driver data. The Contect RC will override the setting on the Target RC.
Allocation Results Table

Example 4
Values To Allocate Table
Driver Data Table
Assignment Dimension Hierarchy

With the Context RC set to ALL the driver data will include all the RC in the driver data.
Allocation Results Table

1.4.13 - Allocation Split
Description
Allocate values based on driver data.
Data Table Settings
The Values To Allocate Table, Driver Data Table and Allocation Result Table can be selected dynamically or statically.
Dynamic Table Selection
The dynamic table option allows specification of a table using text and variables. This is useful when employing variable driven workflows where the table or view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to a table:
legal_entity/inputs/{current_month}/ledger_values
Static Table Selection
When a specific table is desired as the source, leave the Dynamic box unchecked and select the source table using the dropdown menu.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Values To Allocate Table
This is the table that contains the values that are to be allocated. These are typically cost or revenue values.
Driver Data Table
The driver data table contains the values that the allocation step will use to allocate costs.
Examples:
- For a supply chain to assign costs to customers you might use delivery data with the number of deliveries or the weight of the deliveries as the driver.
- For an IT help desk to assign its costs to the departments it supports the driver data be the number of tickets by cost center.
Driver Data Sign Rule
Driver data can contain both positive and negative values. The Driver Data Sign Rule lets you decide how conflicting signs will be handled.
- Error on conficting signs - Allocation step will produce an error and stop if conflicting signs are encountered.
- Proceed with warning on conflicting signs - Allocation step will use both negative and positive driver values but will display a warning.
- Use only positive driver values - Allocation step will only use positive driver values, will ignore negative values.
- Use only negative driver values - Allocation step will only use negative driver values, will ignore positive values.
- Use absolute values of driver data - Allocation step will use the absolute values of the driver data.
Allocation Result Table
Append Results to Target Table
If this box is checked the allocation results will be appended to the allocation result table. If this box is not checked the allocation results table will be overwritten each time the allocation step runs.
Separate Columns for Allocated Results
If this box is checked then the results table will show the amount of each allocated record as well as the amount actually allocated to each driver record.
Allocation Source Map
The Allocation Source Map is used to map the columns from the Values To Allocate Table that will be used in the allocation step.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Role
Each column in the data mapper must be assigned a role:
- Pass Thought - These columns will appear in the allocation results table.
- Value to Allocate - This is the column that contains the values to be allocated.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Allocation Source Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
Driver Data Map
The Allocation Driver Data Map is used to map the columns from the Driver Data Table that will be used in the allocation step.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Role
Each column in the data mapper must be assigned a role:
- Source Relation - These columns have corresponing columns in the Values To Allocate Table.
- Allocation Target - The columns will be the target of the allocation step and will appear in the Allocation Result Table.
- Split Value - This column contains the values that will be used to allocate the values in the Values To Allocate Table.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Driver Data Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.14 - Rule-Based Tagging
Description
Rule Based Tagging is used to add attributes contained within a dimesion to a data table.
Data Table Settings
The Source Table and Tagging Result Table can be selected dynamically or statically.
Dynamic Table Selection
The dynamic table option allows specification of a table using text and variables. This is useful when employing variable driven workflows where the table or view references are relative to the variables specified.
An example that uses the current_month variable to dynamically point to a table:
legal_entity/inputs/{current_month}/ledger_values
Static Table Selection
When a specific table is desired as the source, leave the Dynamic box unchecked and select the source table using the dropdown menu.
Table Explorer is always avaible with any table selection. Click on the Table Explorer button to the right of the table selection and a Table Explorer window will open.
Source Table
This is the table that contains the data that you wish to add the attributes from the Assignment Dimension to.
Tagging Result Table
The Tagging Result Table will contain the data from the Source Data Table with the attributes contained in the Assignment Dimension Hierarchy.
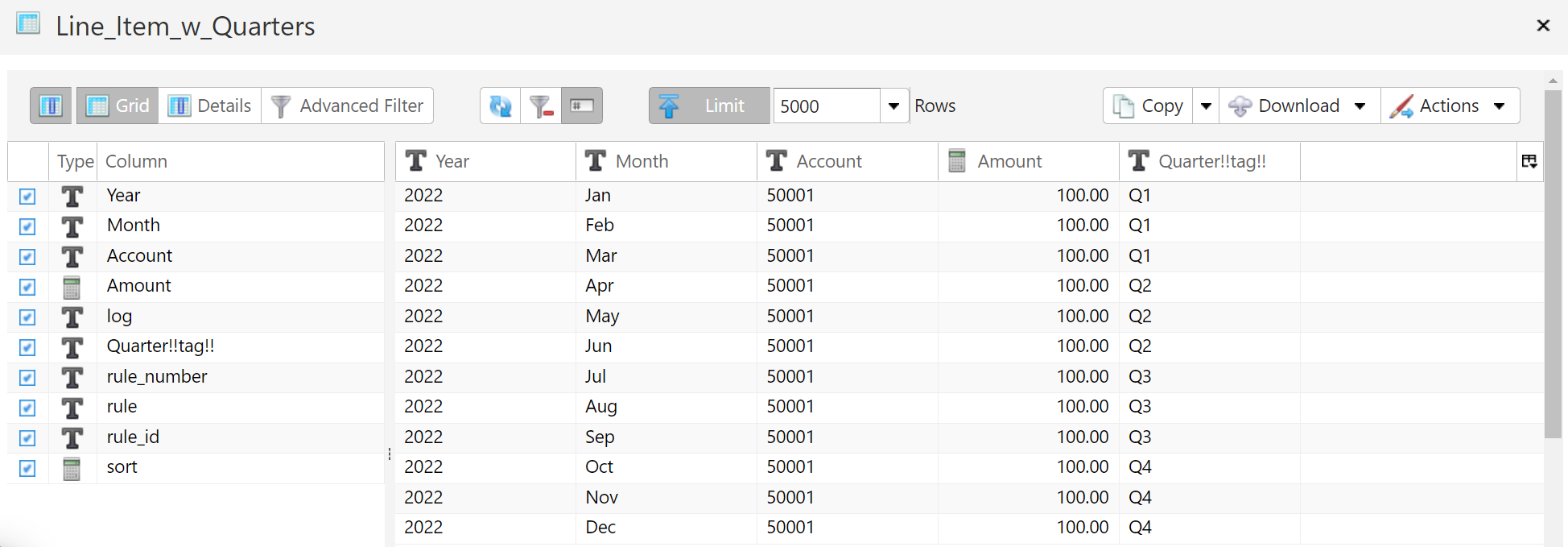
Assignment Dimesion Hierarchy
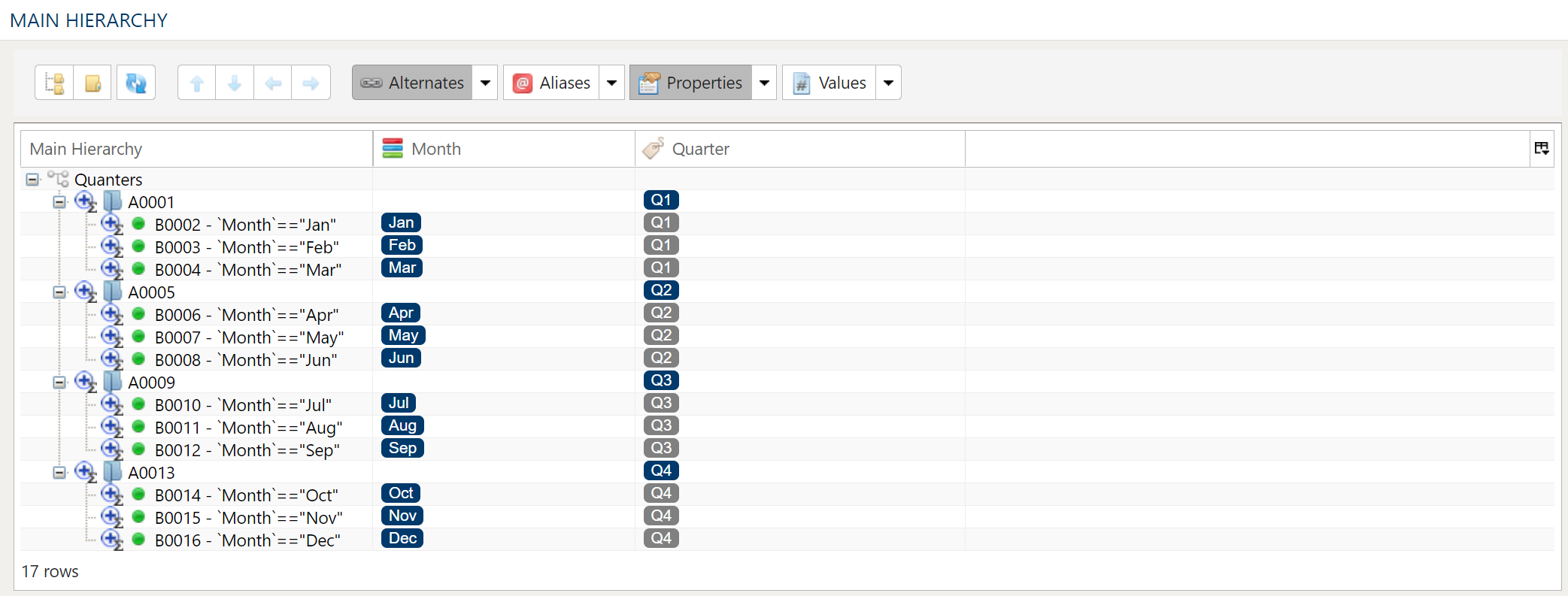
The Assignment Dimension Hierarchy gives the user the ability to point, click and filter the Source Table to add attributes to the Tagging Result Table. The Assignment Dimension Hierarchy is created by combining dimensions that reference the Source Table.
Creating An Assignment Dimension Hierarchy
To create the Assignment Dimension Hierarchy you must first create the dimensions you wish to use to as filters for the Source Table. The links below will guide you through creating these dimensions.
Creating The Main Hierarchy
Once the dimensions for the Source Table have been created the next step is to decide which of the dimensions for the Source Table will serve as the Main Hierarchy for the Assignment Dimension Hierarchy.
Copy this dimension by navigating to the Dimensions tab in PlaidCloud, clicking on the dimension and then selecting Actions and Copy Dimension. When you copy the dimension a pop-up will apprear asking you to enter a name for the copied dimension.
Adding Dimensions To The Assignment Hierarchy
Open the newley created Assignment Dimension, click on the down arrow next to Properties and select New Property.
This will open the Property Configuration dialog box:
Property Configuration
Property Name - This is normally the name of the dimension that is being added to the Assignment Hierarchy.
Property Display - This should be set to "Tag".
Property Type - For Rule Based Tagging property type should be set to Source.
- Source - Is used in conjunction with the Source Table.
Editor Type - This drop down should be set to Select Dimension.
Once the appropriate properties have been selected for the dimension being added to the Assignment Hierarchy select "Edit Configuration".
Dimension Configuration
- Dimension - Use the drop down to select the dimension.
- Hierarchy - If the dimension selected has alternate hierarchies, then they will appear and be selectable here as well as the main hierarchy.
- Start Node - If you don't wish the dimension to be displayed from the top node you can select any node within the hierarchy as the node from which the dimension will be displayed.
- Allow Multiple Selections - If checked the user will be able to select multiple nodes in the hierarchy.
- Special Cases - Are not used in Rule Based Tagging.
Source Map
The Allocation Source Map is used to map the columns from the Values To Allocate Table that will be used in the allocation step.
Inspection and Populating the Mapper
Using the Inspect Source menu button provides additional ways to map columns from source to target:
- Populate Both Mapping Tables: Propagates all values from the source data table into the target data table. This is done by default.
- Populate Source Mapping Table Only: Maps all values in the source data table only. This is helpful when modifying an existing workflow when source column structure has changed.
- Populate Target Mapping Table Only: Propagates all values into the target data table only.
If the source and target column options aren’t enough, other columns can be added into the target data table in several different ways:
- Propagate All will insert all source columns into the target data table, whether they already existed or not.
- Propagate Selected will insert selected source column(s) only.
- Right click on target side and select Insert Row to insert a row immediately above the currently selected row.
- Right click on target side and select Append Row to insert a row at the bottom (far right) of the target data table.
Role
Each column in the data mapper must be assigned a role:
- Pass Thought - These columns will appear in the allocation results table.
- Value to Allocate - This is the column that contains the values to be allocated.
Deleting Columns
To delete columns from the target data table, select the desired column(s), then right click and select Delete.
Changing Column Order
To rearrange columns in the target data table, select the desired column(s). You can use either:
- Bulk Move Arrows: Select the desired move option from the arrows in the upper right
- Context Menu: Right clikc and select Move to Top, Move Up, Move Down, or Move to Bottom.
Reduce Result to Distinct Records Only
To return only distinct options, select the Distinct menu option. This will toggle a set of checkboxes for each column in the source. Simply check any box next to the corresponding column to return only distinct results.
Depending on the situation, you may want to consider use of Summarization instead.
The distinct process retains the first unique record found and discards the rest. You may want to apply a sort on the data if it is important for consistency between runs.
Aggregation and Grouping
To aggregate results, select the Summarize menu option. This will toggle a set of select boxes for each column in the target data table. Choose an appropriate summarization method for each column.
- Group By
- Sum
- Min
- Max
- First
- Last
- Count
- Count (including nulls)
- Mean
- Standard Deviation
- Sample Standard Deviation
- Population Standard Deviation
- Variance
- Sample Variance
- Population Variance
- Advanced Non-Group_By
For advanced data mapper usage such as expressions, cleaning, and constants, please see the Advanced Data Mapper Usage
Source Filters
To allow for maximum flexibility, data filters are available on the source data and the target data. For larger data sets, it can be especially beneficial to filter out rows on the source so the remaining operations are performed on a smaller data set.
Select Subset Of Data
This filter type provides a way to filter the inbound source data based on the specified conditions.
Apply Secondary Filter To Result Data
This filter type provides a way to apply a filter to the post-transformed result data based on the specified conditions. The ability to apply a filter on the post-transformed result allows for exclusions based on results of complex calcuations, summarizaitons, or window functions.
Final Data Table Slicing (Limit)
The row slicing capability provides the ability to limit the rows in the result set based on a range and starting point.
Filter Syntax
The filter syntax utilizes Python SQLAlchemy which is the same syntax as other expressions.
View examples and expression functions in the Expressions area.
1.4.15 - SAP ECC and S/4HANA Steps
1.4.15.1 - Call SAP Financial Document Attachment
Description
Calls an SAP ECC Remote Function Call (RFC) designed to attach a file to specified FI document number.
Examples
RFC Parameters
Select Agent to Use. Select Target Directory from the drop down bar, and browse below for the correct child folder destination for the file. Next, appropriately name the “Target File Name”. Under “Function Call Information”, enter the Function, the Return Value Parameter, and select the parameters.
You can choose to Insert Row or Append Row under the Parameters section, as well as name the parameters and give them values. Choose the Max Concurrent Requests number, and select Wait for RFC to Complete. Save and Run Step.
1.4.15.2 - Call SAP General Ledger Posting
Description
Calls an SAP ECC Remote Function Call (RFC) designed to post a journal entry including applicable VAT and Withholding taxes. This may also run in test mode which will perform a posting process but not complete the posting. This allows for the collection of detectable errors such as an account being closed or a customer not existing in the specified company code specified. The error checking is robust with the ability to return multiple detected errors in a single test.
Examples
RFC Parameters
Select Agent to Use. Select Target Directory from the drop down bar, and browse below for the correct child folder destination for the file. Next, appropriately name the “Target File Name”. Under “Function Call Information”, enter the Function, the Return Value Parameter, and select the parameters.
You can choose to Insert Row or Append Row under the Parameters section, as well as name the parameters and give them values. Choose the Max Concurrent Requests number, and select Wait for RFC to Complete. Save and Run Step.
1.4.15.3 - Call SAP Master Data Table RFC
Description
Calls an SAP ECC Remote Function Call (RFC) designed to access master data tables and retrieves the data in tabular form. This data is then available for transformation processes in PlaidCloud. It also provides the ability to export the master data table structure to a separate file which includes column names, data types, and column order information.
Examples
RFC Parameters
Select Agent to Use. Select Target Directory from the drop down bar, and browse below for the correct child folder destination for the file. Next, appropriately name the “Target File Name”. Under “Function Call Information”, enter the Function, the Return Value Parameter, and select the parameters.
You can choose to Insert Row or Append Row under the Parameters section, as well as name the parameters and give them values. Choose the Max Concurrent Requests number, and select Wait for RFC to Complete. Save and Run Step.
1.4.15.4 - Call SAP RFC
Description
Calls an SAP ECC Remote Function Call (RFC) and retrieves the data in tabular form. This data is then available for transformation processes in PlaidCloud.
Examples
RFC Parameters
Select Agent to Use. Select Target Directory from the drop down bar, and browse below for the correct child folder destination for the file. Next, appropriately name the “Target File Name”. Under “Function Call Information”, enter the Function, the Return Value Parameter, and select the parameters.
You can choose to Insert Row or Append Row under the Parameters section, as well as name the parameters and give them values. Choose the Max Concurrent Requests number, and select Wait for RFC to Complete. Save and Run Step.
Advanced Value Iteration
You can select “No Iterators” at the top of this tab and then select Save and Run Step if desired, or you can specify.
Here, you can select “Specify Argument Values” to Iterate Over and create arguments to then go to the Iteration Value.
Next to Select Iterator Argument to Edit Values, there is the option to Insert Tow, Append Row, Delete Row, Move Down Row, or Move to Bottom Row. Below you can choose Range Iterators using the same drop down menu. The last section is titled “Exclusions for Selected Range Iteration” with the same options per row to add, delete, etc. The excluded values can be entered below. Save and Run Step.
1.4.16 - SAP PCM Steps
1.4.16.1 - Create SAP PCM Model
Description
Creates a blank SAP Profitability and Cost Management (PCM) model.
Our Credentials
PlaidCloud is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown. Enter “Model Name” and select “Model type” from the dropdown (both of which are in the “Model Information” section). Check the “Wait for Copy to Complete” check box, then click “Save and Run Step”.
1.4.16.2 - Delete SAP PCM Model
Description
Deletes SAP Profitability and Cost Management (PCM) models matching the search criteria. Deleting models using this transform allows deletion of many models without having to monitor the process.
Our Credentials
PlaidCloud is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select “Agent to Use” from the dropdown. Select your desired “Model Search Method”. For this example, we’ve selected “Exact Match”. Enter “Model Search Text” (what you are looking for) under “Model Name Information” and decide if the search is case sensitive or not (if so, check the check box). Finally, check the “Wait for Deletion to Complete” and click “Save and Run Step”.
1.4.16.3 - Calculate PCM Model
Description
Starts SAP Profitability and Cost Management (PCM) model calculation process.
Our Credentials
PlaidCloud is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown, enter model name in the “Model Name” field, click the “Wait for Calculation to Complete” check box (if desired), then click “Save and Run Step”.
1.4.16.4 - Copy SAP PCM Model
Description
Copies an SAP Profitability and Cost Management (PCM) model.
Our Credentials
PlaidCloud is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Example
Select Agent to Use from the dropdown, enter “From Model Name” and “To Model Name” in the “Model Information” field, click the “Wait for Copy to Complete” check box, then click “Save and Run Step”.
1.4.16.5 - Copy SAP PCM Period
Description
Copies an SAP Profitability and Cost Management (PCM) model period within the same model.
Our Credentials
PlaidCloud is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown, enter “Model Name”, “From Period Name” and “To Period Name” in the “Model Information” field. Click the “Wait for Copy to Complete” check box, then click “Save and Run Step”.
1.4.16.6 - Copy SAP PCM Version
Description
Copies an SAP Profitability and Cost Management (PCM) model version within the same model.
Our Credentials
PlaidCloud is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown, enter “Model Name”, “Origin Period Name”, and “Destination Period Name” in the “Model Information” field. Click the “Wait for Copy to Complete” check box, then click “Save and Run Step”.
1.4.16.7 - Rename SAP PCM Model
Description
Renames an SAP Profitability and Cost Management (PCM) model.
Our Credentials
PlaidCloud is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown, enter “From Model Name” and “To Model Name” in the “Model Information” field, click the “Wait for Copy to Complete” check box, then click “Save and Run Step”.
1.4.16.8 - Run SAP PCM Console Job
Description
Launches an SAP Profitability and Cost Management (PCM) Console process on the PCM server.
Our Credentials
PlaidCloud is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown, enter console file path in the “Console File Path” field, click the “Wait for Console Job to Complete” check box (if desired), then click “Save and Run Step”.
1.4.16.9 - Run SAP PCM Hyper Loader
Description
Loads an SAP Profitability and Cost Management (PCM) model using direct table loads. This process is significantly faster than Databridge. The Hyper Loader supports virtually all of the current PCM data, assignment, and structure tables.
This is the current list of available loading targets:
- Activity Aliases
- Activity Dimensional Hierarchy
- Activity Driver Aliases
- Activity Driver Dimensional Hierarchy
- Activity Driver Value
- BOM Default Makeup
- BOM External Unit Rate
- BOM Makeup
- BOM Production Volume
- BOM Units Sold
- Cost Object 1 Aliases
- Cost Object 1 Dimensional Hierarchy
- Cost Object 2 Aliases
- Cost Object 2 Dimensional Hierarchy
- Cost Object 3 Aliases
- Cost Object 3 Dimensional Hierarchy
- Cost Object 4 Aliases
- Cost Object 4 Dimensional Hierarchy
- Cost Object 5 Aliases
- Cost Object 5 Dimensional Hierarchy
- Cost Object Assignment
- Cost Object Driver
- Line Item Aliases
- Line Item Detail Aliases
- Line Item Detail Dimensional Hierarchy
- Line Item Detail Value
- Line Item Dimensional Hierarchy
- Line Item Direct Activity Assignment
- Line Item Resource Driver Assignment
- Line Item Value
- Period Aliases
- Period Dimensional Hierarchy
- Resource Driver Aliases
- Resource Driver Dimensional Hierarchy
- Resource Driver Split
- Resource Driver Value
- Responsibility Center Aliases
- Responsibility Center Dimensional Hierarchy
- Revenue
- Revenue Aliases
- Revenue Dimensional Hierarchy
- Service Aliases
- Service Dimensional Hierarchy
- Spread Aliases
- Spread Dimensional Hierarchy
- Spread Value
- Version Aliases
- Version Dimensional Hierarchy
- Worksheet 1 Aliases
- Worksheet 1 Dimensional Hierarchy
- Worksheet 2 Aliases
- Worksheet 2 Dimensional Hierarchy
- Worksheet Value
Our Credentials
PlaidCloud is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown. Enter model name and select the load package storage path location, then select the child folder desired from within. Use the Table Data Selection below to select the source table model and the target load table. Inspect source>>propagate both sides of the table will reveal the data. Click “Save and Run Step” when the data is entered and you have added any expressions.
1.4.16.10 - Stop PCM Model Calculation
Description
Stops an SAP Profitability and Cost Management (PCM) model calculation process.
Our Credentials
PlaidCloud is an official SAP Partner and a preferred vendor of services related to SAP PCM model design and implementation.
Examples
Select Agent to Use from the dropdown, enter “Model Name”, click the “Wait for Copy to Complete” check box, then click “Save and Run Step”.
1.5 - Scheduled Workflows
1.5.1 - Event Scheduler
Description
Scheduling specific workflows can be a useful organization tool, so PlaidCloud provides the ability to do just that. Using event scheduler, you can schedule a workflow to run by month, day, hour, minute, or even on a financial workday schedule. If using the financial workday schedule approach, PlaidCloud also allows configuration of holiday schedules using various holiday calendars.
The Events Table will indicate whether the event is scheduled by month, day, hour and minute, or workday under the event description column.
To view events:
- Open Analyze
- Select “Tools”
- Click “Event Scheduler”
This will open the Events Table showing all the current events configured for the workspace.
Creating an Event
To create an event:
- Open Analyze
- Select “Tools”
- Click “Event Scheduler”
- Click “Add Scheduled Event”
- Complete the required fields
- Click “create”
Limit Running: this section allows you to schedule an event to run for a specific time period and a specific number of times.
Otherwise, you can set the workflow to run using the classic schedule approach.
To use the classic schedule approach:
- Click the “Event Schedule” tab of the Event table
- Under the “Schedule type” select “Use Classic Schedule”
- Select the specific months, hours, minutes, and days you want the workflow to run
To set the workflow to run using the workday schedule approach:
- Click the “Event Schedule” tab of the Event table
- Under the “Schedule type” select “Use Workday Schedule”
- Choose the workday you would like the workflow to run on
Editing an Event
To edit an event:
- Open Analyze
- Select “Tools”
- Click “Event Scheduler”
- Click the edit icon
- Adjust desired fields
- Click “Update”
Deleting an Event
To delete an event:
- Open Analyze
- Select “Tools”
- Click “Event Scheduler”
- Click the delete icon
- Click delete again
Pausing an Event
To temporarily pause an event:
- Open Analyze
- Select “Tools”
- Click “Event Scheduler”
- Click the edit icon
- Uncheck the “Active” checkbox
- Click “Update”
Saving the event after unchecking the active box means the event will no longer run on the specified schedule until it’s reactivated.
Running Events on Demand
To run an event immediately:
- Open Analyze
- Select “Tools”
- Click “Event Scheduler”
- Select the desired event or events
- Click “Run Selected Events”
1.6 - Data Connectors
1.6.1 - Cloud Service Connections
PlaidCloud provides a direct service connections for services that don't use REST or JSON-RPC requests.
The individual service guides will help provide the specific setup necessary to connect.
1.6.1.1 - Quandl Connector
Connection Documentation
Quandl is now Nasdaq Data Link. The documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Service Connection
Documentation under development
1.6.2 - Database and Data Lake Connections
PlaidCloud enables connection directly to databases, data lakes, query engines, and lakehouses. Connections can also utilize a PlaidLink agent if services are behind a firewall.
Since the terms of database, lakehouse, query engine, and potentially others are used to refer to data that can be queried using a connection, we generally treat all of these as "Databases" despite a wide variety of underlying technology that performs the underlying query.
1.6.2.1 - Amazon Athena
Upstream Documentation
Amazon Athena documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.2 - Amazon Redshift
Upstream Documentation
Amazon Redshift has several guides related to use located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.3 - Apache Doris
Upstream Documentation
Apache Doris documentation is here.
The Apache project homepage for Apache Doris is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.4 - Apache Hive
Upstream Documentation
Apache Hive documentation is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Data Lake Connector
Documentation under development
1.6.2.5 - Apache Spark
Upstream Documentation
The Apache Spark documentation is here.
The Apache project is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.6 - Azure Databricks
Upstream Documentation
Azure Databricks documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
In order to obtain the connection credentials necessary for PlaidCloud to communicate with a Databricks warehouse, follow the steps below:
- Open the Databricks console
- Under the User Settings in the upper right, select "Settings"
- Navigate to the "Developers" section
- Generate an Access Token with a sufficient lifespan specified
- Navigate to the "SQL Warehouses" area
- Select the warehouse required for connecting
- Capture the connection details including host, and http path
- Navigate to the warehouse data area
- Capture the initial catalog and initial schema information
With the information above, the connection form can be completed and tested with the Databricks warehouse
Create Database Connector
Documentation under development
1.6.2.7 - Databend
Upstream Documentation
Databend documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.8 - Exasol
Upstream Documentation
Exasol documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.9 - Greenplum
Upstream Documentation
The Greenplum documentation is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.10 - IBM DB2
Upstream Documentation
The IBM DB2 documentation is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.11 - IBM Informix
Upstream Documentation
IBM Informix documentation is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.12 - Microsoft Fabric
Upstream Documentation
The Microsoft Fabric documentation is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.13 - Microsoft SQL Server
Upstream Documentation
Microsoft SQL Server documentation is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.14 - MySQL
Upstream Documentation
MySQL documentation is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.15 - ODBC
Upstream Documentation
Using the ODBC connector will require configuration specific to the database. While ODBC is a generic connection type, each database may implement some specific configurations. Please refer to the ODBC documentation for the target database.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.16 - Oracle
Upstream Documentation
The Oracle database documentation is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.17 - PlaidCloud Lakehouse
Upstream Documentation
There is very little configuration necessary for using the built-in PlaidCloud Lakehouse. The documentation for the service is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Lakehouse Connector
Documentation under development
1.6.2.18 - PostgreSQL
Upstream Documentation
PostreSQL documentation is located here
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.19 - Presto
Upstream Documentation
The Presto documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.20 - SAP HANA
Upstream Documentation
The SAP HANA documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.21 - Snowflake
Upstream Documentation
The Snowflake documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.22 - StarRocks
Upstream Documentation
StarRocks documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.2.23 - Trino
Upstream Documentation
The Trino documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Database Connector
Documentation under development
1.6.3 - ERP System Connections
PlaidCloud provides a direct connections for ERP systems.
The individual service guides will help provide the specific setup necessary to connect.
1.6.3.1 - Infor Connector
Upstream Documentation
The Infor documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create ERP Connection
Documentation under development
1.6.3.2 - JD Edwards (Legacy) Connector
Upstream Documentation
The JDE documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create ERP Connection
Documentation under development
1.6.3.3 - Oracle EBS Connector
Upstream Documentation
The Oracle EBS documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Oracle EBS utilizes the standard Oracle database connection. This connection provides the connectivity to query, load, and execute PL/SQL programs in Oracle.
If the EBS instance has the REST API interface available, this can be accessed using the same approach as Oracle Cloud REST connection too.
Create ERP Connection
Documentation under development
1.6.3.4 - Oracle Fusion Connector
Upstream Documentation
The Oracle Fusion applications documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create ERP Connection
Documentation under development
1.6.3.5 - SAP Analytics Cloud Connector
Upstream Documentation
The SAP Analytics Cloud documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create SAC Connection
Documentation under development
1.6.3.6 - SAP ECC Connector
Upstream Documentation
SAP has removed all ECC documentation and currently only provides documentation for S/4HANA.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create ERP Connection
Documentation under development
1.6.3.7 - SAP Profitability and Cost Management (PCM) Connector
Upstream Documentation
The SAP PCM legacy documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create PCM Connection
Documentation under development
1.6.3.8 - SAP Profitability and Performance Management (PaPM) Connector
Upstream Documentation
The SAP PaPM documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create PaPM Connection
Documentation under development
1.6.3.9 - SAP S/4HANA Connector
Upstream Documentation
The documentation for SAP S/4HANA is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create ERP Connection
Documentation under development
1.6.4 - Git Repository Connections
PlaidCloud provides a direct connections for Git repositories.
The individual service guides will help provide the specific setup necessary to connect.
1.6.4.1 - AWS CodeCommit Repository Connector
Service Documentation
The AWS CodeCommit service documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Git Connection
Documentation under development
1.6.4.2 - Azure Repos Repository Connector
Service Documentation
The Azure Repos service documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Git Connection
Documentation under development
1.6.4.3 - BitBucket Repository Connector
Service Documentation
The BitBucket service documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Git Connection
Documentation under development
1.6.4.4 - GitHub Repository Connector
Service Documentation
The GitHub service documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Git Connection
Documentation under development
1.6.4.5 - GitLab Repository Connector
Service Documentation
The GitLab service documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Git Connection
Documentation under development
1.6.5 - Google Service Connections
PlaidCloud provides a direct connections for Google services.
The individual service guides will help provide the specific setup necessary to connect.
1.6.5.1 - Google BigQuery Connector
Connection Documentation
The Google BigQuery documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Query Connection
Documentation under development
1.6.5.2 - Google Sheets
Connection Documentation
Google Sheets is oriented more towards consumers. For technical documentation, refer to the developer documentation here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Spreadsheet Connection
Documentation under development
1.6.6 - Open Table Format Connections
PlaidCloud provides a direct connections for Open Table Formats for use with the PlaidCloud Lakehouse service. This allows for hybrid query execution without moving data.
The individual service guides will help provide the specific setup necessary to connect.
1.6.6.1 - Apache Hive Open Table Format
Catalog Documentation
Apache Hive documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Catalog Connection
Documentation under development
1.6.6.2 - Apache Hudi Open Table Format
Catalog Documentation
Apache Hudi documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Catalog Connection
Documentation under development
1.6.6.3 - Apache Iceberg Open Table Format
Catalog Documentation
Apache Iceberg documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Catalog Connection
Documentation under development
1.6.6.4 - Delta Lake Open Table Format (Databricks Catalog)
Catalog Documentation
The Delta Lake documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Catalog Connection
Documentation under development
1.6.7 - REST Connections
PlaidCloud provides a comprehensive way to connect to any REST service using standard authentication processes. However, it is quite common that REST based services have nuanced differences in how authentication takes place and the parameters needed for a successful handshake.
The individual service guides will help provide the specific setup necessary to connect.
In addition to the specific REST connectors, PlaidCloud also provides a generic REST connector that can be configured to connect and process responses from other REST services.
1.6.7.1 - Gusto REST Connector
API Documentation
The API documentation is for this connector is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create REST Connector
Documentation under development
1.6.7.2 - Microsoft Dynamics 365 REST Connector
API Documentation
The API documentation is for this connector is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create REST Connector
Documentation under development
1.6.7.3 - Mulesoft REST Connector
API Documentation
The API documentation is for this connector is determined by the service endpoints for which Mulesoft is handling.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create REST Connector
Documentation under development
1.6.7.4 - Netsuite REST Connector
API Documentation
The API documentation is for this connector is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create REST Connector
Documentation under development
1.6.7.5 - Paycor REST Connector
API Documentation
The API documentation is for this connector is located here.
Paycor Setup
The Paycor API Application and Initiation process is a little more involved than other REST providers. Please be sure to go through the steps outlined on their Quick Start Page
Key values you must capture are:
- Application OAuth Client ID
- Application OAuth Client Secret
- APIm Subscription Key
- Scope Key of
currentapplication version
Activate it here, choosing Production or Sandbox depending on your need:
| Environment | Activation Form URL |
|---|---|
| Sandbox | https://hcm-demo.paycor.com/AppActivation/ClientActivation |
| Production | https://hcm.paycor.com/AppActivation/ClientActivation |
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create REST Connector
Documentation under development
1.6.7.6 - Quickbooks REST Connector
API Documentation
The API documentation is for this connector is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create REST Connector
Documentation under development
1.6.7.7 - Ramp REST Connector
API Documentation
The API documentation is for this connector is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create REST Connector
Documentation under development
1.6.7.8 - Sage Intacct REST Connector
API Documentation
The API documentation is for this connector is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create REST Connector
Documentation under development
1.6.7.9 - Salesforce REST Connector
API Documentation
The API documentation is for this connector is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create REST Connector
Documentation under development
1.6.7.10 - Stripe REST Connector
API Documentation
The API documentation is for this connector is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create REST Connector
Documentation under development
1.6.7.11 - Workday REST Connector
API Documentation
The API documentation is for this connector is located here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create REST Connector
Documentation under development
1.6.8 - Team Collaboration Connections
PlaidCloud provides a direct connections for team collaboration services.
The individual service guides will help provide the specific setup necessary to connect.
1.6.8.1 - Microsoft Teams Connector
Connection Documentation
Microsoft Teams Admin documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Teams Connection
Documentation under development
1.6.8.2 - Slack Connector
Connection Documentation
Slack Admin documentation is here.
Security Requirements
Documentation under development
Obtain Credentials
Documentation under development
Create Slack Connection
Documentation under development
1.7 - Allocation Assignments
1.7.1 - Getting Started
1.7.1.1 - Allocations Quick Start
Documentation coming soon...
1.7.1.2 - Rule Based Tagging
Documentation coming soon...
1.7.1.3 - Why are Allocations Useful
Documentation coming soon...
1.7.2 - Configure Allocations
1.7.2.1 - Configure an Allocation
Purpose
Allocations enable values (typically costs) to be shredded to a more-granular level by applying a driver. Allocations are used to for a multitude of purposes. including but not limited to Activity-Based Costing, IT & Shared Service Chargeback, calculation of fully loaded cost to produce and provide a good or service to customers, etc. They are a fundamental tool for financial analysis, and a cornerstone for managerial reporting operations such as Customer & Product Profitability. They are also a useful construct for establishing and managing global Intercompany Transfer Prices for goods and services.
Setting up the Allocation transform
From a practical purpose, allocations are set up in PlaidCloud in similar fashion as other data transforms such as joins and lookups. Four configuration parameters must be set in order for an Allocation transform to succeed.
- Specify Preallocated Data: Specify the preallocated data table in the Values To Allocate Table section of the allocation transform.
- Specify Driver Data: Driver data will serve as the basis for the ratios used in the allocation. Choose the driver data table in the Driver Data Table section of the allocation transform.
- Specify the Results Table: Post-allocated data must be stored in a table. Specify the table in the Allocation Result Table section of the allocation result section of the transform.
- Specify the Assignment Dimension: Allocations require an assignment dimension, whose purpose is to provide the prescription for how each record or set of records in the preallocated will be assigned. Specify the the assignment dimension in the Assignment Dimension Hierarchy section of the allocation transform.
Key Concepts
The sum of values in an allocated dataset should tie out to those of the pre-allocated source data
Allocations are accessible in PlaidCloud as a transform option. To set up an allocation, first, set up assignments, and then configure an allocation transform to use the assignments to allocate inbound records using a specified driver table.
Assignments are special dimensions. They are accessed within the Dimensions section of a PlaidCloud Project.
To set up an assignment dimension, perform the following steps:
- From the project screen, Navigate to the Dimensions tab
- Create a new dimension
1.7.2.2 - Recursive Allocations
Content coming soon...
1.7.3 - Results and Troubleshooting
1.7.3.1 - Allocation Results
Content coming soon...
1.7.3.2 - Troubleshooting Allocations
Stranded Cost
Stranded cost is....
Over Allocation of Cost
Over allocation of cost is when you end up with more output cost...
Incorrect Allocation of Cost
Incorrect allocation of costs happens when...
1.8 - Dimensions
1.8.1 - Dimension Functions for Expressions and Aggregations
Functions for use in Dimension Hierarchy Expressions
Within the Dimension Hierarchy screen it is possible to add 'Aggregations' and 'Expressions'. A description for these is included below.
Aggregations
An Aggregation is used to display an aggregated value from a table (which can be 'Sum', 'Count', 'Min' or 'Max') The following image shows an Aggregation that has been configured to pull values from a 'Line Item Values' table so that values can be displayed for each 'Period' in the hierarchy.
Aggregations can be filtered so that only items matching the filter are displayed. In the following image we have set up the aggregation to show values for a selected item in the 'Account' dimension.
If these filters are left blank then the data can be filtered by using the dimension filter bar at the top of the screen, as can be seen in the following image:
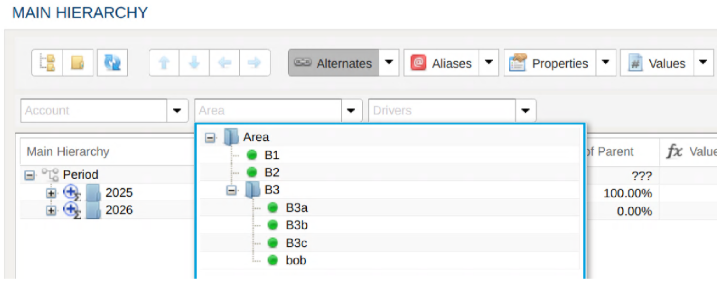
Expressions
Using Expressions it is possible to display values which are calculated based on values from Aggregations displayed for the dimension. Expressions are built using mathematical formulae, which can contain many kinds of operators, and some special functions. The list of operators available can be found here. The functions available are described below
Functions
column(<column_name>)
Fetch a value from a named column for the current row/node.
Below we see an example of an Expression being defined to display the result of multiplying the Line Item Value by 2.
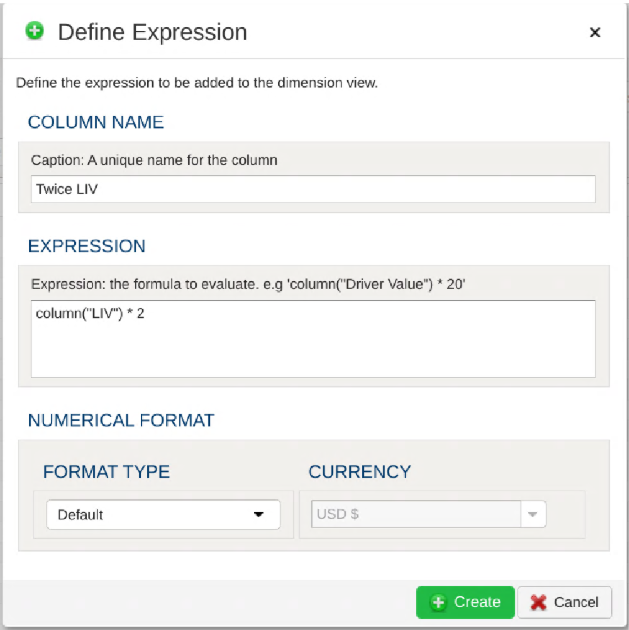
childCount()
Returns the number of children for the current row/node. If the current row/node is a leaf item this will return 0.
In the following example this is being used to return the average value for the child nodes of a parent node.
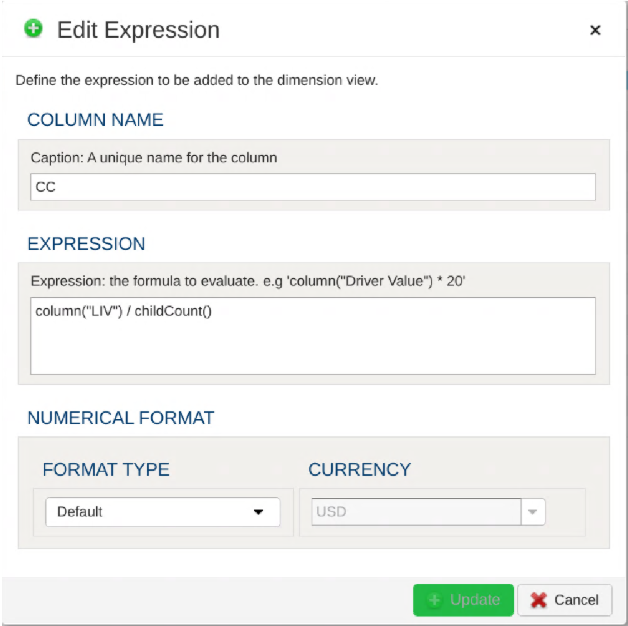
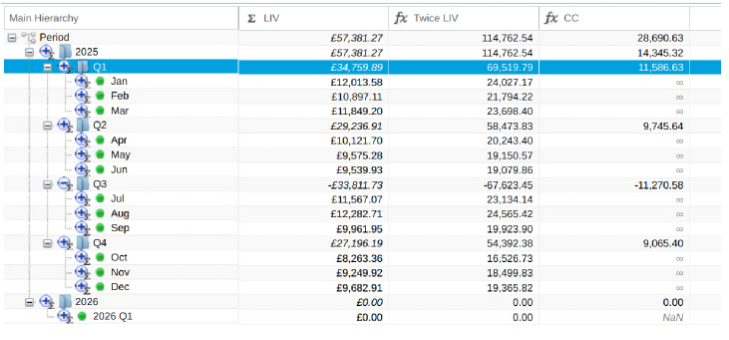
leafCount()
Returns the number of leaf items found in the tree for the current row/node. If the current row/node is a leaf item this will return 1.
descendantCount()
Returns the total number of items found in the tree for the current row/node. If the current row/node is a leaf item this will return 0.
siblingCount()
Returns the number of sibling items for the current row/node. The value returned includes the current node.
nodeValue("<node_name>","<column_name>")
Returns the value from a named column for a named node. Here's an example which is used to show the percentage of the "LIV" total for each row/node.
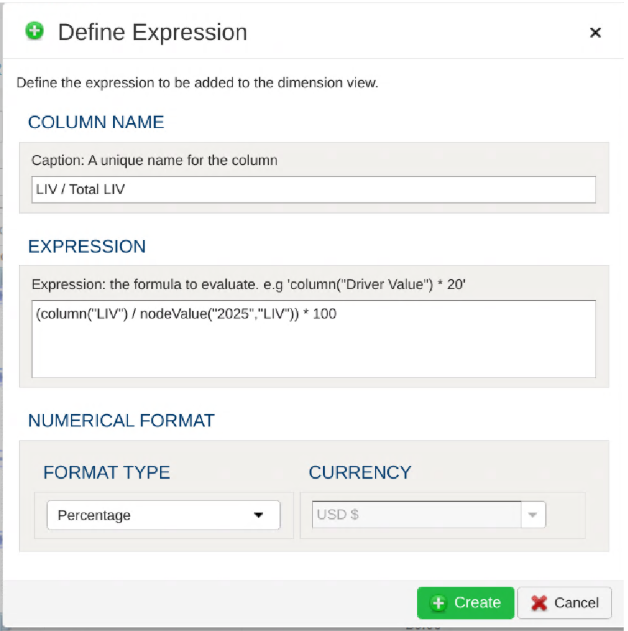
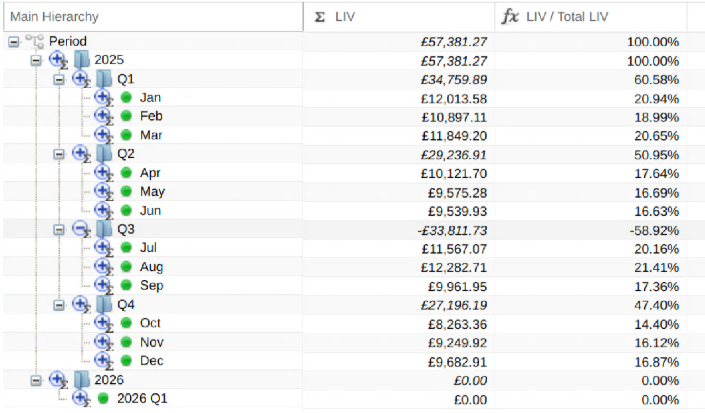
parentValue("<column_name")
Returns the value from a given column for the parent of the current node. This example shows the percentage of the value from a parent node being used by a child node.
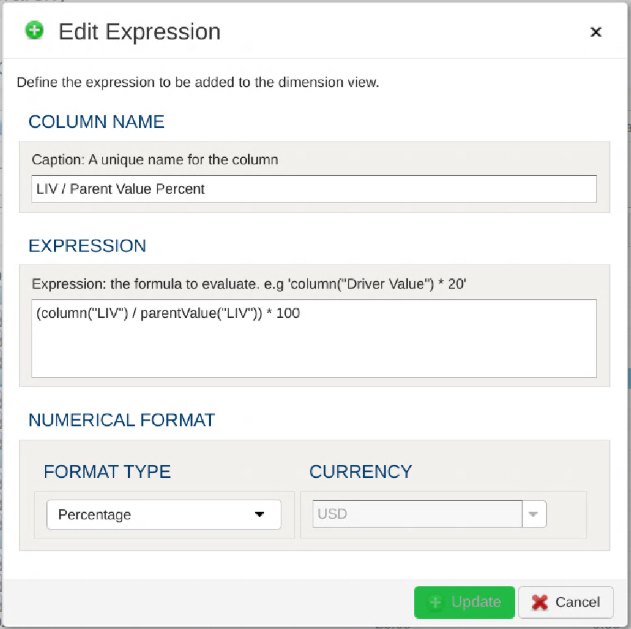
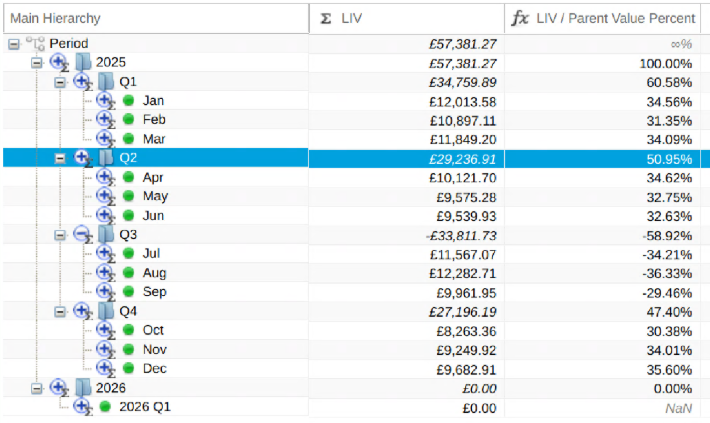
columnTextCompare("<column_name", "")
Returns a numerical result representing if the text in a named column is greater than, less to, or equal to a provided value.
If the text from the column equals the provided text then this function returns 0.
If the text from the column is less than the provided text then this function returns -1.
If the text from the column is greater than the provided text then this function returns 0.
The following example compares the name of the Period to "Jun"
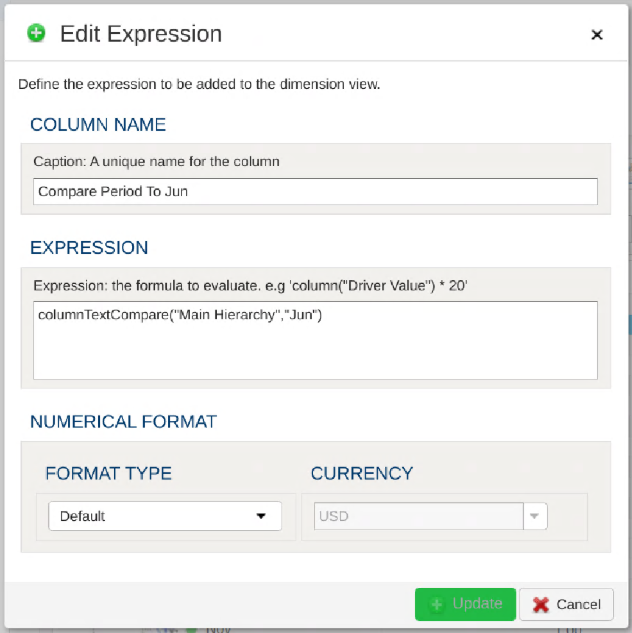
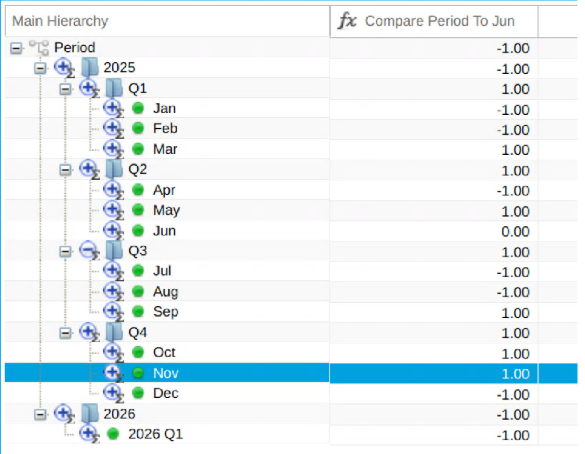
Conditional Expressions
The examples shown above are fairly simplistic. By using conditionals within expressions it is possible to create more complex expressions.
Within Expressions conditionals take the following form:
By combining expressions containing both conditionals and functions we can build more complex expressions, such as this example where 100,000 is added to a Line Item Value if the month is "Jun"

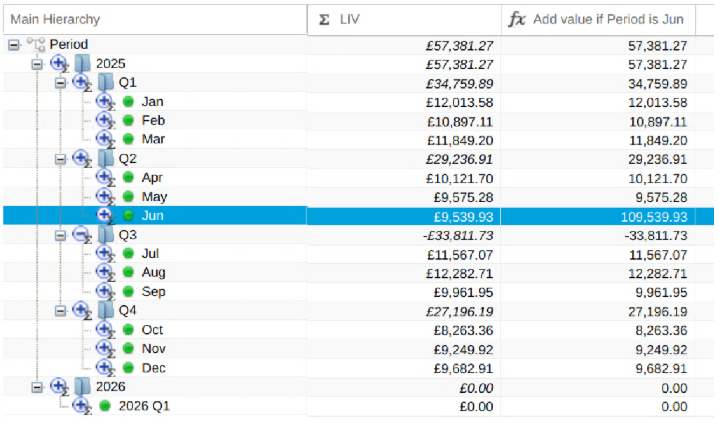
Another example: Simple Allocation
This example shows the amount of a parent's Line Item Value consumed by using the Resource Driver Value for a leaf node.
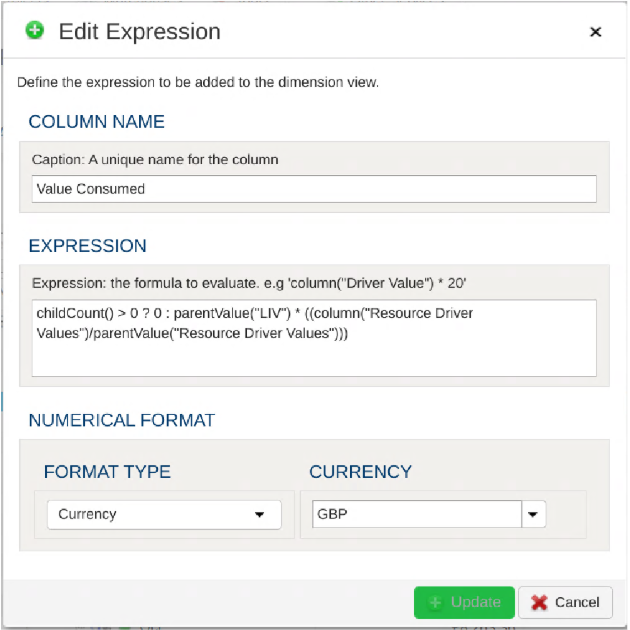
Limitations:
It is currently not possible to build Expressions which are based on values from other Expressions. Expressions can only be built using values from Aggregations.
1.8.2 - Loading and Unloading Dimensions
Dimensions can be maintained from workflow operations by loading data. In addition, dimensional data can be flattened into tabular data and stored in tables. This is often useful for enriching reporting and analytics data.
Loading Dimensions
Since dimensions represent hierarchical data structures, the load process must convey the relationships in the data. PlaidCloud supports two different data structures for loading dimensions:
- Parent-Child - The data is organized vertically with a Parent column and Child column defining each parent of a child throughout the structure
- Levels - The data is organized horizontally with each column representing a level in the hierarchy from left to right
In addition to structure, other dimension information can be included in the load process such as values, aliases, and properties.
See the Workflow Step for Dimension Load for more information.
Unloading (Exporting) Dimensions
Exporting dimensions to tables supports two structural approaches:
- Parent-Child - The data is organized vertically with a Parent column and Child column defining each parent of a child throughout the structure
- Levels - The data is organized horizontally with each column representing a level in the hierarchy from left to right
Properties and values can also be included in the flattened tabular data.
See the Workflow Step for Dimension Unload for more information.
1.8.3 - Using Dimensions (Hierarchies)
PlaidCloud natively manages dimension (i.e. hierarchical) data through our proprietary hierarchy storage system. We decided to construct our own from purpose-built solution because other commercial and open-source solutions seem to present limitations that were not easily overcome.
The hierarchy storage supports not only hierarchical relationships but also properties, aliases, attributes, and values. It is also designed to operate on large structures and perform operations quickly including complex branch and leaf navigation.
Dimensions are managed in the Dimensions tab within each PlaidCloud project configuration area.
Main Hierarchy
Each dimension (i.e. hierarchical dataset) always consists of a main hierarchy. Every member of the hierarchy is represented here.
Having a main hierarchy helps establish the complete set of leaf nodes in the dimension.
Alternate or Attribute Hierarchies
Alternate hierarchies are different representations of the main hierarchy leaf nodes. Alternate hierarchies can consist of a subset of both
leaf nodes and roll-up (i.e. folders) in the main hierarchy as well as its own set of unique roll-ups.
This provides for the maximum amount of flexibility by automatically updating alternate hierarchies when children of a roll-up change or to strictly control the alternate hierarchy members by specifying only the leaf nodes required.
main hierarchy have attribute labels showing alternate hierarchies for which they also belongManaging Dimensions
Creating a Dimension
From the New button in the toolbar, select New Dimension. Enter in the desired name, directory, and a descriptive memo.
Once you press the Create button the dimension will be created and ready for immediate use.
You can also create a dimension from a workflow using the Dimension Create workflow step.
Deleting a Dimension
To delete an existing dimension, select the dimension record and open the Actions menu in the upper right. Select Delete Dimension.
This will delete the dimension and all underlying data.
You can also delete a dimension from a workflow using the Dimension Delete workflow step.
It is also possible to clear the dimension of all structure, values, aliases, properties, and alternate hierarchies without deleting the dimension by using the Dimension Clear workflow step.
Copying a Dimension
To copy an existing dimension, select the dimension record and open the Actions menu in the upper right. Select Copy Dimension.
This will open a dialog where you can specify the name of the copy. Click the Create Copy button to make a copy of the dimension
including values, aliases, properties, and alternate hierarchies.
Sorting a Dimension
The dimension management area makes it easy to move hierarchy members up and down as well as changing parents. It also makes it easy to create and delete members.
However, it can get tedious when manually moving hierarchy items around so you can sort a dimension from a workflow using the Dimension Sort workflow step. This can be a big time saver especially after data loads or major changes.
Dimension Property Inheritance
A dimension may inherit a property from an ancestor. To enable inheritance, click the dropdown next to Properties and select Inherited Properties. All child nodes in the dimension will now inherit the propties of its parents.
Usage Notes:
- Inheritance will happen for all properties in a dimension. You cannot set inheritance on one property but not another.
- If you change and then delete the value of a child property, it will default back to the parent value. You cannot have a null value when the parent has a value.
- If you set the value of a child property, its children will inherit the child property instead of the parent.
- Inheritance will go all the way down to the leaf node.
1.9 - Data Lakehouse Service
1.9.1 - Getting Started
About
The PlaidCloud Data Lakehouse Service (DLS) stands on the shoulders of great technology. The service is based on Databend, a lakehouse suitable for big data analytics and traditional data warehouse operations while supporting vast storage as a data lake. It's extensive analytical optimizations, array of indexing types, high compression, and native time travel capabilities makes it ideal for wide array of uses.
The PlaidCloud DLS also has the ability to integrate with existing data lakes on Apache Hive, Apache Iceberg, and Delta Lake. This allows for accessing vast amounts of already stored data using a modern and fast query engine without having to move any data.
The PlaidCloud DLS continues our goal of providing the best open source options for our customers to eliminate lock-in while also providing services as turn-key solutions.
Managing, upgrading, and maintaining a data lakehouse requires special skills and investment. Both can be hard to find when you need them. The PlaidCloud service eliminates that need while still providing deep technical access for those that need or want total control.
Key Benefits
Always on
The PlaidCloud DLS provides always-on query access. You don't have to schedule availability or incur additional costs for usage outside the expected time.
This also means there is no first-query delay and no cache to warm up before optimal performance is achieved.
Read and Write the way you expect
The PlaidCloud DLS operates like a traditional database so you don't have to decide which instances are read-only or have special processes to load data from a write instance. All instances support full read and write with no special ETL or data loading processes required.
If you are used to using traditional databases, you don't need to learn any new skills or change your applications. The DLS is a drop-in replacement for ANSI SQL compliant databases. If you are coming from other databases such as Oracle, MySQL or Microsoft SQL Server then some adjustments to your query logic may be necessary but not to the overall process.
Since SAP HANA and Amazon Redshift use the PostgreSQL dialect, those seeking a portable alternative will find PlaidCloud DLS a straightforward option.
Economical
With usage based billing, you only pay for what you use. There are no per-query or extra processing charges. Triple redundant storage, incredible IOPS, wide data throughput, time travel queries, and out-of-band backups are all standard at a reasonable price.
We eliminate the headache of having to choose different data warehousing tiers based on optimizing storage costs. We offer the ability to select how long each table's history is kept live for time travel queries and recovery.
Zero (0) days of time travel creates a transient table that will have no time travel or recovery. This is suitable for intermediate tables or tables that can be reproduced from other data.
You can set tables to have from one (1) to ninety (90) days of time travel. During the time travel window you can issue queries to view data at different snapshots or periods along with recovery a table at a point-in-time to a new table. This is an incredibly powerful capability that surpasses traditional backups because the historical state of a table can be viewed with a simple query rather than having to recover a backup.
Highly performant
We employ multiple caching strategies to ensure peak performance.
We also extensively tested optimal compute, networking, and RAM configurations to achieve maximum performance. As new technology and capabilities become available, our goal is to incorporate features that increase performance.
Scale out and scale up capable
The ability to both scale up and scale out are essential for a data lakehouse, especially when it is performing analytical processes.
Scaling up means more simultaneous queries can occur at once. This is useful if you have many users or applications that require many concurrent processes.
Scaling out means more compute power can be applied to each query by breaking the data processing up across many CPUs. This is useful on large data where summarizations or other analytical processes such as machine learning, AI, or geospatial analysis is required.
The PlaidCloud DLS allows scale expansion either on-demand or based on pre-defined events/metrics.
Integrated with PlaidCloud Analyze for Low/No Code operations
Analyze, Dashboards, Forms, PlaidXL, and JupyterLab are quickly connected to any PlaidCloud DLS. This provides point-and-click operations to automate data related activities as well as building beautiful visualizations for reporting and insightful analysis.
From an Analyze project, you can select any DLS instance. This also provides the ability for Analyze projects to switch among DLS instances to facilitate testing and Blue/Green upgrade processes. It also allows quickly restoring an Analyze Project from a DLS point-in-time backup.
Clone
Making a clone of an existing lakehouse performs a complete copy of the source lakehouse. When a clone is made it has nothing shared with the original lakehouse and therefore is a quick way to isolate a complete lakehouse for testing or even a live archive at a specific point in time.
Another important feature is that you can clone a lakehouse to a different data center. This might be desireable if global usage shifts from one region to another or having a copy of a warehouse in various regions for development/testing improves internal processes.
Web or Desktop SQL Client Access
A web SQL console is provided within PlaidCloud. It is a full featured SQL client so it supports most use cases. However, for more advanced use cases, a desktop client or other service may be desired. The PlaidCloud DLS uses standard security and access controls enabling remote connections and controlled user permissions.
Access options allow quick and easy start-up as well as ongoing query and analytics access. A firewall allows control over external access.
DBeaver provides a nice free desktop option that has a Greenplum driver to fully support PlaidCloud DWS instances. They also provide a commercial version called DBeaver Pro for those that require/prefer use of licensed software.
1.9.2 - Pricing
Usage Based
The cost of a PlaidCloud Data Lakehouse instance is determined by a limited number of factors that you control. All costs incurred are usage based.
The factors that impact cost are:
- Concurrency Factor - The size of each compute node in your warehouse instance
- Parallelism Factor - The number of nodes in your warehouse instance
- Allocated Storage - The number of Gigabytes of storage consumed by your warehouse instance
- Network Egress - The number of Gigabytes of network egress. Excludes traffic to PlaidCloud applications within the same region. Ingress is always free.
- Time Travel Period - How many days, weeks, or months to retain time travel history on tables
Storage, backups, and network egress are calculated in gigabytes (GB), where 1 GB is 2^30 bytes. This unit of measurement is also known as a gibibyte (GiB).
All prices are in USD. If you are paying in another currency please convert to your currency using the appropriate rate.
Billing is on an hourly basis. The monthly prices shown are illustrative based on a 730 hour month.
Controlling Factors
Concurrency Factor
| Compute Type | Hourly Cost (streams/hr) | Monthly Cost (streams/month) |
|---|---|---|
| Standard | Contact Us | Contact Us |
Concurrency determines how many simultaneous queries are handled by the DLS instance. This is expressed as a number of process streams. There is not a 1:1 relationship between streams and query capacity since a single stream can handle multiple simultaneous queries. However, as the number of concurrent requests increase, the query duration may exceed the desired response time and an increase in the concurrency factor will help.
From a conceptual standpoint you can view processing streams as vCPUs used to process queries.
The default concurrency factor is 2, which is a good starting point if you are unsure of your needs. It can be adjusted from 1 to 14. If your needs exceed 14, please contact us to increase your concurrency limit.
Parallelism Factor
There is no additional cost per node. The compute cost of the DLS instance is the product of concurrency and parallelism plus the master node.
Parallelism determines how many nodes are in the DLS instance. This is expressed as node count. The number of nodes determines how much compute power can be applied to any single query. By increasing the node count, the computational part of the query can be spread out over many process streams. In addition, the storage throughput is multiplied by the number of nodes, which is very valuable when dealing with large datasets.
For example, if the maximum theoretical write throughput of a single node was 4 TB/sec, a warehouse with 8 nodes would have a theoretical write throughput of 8 x 4 TB/sec = 32 TB/sec. There are many factors that impact write speed including compression level, indexes, table storage type, network overhead, etc... but in general, nodes apply a multiplying factor to data throughput speed.
Allocated Storage
Three types of table storage options are available in a PlaidCloud DLS:
- Regional
- Multi-Regional
| Storage Type | Hourly Cost (GB/hr) | Monthly Cost (GB/month) |
|---|---|---|
| Regional | Contact Us | Contact Us |
| Multi-Regional | Contact Us | Contact Us |
Regional
The storage provides triple redundancy across multiple availability zones in a single region. This is suitable for most workloads that do not need geographically distributed redundancy.
Multi-Regional
This storage provides triple redundancy in each region and is stored in two regions. This provides geographical redundancy and fast failover for data requiring the highest availability.
Network Egress
Network Egress and Ingress charges are dependent on the cloud provider, region, and destination for the traffic. Contact us and we can provide a detailed cost matrix.
Network egress is calculated based on the egress traffic from your PlaidCloud Workspace. In terms of the egress traffic from a DLS instance, traffic to PlaidCloud applications in the same region such as Analyze and Dashboard are excluded. However, if you are connecting directly to the DLS instance through the external access point, egress charges will apply. In addition, if you access DLS instances from different regions using PlaidCloud applications then egress charges will apply.
If you connect between DLS instances in the same region using internal network routing there are no egress charges. However, if you connect using the external endpoint then egress charges will apply.
There is no charge for ingress traffic.
2 - Dashboards
2.1 - Learning About Dashboards
Description
Dashboards support a wide range of use cases from static reporting to dynamic analysis. Dashboards support complex reporting needs while also providing an intuitive point-and-click interface. There may be times when you run into trouble. A member of the PlaidCloud Support Team is always available to assist you, but we have also compiled some tips below in case you run into a similar problem.
Common Questions and Answers for Dashboard
Preferred Browser
Due to frequent caching, Google Chrome is usually the best web browser to use with Dashboard. If you are using another browser and encounter a problem, we suggest first clearing the cache and cookies to see if that resolves the issue. If not, then we suggest switching to Google Chrome and seeing if the problem recurs.
Sync Delay
- Problem: After unpublishing and publishing tables in the Dashboards area, the data does not appear to be syncing properly.
- Solutions: Refresh the dashboard. Currently, old table data is cached, so it is necessary to refresh the dashboard when rebuilding tables.
Table Sync Error
- Problem: After recreating a table using the same published name as a previous table, the table is not syncing, even after hitting refresh on the dashboard, publishing, unpublishing, and republishing the table.
- Solutions: Republish the table with a different name. The Dashboard data model does not allow for duplicate tables, or tables with the same published name and project ID.
Cache Warning
- Problem: A warning popped up on the upper right saying “Loaded data cached 3 hours ago. Click to force-refresh.”
- Solutions: Click on the warning to force-refresh the cache. You can also click the drop-down menu beside “Edit dashboard” and select “Force refresh dashboard” there. Either of these options will refresh within the system and is preferred to refreshing the web browser itself.
Permission Warning
Problem: My published dashboard is populating with the same error in each section where data should be populated: “This endpoint requires the datasource… permission”
Solutions: Check that the datasources are not old. Most likely, the charts are pulling from outdated material. If this happens, update the charts with new datasources.
Problem: I am getting the same permission warning from above, but my colleague can view the chart data.
Solutions: If the problem is that one individual can see the data in the charts and another cannot, the second person may need to be granted permission by someone within the permitted category. To do so:
- Go to Charts
- Select the second small icon of a pencil and paper next to the chart you want to grant access to
- Click Edit Table
- Click Detail
- Click Owners and add the name of the person you want to grant access to and save.
Saving Modified Filters to Dashboard
- Problem: I modified filters in my draft model and want to save them to my dashboard. The filters are not in the list. In my draft model, a warning stated, “There is no chart definition associated with this component, could it have been deleted? Delete this container and save to remove this message.”
- Solutions: Go to “Edit Chart.” From there, make sure the “Dashboards” section has the correct dashboard filled in. If it is blank, add the correct dashboard name.
Formatting Numbers: Breaks
- Problem: My number formatting is broken and out of order.
- Solutions: The most likely reason for this break is the use of nulls in a numeric column. Using a filter, eliminate all null numeric columns. Try running it again. If that does not work, review the material provided here: http://bl.ocks.org/zanarmstrong/05c1e95bf7aa16c4768e or here: https://github.com/apache-superset/superset-ui/issues. Finally, always feel free to reach out to a PlaidCloud Support team member. This problem is known, and a more permanent solution is being developed.
Formatting Numbers
To round numbers to nearest integer:
- Do not use: ,.0f
- Instead use: ,d or $,d for dollars
Importing Existing Dashboard
- Problem: I’m importing an existing dashboard and getting an error on my export.
- Solutions: First, check whether the dashboard has a “Slug.” To do this, open Edit Dashboard, and the second section is titled Slug. If that section is empty or says “null,” then this is not the problem. Otherwise, if there is any other value in that field, you need to ensure that export JSON has a unique slug value. Change the slug to something unique.
2.2 - Using Dashboards
Description
Usually, members will have access to multiple workspaces and projects. Having this data in multiple spots, however, may not always be desirable. This is why PlaidCloud allows the ability to view all of the accessible data in a single location through the use of dashboards and highly intuitive data exploration. PlaidCloud Dashboards (where the dashboards and data exploration are integrated) provides a rich pallet of visualization and data exploration tools that can operate on virtually any size dataset. This setup also makes it possible to create dashboards and other visualizations that combine information across projects and workspaces, including Ad-hoc analysis.
Editing a Table
The message you receive after creating a new table also directs you to edit the table configuration. While there are more advanced features to edit the configuration, we will start with a limited and more simple portion. To edit table configuration:
- Click on the edit icon of the desired table
- Click the “List Columns” tab
- Arrange the columns as desired
- Click “Save”
This allows you to define the way you want to use specific columns of your table when exploring your data.
- Groupable: If you want users to group metrics by a specific field
- Filterable: If you need to filter on a specific field
- Count Distinct: If you want want to get the distinct count of this field
- Sum: If this is a metric you want to sum
- Min: If this is a metric you want to gather basic summary statistics for
- Max: If this is a metric you want to gather basic summary statistics for
- Is temporal: This should be checked for any date or time fields
Exploring Your Data
To start exploring your data, simply click on the desired table. By default, you’ll be presented with a Table View.
Getting a Data Count
To get a the count of all your records in the table:
Change the filter to “Since”
Enter the desired since filter
- You can use simple phrases such as “3 years ago”
Enter the desired until filter
- The upper limit for time defaults is “now”
Select the “Group By” header
Type “Count” into the metrics section
Select “COUNT(*)”
Click the “Query” button
You should then see your results in the table.
If you want to find the count of a specific field or restriction:
- Type in the desired restriction(s) in the “Group By” field
- Run the query
Restricting Result Number
If you only need a certain number of results, such as the top 10:
- Select “Options”
- Type in the desired max result count in the “Row Limit” section
- Click “Query”
Additional Visualization Tools
To expand abbreviated values to their full length:
- Select “Edit Table Config”
- Click “List Sql Metric”
- Click “Edit Metric”
- Click “D3Format”
To edit the unit of measurement:
- Select “Edit Table Config”
- Click “List Sql Metric”
- Click “Edit Metric”
- Click “SQL Expression”
To change the chart type:
- Scroll to “Chart Options”
- Fill in the required fields
- Click “Query”
From here you are able to set axis labels, margins, ticks, etc.
2.3 - Formatting Numbers and Other Data Types
Formatting numbers and other data types
There are 2 ways of formatting numbers in PlaidCloud. One way is to transform the values in the tables directly, and a second (more common way) is to format them on display so the values don't lose precision in the table and the user can see the values in a cleaner, more appropriate way.
When I display a value on a dashboard, how do I format it the way I want? The core way to display a value is through a chart object on a dashboard. Charts can be Tables, Big Numbers, Bar Charts, and so on. Each chart object may have a slightly different place or means to display the values. For example, in Tables, you can change the format for each column, and for a Big Number, you can change the format of the number.
To change the format, edit the chart and locate the D3 FORMAT or NUMBER FORMAT field. For a Big Number chart, click on the CUSTOMIZE tab, and you will see NUMBER FORMAT. For a Table, click on the CUSTOMIZE tab, select a number column (displayed with a #) in CUSTOMIZE COLUMN and you will see the D3 FORMAT field.
The default value is Adaptive formatting. This will adjust the format based on the values. But if you want to fix it to a format (i.e. $12.23 or 12,345,678), then you select the format you want from the dropdown or manually type a different value (if the field allows).
D3 Formatting - what is it?
D3 Formatting is a structured, formalized means to display data results in a particular format. For example, in certain situations you may wish to display a large value as 3B (3 billion), formatted as .3s in D3 format, or as 3,001,238,383, formatted as ,d. Another common example is the decision to represent dollar values with 2 decimal precision, or to round that to the nearest dollar $,d or $,.2f to show dollar sign, commas, 2 decimal precision, and a fixed point notation.
For a deeper dive into D3, see the following site: GitHub D3
General D3 Format
The general structure of D3 is the following:
[[fill]align][sign][symbol][0][width][,][.precision][~][type]
The fill can be any character (like a period, x or anything else). If you have a fill character, you then have an align character following it, which must be one of the following:
> - Right-aligned within the available space. (Default behavior).
< - Left-aligned within the available space.
^ - Centered within the available space.
= - like >, but with any sign and symbol to the left of any padding.
The sign can be:
- - blank for zero or positive and a minus sign for negative. (Default behavior.)
+ - a plus sign for zero or positive and a minus sign for negative.
( - nothing for zero or positive and parentheses for negative.
(space) - a space for zero or positive and a minus sign for negative.
The symbol can be:
$ - apply currency symbol.
The zero (0) option enables zero-padding; this implicitly sets fill to 0 and align to =.
The width defines the minimum field width; if not specified, then the width will be determined by the content. For example, if you have 8, the width of the field will be 8 characters.
The comma (,) option enables the use commas as separators (i.e. for thousands).
Depending on the type, the precision can either indicate the number of digits that follow the decimal point (types f and %), or the number of significant digits (types , g, r, s and p). If the precision is not specified, it defaults to 6 for all types except (none), which defaults to 12.
The tilde ~ option trims insignificant trailing zeros across all format types. This is most commonly used in conjunction with types r, s and %.
types
| Type | Description |
|---|---|
| f | fixed point notation. (common) |
| d | decimal notation, rounded to integer. (common) |
| % | multiply by 100, and then decimal notation with a percent sign. (common) |
| g | either decimal or exponent notation, rounded to significant digits. |
| r | decimal notation, rounded to significant digits. |
| s | decimal notation with an SI prefix, rounded to significant digits. |
| p | multiply by 100, round to significant digits, and then decimal notation with a percent sign. |
Examples
| Expression | Input | Output | Notes |
|---|---|---|---|
| ,d | 12345.67 | 12,346 | rounds the value to the nearest integer, adds commas |
| ,.2f | 12345.678 | 12,345.68 | Adds commas, 2 decimal, rounds to the nearest integer |
| $,.2f | 12345.67 | $12,345.67 | Adds a $ symbol, has commas, 2 digits after the decimal |
| $,d | 12345.67 | $12,346 | |
| .<10, | 151925 | 151,925... | have periods to the left of the value, 10 characters wide, with commas |
| 0>10 | 12345 | 0000012345 | pad the value with zeroes to the left, 10 characters wide. This works well for fixing the width of a code value |
| ,.2% | 13.215 | 1,321.50% | have commas, 2 digits to the right of a decimal, convert to percentage, and show a % symbol |
| x^+$16,.2f | 123456 | xx+$123,456.00xx | buffer with "x", centered, have a +/- symbol, $ symbol, 16 characters wide, have commas, 2 digit decimal |
2.4 - Example Calculated Columns
Description
Data in dashboards can be augmented with calculated columns. Each dataset will contain a section for calculated columns. Calculated columns can be written and modified with PostgreSQL-flavored SQL.
Navigating to a dataset
In order to view and edit metrics and calculated expressions, perform the following steps:
- Sign into plaidcloud.com and navigate to dashboards
- From within visualize.plaidcloud.com, navigate to Data > Datasets
- Search for a dataset to view or modify
- Modify the dataset by hovering over the
editbutton beneathActions
Examples
count
COUNT(*)
min
min("MyColumnName")
max
max("MyColumnName")
coalesce (useful for converting nulls to 0.0, for instance)
coalesce("BaselineCost",0.0)
substring
substring("PERIOD",6,2)
cast
CAST("YEAR" AS integer)-1
concat
concat("Biller Entity" , ' ', "Country_biller")
to_char
to_char("date_created", 'YYYY-mm-dd')
left
left("period",4)
divide
divide, with a hack for avoiding DIV/0 errors
sum("so_infull")/(count(*)+0.00001)
conditional statement
CASE WHEN "Field_A"= 'Foo' THEN max(coalesce("Value_A",0.0)) - max(coalesce("Value_B",0.0)) END
CASE WHEN "sol_otif_pod_missing" = 1 THEN
'POD is missing.'
ELSE
'POD exists.'
END
case when "Customer DC" = "origin_dc" or "order_reason_type" = 'Off Schedule' or "mot_type" = 'UPS' then
'Yes'
else
'No'
end
CASE WHEN "module_type" is NULL THEN '---' ELSE "module_type" END
CASE WHEN "NODE_TYPE" = 'External' THEN '3rd Party' ELSE "ENTITY_LOCATION_DESCRIPTION" END
concatenate
concat("Class",' > ',"Product Family",' > ',"Meta Series")
2.5 - Example Metrics
Description
Data in dashboards can be augmented with metrics. Each dataset will contain a section for Metrics. Metrics can be written and modified with PostgreSQL-flavored SQL.
Navigating to a dataset
In order to view and edit metrics and calculated expressions, perform the following steps:
- Sign into plaidcloud.com and navigate to dashboards
- From within visualize.plaidcloud.com, navigate to Data > Datasets
- Search for a dataset to view or modify
- Modify the dataset by hovering over the
editbutton beneathActions
Examples
Calculated columns are typically additional columns made by combining logic and existing columns.
convert a date to text
to_char("week_ending_sol_del_req", 'YYYY-mm-dd')
various SUM examples
SUM(Value)
SUM(-1*"value_usd_mkp") / (0.0001+SUM(-1*"value_usd_base"))
(SUM("Value_USD_VAT")/SUM("Value_USD_HEADER"))*100
sum(delivery_cases) where Material_Type = Gloves
sum("total_cost") / sum("delivery_count")
various case examples
CASE WHEN
SUM("distance_dc_xd") = 0 THEN 0
ELSE
sum("XD")/sum("distance_dc_xd")
END
sum(CASE
WHEN "FUNCTION" = 'OM' THEN "VALUE__FC"
ELSE 0.0
END)
count
count(*)
First and Cast
public.first(cast("PRETAX_SEQ" AS NUMERIC))
Round
round(Sum("GROSS PROFIT"),0)
Concat
concat("GCOA","CC Code")
3 - Panel Apps
3.1 - Creating and Registering Panel Apps in Plaidcloud
Description
Documentation coming soon...
3.2 - Using Panel Apps in Plaidcloud
Description
Documentation coming soon...
4 - Document Management
4.1 - Adding New Document Accounts
4.1.1 - Add AWS S3 Account
AWS S3 Setup
These steps need to be completed within the AWS console
- Sign into or create an Amazon Web Services (AWS) account
- Go to
All services > Storage > S3in the console - Create a default or test bucket
- Go to
All Services > Security Identity & Compliance > IAM > Usersin the console - Select the
Create Userbutton - When prompted, enter a username and select
Access Key - Programmatic accessonly. Select theNext: Permissionsbutton. - Select the option box called
Attach existing policies directly - In the filter search box type
s3. When the list filters down to S3 related items selectAmazonS3FullAccessby checking the box to the left. Select theNext: Tagsbutton. - Skip this step by selecting the
Next: Reviewbutton - Select the plus icon next to the
WasabiFullAccesspolicy to attach the policy to the user. Select theNextbutton. - Review the User settings and select
Create user - Capture the keys generated for the user by downloading the CSV or copy/pasting the keys somewhere for use later. You will not be able to retrieve this key again so keep track of it. If you need to regenerate a key simply go back to step 5 above.
You should now have everything you need to add your S3 account to PlaidCloud Document.
PlaidCloud Document Setup
- Sign into PlaidCloud
- Select the workspace that the new Document account will reside
- Go to
Document > Manage Accounts - Select the
+ New Accountbutton - Select
Amazon S3as the Service Type - Fill in a name and description
- Leave the Start Path blank or add a start path based on an existing Wasabi account hierarchy. See the use of Start Paths for more information.
- Select an appropriate
Security Modelfor your use case. Leave itPrivateif unsure. - Paste the Access Key created in step 12 above into Public Key/User text field under Auth Credentials
- Paste the Secret Key created in step 12 above into the Private Key/Password text field under Auth Credentials
- Select the Save button and your new Document account is live
4.1.2 - Add Google Cloud Storage Account
Google Cloud Setup
These steps need to be completed within Google Cloud Platform
- Sign into or create a Google Cloud Platform account
- Select or create a project where the Google Cloud Storage account will reside
- Go to
Cloud Storage > Browserin the Google Cloud Platform console - Create a default or test bucket
- Go To
IAM & Admin > Service Accountsin the Google Cloud Platform console - Select the
+ Create Service Accountbutton - Complete the service account information and create the account
- Find the service account just created in the list of service accounts and select
Manage Keysfrom the context menu on the right - Under the
Add Keymenu, selectCreate a Key - When prompted, select JSON format for the key. This will generate the key and automatically download it to your desktop. You will not be able to retrieve this key again so keep track of it. If you need to regenerate a key simply go back to step 8 above.
- Go to
IAM & Admin > IAMin the Google Cloud Platform console - Find the service account you just created and click on the edit permissions icon
- Add
Storage AdminandStorage Transfer Adminrights for the service account and save. Note less permissive rights can be assigned but this will impact the functionality available through Document.
You should now have everything you need to add your GCS account to PlaidCloud Document.
PlaidCloud Document Setup
- Sign into PlaidCloud
- Select the workspace that the new Document account will reside
- Go to
Document > Manage Accounts - Select the
+ New Accountbutton - Select
Google Cloud Storageas the Service Type - Fill in a name and description
- Leave the Start Path blank or add a start path based on an existing GCS account hierarchy. See the use of Start Paths for more information.
- Select an appropriate
Security Modelfor your use case. Leave itPrivateif unsure. - Open the Service Account JSON key file you downloaded in step 10 above and copy the contents
- Paste the contents into the Auth Credentials text area
- Select the Save button and your new Document account is live
4.1.3 - Add Wasabi Hot Storage Account
Wasabi Hot Storage Setup
These steps need to be completed within the Wasabi Hot Storage console
- Sign into or create a Wasabi Hot Storage account
- Go to
Bucketsin the console - Create a default or test bucket
- Go to Users in the console
- Select the
Create Userbutton - When prompted, enter a username and select
Programmatic (create API key)user - Skip the group assignment. Select the
Nextbutton - Select the plus icon next to the
WasabiFullAccesspolicy to attach the policy to the user. Select theNextbutton. - Review the User settings and select
Create User - Capture the keys generated for the user by downloading the CSV or copy/pasting the keys somewhere for use later. You will not be able to retrieve this key again so keep track of it. If you need to regenerate a key simply go back to step 5 above.
You should now have everything you need to add your Wasabi account to PlaidCloud Document.
PlaidCloud Document Setup
- Sign into PlaidCloud
- Select the workspace that the new Document account will reside
- Go to
Document > Manage Accounts - Select the
+ New Accountbutton - Select
Wasabi Hot Storageas the Service Type - Fill in a name and description
- Leave the Start Path blank or add a start path based on an existing Wasabi account hierarchy. See the use of Start Paths for more information.
- Select an appropriate
Security Modelfor your use case. Leave itPrivateif unsure. - Paste the Access Key created in step 10 above into Public Key/User text field under Auth Credentials
- Paste the Secret Key created in step 10 above into the Private Key/Password text field under Auth Credentials
- Select the Save button and your new Document account is live
4.2 - Account and Access Management
4.2.1 - Control Document Account Access
Four types of access restrictions are available for an account: Private, Workspace, Member Only, and Security Group. The type of restriction set for a user is editable at any time from the account form.
Updating Account Access
- Select
Document > Manage Accountswithin PlaidCloud - Enter the edit mode on the account you wish to change
- Select the desired access level restriction located under
Security Model - Select the Save button
Restriction Options
All Workspace Members
This access is the simplest since it provides access to all members of the workspace and does not require any additional assignment of members.
Specific Members Only
This access setting requires assignment of each member to an account. This option is particularly useful when combined with the single sign-on option of assigning members based on a list of groups sent with the authentication. However, for workspaces with large numbers of members, this approach can often require more effort than desired, which is where security groups become useful. To choose specific members only:
- Select the members icon from the Manage Accounts list
- Drag the desired members from the
Unassigned Memberscolumn on the left, to theAssigned Memberscolumn on the right - To remove members, do the opposite
- Select the Save button
Specific Security Groups Only
With this option, permission to access an account is granted to specific security groups rather than just individuals. With access restrictions relying on association with a security group or groups, the administration of accounts with much larger user counts becomes much simpler. To edit assigned groups:
- Select the groups icon from the Manage Accounts list
- Drag the desired groups from the
Unassigned Groupscolumn on the left, to theAssigned Groupscolumn on the right - To remove groups, do the opposite
- Select the Save button
Remote agents
PlaidLink agents will often use Document accounts to store files or move files among systems. To allow remote agents access to Document accounts, agents MUST have permission granted. This is a security feature to limit unwanted access to potentially sensitive information. To add agents:
- Select the agent icon from the Manage Accounts list
- Drag desired agents from the
Unassigned Agentscolumn on the left, to theAssigned Agentscolumn on the right - To remove agents, do the opposite
- Select the Save button
4.2.2 - Document Temporary Storage
Temporary storage may sound counter-intuitive, but real-world use has shown it to be valuable. Typically, permanent storage is used to move large files between members or among other systems, and file cleanup in these storage locations often happens haphazardly, at best. This causes storage to fill with files that shouldn’t be there, eventually requiring manual cleanup.
Temporary storage is perfect for sharing or transferring these types of large files because the files are automatically deleted after 24 hours.
To view temporary storage options
- Go To the
Document > Temp Sharein PlaidCloud
Shared Temporary Storage
Shared temporary storage is viewable by all members of the workspace but is not viewable across workspaces. To access the shared temporary storage area, select the Temp Share menu and click Workspace Temp Share to display a table of files currently in the workspace’s Temp Share area.
To add new files to a shared temporary storage location
- Select the
Temp Sharemenu along the top of the main Document page - Click
Workspace Temp Share - Click
Browseto browse locally stored items - Select the desired file and click
Open - Click
Uploadto upload the file to the temporary storage location
To download existing files from temporary storage
- Click on left-most icon, which represents the file type
To manually delete a file
- Click the red delete icon to the left of the file name.
Additional details on file management can be found below under “File Explorer”.
Personal Temporary Storage
Personal temporary storage is only viewable by the member to which the temp share belongs. This storage option is beneficial because it’s accessible across workspaces. This functionality makes it easy to move or use files across workspaces if the member is working in multiple workspaces simultaneously.
All members of the workspace can upload files to a members personal share as a dropbox.
To upload a file to another member’s personal share:
- Select the
Temp Sharemenu along the top of the main Document page - Select
Drop File to Member Temp.A list of members will be displayed. - Click the left-most icon associated with the member of your choosing
- Click
Browseto browse locally stored items - Select desired file and then click
Open - Click
Uploadto upload the file to the member’s personal storage
Additional details on file uploading can be found below under “File Explorer”.
4.2.3 - Managing Document Account Backups
Document enables the backup of any account on a nightly basis. This feature permits backup across different cloud storage providers and on local systems. Essentially, any account is a valid target for the backup of another account.
The backup process is not limited to a single backup destination. It is possible to have multiple redundant backup locations specified if this is a desired approach. For example, the backup of an internal server to another server may be one location with a second backup sent to Amazon S3 for off-site storage.
By using the prefix feature, it’s possible to have a single backup account contain the backups from multiple other accounts. Each account backup set begins its top level folder(s) with a different prefix, making it easy to distinguish the originating location and the restoration process. For example, if you have three different Document accounts but want to set their backup destination to the same location, using a prefix would allow all three accounts to properly backup without the fear of a name collision.
Reviewing Current Backup Settings
- Go to Document > Manage Accounts
- Select the backup icon for the account you wish to review
Creating a Backup Set
- Go to Document > Manage Accounts
- Select the backup icon for the account for which to create a backup
- Select the
New Backup Setbutton - Complete the required fields
- Select the
Createbutton
The backup process is now scheduled to run nightly (US Time).
Updating a Backup Set
- Go to Document > Manage Accounts
- Select the backup icon for the account for which to edit a backup
- Select the edit icon of the desired backup set
- Adjust the desired information
- Select the
Updatebutton
Deleting a Backup Set
- Go to Document > Manage Accounts
- Select the backup icon for the account for which to edit a backup
- Select the delete icon of the desired backup set
- Select the
Deletebutton
4.2.4 - Managing Document Account Owners
The member who creates the account is assigned as the owner by default. However, Document accounts are designed to support multiple owners. This feature is helpful when a team is responsible for managing account access or when there is member turnover. Adding and removing owners is similar to adding and removing access permissions.
Add or Remove Owners
- Go to
Document > Management Accountsin PlaidCloud - Select the owners icon in the Manage Accounts list
- Drag new owners from the
Unassigned Memberscolumn on the left to theAssigned Memberscolumn on the right - To remove owners, do the opposite
- Select the Save button
Because only owners have the ability to view and edit an account, account administration is set up with two levels:
- The member needs security access to view and manage accounts in general, and
- The member must be an owner of the account to view, manage, and change settings of accounts
4.2.5 - Using Start Paths in Document Accounts
The account management form allows the configuration of the storage connection information and a start path. A start path allows those who use the account to begin browsing the directory structure further down the directory tree. This particular option is useful when you have multiple teams that need segregated file storage, but you only want one underlying storage service account.
The Start Path option in Document accounts is useful for the following reasons:
- When controlling access to sub-directories for specific teams and groups
- Granting access to only one bucket
For example, setting a start path of teams/team_1/ for the Team 1 Document account and teams/team_2 for the Team 2 Document account provides different start points on a shared account. When a member opens the Team 1 Document account they will begin file navigation inside team/team_1. They will not be able to move up the tree and see anything above teams/team_1.
Team 2 would have a similar restriction of not being able to navigate into Team 1's area.
This provides the ability to restrict specific teams to lower levels of the tree while allowing other teams higher level access to the tree while not needing any additional cloud storage complexity like additional buckets or special permissions.
Adding and Updating the Start Path
- Go to Document > Manage Accounts
- Select the account you wish to edit and enter the edit mode
- Add a Start Path in the Start Path text field
- Select the save button
Start Path Format
The path always begins with the bucket name followed by the sub-directories.
<my-bucket>/folder1/folder2/
4.3 - Using Document Accounts
Several file operations are available within a Document Account browser. All operations are accessible from a right-click menu within the file browser. The right-click menu provides specific options depending on whether a folder or file is selected.
To open the file explorer:
- Click on the folder icon (far left) from the list of private or shared accounts
Opening File Explorer
- Go to Document > Shared Accounts
- Select the folder icon (far left) for the account you wish to explore
The various file and folder operations available in the file explorer are detailed below:
- Folders:
- uploading new folders
- creating new folders
- renaming, deleting, and downloading current folders as ZIPs
- Files:
- downloading new files
- renaming, deleting, and refreshing current files.
Upload a File
- Go to Document > Shared Accounts
- Select the folder icon (far left) for the account you wish to explore
- Browse to the desired directory
- Right-click and select
Upload Here
Download a File
- Go to Document > Shared Accounts
- Select the folder icon (far left) for the account you wish to explore
- Browse to the desired directory
- Left-click to select the desired file
- Right-click and select
Download
Rename a File
- Go to Document > Shared Accounts
- Select the folder icon (far left) for the account you wish to explore
- Browse to the desired directory
- Left-click to select the desired file
- Right-click and select
Rename
Move a File
- Go to Document > Shared Accounts
- Select the folder icon (far left) for the account you wish to explore
- Browse to the desired directory
- Left-click to select the desired file
- Drag into desired folder
- Select
Move File
Copy a File
- Go to Document > Shared Accounts
- Select the folder icon (far left) for the account you wish to explore
- Browse to the desired directory
- Left-click to select the desired file
- Right-click and select
Copy
Delete a File
- Go to Document > Shared Accounts
- Select the folder icon (far left) for the account you wish to explore
- Browse to the desired directory
- Left-click to select the desired file
- Right-click and select
Delete
Create a Folder
- Go to Document > Shared Accounts
- Select the folder icon (far left) for the account you wish to explore
- Click “New Top Level Folder”
- Enter a folder name of your choosing
- Click
Create
Rename a Folder
- Go to Document > Shared Accounts
- Select the folder icon (far left) for the account you wish to explore
- Browse to the desired directory
- Left-click to select the desired folder
- Right-click and select
Rename
Move a Folder
- Go to Document > Shared Accounts
- Select the folder icon (far left) for the account you wish to explore
- Browse to the desired directory
- Left-click to select the desired folder
- Drag into desired folder
- Select
Move Folder
Delete a Folder
- Go to Document > Shared Accounts
- Select the folder icon (far left) for the account you wish to explore
- Browse to the desired directory
- Left-click to select the desired folder
- Right-click and select
Delete
Download Folder Contents (zip file)
The Download as Zip option is for downloading many files at once. This option will zip (compress) all contents of the selected folder and download the zip file (.zip extension).
For easy navigation, the zip file retains the directory structure that exists in the file explorer.
- Go to Document > Shared Accounts
- Select the folder icon (far left) for the account you wish to explore
- Browse to the desired directory
- Left-click to select the desired folder
- Right-click and select
Download as ZIP
5 - Expressions
Scalar Functions
- Array Functions Perform array operations
- Bitwise Expression Functions Perform bitwise operations and manipulations
- Conditional Expression Functions Implement conditional logic and case statements
- Context Functions Provide information about the current SQL execution context
- Conversion Functions Convert data types and cast values
- Date & Time Functions Manipulate and format dates and times
- Geospatial Functions Handle and manipulate geospatial data
- Geometry Functions Handle and manipulate geospatial geometry data
- Numeric Functions Perform calculations and numeric operations
- String Functions Manipulate strings and perform regular expression operations
- Searcg Functions Find values using expressions
- Semi-structured and Structured Data Functions Work with JSON and other structured data formats
Aggregate Functions
- Aggregate Functions Calculate summaries like sum, average, count, etc...
- Window Functions Provide aggregate calculations over a specified range of rows
AI Functions
- AI Functions Leverage AI and machine learning capabilities
Specialized Functions
- Hash Functions Generate hash values for data security and comparison
- IP Address Functions Manipulate and analyze IP address data
- UUID Functions Generate and manipulate UUIDs
System and Table Functions
- System Functions Access system-level information and perform control operations
- Table Functions Return results in a tabular format
Other Functions
- Other Miscellaneous Functions A collection of various other functions
- Dictionary Functions Dictionary functions
Full Index
5.1 - Aggregate Functions
Aggregate functions are essential tools in SQL that allow you to perform calculations on a set of values and return a single result.
These functions help you extract and summarize data from databases to gain valuable insights.
| Function Name | What It Does |
|---|---|
| ANY | Checks if any row meets the specified condition |
| APPROX_COUNT_DISTINCT | Estimates the number of distinct values with HyperLogLog |
| ARG_MAX | Finds the arg value for the maximum val value |
| ARG_MIN | Finds the arg value for the minimum val value |
| AVG_IF | Calculates the average for rows meeting a condition |
| ARRAY_AGG | Converts all the values of a column to an Array |
| AVG | Calculates the average value of a specific column |
| COUNT_DISTINCT | Counts the number of distinct values in a column |
| COUNT_IF | Counts rows meeting a specified condition |
| COUNT | Counts the number of rows that meet certain criteria |
| COVAR_POP | Returns the population covariance of a set of number pairs |
| COVAR_SAMP | Returns the sample covariance of a set of number pairs |
| GROUP_ARRAY_MOVING_AVG | Returns an array with elements calculates the moving average of input values |
| GROUP_ARRAY_MOVING_SUM | Returns an array with elements calculates the moving sum of input values |
| KURTOSIS | Calculates the excess kurtosis of a set of values |
| MAX_IF | Finds the maximum value for rows meeting a condition |
| MAX | Finds the largest value in a specific column |
| MEDIAN | Calculates the median value of a specific column |
| MEDIAN_TDIGEST | Calculates the median value of a specific column using t-digest algorithm |
| MIN_IF | Finds the minimum value for rows meeting a condition |
| MIN | Finds the smallest value in a specific column |
| QUANTILE_CONT | Calculates the interpolated quantile for a specific column |
| QUANTILE_DISC | Calculates the quantile for a specific column |
| QUANTILE_TDIGEST | Calculates the quantile using t-digest algorithm |
| QUANTILE_TDIGEST_WEIGHTED | Calculates the quantile with weighted using t-digest algorithm |
| RETENTION | Calculates retention for a set of events |
| SKEWNESS | Calculates the skewness of a set of values |
| STDDEV_POP | Calculates the population standard deviation of a column |
| STDDEV_SAMP | Calculates the sample standard deviation of a column |
| STRING_AGG | Converts all the non-NULL values to String, separated by the delimiter |
| SUM_IF | Adds up the values meeting a condition of a specific column |
| SUM | Adds up the values of a specific column |
| WINDOW_FUNNEL | Analyzes user behavior in a time-ordered sequence of events |
5.1.1 - ANY
Aggregate function.
The ANY() function selects the first encountered (non-NULL) value, unless all rows have NULL values in that column. The query can be executed in any order and even in a different order each time, so the result of this function is indeterminate. To get a determinate result, you can use the ‘min’ or ‘max’ function instead of ‘any’.
Analyze Syntax
func.any(<expr>)
Analyze Examples
func.any(table.product_name).alias('any_product_name')
| any_product_name |
|------------------|
| Laptop |
SQL Syntax
ANY(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any expression |
Return Type
The first encountered (non-NULL) value, in the type of the value. If all values are NULL, the return value is NULL.
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE product_data (
id INT,
product_name VARCHAR NULL,
price FLOAT NULL
);
INSERT INTO product_data (id, product_name, price)
VALUES (1, 'Laptop', 1000),
(2, NULL, 800),
(3, 'Keyboard', NULL),
(4, 'Mouse', 25),
(5, 'Monitor', 150);
Query Demo: Retrieve the First Encountered Non-NULL Product Name
SELECT ANY(product_name) AS any_product_name
FROM product_data;
Result
| any_product_name |
|------------------|
| Laptop |
5.1.2 - APPROX_COUNT_DISTINCT
Estimates the number of distinct values in a data set with the HyperLogLog algorithm.
The HyperLogLog algorithm provides an approximation of the number of unique elements using little memory and time. Consider using this function when dealing with large data sets where an estimated result can be accepted. In exchange for some accuracy, this is a fast and efficient method of returning distinct counts.
To get an accurate result, use COUNT_DISTINCT. See Examples for more explanations.
Analyze Syntax
func.approx_count_distinct(<expr>)
Analyze Examples
func.approx_count_distinct(table.user_id).alias('approx_distinct_user_count')
| approx_distinct_user_count |
|----------------------------|
| 4 |
SQL Syntax
APPROX_COUNT_DISTINCT(<expr>)
Return Type
Integer.
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE user_events (
id INT,
user_id INT,
event_name VARCHAR
);
INSERT INTO user_events (id, user_id, event_name)
VALUES (1, 1, 'Login'),
(2, 2, 'Login'),
(3, 3, 'Login'),
(4, 1, 'Logout'),
(5, 2, 'Logout'),
(6, 4, 'Login'),
(7, 1, 'Login');
Query Demo: Estimate the Number of Distinct User IDs
SELECT APPROX_COUNT_DISTINCT(user_id) AS approx_distinct_user_count
FROM user_events;
Result
| approx_distinct_user_count |
|----------------------------|
| 4 |
5.1.3 - ARG_MAX
Calculates the arg value for a maximum val value. If there are several values of arg for maximum values of val, returns the first of these values encountered.
Analyze Syntax
func.arg_max(<expr>)
Analyze Examples
func.arg_max(table.product, table.price).alias('max_price_product')
| max_price_product |
| ----------------- |
| Product C |
SQL Syntax
ARG_MAX(<arg>, <val>)
Arguments
| Arguments | Description |
|---|---|
<arg> | Argument of any data type that PlaidCloud Lakehouse supports |
<val> | Value of any data type that PlaidCloud Lakehouse supports |
Return Type
arg value that corresponds to maximum val value.
matches arg type.
SQL Examples
Creating a Table and Inserting Sample Data
Let's create a table named "sales" and insert some sample data:
CREATE TABLE sales (
id INTEGER,
product VARCHAR(50),
price FLOAT
);
INSERT INTO sales (id, product, price)
VALUES (1, 'Product A', 10.5),
(2, 'Product B', 20.75),
(3, 'Product C', 30.0),
(4, 'Product D', 15.25),
(5, 'Product E', 25.5);
Query: Using ARG_MAX() Function
Now, let's use the ARG_MAX() function to find the product that has the maximum price:
SELECT ARG_MAX(product, price) AS max_price_product
FROM sales;
The result should look like this:
| max_price_product |
| ----------------- |
| Product C |
5.1.4 - ARG_MIN
Calculates the arg value for a minimum val value. If there are several different values of arg for minimum values of val, returns the first of these values encountered.
Analyze Syntax
func.arg_min(<expr>)
Analyze Examples
func.arg_min(table.name, table.score).alias('student_name')
| student_name |
|--------------|
| Charlie |
SQL Syntax
ARG_MIN(<arg>, <val>)
Arguments
| Arguments | Description |
|---|---|
<arg> | Argument of any data type that PlaidCloud Lakehouse supports |
<val> | Value of any data type that PlaidCloud Lakehouse supports |
Return Type
arg value that corresponds to minimum val value.
matches arg type.
SQL Examples
Let's create a table students with columns id, name, and score, and insert some data:
CREATE TABLE students (
id INT,
name VARCHAR,
score INT
);
INSERT INTO students (id, name, score) VALUES
(1, 'Alice', 80),
(2, 'Bob', 75),
(3, 'Charlie', 90),
(4, 'Dave', 80);
Now, we can use ARG_MIN to find the name of the student with the lowest score:
SELECT ARG_MIN(name, score) AS student_name
FROM students;
Result:
| student_name |
|--------------|
| Charlie |
5.1.5 - ARRAY_AGG
The ARRAY_AGG function (also known by its alias LIST) transforms all the values, including NULL, of a specific column in a query result into an array.
Analyze Syntax
func.array_agg(<expr>)
Analyze Examples
table.movie_title, func.array_agg(table.rating).alias('ratings')
| movie_title | ratings |
|-------------|------------|
| Inception | [5, 4, 5] |
SQL Syntax
ARRAY_AGG(<expr>)
LIST(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any expression |
Return Type
Returns an Array with elements that are of the same type as the original data.
SQL Examples
This example demonstrates how the ARRAY_AGG function can be used to aggregate and present data in a convenient array format:
-- Create a table and insert sample data
CREATE TABLE movie_ratings (
id INT,
movie_title VARCHAR,
user_id INT,
rating INT
);
INSERT INTO movie_ratings (id, movie_title, user_id, rating)
VALUES (1, 'Inception', 1, 5),
(2, 'Inception', 2, 4),
(3, 'Inception', 3, 5),
(4, 'Interstellar', 1, 4),
(5, 'Interstellar', 2, 3);
-- List all ratings for Inception in an array
SELECT movie_title, ARRAY_AGG(rating) AS ratings
FROM movie_ratings
WHERE movie_title = 'Inception'
GROUP BY movie_title;
| movie_title | ratings |
|-------------|------------|
| Inception | [5, 4, 5] |
5.1.6 - AVG
Aggregate function.
The AVG() function returns the average value of an expression.
Note: NULL values are not counted.
Analyze Syntax
func.avg(<column>)
Analyze Examples
func.avg(table.price).alias('avg_price')
| avg_price |
| --------- |
| 20.4 |
SQL Syntax
AVG(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any numerical expression |
Return Type
double
SQL Examples
Creating a Table and Inserting Sample Data
Let's create a table named "sales" and insert some sample data:
CREATE TABLE sales (
id INTEGER,
product VARCHAR(50),
price FLOAT
);
INSERT INTO sales (id, product, price)
VALUES (1, 'Product A', 10.5),
(2, 'Product B', 20.75),
(3, 'Product C', 30.0),
(4, 'Product D', 15.25),
(5, 'Product E', 25.5);
Query: Using AVG() Function
Now, let's use the AVG() function to find the average price of all products in the "sales" table:
SELECT AVG(price) AS avg_price
FROM sales;
The result should look like this:
| avg_price |
| --------- |
| 20.4 |
5.1.7 - AVG_IF
The suffix -If can be appended to the name of any aggregate function. In this case, the aggregate function accepts an extra argument – a condition.
Analyze Syntax
func.avg_if(<column>, <cond>)
Analyze Examples
func.avg_if(table.salary, table.department=='IT').alias('avg_salary_it')
| avg_salary_it |
|-----------------|
| 65000.0 |
SQL Syntax
AVG_IF(<column>, <cond>)
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE employees (
id INT,
salary INT,
department VARCHAR
);
INSERT INTO employees (id, salary, department)
VALUES (1, 50000, 'HR'),
(2, 60000, 'IT'),
(3, 55000, 'HR'),
(4, 70000, 'IT'),
(5, 65000, 'IT');
Query Demo: Calculate Average Salary for IT Department
SELECT AVG_IF(salary, department = 'IT') AS avg_salary_it
FROM employees;
Result
| avg_salary_it |
|-----------------|
| 65000.0 |
5.1.8 - COUNT
The COUNT() function returns the number of records returned by a SELECT query.
Analyze Syntax
func.count(<column>)
Analyze Examples
func.count(table.grade).alias('count_valid_grades')
| count_valid_grades |
|--------------------|
| 4 |
SQL Syntax
COUNT(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any expression. This may be a column name, the result of another function, or a math operation. * is also allowed, to indicate pure row counting. |
Return Type
An integer.
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE students (
id INT,
name VARCHAR,
age INT,
grade FLOAT NULL
);
INSERT INTO students (id, name, age, grade)
VALUES (1, 'John', 21, 85),
(2, 'Emma', 22, NULL),
(3, 'Alice', 23, 90),
(4, 'Michael', 21, 88),
(5, 'Sophie', 22, 92);
Query Demo: Count Students with Valid Grades
SELECT COUNT(grade) AS count_valid_grades
FROM students;
Result
| count_valid_grades |
|--------------------|
| 4 |
5.1.9 - COUNT_DISTINCT
Aggregate function.
The count(distinct ...) function calculates the unique value of a set of values.
To obtain an estimated result from large data sets with little memory and time, consider using APPROX_COUNT_DISTINCT.
Analyze Syntax
func.count_distinct(<column>)
Analyze Examples
func.count_distinct(table.category).alias('unique_categories')
| unique_categories |
|-------------------|
| 2 |
SQL Syntax
COUNT(distinct <expr> ...)
UNIQ(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any expression, size of the arguments is [1, 32] |
Return Type
UInt64
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE products (
id INT,
name VARCHAR,
category VARCHAR,
price FLOAT
);
INSERT INTO products (id, name, category, price)
VALUES (1, 'Laptop', 'Electronics', 1000),
(2, 'Smartphone', 'Electronics', 800),
(3, 'Tablet', 'Electronics', 600),
(4, 'Chair', 'Furniture', 150),
(5, 'Table', 'Furniture', 300);
Query Demo: Count Distinct Categories
SELECT COUNT(DISTINCT category) AS unique_categories
FROM products;
Result
| unique_categories |
|-------------------|
| 2 |
5.1.10 - COUNT_IF
The suffix _IF can be appended to the name of any aggregate function. In this case, the aggregate function accepts an extra argument – a condition.
Analyze Syntax
func.count_if(<column>, <cond>)
Analyze Examples
func.count_if(table.status, table.status=='Completed').alias('completed_orders')
| completed_orders |
|------------------|
| 3 |
SQL Example
COUNT_IF(<column>, <cond>)
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE orders (
id INT,
customer_id INT,
status VARCHAR,
total FLOAT
);
INSERT INTO orders (id, customer_id, status, total)
VALUES (1, 1, 'completed', 100),
(2, 2, 'completed', 200),
(3, 1, 'pending', 150),
(4, 3, 'completed', 250),
(5, 2, 'pending', 300);
Query Demo: Count Completed Orders
SELECT COUNT_IF(status, status = 'completed') AS completed_orders
FROM orders;
Result
| completed_orders |
|------------------|
| 3 |
5.1.11 - COVAR_POP
COVAR_POP returns the population covariance of a set of number pairs.
Analyze Syntax
func.covar_pop(<expr1>, <expr2>)
Analyze Examples
func.covar_pop(table.units_sold, table.revenue).alias('covar_pop_units_revenue')
| covar_pop_units_revenue |
|-------------------------|
| 20000.0 |
SQL Syntax
COVAR_POP(<expr1>, <expr2>)
Arguments
| Arguments | Description |
|---|---|
<expr1> | Any numerical expression |
<expr2> | Any numerical expression |
Return Type
float64
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE product_sales (
id INT,
product_id INT,
units_sold INT,
revenue FLOAT
);
INSERT INTO product_sales (id, product_id, units_sold, revenue)
VALUES (1, 1, 10, 1000),
(2, 2, 20, 2000),
(3, 3, 30, 3000),
(4, 4, 40, 4000),
(5, 5, 50, 5000);
Query Demo: Calculate Population Covariance between Units Sold and Revenue
SELECT COVAR_POP(units_sold, revenue) AS covar_pop_units_revenue
FROM product_sales;
Result
| covar_pop_units_revenue |
|-------------------------|
| 20000.0 |
5.1.12 - COVAR_SAMP
Aggregate function.
The covar_samp() function returns the sample covariance (Σ((x - x̅)(y - y̅)) / (n - 1)) of two data columns.
Analyze Syntax
func.covar_samp(<expr1>, <expr2>)
Analyze Examples
func.covar_samp(table.items_sold, table.profit).alias('covar_samp_items_profit')
| covar_samp_items_profit |
|-------------------------|
| 250000.0 |
SQL Syntax
COVAR_SAMP(<expr1>, <expr2>)
Arguments
| Arguments | Description |
|---|---|
<expr1> | Any numerical expression |
<expr2> | Any numerical expression |
Return Type
float64, when n <= 1, returns +∞.
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE store_sales (
id INT,
store_id INT,
items_sold INT,
profit FLOAT
);
INSERT INTO store_sales (id, store_id, items_sold, profit)
VALUES (1, 1, 100, 1000),
(2, 2, 200, 2000),
(3, 3, 300, 3000),
(4, 4, 400, 4000),
(5, 5, 500, 5000);
Query Demo: Calculate Sample Covariance between Items Sold and Profit
SELECT COVAR_SAMP(items_sold, profit) AS covar_samp_items_profit
FROM store_sales;
Result
| covar_samp_items_profit |
|-------------------------|
| 250000.0 |
5.1.13 - GROUP_ARRAY_MOVING_AVG
The GROUP_ARRAY_MOVING_AVG function calculates the moving average of input values. The function can take the window size as a parameter. If left unspecified, the function takes the window size equal to the number of input values.
Analyze Syntax
func.group_array_moving_avg(<expr1>)
Analyze Examples
table.user_id, func.group_array_moving_avg(table.request_num).alias('avg_request_num')
| user_id | avg_request_num |
|---------|------------------|
| 1 | [5.0,11.5,21.5] |
| 3 | [10.0,22.5,35.0] |
| 2 | [7.5,18.0,31.0] |
SQL Syntax
GROUP_ARRAY_MOVING_AVG(<expr>)
GROUP_ARRAY_MOVING_AVG(<window_size>)(<expr>)
Arguments
| Arguments | Description |
|---|---|
<window_size> | Any numerical expression |
<expr> | Any numerical expression |
Return Type
Returns an Array with elements of double or decimal depending on the source data type.
SQL Examples
-- Create a table and insert sample data
CREATE TABLE hits (
user_id INT,
request_num INT
);
INSERT INTO hits (user_id, request_num)
VALUES (1, 10),
(2, 15),
(3, 20),
(1, 13),
(2, 21),
(3, 25),
(1, 30),
(2, 41),
(3, 45);
SELECT user_id, GROUP_ARRAY_MOVING_AVG(2)(request_num) AS avg_request_num
FROM hits
GROUP BY user_id;
| user_id | avg_request_num |
|---------|------------------|
| 1 | [5.0,11.5,21.5] |
| 3 | [10.0,22.5,35.0] |
| 2 | [7.5,18.0,31.0] |
5.1.14 - GROUP_ARRAY_MOVING_SUM
The GROUP_ARRAY_MOVING_SUM function calculates the moving sum of input values. The function can take the window size as a parameter. If left unspecified, the function takes the window size equal to the number of input values.
Analyze Syntax
func.group_array_moving_sum(<expr>)
Analyze Examples
table.user_id, func.group_array_moving_sum(table.request_num)
| user_id | request_num |
|---------|-------------|
| 1 | [10,23,43] |
| 2 | [20,45,70] |
| 3 | [15,36,62] |
SQL Syntax
GROUP_ARRAY_MOVING_SUM(<expr>)
GROUP_ARRAY_MOVING_SUM(<window_size>)(<expr>)
Arguments
| Arguments | Description |
|---|---|
<window_size> | Any numerical expression |
<expr> | Any numerical expression |
Return Type
Returns an Array with elements that are of the same type as the original data.
SQL Examples
-- Create a table and insert sample data
CREATE TABLE hits (
user_id INT,
request_num INT
);
INSERT INTO hits (user_id, request_num)
VALUES (1, 10),
(2, 15),
(3, 20),
(1, 13),
(2, 21),
(3, 25),
(1, 30),
(2, 41),
(3, 45);
SELECT user_id, GROUP_ARRAY_MOVING_SUM(2)(request_num) AS request_num
FROM hits
GROUP BY user_id;
| user_id | request_num |
|---------|-------------|
| 1 | [10,23,43] |
| 2 | [20,45,70] |
| 3 | [15,36,62] |
5.1.15 - HISTOGRAM
Generates a data distribution histogram using an "equal height" bucketing strategy.
Analyze Syntax
func.histogram(<expr>)
Analyze Examples
See SQL Example for details
SQL Syntax
HISTOGRAM(<expr>)
-- The following two forms are equivalent:
HISTOGRAM(<max_num_buckets>)(<expr>)
HISTOGRAM(<expr> [, <max_num_buckets>])
| Parameter | Description |
|---|---|
expr | The data type of expr should be sortable. |
max_num_buckets | Optional positive integer specifying the maximum number of buckets. Default is 128. |
Return Type
Returns either an empty string or a JSON object with the following structure:
- buckets: List of buckets with detailed information:
- lower: Lower bound of the bucket.
- upper: Upper bound of the bucket.
- count: Number of elements in the bucket.
- pre_sum: Cumulative count of elements up to the current bucket.
- ndv: Number of distinct values in the bucket.
SQL Examples
This example shows how the HISTOGRAM function analyzes the distribution of c_int values in the histagg table, returning bucket boundaries, distinct value counts, element counts, and cumulative counts:
CREATE TABLE histagg (
c_id INT,
c_tinyint TINYINT,
c_smallint SMALLINT,
c_int INT
);
INSERT INTO histagg VALUES
(1, 10, 20, 30),
(1, 11, 21, 33),
(1, 11, 12, 13),
(2, 21, 22, 23),
(2, 31, 32, 33),
(2, 10, 20, 30);
SELECT HISTOGRAM(c_int) FROM histagg;
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ histogram(c_int) │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ [{"lower":"13","upper":"13","ndv":1,"count":1,"pre_sum":0},{"lower":"23","upper":"23","ndv":1,"count":1,"pre_sum":1},{"lower":"30","upper":"30","ndv":1,"count":2,"pre_sum":2},{"lower":"33","upper":"33","ndv":1,"count":2,"pre_sum":4}] │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
The result is returned as a JSON array:
[
{
"lower": "13",
"upper": "13",
"ndv": 1,
"count": 1,
"pre_sum": 0
},
{
"lower": "23",
"upper": "23",
"ndv": 1,
"count": 1,
"pre_sum": 1
},
{
"lower": "30",
"upper": "30",
"ndv": 1,
"count": 2,
"pre_sum": 2
},
{
"lower": "33",
"upper": "33",
"ndv": 1,
"count": 2,
"pre_sum": 4
}
]
This example shows how HISTOGRAM(2) groups c_int values into two buckets:
SELECT HISTOGRAM(2)(c_int) FROM histagg;
-- Or
SELECT HISTOGRAM(c_int, 2) FROM histagg;
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ histogram(2)(c_int) │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ [{"lower":"13","upper":"30","ndv":3,"count":4,"pre_sum":0},{"lower":"33","upper":"33","ndv":1,"count":2,"pre_sum":4}] │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
The result is returned as a JSON array:
[
{
"lower": "13",
"upper": "30",
"ndv": 3,
"count": 4,
"pre_sum": 0
},
{
"lower": "33",
"upper": "33",
"ndv": 1,
"count": 2,
"pre_sum": 4
}
]
5.1.16 - JSON_ARRAY_AGG
Converts values into a JSON array while skipping NULLs.
See also: JSON_OBJECT_AGG
Analyze Syntax
func.json_array_agg(<expr>)
Analyze Examples
See SQL Example for details
SQL Syntax
JSON_ARRAY_AGG(<expr>)
Return Type
JSON array.
Examples
This example demonstrates how JSON_ARRAY_AGG aggregates values from each column into JSON arrays:
CREATE TABLE d (
a DECIMAL(10, 2),
b STRING,
c INT,
d VARIANT,
e ARRAY(STRING)
);
INSERT INTO d VALUES
(20, 'abc', NULL, '{"k":"v"}', ['a','b']),
(10, 'de', 100, 'null', []),
(4.23, NULL, 200, '"uvw"', ['x','y']),
(5.99, 'xyz', 300, '[1,2,3]', ['z']);
SELECT
json_array_agg(a) AS aggregated_a,
json_array_agg(b) AS aggregated_b,
json_array_agg(c) AS aggregated_c,
json_array_agg(d) AS aggregated_d,
json_array_agg(e) AS aggregated_e
FROM d;
-[ RECORD 1 ]-----------------------------------
aggregated_a: [20.0,10.0,4.23,5.99]
aggregated_b: ["abc","de","xyz"]
aggregated_c: [100,200,300]
aggregated_d: [{"k":"v"},null,"uvw",[1,2,3]]
aggregated_e: [["a","b"],[],["x","y"],["z"]]
5.1.17 - JSON_OBJECT_AGG
Converts key-value pairs into a JSON object. For each row in the input, it generates a key-value pair where the key is derived from the <key_expression> and the value is derived from the <value_expression>. These key-value pairs are then combined into a single JSON object.
See also: JSON_ARRAY_AGG
Analyze Syntax
func.json_object_agg(<key_expression>, <value_expression>)
Analyze Examples
See SQL Example for details
SQL Syntax
JSON_OBJECT_AGG(<key_expression>, <value_expression>)
| Parameter | Description |
|---|---|
| key_expression | Specifies the key in the JSON object. Only supports string expressions. If the key_expression evaluates to NULL, the key-value pair is skipped. |
| value_expression | Specifies the value in the JSON object. It can be any supported data type. If the value_expression evaluates to NULL, the key-value pair is skipped. |
Return Type
JSON object.
SQL Examples
This example demonstrates how JSON_OBJECT_AGG can be used to aggregate different types of data—such as decimals, integers, JSON variants, and arrays—into JSON objects, with the column b as the key for each JSON object:
CREATE TABLE d (
a DECIMAL(10, 2),
b STRING,
c INT,
d VARIANT,
e ARRAY(STRING)
);
INSERT INTO d VALUES
(20, 'abc', NULL, '{"k":"v"}', ['a','b']),
(10, 'de', 100, 'null', []),
(4.23, NULL, 200, '"uvw"', ['x','y']),
(5.99, 'xyz', 300, '[1,2,3]', ['z']);
SELECT
json_object_agg(b, a) AS json_a,
json_object_agg(b, c) AS json_c,
json_object_agg(b, d) AS json_d,
json_object_agg(b, e) AS json_e
FROM
d;
-[ RECORD 1 ]-----------------------------------
json_a: {"abc":20.0,"de":10.0,"xyz":5.99}
json_c: {"de":100,"xyz":300}
json_d: {"abc":{"k":"v"},"de":null,"xyz":[1,2,3]}
json_e: {"abc":["a","b"],"de":[],"xyz":["z"]}
5.1.18 - KURTOSIS
Aggregate function.
The KURTOSIS() function returns the excess kurtosis of all input values.
Analyze Syntax
func.kurtosis(<expr>)
Analyze Examples
func.kurtosis(table.price).alias('excess_kurtosis')
| excess_kurtosis |
|-------------------------|
| 0.06818181325581445 |
SQL Syntax
KURTOSIS(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any numerical expression |
Return Type
Nullable Float64.
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE stock_prices (
id INT,
stock_symbol VARCHAR,
price FLOAT
);
INSERT INTO stock_prices (id, stock_symbol, price)
VALUES (1, 'AAPL', 150),
(2, 'AAPL', 152),
(3, 'AAPL', 148),
(4, 'AAPL', 160),
(5, 'AAPL', 155);
Query Demo: Calculate Excess Kurtosis for Apple Stock Prices
SELECT KURTOSIS(price) AS excess_kurtosis
FROM stock_prices
WHERE stock_symbol = 'AAPL';
Result
| excess_kurtosis |
|-------------------------|
| 0.06818181325581445 |
5.1.19 - MAX
Aggregate function.
The MAX() function returns the maximum value in a set of values.
Analyze Syntax
func.max(<column>)
Analyze Examples
table.city, func.max(table.temperature).alias('max_temperature')
| city | max_temperature |
|------------|-----------------|
| New York | 32 |
SQL Syntax
MAX(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any expression |
Return Type
The maximum value, in the type of the value.
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE temperatures (
id INT,
city VARCHAR,
temperature FLOAT
);
INSERT INTO temperatures (id, city, temperature)
VALUES (1, 'New York', 30),
(2, 'New York', 28),
(3, 'New York', 32),
(4, 'Los Angeles', 25),
(5, 'Los Angeles', 27);
Query Demo: Find Maximum Temperature for New York City
SELECT city, MAX(temperature) AS max_temperature
FROM temperatures
WHERE city = 'New York'
GROUP BY city;
Result
| city | max_temperature |
|------------|-----------------|
| New York | 32 |
5.1.20 - MAX_IF
The suffix _IF can be appended to the name of any aggregate function. In this case, the aggregate function accepts an extra argument – a condition.
Analyze Syntax
func.max_if(<column>, <cond>)
Analyze Examples
func.max_if(table.revenue, table.salesperson_id==1).alias('max_revenue_salesperson_1')
| max_revenue_salesperson_1 |
|---------------------------|
| 3000 |
SQL Example
MAX_IF(<column>, <cond>)
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE sales (
id INT,
salesperson_id INT,
product_id INT,
revenue FLOAT
);
INSERT INTO sales (id, salesperson_id, product_id, revenue)
VALUES (1, 1, 1, 1000),
(2, 1, 2, 2000),
(3, 1, 3, 3000),
(4, 2, 1, 1500),
(5, 2, 2, 2500);
Query Demo: Find Maximum Revenue for Salesperson with ID 1
SELECT MAX_IF(revenue, salesperson_id = 1) AS max_revenue_salesperson_1
FROM sales;
Result
| max_revenue_salesperson_1 |
|---------------------------|
| 3000 |
5.1.21 - MEDIAN
Aggregate function.
The MEDIAN() function computes the median of a numeric data sequence.
Analyze Syntax
func.median(<expr>)
Analyze Examples
func.median(table.score).alias('median_score')
| median_score |
|----------------|
| 85.0 |
SQL Syntax
MEDIAN(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any numerical expression |
Return Type
the type of the value.
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE exam_scores (
id INT,
student_id INT,
score INT
);
INSERT INTO exam_scores (id, student_id, score)
VALUES (1, 1, 80),
(2, 2, 90),
(3, 3, 75),
(4, 4, 95),
(5, 5, 85);
Query Demo: Calculate Median Exam Score
SELECT MEDIAN(score) AS median_score
FROM exam_scores;
Result
| median_score |
|----------------|
| 85.0 |
5.1.22 - MEDIAN_TDIGEST
Computes the median of a numeric data sequence using the t-digest algorithm.
Analyze Syntax
func.median_tdigest(<expr>)
Analyze Examples
func.median_tdigest(table.score).alias('median_score')
| median_score |
|----------------|
| 85.0 |
SQL Syntax
MEDIAN_TDIGEST(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any numerical expression |
Return Type
Returns a value of the same data type as the input values.
SQL Examples
-- Create a table and insert sample data
CREATE TABLE exam_scores (
id INT,
student_id INT,
score INT
);
INSERT INTO exam_scores (id, student_id, score)
VALUES (1, 1, 80),
(2, 2, 90),
(3, 3, 75),
(4, 4, 95),
(5, 5, 85);
-- Calculate median exam score
SELECT MEDIAN_TDIGEST(score) AS median_score
FROM exam_scores;
| median_score |
|----------------|
| 85.0 |
5.1.23 - MIN
Aggregate function.
The MIN() function returns the minimum value in a set of values.
Analyze Syntax
func.min(<column>)
Analyze Examples
table.station_id, func.min(table.price).alias('min_price')
| station_id | min_price |
|------------|-----------|
| 1 | 3.45 |
SQL Syntax
MIN(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any expression |
Return Type
The minimum value, in the type of the value.
SQL Examples
title: MIN
Aggregate function.
The MIN() function returns the minimum value in a set of values.
SQL Syntax
MIN(expression)
Arguments
| Arguments | Description |
|---|---|
| expression | Any expression |
Return Type
The minimum value, in the type of the value.
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE gas_prices (
id INT,
station_id INT,
price FLOAT
);
INSERT INTO gas_prices (id, station_id, price)
VALUES (1, 1, 3.50),
(2, 1, 3.45),
(3, 1, 3.55),
(4, 2, 3.40),
(5, 2, 3.35);
Query Demo: Find Minimum Gas Price for Station 1
SELECT station_id, MIN(price) AS min_price
FROM gas_prices
WHERE station_id = 1
GROUP BY station_id;
Result
| station_id | min_price |
|------------|-----------|
| 1 | 3.45 |
5.1.24 - MIN_IF
The suffix _IF can be appended to the name of any aggregate function. In this case, the aggregate function accepts an extra argument – a condition.
Analyze Syntax
func.min_if(<column>, <cond>)
Analyze Examples
func.min_if(table.budget, table.departing=='IT').alias('min_it_budget')
| min_it_budget |
|---------------|
| 2000 |
SQL Syntax
MIN_IF(<column>, <cond>)
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE project_budgets (
id INT,
project_id INT,
department VARCHAR,
budget FLOAT
);
INSERT INTO project_budgets (id, project_id, department, budget)
VALUES (1, 1, 'HR', 1000),
(2, 1, 'IT', 2000),
(3, 1, 'Marketing', 3000),
(4, 2, 'HR', 1500),
(5, 2, 'IT', 2500);
Query Demo: Find Minimum Budget for IT Department
SELECT MIN_IF(budget, department = 'IT') AS min_it_budget
FROM project_budgets;
Result
| min_it_budget |
|---------------|
| 2000 |
5.1.25 - QUANTILE_CONT
Aggregate function.
The QUANTILE_CONT() function computes the interpolated quantile number of a numeric data sequence.
Analyze Syntax
func.quantile_cont(<levels>, <expr>)
Analyze Examples
func.quantile_cont(0.5, table.sales_amount).alias('median_sales_amount')
| median_sales_amount |
|-----------------------|
| 6000.0 |
SQL Syntax
QUANTILE_CONT(<levels>)(<expr>)
QUANTILE_CONT(level1, level2, ...)(<expr>)
Arguments
| Arguments | Description |
|---|---|
<level(s) | level(s) of quantile. Each level is constant floating-point number from 0 to 1. We recommend using a level value in the range of [0.01, 0.99] |
<expr> | Any numerical expression |
Return Type
Float64 or float64 array based on level number.
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE sales_data (
id INT,
sales_person_id INT,
sales_amount FLOAT
);
INSERT INTO sales_data (id, sales_person_id, sales_amount)
VALUES (1, 1, 5000),
(2, 2, 5500),
(3, 3, 6000),
(4, 4, 6500),
(5, 5, 7000);
Query Demo: Calculate 50th Percentile (Median) of Sales Amount using Interpolation
SELECT QUANTILE_CONT(0.5)(sales_amount) AS median_sales_amount
FROM sales_data;
Result
| median_sales_amount |
|-----------------------|
| 6000.0 |
5.1.26 - QUANTILE_DISC
Aggregate function.
The QUANTILE_DISC() function computes the exact quantile number of a numeric data sequence.
The QUANTILE alias to QUANTILE_DISC
Analyze Syntax
func.quantile_disc(<levels>, <expr>)
Analyze Examples
func.quantile_disc([0.25, 0.75], table.salary).alias('salary_quantiles')
| salary_quantiles |
|---------------------|
| [55000.0, 65000.0] |
SQL Syntax
QUANTILE_DISC(<levels>)(<expr>)
QUANTILE_DISC(level1, level2, ...)(<expr>)
Arguments
| Arguments | Description |
|---|---|
level(s) | level(s) of quantile. Each level is constant floating-point number from 0 to 1. We recommend using a level value in the range of [0.01, 0.99] |
<expr> | Any numerical expression |
Return Type
InputType or array of InputType based on level number.
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE salary_data (
id INT,
employee_id INT,
salary FLOAT
);
INSERT INTO salary_data (id, employee_id, salary)
VALUES (1, 1, 50000),
(2, 2, 55000),
(3, 3, 60000),
(4, 4, 65000),
(5, 5, 70000);
Query Demo: Calculate 25th and 75th Percentile of Salaries
SELECT QUANTILE_DISC(0.25, 0.75)(salary) AS salary_quantiles
FROM salary_data;
Result
| salary_quantiles |
|---------------------|
| [55000.0, 65000.0] |
5.1.27 - QUANTILE_TDIGEST
Computes an approximate quantile of a numeric data sequence using the t-digest algorithm.
Analyze Syntax
func.quantile_tdigest(<levels>, <expr>)
Analyze Examples
func.quantile_tdigest([0.5, 0.8], table.sales_amount).alias('sales_amounts')
| sales_amounts |
|-----------------------+
| [6000.0,7000.0] |
SQL Syntax
QUANTILE_TDIGEST(<level1>[, <level2>, ...])(<expr>)
Arguments
| Arguments | Description |
|---|---|
<level n> | A level of quantile represents a constant floating-point number ranging from 0 to 1. It is recommended to use a level value in the range of [0.01, 0.99]. |
<expr> | Any numerical expression |
Return Type
Returns either a Float64 value or an array of Float64 values, depending on the number of quantile levels specified.
SQL Examples
-- Create a table and insert sample data
CREATE TABLE sales_data (
id INT,
sales_person_id INT,
sales_amount FLOAT
);
INSERT INTO sales_data (id, sales_person_id, sales_amount)
VALUES (1, 1, 5000),
(2, 2, 5500),
(3, 3, 6000),
(4, 4, 6500),
(5, 5, 7000);
SELECT QUANTILE_TDIGEST(0.5)(sales_amount) AS median_sales_amount
FROM sales_data;
median_sales_amount|
-------------------+
6000.0|
SELECT QUANTILE_TDIGEST(0.5, 0.8)(sales_amount)
FROM sales_data;
quantile_tdigest(0.5, 0.8)(sales_amount)|
----------------------------------------+
[6000.0,7000.0] |
5.1.28 - QUANTILE_TDIGEST_WEIGHTED
Computes an approximate quantile of a numeric data sequence using the t-digest algorithm. This function takes into account the weight of each sequence member. Memory consumption is log(n), where n is a number of values.
Analyze Syntax
func.quantile_tdigest_weighted(<levels>, <expr>, <weight_expr>)
Analyze Examples
func.quantile_tdigest_weighted([0.5, 0.8], table.sales_amount, 1).alias('sales_amounts')
| sales_amounts |
|-----------------------+
| [6000.0,7000.0] |
SQL Syntax
QUANTILE_TDIGEST_WEIGHTED(<level1>[, <level2>, ...])(<expr>, <weight_expr>)
Arguments
| Arguments | Description |
|---|---|
<level n> | A level of quantile represents a constant floating-point number ranging from 0 to 1. It is recommended to use a level value in the range of [0.01, 0.99]. |
<expr> | Any numerical expression |
<weight_expr> | Any unsigned integer expression. Weight is a number of value occurrences. |
Return Type
Returns either a Float64 value or an array of Float64 values, depending on the number of quantile levels specified.
SQL Examples
-- Create a table and insert sample data
CREATE TABLE sales_data (
id INT,
sales_person_id INT,
sales_amount FLOAT
);
INSERT INTO sales_data (id, sales_person_id, sales_amount)
VALUES (1, 1, 5000),
(2, 2, 5500),
(3, 3, 6000),
(4, 4, 6500),
(5, 5, 7000);
SELECT QUANTILE_TDIGEST_WEIGHTED(0.5)(sales_amount, 1) AS median_sales_amount
FROM sales_data;
median_sales_amount|
-------------------+
6000.0|
SELECT QUANTILE_TDIGEST_WEIGHTED(0.5, 0.8)(sales_amount, 1)
FROM sales_data;
quantile_tdigest_weighted(0.5, 0.8)(sales_amount)|
-------------------------------------------------+
[6000.0,7000.0] |
5.1.29 - RETENTION
Aggregate function
The RETENTION() function takes as arguments a set of conditions from 1 to 32 arguments of type UInt8 that indicate whether a certain condition was met for the event.
Any condition can be specified as an argument (as in WHERE).
The conditions, except the first, apply in pairs: the result of the second will be true if the first and second are true, of the third if the first and third are true, etc.
Analyze Syntax
func.retention(<cond1> , <cond2> , ..., <cond32>)
Analyze Examples
table.user_id, func.retention(table.event_type=='signup', table.event_type='login', table.event_type='purchase').alias('sales_amounts')
| user_id | retention |
|---------|-----------|
| 1 | [1, 1, 0] |
| 2 | [1, 0, 1] |
| 3 | [1, 1, 0] |
SQL Syntax
RETENTION( <cond1> , <cond2> , ..., <cond32> );
Arguments
| Arguments | Description |
|---|---|
<cond> | An expression that returns a Boolean result |
Return Type
The array of 1 or 0.
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE user_events (
id INT,
user_id INT,
event_date DATE,
event_type VARCHAR
);
INSERT INTO user_events (id, user_id, event_date, event_type)
VALUES (1, 1, '2022-01-01', 'signup'),
(2, 1, '2022-01-02', 'login'),
(3, 2, '2022-01-01', 'signup'),
(4, 2, '2022-01-03', 'purchase'),
(5, 3, '2022-01-01', 'signup'),
(6, 3, '2022-01-02', 'login');
Query Demo: Calculate User Retention Based on Signup, Login, and Purchase Events
SELECT
user_id,
RETENTION(event_type = 'signup', event_type = 'login', event_type = 'purchase') AS retention
FROM user_events
GROUP BY user_id;
Result
| user_id | retention |
|---------|-----------|
| 1 | [1, 1, 0] |
| 2 | [1, 0, 1] |
| 3 | [1, 1, 0] |
5.1.30 - SKEWNESS
Aggregate function.
The SKEWNESS() function returns the skewness of all input values.
Analyze Syntax
func.skewness(<expr>)
Analyze Examples
func.skewness(table.temperature).alias('temperature_skewness')
| temperature_skewness |
|----------------------|
| 0.68 |
SQL Syntax
SKEWNESS(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any numerical expression |
Return Type
Nullable Float64.
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE temperature_data (
id INT,
city_id INT,
temperature FLOAT
);
INSERT INTO temperature_data (id, city_id, temperature)
VALUES (1, 1, 60),
(2, 1, 65),
(3, 1, 62),
(4, 2, 70),
(5, 2, 75);
Query Demo: Calculate Skewness of Temperature Data
SELECT SKEWNESS(temperature) AS temperature_skewness
FROM temperature_data;
Result
| temperature_skewness |
|----------------------|
| 0.68 |
5.1.31 - STDDEV_POP
Aggregate function.
The STDDEV_POP() function returns the population standard deviation(the square root of VAR_POP()) of an expression.
Analyze Syntax
func.stddev_pop(<expr>)
Analyze Examples
func.stddev_pop(table.score).alias('test_score_stddev_pop')
| test_score_stddev_pop |
|-----------------------|
| 7.07107 |
SQL Syntax
STDDEV_POP(<expr>)
STDDEV(<expr>)
STD(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any numerical expression |
Return Type
double
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE test_scores (
id INT,
student_id INT,
score FLOAT
);
INSERT INTO test_scores (id, student_id, score)
VALUES (1, 1, 80),
(2, 2, 85),
(3, 3, 90),
(4, 4, 95),
(5, 5, 100);
Query Demo: Calculate Population Standard Deviation of Test Scores
SELECT STDDEV_POP(score) AS test_score_stddev_pop
FROM test_scores;
Result
| test_score_stddev_pop |
|-----------------------|
| 7.07107 |
5.1.32 - STDDEV_SAMP
Aggregate function.
The STDDEV_SAMP() function returns the sample standard deviation(the square root of VAR_SAMP()) of an expression.
Analyze Syntax
func.stddev_samp(<expr>)
Analyze Examples
func.stddev_samp(table.height).alias('height_stddev_samp')
| height_stddev_samp |
|--------------------|
| 0.240 |
SQL Syntax
STDDEV_SAMP(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any numerical expression |
Return Type
double
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE height_data (
id INT,
person_id INT,
height FLOAT
);
INSERT INTO height_data (id, person_id, height)
VALUES (1, 1, 5.8),
(2, 2, 6.1),
(3, 3, 5.9),
(4, 4, 5.7),
(5, 5, 6.3);
Query Demo: Calculate Sample Standard Deviation of Heights
SELECT STDDEV_SAMP(height) AS height_stddev_samp
FROM height_data;
Result
| height_stddev_samp |
|--------------------|
| 0.240 |
5.1.33 - STRING_AGG
Aggregate function.
The STRING_AGG() function converts all the non-NULL values of a column to String, separated by the delimiter.
Analyze Syntax
func.string_agg(<expr> [, delimiter])
Analyze Examples
func.string_agg(table.language_name).alias('concatenated_languages')
| concatenated_languages |
|-----------------------------------------|
| Python, JavaScript, Java, C#, Ruby |
SQL Syntax
STRING_AGG(<expr>)
STRING_AGG(<expr> [, delimiter])
If <expr> is not a String expression, should use ::VARCHAR to convert.
For example:
SELECT string_agg(number::VARCHAR, '|') AS s FROM numbers(5);
+-----------+
| s |
+-----------+
| 0|1|2|3|4 |
+-----------+
Arguments
| Arguments | Description |
|---|---|
<expr> | Any string expression (if not a string, use ::VARCHAR to convert) |
delimiter | Optional constant String, if not specified, use empty String |
Return Type
the String type
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE programming_languages (
id INT,
language_name VARCHAR
);
INSERT INTO programming_languages (id, language_name)
VALUES (1, 'Python'),
(2, 'JavaScript'),
(3, 'Java'),
(4, 'C#'),
(5, 'Ruby');
Query Demo: Concatenate Programming Language Names with a Delimiter
SELECT STRING_AGG(language_name, ', ') AS concatenated_languages
FROM programming_languages;
Result
| concatenated_languages |
|------------------------------------------|
| Python, JavaScript, Java, C#, Ruby |
5.1.34 - SUM
Aggregate function.
The SUM() function calculates the sum of a set of values.
Analyze Syntax
func.sum(<column>)
Analyze Examples
func.sum(table.quantity).alias('total_quantity_sold')
| total_quantity_sold |
|---------------------|
| 41 |
SQL Syntax
SUM(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Any numerical expression |
Return Type
A double if the input type is double, otherwise integer.
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE sales_data (
id INT,
product_id INT,
quantity INT
);
INSERT INTO sales_data (id, product_id, quantity)
VALUES (1, 1, 10),
(2, 2, 5),
(3, 3, 8),
(4, 4, 3),
(5, 5, 15);
Query Demo: Calculate the Total Quantity of Products Sold
SELECT SUM(quantity) AS total_quantity_sold
FROM sales_data;
Result
| total_quantity_sold |
|---------------------|
| 41 |
5.1.35 - SUM_IF
The suffix -If can be appended to the name of any aggregate function. In this case, the aggregate function accepts an extra argument – a condition.
Analyze Syntax
func.sum_if(<column>, <cond>)
Analyze Examples
func.sum_if(table.amount, table.status=='Completed').alias('total_amount_completed')
| total_amount_completed |
|------------------------|
| 270.0 |
SQL Syntax
SUM_IF(<column>, <cond>)
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE order_data (
id INT,
customer_id INT,
amount FLOAT,
status VARCHAR
);
INSERT INTO order_data (id, customer_id, amount, status)
VALUES (1, 1, 100, 'Completed'),
(2, 2, 50, 'Completed'),
(3, 3, 80, 'Cancelled'),
(4, 4, 120, 'Completed'),
(5, 5, 75, 'Cancelled');
Query Demo: Calculate the Total Amount of Completed Orders
SELECT SUM_IF(amount, status = 'Completed') AS total_amount_completed
FROM order_data;
Result
| total_amount_completed |
|------------------------|
| 270.0 |
5.1.36 - WINDOW_FUNNEL

Similar to windowFunnel in ClickHouse (they were created by the same author), it searches for event chains in a sliding time window and calculates the maximum number of events from the chain.
The function works according to the algorithm:
The function searches for data that triggers the first condition in the chain and sets the event counter to 1. This is the moment when the sliding window starts.
If events from the chain occur sequentially within the window, the counter is incremented. If the sequence of events is disrupted, the counter isn’t incremented.
If the data has multiple event chains at varying completion points, the function will only output the size of the longest chain.
SQL Syntax
WINDOW_FUNNEL( <window> )( <timestamp>, <cond1>, <cond2>, ..., <condN> )
Arguments
<timestamp>— Name of the column containing the timestamp. Data types supported: integer types and datetime types.<cond>— Conditions or data describing the chain of events. Must beBooleandatatype.
Parameters
<window>— Length of the sliding window, it is the time interval between the first and the last condition. The unit ofwindowdepends on thetimestampitself and varies. Determined using the expressiontimestamp of cond1 <= timestamp of cond2 <= ... <= timestamp of condN <= timestamp of cond1 + window.
Returned value
The maximum number of consecutive triggered conditions from the chain within the sliding time window. All the chains in the selection are analyzed.
Type: UInt8.
Example
Determine if a set period of time is enough for the user to SELECT a phone and purchase it twice in the online store.
Set the following chain of events:
- The user logged into their account on the store (
event_name = 'login'). - The user land the page (
event_name = 'visit'). - The user adds to the shopping cart(
event_name = 'cart'). - The user complete the purchase (
event_name = 'purchase').
CREATE TABLE events(user_id BIGINT, event_name VARCHAR, event_timestamp TIMESTAMP);
INSERT INTO events VALUES(100123, 'login', '2022-05-14 10:01:00');
INSERT INTO events VALUES(100123, 'visit', '2022-05-14 10:02:00');
INSERT INTO events VALUES(100123, 'cart', '2022-05-14 10:04:00');
INSERT INTO events VALUES(100123, 'purchase', '2022-05-14 10:10:00');
INSERT INTO events VALUES(100125, 'login', '2022-05-15 11:00:00');
INSERT INTO events VALUES(100125, 'visit', '2022-05-15 11:01:00');
INSERT INTO events VALUES(100125, 'cart', '2022-05-15 11:02:00');
INSERT INTO events VALUES(100126, 'login', '2022-05-15 12:00:00');
INSERT INTO events VALUES(100126, 'visit', '2022-05-15 12:01:00');
Input table:
+---------+------------+----------------------------+
| user_id | event_name | event_timestamp |
+---------+------------+----------------------------+
| 100123 | login | 2022-05-14 10:01:00.000000 |
| 100123 | visit | 2022-05-14 10:02:00.000000 |
| 100123 | cart | 2022-05-14 10:04:00.000000 |
| 100123 | purchase | 2022-05-14 10:10:00.000000 |
| 100125 | login | 2022-05-15 11:00:00.000000 |
| 100125 | visit | 2022-05-15 11:01:00.000000 |
| 100125 | cart | 2022-05-15 11:02:00.000000 |
| 100126 | login | 2022-05-15 12:00:00.000000 |
| 100126 | visit | 2022-05-15 12:01:00.000000 |
+---------+------------+----------------------------+
Find out how far the user user_id could get through the chain in an hour window slides.
Query:
SELECT
level,
count() AS count
FROM
(
SELECT
user_id,
window_funnel(3600000000)(event_timestamp, event_name = 'login', event_name = 'visit', event_name = 'cart', event_name = 'purchase') AS level
FROM events
GROUP BY user_id
)
GROUP BY level ORDER BY level ASC;
event_timestamp type is timestamp, 3600000000 is a hour time window.Result:
+-------+-------+
| level | count |
+-------+-------+
| 2 | 1 |
| 3 | 1 |
| 4 | 1 |
+-------+-------+
- User
100126level is 2 (login -> visit) . - user
100125level is 3 (login -> visit -> cart). - User
100123level is 4 (login -> visit -> cart -> purchase).
5.2 - AI Functions
This document demonstrates how to leverage PlaidCloud Lakehouse's built-in AI functions for creating document embeddings, searching for similar documents, and generating text completions based on context.
5.2.1 - AI_EMBEDDING_VECTOR
This document provides an overview of the ai_embedding_vector function in PlaidCloud Lakehouse and demonstrates how to create document embeddings using this function.
The main code implementation can be found here.
By default, PlaidCloud Lakehouse leverages the text-embedding-ada model for generating embeddings.
Starting from PlaidCloud Lakehouse v1.1.47, PlaidCloud Lakehouse supports the Azure OpenAI service.
This integration offers improved data privacy.
To use Azure OpenAI, add the following configurations to the [query] section:
# Azure OpenAI
openai_api_chat_base_url = "https://<name>.openai.azure.com/openai/deployments/<name>/"
openai_api_embedding_base_url = "https://<name>.openai.azure.com/openai/deployments/<name>/"
openai_api_version = "2023-03-15-preview"
PlaidCloud Lakehouse relies on (Azure) OpenAI for AI_EMBEDDING_VECTOR and sends the embedding column data to (Azure) OpenAI.
They will only work when the PlaidCloud Lakehouse configuration includes the openai_api_key, otherwise they will be inactive.
This function is available by default on PlaidCloud Lakehouse using an Azure OpenAI key. If you use them, you acknowledge that your data will be sent to Azure OpenAI by us.
Overview of ai_embedding_vector
The ai_embedding_vector function in PlaidCloud Lakehouse is a built-in function that generates vector embeddings for text data. It is useful for natural language processing tasks, such as document similarity, clustering, and recommendation systems.
The function takes a text input and returns a high-dimensional vector that represents the input text's semantic meaning and context. The embeddings are created using pre-trained models on large text corpora, capturing the relationships between words and phrases in a continuous space.
Creating embeddings using ai_embedding_vector
To create embeddings for a text document using the ai_embedding_vector function, follow the example below.
- Create a table to store the documents:
CREATE TABLE documents (
id INT,
title VARCHAR,
content VARCHAR,
embedding ARRAY(FLOAT32)
);
- Insert example documents into the table:
INSERT INTO documents(id, title, content)
VALUES
(1, 'A Brief History of AI', 'Artificial intelligence (AI) has been a fascinating concept of science fiction for decades...'),
(2, 'Machine Learning vs. Deep Learning', 'Machine learning and deep learning are two subsets of artificial intelligence...'),
(3, 'Neural Networks Explained', 'A neural network is a series of algorithms that endeavors to recognize underlying relationships...'),
- Generate the embeddings:
UPDATE documents SET embedding = ai_embedding_vector(content) WHERE length(embedding) = 0;
After running the query, the embedding column in the table will contain the generated embeddings.
The embeddings are stored as an array of FLOAT32 values in the embedding column, which has the ARRAY(FLOAT32) column type.
You can now use these embeddings for various natural language processing tasks, such as finding similar documents or clustering documents based on their content.
- Inspect the embeddings:
SELECT length(embedding) FROM documents;
+-------------------+
| length(embedding) |
+-------------------+
| 1536 |
| 1536 |
| 1536 |
+-------------------+
The query above shows that the generated embeddings have a length of 1536(dimensions) for each document.
5.2.2 - AI_TEXT_COMPLETION
This document provides an overview of the ai_text_completion function in PlaidCloud Lakehouse and demonstrates how to generate text completions using this function.
The main code implementation can be found here.
Starting from PlaidCloud Lakehouse v1.1.47, PlaidCloud Lakehouse supports the Azure OpenAI service.
This integration offers improved data privacy.
To use Azure OpenAI, add the following configurations to the [query] section:
# Azure OpenAI
openai_api_chat_base_url = "https://<name>.openai.azure.com/openai/deployments/<name>/"
openai_api_embedding_base_url = "https://<name>.openai.azure.com/openai/deployments/<name>/"
openai_api_version = "2023-03-15-preview"
PlaidCloud Lakehouse relies on (Azure) OpenAI for AI_TEXT_COMPLETION and sends the completion prompt data to (Azure) OpenAI.
They will only work when the PlaidCloud Lakehouse configuration includes the openai_api_key, otherwise they will be inactive.
This function is available by default on PlaidCloud Lakehouse using an Azure OpenAI key. If you use them, you acknowledge that your data will be sent to Azure OpenAI by us.
Overview of ai_text_completion
The ai_text_completion function in PlaidCloud Lakehouse is a built-in function that generates text completions based on a given prompt. It is useful for natural language processing tasks, such as question answering, text generation, and autocompletion systems.
The function takes a text prompt as input and returns a generated completion for the prompt. The completions are created using pre-trained models on large text corpora, capturing the relationships between words and phrases in a continuous space.
Generating text completions using ai_text_completion
Here is a simple example using the ai_text_completion function in PlaidCloud Lakehouse to generate a text completion:
SELECT ai_text_completion('What is artificial intelligence?') AS completion;
Result:
+--------------------------------------------------------------------------------------------------------------------+
| completion |
+--------------------------------------------------------------------------------------------------------------------+
| Artificial intelligence (AI) is the field of study focused on creating machines and software capable of thinking, learning, and solving problems in a way that mimics human intelligence. This includes areas such as machine learning, natural language processing, computer vision, and robotics. |
+--------------------------------------------------------------------------------------------------------------------+
In this example, we provide the prompt "What is artificial intelligence?" to the ai_text_completion function, and it returns a generated completion that briefly describes artificial intelligence.
5.2.3 - AI_TO_SQL
Converts natural language instructions into SQL queries with the latest model text-davinci-003.
PlaidCloud Lakehouse offers an efficient solution for constructing SQL queries by incorporating OLAP and AI. Through this function, instructions written in a natural language can be converted into SQL query statements that align with the table schema. For example, the function can be provided with a sentence like "Get all items that cost 10 dollars or less" as an input and generate the corresponding SQL query "SELECT * FROM items WHERE price <= 10" as output.
The main code implementation can be found here.
Starting from PlaidCloud Lakehouse v1.1.47, PlaidCloud Lakehouse supports the Azure OpenAI service.
This integration offers improved data privacy.
To use Azure OpenAI, add the following configurations to the [query] section:
# Azure OpenAI
openai_api_chat_base_url = "https://<name>.openai.azure.com/openai/deployments/<name>/"
openai_api_embedding_base_url = "https://<name>.openai.azure.com/openai/deployments/<name>/"
openai_api_version = "2023-03-15-preview"
PlaidCloud Lakehouse relies on (Azure) OpenAI for AI_TO_SQL but only sends the table schema to (Azure) OpenAI, not the data.
They will only work when the PlaidCloud Lakehouse configuration includes the openai_api_key, otherwise they will be inactive.
This function is available by default on PlaidCloud Lakehouse using an Azure OpenAI key. If you use them, you acknowledge that your table schema will be sent to Azure OpenAI by us.
Analyze Syntax
func.ai_to_sql('<natural-language-instruction>')
Analyze Examples
In this example, an SQL query statement is generated from an instruction with the AI_TO_SQL function, and the resulting statement is executed to obtain the query results.
func.ai_to_sql('List the total amount spent by users from the USA who are older than 30 years, grouped by their names, along with the number of orders they made in 2022')
A SQL statement is generated by the function as the output:
*************************** 1. row ***************************
database: openai
generated_sql: SELECT name, SUM(price) AS total_spent, COUNT(order_id) AS total_orders
FROM users
JOIN orders ON users.id = orders.user_id
WHERE country = 'USA' AND age > 30 AND order_date BETWEEN '2022-01-01' AND '2022-12-31'
GROUP BY name;
SQL Syntax
USE <your-database>;
SELECT * FROM ai_to_sql('<natural-language-instruction>');
Obtain and Config OpenAI API Key
- To obtain your openAI API key, please visit https://platform.openai.com/account/api-keys and generate a new key.
- Configure the databend-query.toml file with the openai_api_key setting.
[query]
... ...
openai_api_key = "<your-key>"
SQL Examples
In this example, an SQL query statement is generated from an instruction with the AI_TO_SQL function, and the resulting statement is executed to obtain the query results.
- Prepare data.
CREATE DATABASE IF NOT EXISTS openai;
USE openai;
CREATE TABLE users(
id INT,
name VARCHAR,
age INT,
country VARCHAR
);
CREATE TABLE orders(
order_id INT,
user_id INT,
product_name VARCHAR,
price DECIMAL(10,2),
order_date DATE
);
-- Insert sample data into the users table
INSERT INTO users VALUES (1, 'Alice', 31, 'USA'),
(2, 'Bob', 32, 'USA'),
(3, 'Charlie', 45, 'USA'),
(4, 'Diana', 29, 'USA'),
(5, 'Eva', 35, 'Canada');
-- Insert sample data into the orders table
INSERT INTO orders VALUES (1, 1, 'iPhone', 1000.00, '2022-03-05'),
(2, 1, 'OpenAI Plus', 20.00, '2022-03-06'),
(3, 2, 'OpenAI Plus', 20.00, '2022-03-07'),
(4, 2, 'MacBook Pro', 2000.00, '2022-03-10'),
(5, 3, 'iPad', 500.00, '2022-03-12'),
(6, 3, 'AirPods', 200.00, '2022-03-14');
- Run the AI_TO_SQL function with an instruction written in English as the input.
SELECT * FROM ai_to_sql(
'List the total amount spent by users from the USA who are older than 30 years, grouped by their names, along with the number of orders they made in 2022');
A SQL statement is generated by the function as the output:
*************************** 1. row ***************************
database: openai
generated_sql: SELECT name, SUM(price) AS total_spent, COUNT(order_id) AS total_orders
FROM users
JOIN orders ON users.id = orders.user_id
WHERE country = 'USA' AND age > 30 AND order_date BETWEEN '2022-01-01' AND '2022-12-31'
GROUP BY name;
- Run the generated SQL statement to get the query results.
+---------+-------------+-------------+
| name | order_count | total_spent |
+---------+-------------+-------------+
| Bob | 2 | 2020.00 |
| Alice | 2 | 1020.00 |
| Charlie | 2 | 700.00 |
+---------+-------------+-------------+
5.2.4 - COSINE_DISTANCE
This document provides an overview of the cosine_distance function in PlaidCloud Lakehouse and demonstrates how to measure document similarity using this function.
The cosine_distance function in PlaidCloud Lakehouse is a built-in function that calculates the cosine distance between two vectors. It is commonly used in natural language processing tasks, such as document similarity and recommendation systems.
Cosine distance is a measure of similarity between two vectors, based on the cosine of the angle between them. The function takes two input vectors and returns a value between 0 and 1, with 0 indicating identical vectors and 1 indicating orthogonal (completely dissimilar) vectors.
Analyze Syntax
func.cosine_distance(<vector1>, <vector2>)
SQL Examples
Creating a Table and Inserting Sample Data
Let's create a table to store some sample text documents and their corresponding embeddings:
CREATE TABLE articles (
id INT,
title VARCHAR,
content VARCHAR,
embedding ARRAY(FLOAT32)
);
Now, let's insert some sample documents into the table:
INSERT INTO articles (id, title, content, embedding)
VALUES
(1, 'Python for Data Science', 'Python is a versatile programming language widely used in data science...', ai_embedding_vector('Python is a versatile programming language widely used in data science...')),
(2, 'Introduction to R', 'R is a popular programming language for statistical computing and graphics...', ai_embedding_vector('R is a popular programming language for statistical computing and graphics...')),
(3, 'Getting Started with SQL', 'Structured Query Language (SQL) is a domain-specific language used for managing relational databases...', ai_embedding_vector('Structured Query Language (SQL) is a domain-specific language used for managing relational databases...'));
Querying for Similar Documents
Now, let's find the documents that are most similar to a given query using the cosine_distance function:
SELECT
id,
title,
content,
cosine_distance(embedding, ai_embedding_vector('How to use Python in data analysis?')) AS similarity
FROM
articles
ORDER BY
similarity ASC
LIMIT 3;
Result:
+------+--------------------------+---------------------------------------------------------------------------------------------------------+------------+
| id | title | content | similarity |
+------+--------------------------+---------------------------------------------------------------------------------------------------------+------------+
| 1 | Python for Data Science | Python is a versatile programming language widely used in data science... | 0.1142081 |
| 2 | Introduction to R | R is a popular programming language for statistical computing and graphics... | 0.18741018 |
| 3 | Getting Started with SQL | Structured Query Language (SQL) is a domain-specific language used for managing relational databases... | 0.25137568 |
+------+--------------------------+---------------------------------------------------------------------------------------------------------+------------+
5.3 - Array Functions
This section provides reference information for the array functions in PlaidCloud Lakehouse.
5.3.1 - ARRAY_AGGREGATE
Aggregates elements in the array with an aggregate function.
Analyze Syntax
func.array_aggregate( <array>, '<agg_func>' )
Supported aggregate functions include
avg,count,max,min,sum,any,stddev_samp,stddev_pop,stddev,std,median,approx_count_distinct,kurtosis, andskewness.The syntax can be rewritten as
func.array_<agg_func>( <array> ). For example,func.array_avg( <array> ).
Analyze Examples
func.array_aggregate([1, 2, 3, 4], 'sum'), func.array_sum([1, 2, 3, 4])
┌──────────────────────────────────────────────────────────────────────────┐
│ func.array_aggregate([1, 2, 3, 4], 'sum') │ func.array_sum([1, 2, 3, 4])│
├────────────────────────────────────────────┼─────────────────────────────┤
│ 10 │ 10 │
└──────────────────────────────────────────────────────────────────────────┘
SQL Syntax
ARRAY_AGGREGATE( <array>, '<agg_func>' )
Supported aggregate functions include
avg,count,max,min,sum,any,stddev_samp,stddev_pop,stddev,std,median,approx_count_distinct,kurtosis, andskewness.The syntax can be rewritten as
ARRAY_<agg_func>( <array> ). For example,ARRAY_AVG( <array> ).
SQL Examples
SELECT ARRAY_AGGREGATE([1, 2, 3, 4], 'SUM'), ARRAY_SUM([1, 2, 3, 4]);
┌────────────────────────────────────────────────────────────────┐
│ array_aggregate([1, 2, 3, 4], 'sum') │ array_sum([1, 2, 3, 4]) │
├──────────────────────────────────────┼─────────────────────────┤
│ 10 │ 10 │
└────────────────────────────────────────────────────────────────┘
5.3.2 - ARRAY_APPEND
Prepends an element to the array.
Analyze Syntax
func.array_append( <array>, <element>)
Analyze Examples
func.array_append([3, 4], 5)
┌──────────────────────────────┐
│ func.array_append([3, 4], 5) │
├──────────────────────────────┤
│ [3,4,5] │
└──────────────────────────────┘
SQL Syntax
ARRAY_APPEND( <array>, <element>)
SQL Examples
SELECT ARRAY_APPEND([3, 4], 5);
┌─────────────────────────┐
│ array_append([3, 4], 5) │
├─────────────────────────┤
│ [3,4,5] │
└─────────────────────────┘
5.3.3 - ARRAY_APPLY
Alias for ARRAY_TRANSFORM.
5.3.4 - ARRAY_CONCAT
Concats two arrays.
Analyze Syntax
func.array_concat( <array1>, <array2> )
Analyze Examples
func.array_concat([1, 2], [3, 4])
┌────────────────────────────────────┐
│ func.array_concat([1, 2], [3, 4]) │
├────────────────────────────────────┤
│ [1,2,3,4] │
└────────────────────────────────────┘
SQL Syntax
ARRAY_CONCAT( <array1>, <array2> )
SQL Examples
SELECT ARRAY_CONCAT([1, 2], [3, 4]);
┌──────────────────────────────┐
│ array_concat([1, 2], [3, 4]) │
├──────────────────────────────┤
│ [1,2,3,4] │
└──────────────────────────────┘
5.3.5 - ARRAY_CONTAINS
Alias for CONTAINS.
5.3.6 - ARRAY_DISTINCT
Removes all duplicates and NULLs from the array without preserving the original order.
Analyze Syntax
func.array_distinct( <array> )
Analyze Examples
func.array_distinct([1, 2, 2, 4, 3])
┌───────────────────────────────────────┐
│ func.array_distinct([1, 2, 2, 4, 3]) │
├───────────────────────────────────────┤
│ [1,2,4,3] │
└───────────────────────────────────────┘
SQL Syntax
ARRAY_DISTINCT( <array> )
SQL Examples
SELECT ARRAY_DISTINCT([1, 2, 2, 4, 3]);
┌─────────────────────────────────┐
│ array_distinct([1, 2, 2, 4, 3]) │
├─────────────────────────────────┤
│ [1,2,4,3] │
└─────────────────────────────────┘
5.3.7 - ARRAY_FILTER
Constructs an array from those elements of the input array for which the lambda function returns true.
Analyze Syntax
func.array_filter( <array>, <lambda> )
Analyze Examples
func.array_filter([1, 2, 3], x -> (x > 1))
┌─────────────────────────────────────────────┐
│ func.array_filter([1, 2, 3], x -> (x > 1)) │
├─────────────────────────────────────────────┤
│ [2,3] │
└─────────────────────────────────────────────┘
SQL Syntax
ARRAY_FILTER( <array>, <lambda> )
SQL Examples
SELECT ARRAY_FILTER([1, 2, 3], x -> x > 1);
┌───────────────────────────────────────┐
│ array_filter([1, 2, 3], x -> (x > 1)) │
├───────────────────────────────────────┤
│ [2,3] │
└───────────────────────────────────────┘
5.3.8 - ARRAY_FLATTEN
Flattens nested arrays, converting them into a single-level array.
Analyze Syntax
func.array_flatten( <array> )
Analyze Examples
func.array_flatten([[1, 2], [3, 4, 5]])
┌──────────────────────────────────────────┐
│ func.array_flatten([[1, 2], [3, 4, 5]]) │
├──────────────────────────────────────────┤
│ [1,2,3,4,5] │
└──────────────────────────────────────────┘
SQL Syntax
ARRAY_FLATTEN( <array> )
SQL Examples
SELECT ARRAY_FLATTEN([[1,2], [3,4,5]]);
┌────────────────────────────────────┐
│ array_flatten([[1, 2], [3, 4, 5]]) │
├────────────────────────────────────┤
│ [1,2,3,4,5] │
└────────────────────────────────────┘
5.3.9 - ARRAY_GET
Alias for GET.
5.3.10 - ARRAY_INDEXOF
Returns the index(1-based) of an element if the array contains the element.
Analyze Syntax
func.array_indexof( <array>, <element> )
Analyze Examples
func.array_indexof([1, 2, 9], 9)
┌───────────────────────────────────┐
│ func.array_indexof([1, 2, 9], 9) │
├───────────────────────────────────┤
│ 3 │
└───────────────────────────────────┘
SQL Syntax
ARRAY_INDEXOF( <array>, <element> )
SQL Examples
SELECT ARRAY_INDEXOF([1, 2, 9], 9);
┌─────────────────────────────┐
│ array_indexof([1, 2, 9], 9) │
├─────────────────────────────┤
│ 3 │
└─────────────────────────────┘
5.3.11 - ARRAY_LENGTH
Returns the length of an array.
Analyze Syntax
func.array_length( <array> )
Analyze Examples
func.array_length([1, 2])
┌────────────────────────────┐
│ func.array_length([1, 2]) │
├────────────────────────────┤
│ 2 │
└────────────────────────────┘
SQL Syntax
ARRAY_LENGTH( <array> )
SQL Examples
SELECT ARRAY_LENGTH([1, 2]);
┌──────────────────────┐
│ array_length([1, 2]) │
├──────────────────────┤
│ 2 │
└──────────────────────┘
5.3.12 - ARRAY_PREPEND
Prepends an element to the array.
Analyze Syntax
func.array_prepend( <element>, <array> )
Analyze Examples
func.array_prepend(1, [3, 4])
┌────────────────────────────────┐
│ func.array_prepend(1, [3, 4]) │
├────────────────────────────────┤
│ [1,3,4] │
└────────────────────────────────┘
SQL Syntax
ARRAY_PREPEND( <element>, <array> )
SQL Examples
SELECT ARRAY_PREPEND(1, [3, 4]);
┌──────────────────────────┐
│ array_prepend(1, [3, 4]) │
├──────────────────────────┤
│ [1,3,4] │
└──────────────────────────┘
5.3.13 - ARRAY_REDUCE
Applies iteratively the lambda function to the elements of the array, so as to reduce the array to a single value.
Analyze Syntax
func.array_reduce( <array>, <lambda> )
Analyze Examples
func.array_reduce([1, 2, 3, 4], (x, y) -> (x + y))
┌─────────────────────────────────────────────────────┐
│ func.array_reduce([1, 2, 3, 4], (x, y) -> (x + y)) │
├─────────────────────────────────────────────────────┤
│ 10 │
└─────────────────────────────────────────────────────┘
SQL Syntax
ARRAY_REDUCE( <array>, <lambda> )
SQL Examples
SELECT ARRAY_REDUCE([1, 2, 3, 4], (x,y) -> x + y);
┌───────────────────────────────────────────────┐
│ array_reduce([1, 2, 3, 4], (x, y) -> (x + y)) │
├───────────────────────────────────────────────┤
│ 10 │
└───────────────────────────────────────────────┘
5.3.14 - ARRAY_REMOVE_FIRST
Removes the first element from the array.
Analyze Syntax
func.array_remove_first( <array> )
Analyze Examples
func.array_remove_first([1, 2, 3])
┌─────────────────────────────────────┐
│ func.array_remove_first([1, 2, 3]) │
├─────────────────────────────────────┤
│ [2,3] │
└─────────────────────────────────────┘
SQL Syntax
ARRAY_REMOVE_FIRST( <array> )
SQL Examples
SELECT ARRAY_REMOVE_FIRST([1, 2, 3]);
┌───────────────────────────────┐
│ array_remove_first([1, 2, 3]) │
├───────────────────────────────┤
│ [2,3] │
└───────────────────────────────┘
5.3.15 - ARRAY_REMOVE_LAST
Removes the last element from the array.
Analyze Syntax
func.array_remove_last( <array> )
Analyze Examples
func.array_remove_last([1, 2, 3])
┌────────────────────────────────────┐
│ func.array_remove_last([1, 2, 3]) │
├────────────────────────────────────┤
│ [1,2] │
└────────────────────────────────────┘
SQL Syntax
ARRAY_REMOVE_LAST( <array> )
SQL Examples
SELECT ARRAY_REMOVE_LAST([1, 2, 3]);
┌──────────────────────────────┐
│ array_remove_last([1, 2, 3]) │
├──────────────────────────────┤
│ [1,2] │
└──────────────────────────────┘
5.3.16 - ARRAY_SIZE
Alias for ARRAY_LENGTH.
5.3.17 - ARRAY_SLICE
Alias for SLICE.
5.3.18 - ARRAY_SORT
Sorts elements in the array in ascending order.
Analyze Syntax
func.array_sort( <array>[, <order>, <nullposition>] )
| Parameter | Default | Description |
|---|---|---|
| order | ASC | Specifies the sorting order as either ascending (ASC) or descending (DESC). |
| nullposition | NULLS FIRST | Determines the position of NULL values in the sorting result, at the beginning (NULLS FIRST) or at the end (NULLS LAST) of the sorting output. |
Analyze Examples
func.array_sort([1, 4, 3, 2])
┌────────────────────────────────┐
│ func.array_sort([1, 4, 3, 2]) │
├────────────────────────────────┤
│ [1,2,3,4] │
└────────────────────────────────┘
SQL Syntax
ARRAY_SORT( <array>[, <order>, <nullposition>] )
| Parameter | Default | Description |
|---|---|---|
| order | ASC | Specifies the sorting order as either ascending (ASC) or descending (DESC). |
| nullposition | NULLS FIRST | Determines the position of NULL values in the sorting result, at the beginning (NULLS FIRST) or at the end (NULLS LAST) of the sorting output. |
SQL Examples
SELECT ARRAY_SORT([1, 4, 3, 2]);
┌──────────────────────────┐
│ array_sort([1, 4, 3, 2]) │
├──────────────────────────┤
│ [1,2,3,4] │
└──────────────────────────┘
5.3.19 - ARRAY_TO_STRING
Concatenates elements of an array into a single string, using a specified separator.
Analyze Syntax
func.array_to_string( <array>, '<separator>' )
Analyze Examples
func.array_to_string(['apple', 'banana', 'cherry'], ', ')
┌────────────────────────────────────────────────────────────┐
│ func.array_to_string(['apple', 'banana', 'cherry'], ', ') │
├────────────────────────────────────────────────────────────┤
│ Apple, Banana, Cherry │
└────────────────────────────────────────────────────────────┘
SQL Syntax
ARRAY_TO_STRING( <array>, '<separator>' )
SQL Examples
SELECT ARRAY_TO_STRING(['Apple', 'Banana', 'Cherry'], ', ');
┌──────────────────────────────────────────────────────┐
│ array_to_string(['apple', 'banana', 'cherry'], ', ') │
├──────────────────────────────────────────────────────┤
│ Apple, Banana, Cherry │
└──────────────────────────────────────────────────────┘
5.3.20 - ARRAY_TRANSFORM
Returns an array that is the result of applying the lambda function to each element of the input array.
Analyze Syntax
func.array_transform( <array>, <lambda> )
Analyze Examples
func.array_transform([1, 2, 3], x -> (x + 1))
┌───────────────────────────────────────────────┐
│ func.array_transform([1, 2, 3], x -> (x + 1)) │
├───────────────────────────────────────────────┤
│ [2,3,4] │
└───────────────────────────────────────────────┘
SQL Syntax
ARRAY_TRANSFORM( <array>, <lambda> )
Aliases
SQL Examples
SELECT ARRAY_TRANSFORM([1, 2, 3], x -> x + 1);
┌──────────────────────────────────────────┐
│ array_transform([1, 2, 3], x -> (x + 1)) │
├──────────────────────────────────────────┤
│ [2,3,4] │
└──────────────────────────────────────────┘
5.3.21 - ARRAY_UNIQUE
Counts unique elements in the array (except NULL).
Analyze Syntax
func.array_unique( <array> )
Analyze Examples
func.array_unique([1, 2, 3, 3, 4])
┌─────────────────────────────────────┐
│ func.array_unique([1, 2, 3, 3, 4]) │
├─────────────────────────────────────┤
│ 4 │
└─────────────────────────────────────┘
SQL Syntax
ARRAY_UNIQUE( <array> )
SQL Examples
SELECT ARRAY_UNIQUE([1, 2, 3, 3, 4]);
┌───────────────────────────────┐
│ array_unique([1, 2, 3, 3, 4]) │
├───────────────────────────────┤
│ 4 │
└───────────────────────────────┘
5.3.22 - ARRAYS_ZIP
Merges multiple arrays into a single array tuple.
Analyze Syntax
func.arrays_zip( <array1> [, ...] )
Analyze Examples
func.arrays_zip([1, 2, 3], ['a', 'b', 'c'])
┌──────────────────────────────────────────────┐
│ func.arrays_zip([1, 2, 3], ['a', 'b', 'c']) │
├──────────────────────────────────────────────┤
│ [(1,'a'),(2,'b'),(3,'c')] │
└──────────────────────────────────────────────┘
SQL Syntax
ARRAYS_ZIP( <array1> [, ...] )
Arguments
| Arguments | Description |
|---|---|
<arrayN> | The input ARRAYs. |
:::note
- The length of each array must be the same. :::
Return Type
Array(Tuple).
SQL Examples
SELECT ARRAYS_ZIP([1, 2, 3], ['a', 'b', 'c']);
┌────────────────────────────────────────┐
│ arrays_zip([1, 2, 3], ['a', 'b', 'c']) │
├────────────────────────────────────────┤
│ [(1,'a'),(2,'b'),(3,'c')] │
└────────────────────────────────────────┘
5.3.23 - CONTAINS
Checks if the array contains a specific element.
Analyze Syntax
func.contains( <array>, <element> )
Analyze Examples
func.contains([1, 2], 1)
┌───────────────────────────┐
│ func.contains([1, 2], 1) │
├───────────────────────────┤
│ true │
└───────────────────────────┘
SQL Syntax
CONTAINS( <array>, <element> )
Aliases
SQL Examples
SELECT ARRAY_CONTAINS([1, 2], 1), CONTAINS([1, 2], 1);
┌─────────────────────────────────────────────────┐
│ array_contains([1, 2], 1) │ contains([1, 2], 1) │
├───────────────────────────┼─────────────────────┤
│ true │ true │
└─────────────────────────────────────────────────┘
5.3.24 - GET
Returns an element from an array by index (1-based).
Analyze Syntax
func.get( <array>, <index> )
Analyze Examples
func.get([1, 2], 2)
┌─────────────────────┐
│ func.get([1, 2], 2) │
├─────────────────────┤
│ 2 │
└─────────────────────┘
SQL Syntax
GET( <array>, <index> )
Aliases
SQL Examples
SELECT GET([1, 2], 2), ARRAY_GET([1, 2], 2);
┌───────────────────────────────────────┐
│ get([1, 2], 2) │ array_get([1, 2], 2) │
├────────────────┼──────────────────────┤
│ 2 │ 2 │
└───────────────────────────────────────┘
5.3.25 - RANGE
Returns an array collected by [start, end).
Analyze Syntax
func.range( <start>, <end> )
SQAnalyzeL Examples
func.range(1, 5)
┌────────────────────┐
│ func.range(1, 5) │
├────────────────────┤
│ [1,2,3,4] │
└────────────────────┘
SQL Syntax
RANGE( <start>, <end> )
SQL Examples
SELECT RANGE(1, 5);
┌───────────────┐
│ range(1, 5) │
├───────────────┤
│ [1,2,3,4] │
└───────────────┘
5.3.26 - SLICE
Extracts a slice from the array by index (1-based).
Analyze Syntax
func.slice( <array>, <start>[, <end>] )
Analyze Examples
func.slice([1, 21, 32, 4], 2, 3)
┌──────────────────────────────────┐
│ func.slice([1, 21, 32, 4], 2, 3) │
├──────────────────────────────────┤
│ [21,32] │
└──────────────────────────────────┘
SQL Syntax
SLICE( <array>, <start>[, <end>] )
Aliases
SQL Examples
SELECT ARRAY_SLICE([1, 21, 32, 4], 2, 3), SLICE([1, 21, 32, 4], 2, 3);
┌─────────────────────────────────────────────────────────────────┐
│ array_slice([1, 21, 32, 4], 2, 3) │ slice([1, 21, 32, 4], 2, 3) │
├───────────────────────────────────┼─────────────────────────────┤
│ [21,32] │ [21,32] │
└─────────────────────────────────────────────────────────────────┘
5.3.27 - UNNEST
Unnests the array and returns the set of elements.
Analyze Syntax
func.unnest( <array> )
Analyze Examples
func.unnest([1, 2])
┌──────────────────────┐
│ func.unnest([1, 2]) │
├──────────────────────┤
│ 1 │
│ 2 │
└──────────────────────┘
SQL Syntax
UNNEST( <array> )
SQL Examples
SELECT UNNEST([1, 2]);
┌─────────────────┐
│ unnest([1, 2]) │
├─────────────────┤
│ 1 │
│ 2 │
└─────────────────┘
-- UNNEST(array) can be used as a table function.
SELECT * FROM UNNEST([1, 2]);
┌─────────────────┐
│ value │
├─────────────────┤
│ 1 │
│ 2 │
└─────────────────┘
A Practical Example
In the examples below, we will use the following table called contacts with the phones column defined with an array of text.
CREATE TABLE contacts (
id SERIAL PRIMARY KEY,
name VARCHAR (100),
phones TEXT []
);
The phones column is a one-dimensional array that holds various phone numbers that a contact may have.
To define multiple dimensional array, you add the square brackets.
For example, you can define a two-dimensional array as follows:
column_name data_type [][]
An example of inserting data into that table
INSERT INTO contacts (name, phones)
VALUES('John Doe',ARRAY [ '(408)-589-5846','(408)-589-5555' ]);
or
INSERT INTO contacts (name, phones)
VALUES('Lily Bush','{"(408)-589-5841"}'),
('William Gate','{"(408)-589-5842","(408)-589-5843"}');
The unnest() function expands an array to a list of rows. For example, the following query expands all phone numbers of the phones array.
SELECT
name,
unnest(phones)
FROM
contacts;
Output:
| name | unnest |
|---|---|
| John Doe | (408)-589-5846 |
| John Doe | (408)-589-5555 |
| Lily Bush | (408)-589-5841 |
| William Gate | (408)-589-5843 |
5.4 - Bitmap Functions
This section provides reference information for the bitmap functions in PlaidCloud Lakehouse.
5.4.1 - BITMAP_AND
Performs a bitwise AND operation on the two bitmaps.
Analyze Syntax
func.bitmap_and( <bitmap1>, <bitmap2> )
Analyze Examples
func.bitmap_and(func.build_bitmap([1, 4, 5]), func.cast(build_bitmap([4, 5])), string)
┌────────────────────────────────────────────────────────────────────────────────────────┐
│ func.bitmap_and(func.build_bitmap([1, 4, 5]), func.cast(build_bitmap([4, 5])), string) │
├────────────────────────────────────────────────────────────────────────────────────────┤
│ 4,5 │
└────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
BITMAP_AND( <bitmap1>, <bitmap2> )
SQL Examples
SELECT BITMAP_AND(BUILD_BITMAP([1,4,5]), BUILD_BITMAP([4,5]))::String;
┌───────────────────────────────────────────────────────────────────┐
│ bitmap_and(build_bitmap([1, 4, 5]), build_bitmap([4, 5]))::string │
├───────────────────────────────────────────────────────────────────┤
│ 4,5 │
└───────────────────────────────────────────────────────────────────┘
5.4.2 - BITMAP_AND_COUNT
Counts the number of bits set to 1 in the bitmap by performing a logical AND operation.
Analyze Syntax
func.bitmap_and_count( <bitmap> )
Analyze Examples
func.bitmap_and_count(to_bitmap('1, 3, 5'))
┌─────────────────────────────────────────────┐
│ func.bitmap_and_count(to_bitmap('1, 3, 5')) │
├─────────────────────────────────────────────┤
│ 3 │
└─────────────────────────────────────────────┘
SQL Syntax
BITMAP_AND_COUNT( <bitmap> )
SQL Examples
SELECT BITMAP_AND_COUNT(TO_BITMAP('1, 3, 5'));
┌────────────────────────────────────────┐
│ bitmap_and_count(to_bitmap('1, 3, 5')) │
├────────────────────────────────────────┤
│ 3 │
└────────────────────────────────────────┘
5.4.3 - BITMAP_AND_NOT
Alias for BITMAP_NOT.
5.4.4 - BITMAP_CARDINALITY
Alias for BITMAP_COUNT.
5.4.5 - BITMAP_CONTAINS
Checks if the bitmap contains a specific value.
Analyze Syntax
func.bitmap_contains( <bitmap>, <value> )
Analyze Examples
func.bitmap_contains(build_bitmap([1, 4, 5]), 1)
┌───────────────────────────────────────────────────┐
│ func.bitmap_contains(build_bitmap([1, 4, 5]), 1) │
├───────────────────────────────────────────────────┤
│ true │
└───────────────────────────────────────────────────┘
SQL Syntax
BITMAP_CONTAINS( <bitmap>, <value> )
SQL Examples
SELECT BITMAP_CONTAINS(BUILD_BITMAP([1,4,5]), 1);
┌─────────────────────────────────────────────┐
│ bitmap_contains(build_bitmap([1, 4, 5]), 1) │
├─────────────────────────────────────────────┤
│ true │
└─────────────────────────────────────────────┘
5.4.6 - BITMAP_COUNT
Counts the number of bits set to 1 in the bitmap.
Analyze Syntax
func.bitmap_count( <bitmap> )
Analyze Examples
func.bitmap_count(build_bitmap([1, 4, 5]))
┌────────────────────────────────────────────┐
│ func.bitmap_count(build_bitmap([1, 4, 5])) │
├────────────────────────────────────────────┤
│ 3 │
└────────────────────────────────────────────┘
SQL Syntax
BITMAP_COUNT( <bitmap> )
Aliases
SQL Examples
SELECT BITMAP_COUNT(BUILD_BITMAP([1,4,5])), BITMAP_CARDINALITY(BUILD_BITMAP([1,4,5]));
┌─────────────────────────────────────────────────────────────────────────────────────┐
│ bitmap_count(build_bitmap([1, 4, 5])) │ bitmap_cardinality(build_bitmap([1, 4, 5])) │
├───────────────────────────────────────┼─────────────────────────────────────────────┤
│ 3 │ 3 │
└─────────────────────────────────────────────────────────────────────────────────────┘
5.4.7 - BITMAP_HAS_ALL
Checks if the first bitmap contains all the bits in the second bitmap.
Analyze Syntax
func.bitmap_has_all( <bitmap1>, <bitmap2> )
Analyze Examples
func.bitmap_has_all(build_bitmap([1, 4, 5]), build_bitmap([1, 2]))
┌─────────────────────────────────────────────────────────────────────┐
│ func.bitmap_has_all(build_bitmap([1, 4, 5]), build_bitmap([1, 2])) │
├─────────────────────────────────────────────────────────────────────┤
│ false │
└─────────────────────────────────────────────────────────────────────┘
SQL Syntax
BITMAP_HAS_ALL( <bitmap1>, <bitmap2> )
SQL Examples
SELECT BITMAP_HAS_ALL(BUILD_BITMAP([1,4,5]), BUILD_BITMAP([1,2]));
┌───────────────────────────────────────────────────────────────┐
│ bitmap_has_all(build_bitmap([1, 4, 5]), build_bitmap([1, 2])) │
├───────────────────────────────────────────────────────────────┤
│ false │
└───────────────────────────────────────────────────────────────┘
5.4.8 - BITMAP_HAS_ANY
Checks if the first bitmap has any bit matching the bits in the second bitmap.
Analyze Syntax
func.bitmap_has_any( <bitmap1>, <bitmap2> )
Analyze Examples
func.bitmap_has_any(func.build_bitmap([1, 4, 5]), func.build_bitmap([1, 2]))
┌───────────────────────────────────────────────────────────────────────────────┐
│ func.bitmap_has_any(func.build_bitmap([1, 4, 5]), func.build_bitmap([1, 2])) │
├───────────────────────────────────────────────────────────────────────────────┤
│ true │
└───────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
BITMAP_HAS_ANY( <bitmap1>, <bitmap2> )
SQL Examples
SELECT BITMAP_HAS_ANY(BUILD_BITMAP([1,4,5]), BUILD_BITMAP([1,2]));
┌───────────────────────────────────────────────────────────────┐
│ bitmap_has_any(build_bitmap([1, 4, 5]), build_bitmap([1, 2])) │
├───────────────────────────────────────────────────────────────┤
│ true │
└───────────────────────────────────────────────────────────────┘
5.4.9 - BITMAP_INTERSECT
Counts the number of bits set to 1 in the bitmap by performing a logical INTERSECT operation.
Analyze Syntax
func.bitmap_intersect( <bitmap> )
Analyze Examples
func.bitmap_intersect(func.to_bitmap('1, 3, 5'))
┌──────────────────────────────────────────────────┐
│ func.bitmap_intersect(func.to_bitmap('1, 3, 5')) │
├──────────────────────────────────────────────────┤
│ 1,3,5 │
└──────────────────────────────────────────────────┘
SQL Syntax
BITMAP_INTERSECT( <bitmap> )
SQL Examples
SELECT BITMAP_INTERSECT(TO_BITMAP('1, 3, 5'))::String;
┌────────────────────────────────────────────────┐
│ bitmap_intersect(to_bitmap('1, 3, 5'))::string │
├────────────────────────────────────────────────┤
│ 1,3,5 │
└────────────────────────────────────────────────┘
5.4.10 - BITMAP_MAX
Gets the maximum value in the bitmap.
Analyze Syntax
func.bitmap_max( <bitmap> )
Analyze Examples
func.bitmap_max(func.build_bitmap([1, 4, 5]))
┌───────────────────────────────────────────────┐
│ func.bitmap_max(func.build_bitmap([1, 4, 5])) │
├───────────────────────────────────────────────┤
│ 5 │
└───────────────────────────────────────────────┘
SQL Syntax
BITMAP_MAX( <bitmap> )
SQL Examples
SELECT BITMAP_MAX(BUILD_BITMAP([1,4,5]));
┌─────────────────────────────────────┐
│ bitmap_max(build_bitmap([1, 4, 5])) │
├─────────────────────────────────────┤
│ 5 │
└─────────────────────────────────────┘
5.4.11 - BITMAP_MIN
Gets the minimum value in the bitmap.
Analyze Syntax
func.bitmap_min( <bitmap> )
Analyze Examples
func.bitmap_min(func.build_bitmap([1, 4, 5]))
┌───────────────────────────────────────────────┐
│ func.bitmap_min(func.build_bitmap([1, 4, 5])) │
├───────────────────────────────────────────────┤
│ 1 │
└───────────────────────────────────────────────┘
SQL Syntax
BITMAP_MIN( <bitmap> )
SQL Examples
SELECT BITMAP_MIN(BUILD_BITMAP([1,4,5]));
┌─────────────────────────────────────┐
│ bitmap_min(build_bitmap([1, 4, 5])) │
├─────────────────────────────────────┤
│ 1 │
└─────────────────────────────────────┘
5.4.12 - BITMAP_NOT
Generates a new bitmap with elements from the first bitmap that are not in the second one.
Analyze Syntax
func.bitmap_not( <bitmap1>, <bitmap2> )
Analyze Examples
func.bitmap_not(func.build_bitmap([1, 4, 5]), func.cast(func.build_bitmap([5, 6, 7])), Text)
┌───────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.bitmap_not(func.build_bitmap([1, 4, 5]), func.cast(func.build_bitmap([5, 6, 7])), Text) │
├───────────────────────────────────────────────────────────────────────────────────────────────┤
│ 1,4 │
└───────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
BITMAP_NOT( <bitmap1>, <bitmap2> )
Aliases
SQL Examples
SELECT BITMAP_NOT(BUILD_BITMAP([1,4,5]), BUILD_BITMAP([5,6,7]))::String;
┌──────────────────────────────────────────────────────────────────────┐
│ bitmap_not(build_bitmap([1, 4, 5]), build_bitmap([5, 6, 7]))::string │
├──────────────────────────────────────────────────────────────────────┤
│ 1,4 │
└──────────────────────────────────────────────────────────────────────┘
SELECT BITMAP_AND_NOT(BUILD_BITMAP([1,4,5]), BUILD_BITMAP([5,6,7]))::String;
┌──────────────────────────────────────────────────────────────────────────┐
│ bitmap_and_not(build_bitmap([1, 4, 5]), build_bitmap([5, 6, 7]))::string │
├──────────────────────────────────────────────────────────────────────────┤
│ 1,4 │
└──────────────────────────────────────────────────────────────────────────┘
5.4.13 - BITMAP_NOT_COUNT
Counts the number of bits set to 0 in the bitmap by performing a logical NOT operation.
Analyze Syntax
func.bitmap_not_count( <bitmap> )
Analyze Examples
func.bitmap_not_count(func.to_bitmap('1, 3, 5'))
┌──────────────────────────────────────────────────┐
│ func.bitmap_not_count(func.to_bitmap('1, 3, 5')) │
├──────────────────────────────────────────────────┤
│ 3 │
└──────────────────────────────────────────────────┘
SQL Syntax
BITMAP_NOT_COUNT( <bitmap> )
SQL Examples
SELECT BITMAP_NOT_COUNT(TO_BITMAP('1, 3, 5'));
┌────────────────────────────────────────┐
│ bitmap_not_count(to_bitmap('1, 3, 5')) │
├────────────────────────────────────────┤
│ 3 │
└────────────────────────────────────────┘
5.4.14 - BITMAP_OR
Performs a bitwise OR operation on the two bitmaps.
Analyze Syntax
func.bitmap_or( <bitmap1>, <bitmap2> )
Analyze Examples
func.bitmap_or(func.build_bitmap([1, 4, 5]), func.build_bitmap([6, 7]))
┌─────────────────────────────────────────────────────────────────────────┐
│ func.bitmap_or(func.build_bitmap([1, 4, 5]), func.build_bitmap([6, 7])) │
├─────────────────────────────────────────────────────────────────────────┤
│ 1,4,5,6,7 │
└─────────────────────────────────────────────────────────────────────────┘
SQL Syntax
BITMAP_OR( <bitmap1>, <bitmap2> )
SQL Examples
SELECT BITMAP_OR(BUILD_BITMAP([1,4,5]), BUILD_BITMAP([6,7]))::String;
┌──────────────────────────────────────────────────────────────────┐
│ bitmap_or(build_bitmap([1, 4, 5]), build_bitmap([6, 7]))::string │
├──────────────────────────────────────────────────────────────────┤
│ 1,4,5,6,7 │
└──────────────────────────────────────────────────────────────────┘
5.4.15 - BITMAP_OR_COUNT
Counts the number of bits set to 1 in the bitmap by performing a logical OR operation.
Analyze Syntax
func.bitmap_or_count( <bitmap> )
Analyze Examples
func.bitmap_or_count(func.to_bitmap('1, 3, 5'))
┌─────────────────────────────────────────────────┐
│ func.bitmap_or_count(func.to_bitmap('1, 3, 5')) │
├─────────────────────────────────────────────────┤
│ 3 │
└─────────────────────────────────────────────────┘
SQL Syntax
BITMAP_OR_COUNT( <bitmap> )
SQL Examples
SELECT BITMAP_OR_COUNT(TO_BITMAP('1, 3, 5'));
┌───────────────────────────────────────┐
│ bitmap_or_count(to_bitmap('1, 3, 5')) │
├───────────────────────────────────────┤
│ 3 │
└───────────────────────────────────────┘
5.4.16 - BITMAP_SUBSET_IN_RANGE
Generates a sub-bitmap of the source bitmap within a specified range.
Analyze Syntax
func.bitmap_subset_in_range( <bitmap>, <start>, <end> )
Analyze Examples
func.bitmap_subset_in_range(func.build_bitmap([5, 7, 9]), 6, 9)
┌─────────────────────────────────────────────────────────────────┐
│ func.bitmap_subset_in_range(func.build_bitmap([5, 7, 9]), 6, 9) │
├─────────────────────────────────────────────────────────────────┤
│ 7 │
└─────────────────────────────────────────────────────────────────┘
SQL Syntax
BITMAP_SUBSET_IN_RANGE( <bitmap>, <start>, <end> )
SQL Examples
SELECT BITMAP_SUBSET_IN_RANGE(BUILD_BITMAP([5,7,9]), 6, 9)::String;
┌───────────────────────────────────────────────────────────────┐
│ bitmap_subset_in_range(build_bitmap([5, 7, 9]), 6, 9)::string │
├───────────────────────────────────────────────────────────────┤
│ 7 │
└───────────────────────────────────────────────────────────────┘
5.4.17 - BITMAP_SUBSET_LIMIT
Generates a sub-bitmap of the source bitmap, beginning with a range from the start value, with a size limit.
Analyze Syntax
func.bitmap_subset_limit( <bitmap>, <start>, <limit> )
Analyze Examples
func.bitmap_subset_limit(func.build_bitmap([1, 4, 5]), 2, 2)
┌──────────────────────────────────────────────────────────────┐
│ func.bitmap_subset_limit(func.build_bitmap([1, 4, 5]), 2, 2) │
├──────────────────────────────────────────────────────────────┤
│ 4,5 │
└──────────────────────────────────────────────────────────────┘
SQL Syntax
BITMAP_SUBSET_LIMIT( <bitmap>, <start>, <limit> )
SQL Examples
SELECT BITMAP_SUBSET_LIMIT(BUILD_BITMAP([1,4,5]), 2, 2)::String;
┌────────────────────────────────────────────────────────────┐
│ bitmap_subset_limit(build_bitmap([1, 4, 5]), 2, 2)::string │
├────────────────────────────────────────────────────────────┤
│ 4,5 │
└────────────────────────────────────────────────────────────┘
5.4.18 - BITMAP_UNION
Counts the number of bits set to 1 in the bitmap by performing a logical UNION operation.
Analyze Syntax
func.bitmap_union( <bitmap> )
Analyze Examples
func.bitmap_union(func.to_bitmap('1, 3, 5'))
┌──────────────────────────────────────────────┐
│ func.bitmap_union(func.to_bitmap('1, 3, 5')) │
├──────────────────────────────────────────────┤
│ 1,3,5 │
└──────────────────────────────────────────────┘
SQL Syntax
BITMAP_UNION( <bitmap> )
SQL Examples
SELECT BITMAP_UNION(TO_BITMAP('1, 3, 5'))::String;
┌────────────────────────────────────────────┐
│ bitmap_union(to_bitmap('1, 3, 5'))::string │
├────────────────────────────────────────────┤
│ 1,3,5 │
└────────────────────────────────────────────┘
5.4.19 - BITMAP_XOR
Performs a bitwise XOR (exclusive OR) operation on the two bitmaps.
Analyze Syntax
func.bitmap_xor( <bitmap1>, <bitmap2> )
Analyze Examples
func.bitmap_xor(func.build_bitmap([1, 4, 5]), func.build_bitmap([5, 6, 7]))
┌─────────────────────────────────────────────────────────────────────────────┐
│ func.bitmap_xor(func.build_bitmap([1, 4, 5]), func.build_bitmap([5, 6, 7])) │
├─────────────────────────────────────────────────────────────────────────────┤
│ 1,4,6,7 │
└─────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
BITMAP_XOR( <bitmap1>, <bitmap2> )
SQL Examples
SELECT BITMAP_XOR(BUILD_BITMAP([1,4,5]), BUILD_BITMAP([5,6,7]))::String;
┌──────────────────────────────────────────────────────────────────────┐
│ bitmap_xor(build_bitmap([1, 4, 5]), build_bitmap([5, 6, 7]))::string │
├──────────────────────────────────────────────────────────────────────┤
│ 1,4,6,7 │
└──────────────────────────────────────────────────────────────────────┘
5.4.20 - BITMAP_XOR_COUNT
Counts the number of bits set to 1 in the bitmap by performing a logical XOR (exclusive OR) operation.
Analyze Syntax
func.bitmap_xor_count( <bitmap> )
Analyze Examples
func.bitmap_xor_count(func.to_bitmap('1, 3, 5'))
┌──────────────────────────────────────────────────┐
│ func.bitmap_xor_count(func.to_bitmap('1, 3, 5')) │
├──────────────────────────────────────────────────┤
│ 3 │
└──────────────────────────────────────────────────┘
SQL Syntax
BITMAP_XOR_COUNT( <bitmap> )
SQL Examples
SELECT BITMAP_XOR_COUNT(TO_BITMAP('1, 3, 5'));
┌────────────────────────────────────────┐
│ bitmap_xor_count(to_bitmap('1, 3, 5')) │
├────────────────────────────────────────┤
│ 3 │
└────────────────────────────────────────┘
5.4.21 - INTERSECT_COUNT
Counts the number of intersecting bits between two bitmap columns.
Analyze Syntax
func.intersect_count(( '<bitmap1>', '<bitmap2>' ), ( <bitmap_column1>, <bitmap_column2> ))
Analyze Examples
# Given a dataset like this:
┌───────────────────────────────────────┐
│ id │ tag │ v │
├─────────────────┼─────────────────────┤
│ 1 │ a │ 0, 1 │
│ 3 │ b │ 0, 1, 2 │
│ 2 │ c │ 1, 3, 4 │
└───────────────────────────────────────┘
# This is produced
func.intersect_count(('b', 'c'), (v, tag))
┌──────────────────────────────────────────────────────────┐
│ id │ func.intersect_count('b', 'c')(v, tag) │
├─────────────────┼────────────────────────────────────────┤
│ 1 │ 0 │
│ 3 │ 3 │
│ 2 │ 3 │
└──────────────────────────────────────────────────────────┘
SQL Syntax
INTERSECT_COUNT( '<bitmap1>', '<bitmap2>' )( <bitmap_column1>, <bitmap_column2> )
SQL Examples
CREATE TABLE agg_bitmap_test(id Int, tag String, v Bitmap);
INSERT INTO
agg_bitmap_test(id, tag, v)
VALUES
(1, 'a', to_bitmap('0, 1')),
(2, 'b', to_bitmap('0, 1, 2')),
(3, 'c', to_bitmap('1, 3, 4'));
SELECT id, INTERSECT_COUNT('b', 'c')(v, tag)
FROM agg_bitmap_test GROUP BY id;
┌─────────────────────────────────────────────────────┐
│ id │ intersect_count('b', 'c')(v, tag) │
├─────────────────┼───────────────────────────────────┤
│ 1 │ 0 │
│ 3 │ 3 │
│ 2 │ 3 │
└─────────────────────────────────────────────────────┘
5.4.22 - SUB_BITMAP
Generates a sub-bitmap of the source bitmap, beginning from the start index, with a specified size.
Analyze Syntax
func.sub_bitmap( <bitmap>, <start>, <size> )
Analyze Examples
func.sub_bitmap(func.build_bitmap([1, 2, 3, 4, 5]), 1, 3)
┌───────────────────────────────────────────────────────────┐
│ func.sub_bitmap(func.build_bitmap([1, 2, 3, 4, 5]), 1, 3) │
├───────────────────────────────────────────────────────────┤
│ 2,3,4 │
└───────────────────────────────────────────────────────────┘
SQL Syntax
SUB_BITMAP( <bitmap>, <start>, <size> )
SQL Examples
SELECT SUB_BITMAP(BUILD_BITMAP([1, 2, 3, 4, 5]), 1, 3)::String;
┌─────────────────────────────────────────────────────────┐
│ sub_bitmap(build_bitmap([1, 2, 3, 4, 5]), 1, 3)::string │
├─────────────────────────────────────────────────────────┤
│ 2,3,4 │
└─────────────────────────────────────────────────────────┘
5.5 - Conditional Functions
This section provides reference information for the conditional functions in PlaidCloud Lakehouse.
5.5.1 - [ NOT ] BETWEEN
Returns true if the given numeric or string <expr> falls inside the defined lower and upper limits.
Analyze Syntax
table.column.between(<lower_limit>, <upper_limit>
Analyze Examples
table.column.between(0, 5)
SQL Syntax
<expr> [ NOT ] BETWEEN <lower_limit> AND <upper_limit>
SQL Examples
SELECT 'true' WHERE 5 BETWEEN 0 AND 5;
┌────────┐
│ 'true' │
├────────┤
│ true │
└────────┘
SELECT 'true' WHERE 'data' BETWEEN 'data' AND 'databendcloud';
┌────────┐
│ 'true' │
├────────┤
│ true │
└────────┘
5.5.2 - [ NOT ] IN
Checks whether a value is (or is not) in an explicit list.
Analyze Syntax
table.columns.in_((<value1>, <value2> ...))
Analyze Examples
table.columns.in_((<value1>, <value2> ...))
┌──────────────────────────┐
│ table.column.in_((2, 3)) │
├──────────────────────────┤
│ true │
└──────────────────────────┘
SQL Syntax
<value> [ NOT ] IN (<value1>, <value2> ...)
SQL Examples
SELECT 1 NOT IN (2, 3);
┌────────────────┐
│ 1 not in(2, 3) │
├────────────────┤
│ true │
└────────────────┘
5.5.3 - AND
Conditional AND operator. Checks whether both conditions are true.
Analyze Syntax
and_(<expr1>[, <expr2> ...])
Analyze Examples
and_(
table.color == 'green',
table.shape == 'circle',
table.price >= 1.25
)
SQL Syntax
<expr1> AND <expr2>
SQL Examples
SELECT * FROM table WHERE
table.color = 'green'
AND table.shape = 'circle'
AND table.price >= 1.25;
5.5.4 - CASE
Handles IF/THEN logic. It is structured with at least one pair of WHEN and THEN statements. Every CASE statement must be concluded with the END keyword. The ELSE statement is optional, providing a way to capture values not explicitly specified in the WHEN and THEN statements.
SQL Syntax
case(
(<condition_1>, <value_1>),
(<condition_2>, <value_2>),
[ ... ]
[ else_=<value_n>]
)
Analyze Examples
A simple example
This example returns a person's name. It starts off searching to see if the first name column has a value (the "if"). If there is a value, concatenate the first name with the last name and return it (the "then"). If there isn't a first name, then return the last name only (the "else").
case(
(table.first_name.is_not(None), func.concat(table.first_name, table.last_name)),
else_=table.last_name
)
A more complex example with multiple conditions
This example returns a price based on quantity. "If" the quantity in the order is more than 100, then give the customer the special price. If it doesn't satisfy the first condition, go to the second. If the quantity is greater than 10 (11-100), then give the customer the bulk price. Otherwise give the customer the regular price.
case(
(order_table.qty > 100, item_table.specialprice),
(order_table.qty > 10, item_table.bulkprice),
else_=item_table.regularprice
)
This example returns the first initial of the person's first name. If the user's name is wendy, return W. Otherwise if the user's name is jack, return J. Otherwise return E.
case(
(users_table.name == "wendy", "W"),
(users_table.name == "jack", "J"),
else_='E'
)
The above may also be written in shorthand as:
case(
{"wendy": "W", "jack": "J"},
value=users_table.name,
else_='E'
)
Other Examples
In this example is from a Table:Lookup step where we are updating the "dock_final" column when the table1.dock_final value is Null.
case(
(table1.dock_final == Null, table2.dock_final),
else_ = table1.dock_final
)
This example is from a Table:Lookup step where we are updating the "Marketing Channel" column when "Marketing Channel" in table1 is not 'none' or the "Serial Number" contains a '_'.
case(
(get_column(table1, 'Marketing Channel') != 'none', get_column(table1, 'Marketing Channel')),
(get_column(table1, 'Serial Number').contains('_'), get_column(table1, 'Marketing Channel')),
(get_column(table2, 'Marketing Channel').is_not(Null), get_column(table2, 'Marketing Channel')),
else_ = 'none'
)
SQL Syntax
CASE
WHEN <condition_1> THEN <value_1>
[ WHEN <condition_2> THEN <value_2> ]
[ ... ]
[ ELSE <value_n> ]
END AS <column_name>
SQL Examples
This example categorizes employee salaries using a CASE statement, presenting details with a dynamically assigned column named "SalaryCategory":
-- Create a sample table
CREATE TABLE Employee (
EmployeeID INT,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Salary INT
);
-- Insert some sample data
INSERT INTO Employee VALUES (1, 'John', 'Doe', 50000);
INSERT INTO Employee VALUES (2, 'Jane', 'Smith', 60000);
INSERT INTO Employee VALUES (3, 'Bob', 'Johnson', 75000);
INSERT INTO Employee VALUES (4, 'Alice', 'Williams', 90000);
-- Add a new column 'SalaryCategory' using CASE statement
-- Categorize employees based on their salary
SELECT
EmployeeID,
FirstName,
LastName,
Salary,
CASE
WHEN Salary < 60000 THEN 'Low'
WHEN Salary >= 60000 AND Salary < 80000 THEN 'Medium'
WHEN Salary >= 80000 THEN 'High'
ELSE 'Unknown'
END AS SalaryCategory
FROM
Employee;
┌──────────────────────────────────────────────────────────────────────────────────────────┐
│ employeeid │ firstname │ lastname │ salary │ salarycategory │
├─────────────────┼──────────────────┼──────────────────┼─────────────────┼────────────────┤
│ 1 │ John │ Doe │ 50000 │ Low │
│ 2 │ Jane │ Smith │ 60000 │ Medium │
│ 4 │ Alice │ Williams │ 90000 │ High │
│ 3 │ Bob │ Johnson │ 75000 │ Medium │
└──────────────────────────────────────────────────────────────────────────────────────────┘
5.5.5 - COALESCE
Returns the first non-NULL expression within its arguments; if all arguments are NULL, it returns NULL.
Analyze Syntax
func.coalesce(<expr1>[, <expr2> ...])
Analyze Examples
func.coalesce(table.UOM, 'none', \n)
func.coalesce(get_column(table2, 'TECHNOLOGY_RATE'), 0.0)
func.coalesce(table_beta.adjusted_price, table_alpha.override_price, table_alpha.price) * table_beta.quantity_sold
SQL Syntax
COALESCE(<expr1>[, <expr2> ...])
SQL Examples
SELECT COALESCE(1), COALESCE(1, NULL), COALESCE(NULL, 1, 2);
┌────────────────────────────────────────────────────────┐
│ coalesce(1) │ coalesce(1, null) │ coalesce(null, 1, 2) │
├─────────────┼───────────────────┼──────────────────────┤
│ 1 │ 1 │ 1 │
└────────────────────────────────────────────────────────┘
SELECT COALESCE('a'), COALESCE('a', NULL), COALESCE(NULL, 'a', 'b');
┌────────────────────────────────────────────────────────────────┐
│ coalesce('a') │ coalesce('a', null) │ coalesce(null, 'a', 'b') │
├───────────────┼─────────────────────┼──────────────────────────┤
│ a │ a │ a │
└────────────────────────────────────────────────────────────────┘
5.5.6 - Comparison Methods
These comparison methods are available in Analyze expressions.
| Category | Expression | Structure | Example | Description |
|---|---|---|---|---|
| General Usage | > | > | table.column > 23 | Greater Than |
| General Usage | < | < | table.column < 23 | Less Than |
| General Usage | >= | >= | table.column >= 23 | Greater than or equal to |
| General Usage | <= | <= | table.column <= 23 | Less than or equal to |
| General Usage | == | == | table.column == 23 | Equal to |
| General Usage | != | != | table.column != 23 | Not Equal to |
| General Usage | and_ | and_() | and_(table.a > 23, table.b == u'blue') Additional Examples | Creates an AND SQL condition |
| General Usage | any_ | any_() | table.column.any(('red', 'blue', 'yellow')) | Applies the SQL ANY() condition to a column |
| General Usage | between | between | table.column.between(23, 46) get_column(table, 'LAST_CHANGED_DATE').between({start_date}, {end_date}) | Applies the SQL BETWEEN condition |
| General Usage | contains | contains | table.column.contains('mno') table.SOURCE_SYSTEM.contains('TEST') | Applies the SQL LIKE '%%' |
| General Usage | endswith | endswith | table.column.endswith('xyz') table.Parent.endswith(':EBITX') table.PERIOD.endswith("01") | Applies the SQL LIKE '%%' |
| General Usage | FALSE | FALSE | FALSE | False, false, FALSE - Alias for Python False |
| General Usage | ilike | ilike | table.column.ilike('%foobar%') | Applies the SQL ILIKE method |
| General Usage | in_ | in_() | table.column.in_((1, 2, 3)) get_column(table, 'Source Country').in_(['CN','SG','BR']) table.MONTH.in_(['01','02','03','04','05','06','07','08','09']) | Test if values are with a tuple of values |
| General Usage | is_ | is_ | table.column.is_(None) get_column(table, 'Min SafetyStock').is_(None) get_column(table, 'date_pod').is_(None) | Applies the SQL is the IS for things like IS NULL |
| General Usage | isnot | isnot | table.column.isnot(None) | Applies the SQL is the IS for things like IS NOT NULL |
| General Usage | like | like | table.column.like('%foobar%') table.SOURCE_SYSTEM.like('%Adjustments%') | Applies the SQL LIKE method |
| General Usage | not_ | not_() | not_(and_(table.a > 23, table.b == u'blue')) | Inverts the condition |
| General Usage | notilike | notilike | table.column.notilike('%foobar%') | Applies the SQL NOT ILIKE method |
| General Usage | notin | notin | table.column.notin((1, 2, 3)) table.LE.notin_(['12345','67890']) | Inverts the IN condition |
| General Usage | notlike | notlike | table.column.notlike('%foobar%') | Applies the SQL NOT LIKE method |
| General Usage | NULL | NULL | NULL | Null, null, NULL - Alias for Python None |
| General Usage | or_ | or_() | or_(table.a > 23, table.b == u'blue') Additional Examples | Creates an OR SQL condition |
| General Usage | startswith | startswith | table.column.startswith('abc') get_column(table, 'Zip Code').startswith('9') get_column(table1, 'GL Account').startswith('CORP') | Applies the SQL LIKE '%' |
| General Usage | TRUE | TRUE | TRUE | True, true, TRUE - Alias for Python True |
| Math Expressions | + | + | + | 2+3=5 |
| Math Expressions | – | – | - | 2–3=-1 |
| Math Expressions | * | * | * | 2*3=6 |
| Math Expressions | / | / | / | 4/2=2 |
| Math Expressions | column.op | column.op(operator) | column.op('%') | 5%4=1 |
| Math Expressions | column.op | column.op(operator) | column.op('^') | 2.0^3.0=8 |
| Math Expressions | column.op | column.op(operator) | column.op('!') | 5!=120 |
| Math Expressions | column.op | column.op(operator) | column.op('!!') | !!5=120 |
| Math Expressions | column.op | column.op(operator) | column.op('@') | @-5.0=5 |
| Math Expressions | column.op | column.op(operator) | column.op('&') | 91&15=11 |
| Math Expressions | column.op | column.op(operator) | column.op('#') | 17##5=20 |
| Math Expressions | column.op | column.op(operator) | column.op('~') | ~1=-2 |
| Math Expressions | column.op | column.op(operator) | column.op('<<') | 1<<4=16 |
| Math Expressions | column.op | column.op(operator) | column.op('>>') | 8>>2=2 |
5.5.7 - ERROR_OR
Returns the first non-error expression among its inputs. If all expressions result in errors, it returns NULL.
Analyze Syntax
func.error_or(expr1, expr2, ...)
Analyze Examples
# Returns the valid date if no errors occur
# Returns the current date if the conversion results in an error
func.now(), func.error_or(func.to_date('2024-12-25'), func.now())
┌──────────────────────────────────────────────────────────────────────────────────────────┐
│ func.now() │ func.error_or(func.to_date('2024-12-25'), func.now()) │
├─────────────────────────────────┼────────────────────────────────────────────────────────┤
│ 2024-03-18 01:22:39.460320 │ 2024-12-25 │
└──────────────────────────────────────────────────────────────────────────────────────────┘
# Returns NULL because the conversion results in an error
func.error_or(func.to_date('2024-1234'))
┌────────────────────────────────────────────┐
│ func.error_or(func.to_date('2024-1234')) │
├────────────────────────────────────────────┤
│ NULL │
└────────────────────────────────────────────┘
SQL Syntax
ERROR_OR(expr1, expr2, ...)
SQL Examples
-- Returns the valid date if no errors occur
-- Returns the current date if the conversion results in an error
SELECT NOW(), ERROR_OR('2024-12-25'::DATE, NOW()::DATE);
┌────────────────────────────────────────────────────────────────────────┐
│ now() │ error_or('2024-12-25'::date, now()::date) │
├────────────────────────────┼───────────────────────────────────────────┤
│ 2024-03-18 01:22:39.460320 │ 2024-12-25 │
└────────────────────────────────────────────────────────────────────────┘
-- Returns NULL because the conversion results in an error
SELECT ERROR_OR('2024-1234'::DATE);
┌─────────────────────────────┐
│ error_or('2024-1234'::date) │
├─────────────────────────────┤
│ NULL │
└─────────────────────────────┘
5.5.8 - GREATEST
Returns the maximum value from a set of values.
Analyze Syntax
func.greatest(<value1>, <value2> ...)
Analyze Examples
func.greatest((5, 9, 4))
┌──────────────────────────┐
│ func.greatest((5, 9, 4)) │
├──────────────────────────┤
│ 9 │
└──────────────────────────┘
SQL Syntax
GREATEST(<value1>, <value2> ...)
SQL Examples
SELECT GREATEST(5, 9, 4);
┌───────────────────┐
│ greatest(5, 9, 4) │
├───────────────────┤
│ 9 │
└───────────────────┘
5.5.9 - IF
If <cond1> is TRUE, it returns <expr1>. Otherwise if <cond2> is TRUE, it returns <expr2>, and so on.
Analyze Syntax
func.if(<cond1>, <expr1>, [<cond2>, <expr2> ...], <expr_else>)
Analyze Examples
func.if((1 > 2), 3, (4 < 5), 6, 7)
┌────────────────────────────────────┐
│ func.if((1 > 2), 3, (4 < 5), 6, 7) │
├────────────────────────────────────┤
│ 6 │
└────────────────────────────────────┘
SQL Syntax
IF(<cond1>, <expr1>, [<cond2>, <expr2> ...], <expr_else>)
SQL Examples
SELECT IF(1 > 2, 3, 4 < 5, 6, 7);
┌───────────────────────────────┐
│ if((1 > 2), 3, (4 < 5), 6, 7) │
├───────────────────────────────┤
│ 6 │
└───────────────────────────────┘
5.5.10 - IFNULL
If <expr1> is NULL, returns <expr2>, otherwise returns <expr1>.
Analyze Syntax
func.ifnull(<expr1>, <expr2>)
Analyze Examples
func.ifnull(null, 'b'), func.ifnull('a', 'b')
┌────────────────────────────────────────────────┐
│ func.ifnull(null, 'b') │ func.ifnull('a', 'b') │
├────────────────────────┼───────────────────────┤
│ b │ a │
└────────────────────────────────────────────────┘
func.ifnull(null, 2), func.ifnull(1, 2)
┌──────────────────────────────────────────┐
│ func.ifnull(null, 2) │ func.ifnull(1, 2) │
├──────────────────────┼───────────────────┤
│ 2 │ 1 │
└──────────────────────────────────────────┘
SQL Syntax
IFNULL(<expr1>, <expr2>)
Aliases
SQL Examples
SELECT IFNULL(NULL, 'b'), IFNULL('a', 'b');
┌──────────────────────────────────────┐
│ ifnull(null, 'b') │ ifnull('a', 'b') │
├───────────────────┼──────────────────┤
│ b │ a │
└──────────────────────────────────────┘
SELECT IFNULL(NULL, 2), IFNULL(1, 2);
┌────────────────────────────────┐
│ ifnull(null, 2) │ ifnull(1, 2) │
├─────────────────┼──────────────┤
│ 2 │ 1 │
└────────────────────────────────┘
5.5.11 - IS [ NOT ] DISTINCT FROM
Compares whether two expressions are equal (or not equal) with awareness of nullability, meaning it treats NULLs as known values for comparing equality.
SQL Syntax
<expr1> IS [ NOT ] DISTINCT FROM <expr2>
SQL Examples
SELECT NULL IS DISTINCT FROM NULL;
┌────────────────────────────┐
│ null is distinct from null │
├────────────────────────────┤
│ false │
└────────────────────────────┘
5.5.12 - IS_ERROR
Returns a Boolean value indicating whether an expression is an error value.
See also: IS_NOT_ERROR
Analyze Syntax
func.is_error( <expr> )
Analyze Examples
# Indicates division by zero, hence an error
func.is_error((1 / 0)), func.is_not_error((1 / 0))
┌─────────────────────────────────────────────────────┐
│ func.is_error((1 / 0)) │ func.is_not_error((1 / 0)) │
├────────────────────────┼────────────────────────────┤
│ true │ false │
└─────────────────────────────────────────────────────┘
# The conversion to DATE is successful, hence not an error
func.is_error(func.to_date('2024-03-17')), func.is_not_error(func.to_date('2024-03-17'))
┌───────────────────────────────────────────────────────────────────────────────────────────┐
│ func.is_error(func.to_date('2024-03-17')) │ func.is_not_error(func.to_date('2024-03-17')) │
├───────────────────────────────────────────┼───────────────────────────────────────────────┤
│ false │ true │
└───────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
IS_ERROR( <expr> )
Return Type
Returns true if the expression is an error, otherwise false.
SQL Examples
-- Indicates division by zero, hence an error
SELECT IS_ERROR(1/0), IS_NOT_ERROR(1/0);
┌───────────────────────────────────────────┐
│ is_error((1 / 0)) │ is_not_error((1 / 0)) │
├───────────────────┼───────────────────────┤
│ true │ false │
└───────────────────────────────────────────┘
-- The conversion to DATE is successful, hence not an error
SELECT IS_ERROR('2024-03-17'::DATE), IS_NOT_ERROR('2024-03-17'::DATE);
┌─────────────────────────────────────────────────────────────────┐
│ is_error('2024-03-17'::date) │ is_not_error('2024-03-17'::date) │
├──────────────────────────────┼──────────────────────────────────┤
│ false │ true │
└─────────────────────────────────────────────────────────────────┘
5.5.13 - IS_NOT_ERROR
Returns a Boolean value indicating whether an expression is an error value.
See also: IS_ERROR
Analyze Syntax
func.is_error( <expr> )
Analyze Examples
# Indicates division by zero, hence an error
func.is_error((1 / 0)), func.is_not_error((1 / 0))
┌─────────────────────────────────────────────────────┐
│ func.is_error((1 / 0)) │ func.is_not_error((1 / 0)) │
├────────────────────────┼────────────────────────────┤
│ true │ false │
└─────────────────────────────────────────────────────┘
# The conversion to DATE is successful, hence not an error
func.is_error(func.to_date('2024-03-17')), func.is_not_error(func.to_date('2024-03-17'))
┌───────────────────────────────────────────────────────────────────────────────────────────┐
│ func.is_error(func.to_date('2024-03-17')) │ func.is_not_error(func.to_date('2024-03-17')) │
├───────────────────────────────────────────┼───────────────────────────────────────────────┤
│ false │ true │
└───────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
IS_NOT_ERROR( <expr> )
Return Type
Returns true if the expression is not an error, otherwise false.
SQL Examples
-- Indicates division by zero, hence an error
SELECT IS_ERROR(1/0), IS_NOT_ERROR(1/0);
┌───────────────────────────────────────────┐
│ is_error((1 / 0)) │ is_not_error((1 / 0)) │
├───────────────────┼───────────────────────┤
│ true │ false │
└───────────────────────────────────────────┘
-- The conversion to DATE is successful, hence not an error
SELECT IS_ERROR('2024-03-17'::DATE), IS_NOT_ERROR('2024-03-17'::DATE);
┌─────────────────────────────────────────────────────────────────┐
│ is_error('2024-03-17'::date) │ is_not_error('2024-03-17'::date) │
├──────────────────────────────┼──────────────────────────────────┤
│ false │ true │
└─────────────────────────────────────────────────────────────────┘
5.5.14 - IS_NOT_NULL
Checks whether a value is not NULL.
Analyze Syntax
func.is_not_null(<expr>)
Analyze Examples
func.is_not_null(1)
┌─────────────────────┐
│ func.is_not_null(1) │
├─────────────────────┤
│ true │
└─────────────────────┘
SQL Syntax
IS_NOT_NULL(<expr>)
SQL Examples
SELECT IS_NOT_NULL(1);
┌────────────────┐
│ is_not_null(1) │
├────────────────┤
│ true │
└────────────────┘
5.5.15 - IS_NULL
Checks whether a value is NULL.
Analyze Syntax
func.is_null(<expr>)
Analyze Examples
func.is_null(1)
┌─────────────────┐
│ func.is_null(1) │
├─────────────────┤
│ false │
└─────────────────┘
SQL Syntax
IS_NULL(<expr>)
SQL Examples
SELECT IS_NULL(1);
┌────────────┐
│ is_null(1) │
├────────────┤
│ false │
└────────────┘
5.5.16 - LEAST
Returns the minimum value from a set of values.
Analyze Syntax
func.least((<value1>, <value2> ...))
Analyze Examples
func.least((5, 9, 4))
┌───────────────────────┐
│ func.least((5, 9, 4)) │
├───────────────────────┤
│ 4 │
└───────────────────────┘
SQL Syntax
LEAST(<value1>, <value2> ...)
SQL Examples
SELECT LEAST(5, 9, 4);
┌────────────────┐
│ least(5, 9, 4) │
├────────────────┤
│ 4 │
└────────────────┘
5.5.17 - NULLIF
Returns NULL if two expressions are equal. Otherwise return expr1. They must have the same data type.
Analyze Syntax
func.nullif(<expr1>, <expr2>)
Analyze Examples
func.nullif(0, null)
┌──────────────────────┐
│ func.nullif(0, null) │
├──────────────────────┤
│ 0 │
└──────────────────────┘
SQL Syntax
NULLIF(<expr1>, <expr2>)
SQL Examples
SELECT NULLIF(0, NULL);
┌─────────────────┐
│ nullif(0, null) │
├─────────────────┤
│ 0 │
└─────────────────┘
5.5.18 - NVL
If <expr1> is NULL, returns <expr2>, otherwise returns <expr1>.
Analyze Syntax
func.nvl(<expr1>, <expr2>)
Analyze Examples
func.nvl(null, 'b'), func.nvl('a', 'b')
┌──────────────────────────────────────────┐
│ func.nvl(null, 'b') │ func.nvl('a', 'b') │
├─────────────────────┼────────────────────┤
│ b │ a │
└──────────────────────────────────────────┘
func.nvl(null, 2), func.nvl(1, 2)
┌────────────────────────────────────┐
│ func.nvl(null, 2) │ func.nvl(1, 2) │
├───────────────────┼────────────────┤
│ 2 │ 1 │
└────────────────────────────────────┘
SQL Syntax
NVL(<expr1>, <expr2>)
Aliases
SQL Examples
SELECT NVL(NULL, 'b'), NVL('a', 'b');
┌────────────────────────────────┐
│ nvl(null, 'b') │ nvl('a', 'b') │
├────────────────┼───────────────┤
│ b │ a │
└────────────────────────────────┘
SELECT NVL(NULL, 2), NVL(1, 2);
┌──────────────────────────┐
│ nvl(null, 2) │ nvl(1, 2) │
├──────────────┼───────────┤
│ 2 │ 1 │
└──────────────────────────┘
5.5.19 - NVL2
Returns <expr2> if <expr1> is not NULL; otherwise, it returns <expr3>.
Analyze Syntax
func.nvl2(<expr1> , <expr2> , <expr3>)
Analyze Examples
func.nvl2('a', 'b', 'c'), func.nvl2(null, 'b', 'c')
┌──────────────────────────────────────────────────────┐
│ func.nvl2('a', 'b', 'c') │ func.nvl2(null, 'b', 'c') │
├──────────────────────────┼───────────────────────────┤
│ b │ c │
└──────────────────────────────────────────────────────┘
func.nvl2(1, 2, 3), func.nvl2(null, 2, 3)
┌────────────────────────────────────────────┐
│ func.nvl2(1, 2, 3) │ func.nvl2(null, 2, 3) │
├────────────────────┼───────────────────────┤
│ 2 │ 3 │
└────────────────────────────────────────────┘
SQL Syntax
NVL2(<expr1> , <expr2> , <expr3>)
SQL Examples
SELECT NVL2('a', 'b', 'c'), NVL2(NULL, 'b', 'c');
┌────────────────────────────────────────────┐
│ nvl2('a', 'b', 'c') │ nvl2(null, 'b', 'c') │
├─────────────────────┼──────────────────────┤
│ b │ c │
└────────────────────────────────────────────┘
SELECT NVL2(1, 2, 3), NVL2(NULL, 2, 3);
┌──────────────────────────────────┐
│ nvl2(1, 2, 3) │ nvl2(null, 2, 3) │
├───────────────┼──────────────────┤
│ 2 │ 3 │
└──────────────────────────────────┘
5.5.20 - OR
Conditional OR operator. Checks whether either condition is true.
Analyze Syntax
or_(<expr1>[, <expr2> ...])
Analyze Examples
or_(
table.color == 'green',
table.shape == 'circle',
table.price >= 1.25
)
SQL Syntax
<expr1> OR <expr2>
SQL Examples
SELECT * FROM table WHERE
table.color = 'green'
OR table.shape = 'circle'
OR table.price >= 1.25;
5.6 - Context Functions
This section provides reference information for the context-related functions in PlaidCloud Lakehouse.
5.6.1 - CONNECTION_ID
Returns the connection ID for the current connection.
Analyze Syntax
func.connection_id()
Analyze Examples
func.connection_id()
┌──────────────────────────────────────┐
│ func.connection_id() │
├──────────────────────────────────────┤
│ 23cb06ec-583e-4eba-b790-7c8cf72a53f8 │
└──────────────────────────────────────┘
SQL Syntax
CONNECTION_ID()
SQL Examples
SELECT CONNECTION_ID();
┌──────────────────────────────────────┐
│ connection_id() │
├──────────────────────────────────────┤
│ 23cb06ec-583e-4eba-b790-7c8cf72a53f8 │
└──────────────────────────────────────┘
5.6.2 - CURRENT_CATALOG
Returns the name of the catalog currently in use for the session.
SQL Syntax
CURRENT_CATALOG()
SQL Examples
SELECT CURRENT_CATALOG();
┌───────────────────┐
│ current_catalog() │
├───────────────────┤
│ default │
└───────────────────┘
5.6.3 - CURRENT_USER
Returns the user name and host name combination for the account that the server used to authenticate the current client. This account determines your access privileges. The return value is a string in the utf8 character set.
Analyze Syntax
func.current_user()
Analyze Examples
func.current_user()
┌─────────────────────┐
│ func.current_user() │
├─────────────────────┤
│ 'root'@'%' │
└─────────────────────┘
SQL Syntax
CURRENT_USER()
SQL Examples
SELECT CURRENT_USER();
┌────────────────┐
│ current_user() │
├────────────────┤
│ 'root'@'%' │
└────────────────┘
5.6.4 - DATABASE
Returns the name of the currently selected database. If no database is selected, then this function returns default.
Analyze Syntax
func.database()
Analyze Examples
func.database()
┌─────────────────┐
│ func.database() │
├─────────────────┤
│ default │
└─────────────────┘
SQL Syntax
DATABASE()
SQL Examples
SELECT DATABASE();
┌────────────┐
│ database() │
├────────────┤
│ default │
└────────────┘
5.6.5 - LAST_QUERY_ID
Returns the last query ID of query in current session, index can be (-1, 1, 1+2)..., out of range index will return empty string.
Analyze Syntax
func.last_query_id(<index>)
Analyze Examples
func.last_query_id(-1)
┌──────────────────────────────────────┐
│ func.last_query_id((- 1)) │
├──────────────────────────────────────┤
│ a6f615c6-5bad-4863-8558-afd01889448c │
└──────────────────────────────────────┘
SQL Syntax
LAST_QUERY_ID(<index>)
SQL Examples
SELECT LAST_QUERY_ID(-1);
┌──────────────────────────────────────┐
│ last_query_id((- 1)) │
├──────────────────────────────────────┤
│ a6f615c6-5bad-4863-8558-afd01889448c │
└──────────────────────────────────────┘
5.6.6 - VERSION
Returns the current version of PlaidCloud LakehouseQuery.
Analyze Syntax
func.version()
Analyze Examples
func.version()
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.version() │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ PlaidCloud LakehouseQuery v1.2.252-nightly-193ed56304(rust-1.75.0-nightly-2023-12-12T22:07:25.371440000Z) │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
VERSION()
SQL Examples
SELECT VERSION();
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ version() │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ PlaidCloud LakehouseQuery v1.2.252-nightly-193ed56304(rust-1.75.0-nightly-2023-12-12T22:07:25.371440000Z) │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.7 - Conversion Functions
This section provides reference information for the conversion functions in PlaidCloud Lakehouse.
Please note the following when converting a value from one type to another:
When converting from floating-point, decimal numbers, or strings to integers or decimal numbers with fractional parts, PlaidCloud Lakehouse rounds the values to the nearest integer. This is determined by the setting
numeric_cast_option(defaults to 'rounding') which controls the behavior of numeric casting operations. Whennumeric_cast_optionis explicitly set to 'truncating', PlaidCloud Lakehouse will truncate the decimal part, discarding any fractional values.SELECT CAST('0.6' AS DECIMAL(10, 0)), CAST(0.6 AS DECIMAL(10, 0)), CAST(1.5 AS INT); ┌──────────────────────────────────────────────────────────────────────────────────┐ │ cast('0.6' as decimal(10, 0)) │ cast(0.6 as decimal(10, 0)) │ cast(1.5 as int32) │ ├───────────────────────────────┼─────────────────────────────┼────────────────────┤ │ 1 │ 1 │ 2 │ └──────────────────────────────────────────────────────────────────────────────────┘ SET numeric_cast_option = 'truncating'; SELECT CAST('0.6' AS DECIMAL(10, 0)), CAST(0.6 AS DECIMAL(10, 0)), CAST(1.5 AS INT); ┌──────────────────────────────────────────────────────────────────────────────────┐ │ cast('0.6' as decimal(10, 0)) │ cast(0.6 as decimal(10, 0)) │ cast(1.5 as int32) │ ├───────────────────────────────┼─────────────────────────────┼────────────────────┤ │ 0 │ 0 │ 1 │ └──────────────────────────────────────────────────────────────────────────────────┘The table below presents a summary of numeric casting operations, highlighting the casting possibilities between different source and target numeric data types. Please note that, it specifies the requirement for String to Integer casting, where the source string must contain an integer value.
Source Type Target Type String Decimal Float Decimal Decimal Decimal Float Int Decimal Int String (Int) Int PlaidCloud Lakehouse also offers a variety of functions for converting expressions into different date and time formats. For more information, see Date & Time Functions.
5.7.1 - BUILD_BITMAP
Converts an array of positive integers to a BITMAP value.
Analyze Syntax
func.build_bitmap( <expr> )
Analyze Examples
func.to_string(func.build_bitmap([1, 4, 5]))
┌───────────────────────────────────────────────┐
│ func.to_string(func.build_bitmap([1, 4, 5])) │
├───────────────────────────────────────────────┤
│ 1,4,5 │
└───────────────────────────────────────────────┘
SQL Syntax
BUILD_BITMAP( <expr> )
SQL Examples
SELECT BUILD_BITMAP([1,4,5])::String;
┌─────────────────────────────────┐
│ build_bitmap([1, 4, 5])::string │
├─────────────────────────────────┤
│ 1,4,5 │
└─────────────────────────────────┘
5.7.2 - CAST, ::
Converts a value from one data type to another. :: is an alias for CAST.
See also: TRY_CAST
Analyze Syntax
func.cast( <expr>, <data_type> )
Analyze Examples
func.cast(1, string), func.to_string(1)
┌───────────────────────────────────────────┐
│ func.cast(1, string) │ func.to_string(1) │
├──────────────────────┼────────────────────┤
│ 1 │ 1 │
└───────────────────────────────────────────┘
SQL Syntax
CAST( <expr> AS <data_type> )
<expr>::<data_type>
SQL Examples
SELECT CAST(1 AS VARCHAR), 1::VARCHAR;
┌───────────────────────────────┐
│ cast(1 as string) │ 1::string │
├───────────────────┼───────────┤
│ 1 │ 1 │
└───────────────────────────────┘
5.7.3 - TO_BINARY
Converts supported data types, including string, variant, bitmap, geometry, and geography, into their binary representation (hex format).
See also: TRY_TO_BINARY
Analyze Syntax
func.to_binary( <expr> )
Analyze Examples
func.to_binary('Databend')
┌───────────────────────────────┐
│ func.to_binary('Databend') │
├───────────────────────────────┤
│ 4461746162656E64 │
└───────────────────────────────┘
SQL Syntax
TO_BINARY( <expr> )
SQL Examples
This example converts a string to binary:
SELECT TO_BINARY('Databend');
┌───────────────────────┐
│ to_binary('Databend') │
├───────────────────────┤
│ 4461746162656E64 │
└───────────────────────┘
This example converts JSON data to binary:
SELECT TO_BINARY(PARSE_JSON('{"key":"value", "number":123}')) AS binary_variant;
┌──────────────────────────────────────────────────────────────────────────┐
│ binary_variant │
├──────────────────────────────────────────────────────────────────────────┤
│ 40000002100000031000000610000005200000026B65796E756D62657276616C7565507B │
└──────────────────────────────────────────────────────────────────────────┘
This example converts bitmap data to binary:
SELECT TO_BINARY(TO_BITMAP('10,20,30')) AS binary_bitmap;
┌──────────────────────────────────────────────────────────────────────┐
│ binary_bitmap │
├──────────────────────────────────────────────────────────────────────┤
│ 0100000000000000000000003A3000000100000000000200100000000A0014001E00 │
└──────────────────────────────────────────────────────────────────────┘
This example converts geometry data (WKT format) to binary:
SELECT TO_BINARY(ST_GEOMETRYFROMWKT('SRID=4326;POINT(1.0 2.0)')) AS binary_geometry;
┌────────────────────────────────────────────────────┐
│ binary_geometry │
├────────────────────────────────────────────────────┤
│ 0101000020E6100000000000000000F03F0000000000000040 │
└────────────────────────────────────────────────────┘
This example converts geography data (EWKT format) to binary:
SELECT TO_BINARY(ST_GEOGRAPHYFROMEWKT('SRID=4326;POINT(-122.35 37.55)')) AS binary_geography;
┌────────────────────────────────────────────────────┐
│ binary_geography │
├────────────────────────────────────────────────────┤
│ 0101000020E61000006666666666965EC06666666666C64240 │
└────────────────────────────────────────────────────┘
5.7.4 - TO_BITMAP
Converts a value to BITMAP data type.
Analyze Syntax
func.to_bitmap( <expr> )
Analyze Examples
func.to_bitmap('1101')
┌─────────────────────────┐
│ func.to_bitmap('1101') │
├─────────────────────────┤
│ <bitmap binary> │
└─────────────────────────┘
SQL Syntax
TO_BITMAP( <expr> )
SQL Examples
SELECT TO_BITMAP('1101');
┌───────────────────┐
│ to_bitmap('1101') │
├───────────────────┤
│ <bitmap binary> │
└───────────────────┘
5.7.5 - TO_BOOLEAN
Converts a value to BOOLEAN data type.
Analyze Syntax
func.to_boolean( <expr> )
Analyze Examples
func.to_boolean('true')
┌──────────────────────────┐
│ func.to_boolean('true') │
├──────────────────────────┤
│ true │
└──────────────────────────┘
SQL Syntax
TO_BOOLEAN( <expr> )
SQL Examples
SELECT TO_BOOLEAN('true');
┌────────────────────┐
│ to_boolean('true') │
├────────────────────┤
│ true │
└────────────────────┘
5.7.6 - TO_FLOAT32
Converts a value to FLOAT32 data type.
Analyze Syntax
func.to_float32( <expr> )
Analyze Examples
func.to_float32('1.2')
┌─────────────────────────┐
│ func.to_float32('1.2') │
├─────────────────────────┤
│ 1.2 │
└─────────────────────────┘
SQL Syntax
TO_FLOAT32( <expr> )
SQL Examples
SELECT TO_FLOAT32('1.2');
┌───────────────────┐
│ to_float32('1.2') │
├───────────────────┤
│ 1.2 │
└───────────────────┘
5.7.7 - TO_FLOAT64
Converts a value to FLOAT64 data type.
Analyze Syntax
func.to_float64( <expr> )
Analyze Examples
func.to_float64('1.2')
┌─────────────────────────┐
│ func.to_float64('1.2') │
├─────────────────────────┤
│ 1.2 │
└─────────────────────────┘
SQL Syntax
TO_FLOAT64( <expr> )
SQL Examples
SELECT TO_FLOAT64('1.2');
┌───────────────────┐
│ to_float64('1.2') │
├───────────────────┤
│ 1.2 │
└───────────────────┘
5.7.8 - TO_HEX
For a string argument str, TO_HEX() returns a hexadecimal string representation of str where each byte of each character in str is converted to two hexadecimal digits. The inverse of this operation is performed by the UNHEX() function.
For a numeric argument N, TO_HEX() returns a hexadecimal string representation of the value of N treated as a longlong (BIGINT) number.
Analyze Syntax
func.to_hex(<expr>)
Analyze Examples
func.to_hex('abc')
┌────────────────────┐
│ func.to_hex('abc') │
├────────────────────┤
│ 616263 │
└────────────────────┘
SQL Syntax
TO_HEX(<expr>)
Aliases
SQL Examples
SELECT HEX('abc'), TO_HEX('abc');
┌────────────────────────────┐
│ hex('abc') │ to_hex('abc') │
├────────────┼───────────────┤
│ 616263 │ 616263 │
└────────────────────────────┘
SELECT HEX(255), TO_HEX(255);
┌────────────────────────┐
│ hex(255) │ to_hex(255) │
├──────────┼─────────────┤
│ ff │ ff │
└────────────────────────┘
5.7.9 - TO_INT16
Converts a value to INT16 data type.
Analyze Syntax
func.to_int16( <expr> )
Analyze Examples
func.to_int16('123')
┌──────────────────────┐
│ func.to_int16('123') │
├──────────────────────┤
│ 123 │
└──────────────────────┘
SQL Syntax
TO_INT16( <expr> )
SQL Examples
SELECT TO_INT16('123');
┌─────────────────┐
│ to_int16('123') │
├─────────────────┤
│ 123 │
└─────────────────┘
5.7.10 - TO_INT32
Converts a value to INT32 data type.
Analyze Syntax
func.to_int32( <expr> )
Analyze Examples
func.to_int32('123')
┌──────────────────────┐
│ func.to_int32('123') │
├──────────────────────┤
│ 123 │
└──────────────────────┘
SQL Syntax
TO_INT32( <expr> )
SQL Examples
SELECT TO_INT32('123');
┌─────────────────┐
│ to_int32('123') │
├─────────────────┤
│ 123 │
└─────────────────┘
5.7.11 - TO_INT64
Converts a value to INT64 data type.
Analyze Syntax
func.to_int64( <expr> )
Analyze Examples
func.to_int64('123')
┌──────────────────────┐
│ func.to_int64('123') │
├──────────────────────┤
│ 123 │
└──────────────────────┘
SQL Syntax
TO_INT64( <expr> )
SQL Examples
SELECT TO_INT64('123');
┌─────────────────┐
│ to_int64('123') │
├─────────────────┤
│ 123 │
└─────────────────┘
5.7.12 - TO_INT8
Converts a value to INT8 data type.
Analyze Syntax
func.to_int8( <expr> )
Analyze Examples
func.to_int8('123')
┌─────────────────────┐
│ func.to_int8('123') │
├─────────────────────┤
│ 123 │
└─────────────────────┘
SQL Syntax
TO_INT8( <expr> )
SQL Examples
SELECT TO_INT8('123');
┌────────────────┐
│ to_int8('123') │
│ UInt8 │
├────────────────┤
│ 123 │
└────────────────┘
5.7.13 - TO_STRING
Converts a value to String data type, or converts a Date value to a specific string format. To customize the format of date and time in PlaidCloud Lakehouse, you can utilize specifiers. These specifiers allow you to define the desired format for date and time values. For a comprehensive list of supported specifiers, see Formatting Date and Time.
Analyze Syntax
func.to_string( '<expr>' )
Analyze Examples
func.date_format('1.23'), func.to_string('1.23'), func.to_text('1.23'), func.to_varchar('1.23'), func.json_to_string('1.23')
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.date_format('1.23') │ func.to_string('1.23') │ func.to_text('1.23') │ func.to_varchar('1.23') │ func.json_to_string('1.23') │
├──────────────────────────┼────────────────────────┼──────────────────────┼─────────────────────────┼─────────────────────────────┤
│ 1.23 │ 1.23 │ 1.23 │ 1.23 │ 1.23 │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_STRING( '<expr>' )
TO_STRING( '<date>', '<format>' )
Aliases
Return Type
String.
SQL Examples
SELECT
DATE_FORMAT('1.23'),
TO_STRING('1.23'),
TO_TEXT('1.23'),
TO_VARCHAR('1.23'),
JSON_TO_STRING('1.23');
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ date_format('1.23') │ to_string('1.23') │ to_text('1.23') │ to_varchar('1.23') │ json_to_string('1.23') │
├─────────────────────┼───────────────────┼─────────────────┼────────────────────┼────────────────────────┤
│ 1.23 │ 1.23 │ 1.23 │ 1.23 │ 1.23 │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SELECT
DATE_FORMAT('["Cooking", "Reading"]' :: JSON),
TO_STRING('["Cooking", "Reading"]' :: JSON),
TO_TEXT('["Cooking", "Reading"]' :: JSON),
TO_VARCHAR('["Cooking", "Reading"]' :: JSON),
JSON_TO_STRING('["Cooking", "Reading"]' :: JSON);
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ date_format('["cooking", "reading"]'::variant) │ to_string('["cooking", "reading"]'::variant) │ to_text('["cooking", "reading"]'::variant) │ to_varchar('["cooking", "reading"]'::variant) │ json_to_string('["cooking", "reading"]'::variant) │
├────────────────────────────────────────────────┼──────────────────────────────────────────────┼────────────────────────────────────────────┼───────────────────────────────────────────────┼───────────────────────────────────────────────────┤
│ ["Cooking","Reading"] │ ["Cooking","Reading"] │ ["Cooking","Reading"] │ ["Cooking","Reading"] │ ["Cooking","Reading"] │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- With one argument, the function converts input to a string without validating as a date.
SELECT
DATE_FORMAT('20223-12-25'),
TO_STRING('20223-12-25'),
TO_TEXT('20223-12-25'),
TO_VARCHAR('20223-12-25'),
JSON_TO_STRING('20223-12-25');
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ date_format('20223-12-25') │ to_string('20223-12-25') │ to_text('20223-12-25') │ to_varchar('20223-12-25') │ json_to_string('20223-12-25') │
├────────────────────────────┼──────────────────────────┼────────────────────────┼───────────────────────────┼───────────────────────────────┤
│ 20223-12-25 │ 20223-12-25 │ 20223-12-25 │ 20223-12-25 │ 20223-12-25 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SELECT
DATE_FORMAT('2022-12-25', '%m/%d/%Y'),
TO_STRING('2022-12-25', '%m/%d/%Y'),
TO_TEXT('2022-12-25', '%m/%d/%Y'),
TO_VARCHAR('2022-12-25', '%m/%d/%Y'),
JSON_TO_STRING('2022-12-25', '%m/%d/%Y');
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ date_format('2022-12-25', '%m/%d/%y') │ to_string('2022-12-25', '%m/%d/%y') │ to_text('2022-12-25', '%m/%d/%y') │ to_varchar('2022-12-25', '%m/%d/%y') │ json_to_string('2022-12-25', '%m/%d/%y') │
├───────────────────────────────────────┼─────────────────────────────────────┼───────────────────────────────────┼──────────────────────────────────────┼──────────────────────────────────────────┤
│ 12/25/2022 │ 12/25/2022 │ 12/25/2022 │ 12/25/2022 │ 12/25/2022 │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.7.14 - TO_TEXT
Alias for TO_STRING.
5.7.15 - TO_UINT16
Converts a value to UINT16 data type.
Analyze Syntax
func.to_uint16( <expr> )
Analyze Examples
func.to_uint16('123')
┌───────────────────────┐
│ func.to_uint16('123') │
├───────────────────────┤
│ 123 │
└───────────────────────┘
SQL Syntax
TO_UINT16( <expr> )
SQL Examples
SELECT TO_UINT16('123');
┌──────────────────┐
│ to_uint16('123') │
├──────────────────┤
│ 123 │
└──────────────────┘
5.7.16 - TO_UINT32
Converts a value to UINT32 data type.
Analyze Syntax
func.to_uint32( <expr> )
Analyze Examples
func.to_uint32('123')
┌───────────────────────┐
│ func.to_uint32('123') │
├───────────────────────┤
│ 123 │
└───────────────────────┘
SQL Syntax
TO_UINT32( <expr> )
SQL Examples
SELECT TO_UINT32('123');
┌──────────────────┐
│ to_uint32('123') │
├──────────────────┤
│ 123 │
└──────────────────┘
5.7.17 - TO_UINT64
Converts a value to UINT64 data type.
Analyze Syntax
func.to_uint64( <expr> )
Analyze Examples
func.to_uint64('123')
┌───────────────────────┐
│ func.to_uint64('123') │
├───────────────────────┤
│ 123 │
└───────────────────────┘
SQL Syntax
TO_UINT64( <expr> )
SQL Examples
SELECT TO_UINT64('123');
┌──────────────────┐
│ to_uint64('123') │
├──────────────────┤
│ 123 │
└──────────────────┘
5.7.18 - TO_UINT8
Converts a value to UINT8 data type.
Analyze Syntax
func.to_uint8( <expr> )
Analyze Examples
func.to_uint8('123')
┌──────────────────────┐
│ func.to_uint8('123') │
├──────────────────────┤
│ 123 │
└──────────────────────┘
SQL Syntax
TO_UINT8( <expr> )
SQL Examples
SELECT TO_UINT8('123');
┌─────────────────┐
│ to_uint8('123') │
├─────────────────┤
│ 123 │
└─────────────────┘
5.7.19 - TO_VARCHAR
Alias for TO_STRING.
5.7.20 - TO_VARIANT
Converts a value to VARIANT data type.
Analyze Syntax
func.to_variant( <expr> )
Analyze Examples
func.to_variant(to_bitmap('100,200,300'))
┌───────────────────────────────────────────┐
│ func.to_variant(to_bitmap('100,200,300')) │
├───────────────────────────────────────────┤
│ [100,200,300] │
└───────────────────────────────────────────┘
SQL Syntax
TO_VARIANT( <expr> )
SQL Examples
SELECT TO_VARIANT(TO_BITMAP('100,200,300'));
┌──────────────────────────────────────┐
│ to_variant(to_bitmap('100,200,300')) │
├──────────────────────────────────────┤
│ [100,200,300] │
└──────────────────────────────────────┘
5.7.21 - TRY_CAST
Converts a value from one data type to another. Returns NULL on error.
See also: CAST
Analyze Syntax
func.try_cast( <expr>, <data_type> )
Analyze Examples
func.try_cast(1, string)
┌──────────────────────────┐
│ func.try_cast(1, string) │
├──────────────────────────┤
│ 1 │
└──────────────────────────┘
SQL Syntax
TRY_CAST( <expr> AS <data_type> )
SQL Examples
SELECT TRY_CAST(1 AS VARCHAR);
┌───────────────────────┐
│ try_cast(1 as string) │
├───────────────────────┤
│ 1 │
└───────────────────────┘
5.7.22 - TRY_TO_BINARY
An enhanced version of TO_BINARY that converts an input expression to a binary value, returning NULL if the conversion fails instead of raising an error.
See also: TO_BINARY
Analyze Syntax
func.try_to_binary( <expr> )
Analyze Examples
func.try_to_binary('Databend')
┌───────────────────────────────────────┐
│ func.try_to_binary('Databend') │
├───────────────────────────────────────┤
│ 4461746162656E64 │
└───────────────────────────────────────┘
SQL Syntax
TRY_TO_BINARY( <expr> )
Examples
This example successfully converts the JSON data to binary:
SELECT TRY_TO_BINARY(PARSE_JSON('{"key":"value", "number":123}')) AS binary_variant_success;
┌──────────────────────────────────────────────────────────────────────────┐
│ binary_variant │
├──────────────────────────────────────────────────────────────────────────┤
│ 40000002100000031000000610000005200000026B65796E756D62657276616C7565507B │
└──────────────────────────────────────────────────────────────────────────┘
This example demonstrates that the function fails to convert when the input is NULL:
SELECT TRY_TO_BINARY(PARSE_JSON(NULL)) AS binary_variant_invalid_json;
┌─────────────────────────────┐
│ binary_variant_invalid_json │
├─────────────────────────────┤
│ NULL │
└─────────────────────────────┘
5.8 - Date & Time Functions
This section provides reference information for the datetime-related functions in PlaidCloud Lakehouse.
Conversion Functions
- DATE
- TO_MONTH
- MONTH
- TO_DATE
- TO_DATETIME
- TODAY
- TO_DAY_OF_MONTH
- DAY
- TO_DAY_OF_WEEK
- TO_DAY_OF_YEAR
- TO_HOUR
- TO_MINUTE
- TO_MONDAY
- TOMORROW
- TO_QUARTER
- QUARTER
- TO_SECOND
- TO_START_OF_DAY
- TO_START_OF_FIFTEEN_MINUTES
- TO_START_OF_FIVE_MINUTES
- TO_START_OF_HOUR
- TO_START_OF_ISO_YEAR
- TO_START_OF_MINUTE
- TO_START_OF_MONTH
- TO_START_OF_QUARTER
- TO_START_OF_SECOND
- TO_START_OF_TENMINUTES
- TO_START_OF_WEEK
- TO_START_OF_YEAR
- TOTIMESTAMP
- TO_UNIX_TIMESTAMP
- TO_WEEK_OF_YEAR
- WEEK
- WEEKOFYEAR
- TO_YEAR
- YEAR
- TO_YYYYMM
- TO_YYYYMMDD
- TO_YYYYMMDDHH
- TO_YYYYMMDDHHMMSS
Date Arithmetic Functions
Date Information Functions
Others
5.8.1 - ADD TIME INTERVAL
Add a time interval to a date or timestamp, return the result of date or timestamp type.
Analyze Syntax
func.add_years(<exp0>, <expr1>)
func.add_quarters(<exp0>, <expr1>)
func.add_months(<exp0>, <expr1>)
func.add_days(<exp0>, <expr1>)
func.add_hours(<exp0>, <expr1>)
func.add_minutes(<exp0>, <expr1>)
func.add_seconds(<exp0>, <expr1>)
Analyze Examples
func.to_date(18875), func.add_years(func.to_date(18875), 2)
+---------------------------------+---------------------------------------------------+
| func.to_date(18875) | func.add_years(func.to_date(18875), 2) |
+---------------------------------+---------------------------------------------------+
| 2021-09-05 | 2023-09-05 |
+---------------------------------+---------------------------------------------------+
func.to_date(18875), func.add_quarters(func.to_date(18875), 2)
+---------------------------------+---------------------------------------------------+
| func.to_date(18875) | add_quarters(func.to_date(18875), 2) |
+---------------------------------+---------------------------------------------------+
| 2021-09-05 | 2022-03-05 |
+---------------------------------+---------------------------------------------------+
func.to_date(18875), func.add_months(func.to_date(18875), 2)
+---------------------------------+---------------------------------------------------+
| func.to_date(18875) | func.add_months(func.to_date(18875), 2) |
+---------------------------------+---------------------------------------------------+
| 2021-09-05 | 2021-11-05 |
+---------------------------------+---------------------------------------------------+
func.to_date(18875), func.add_days(func.to_date(18875), 2)
+---------------------------------+---------------------------------------------------+
| func.to_date(18875) | func.add_days(func.to_date(18875), 2) |
+---------------------------------+---------------------------------------------------+
| 2021-09-05 | 2021-09-07 |
+---------------------------------+---------------------------------------------------+
func.to_datetime(1630833797), func.add_hours(func.to_datetime(1630833797), 2)
+---------------------------------+---------------------------------------------------+
| func.to_datetime(1630833797) | func.add_hours(func.to_datetime(1630833797), 2) |
+---------------------------------+---------------------------------------------------+
| 2021-09-05 09:23:17.000000 | 2021-09-05 11:23:17.000000 |
+---------------------------------+---------------------------------------------------+
func.to_datetime(1630833797), func.add_minutes(func.to_datetime(1630833797), 2)
+---------------------------------+---------------------------------------------------+
| func.to_datetime(1630833797) | func.add_minutes(func.to_datetime(1630833797), 2) |
+---------------------------------+---------------------------------------------------+
| 2021-09-05 09:23:17.000000 | 2021-09-05 09:25:17.000000 |
+---------------------------------+---------------------------------------------------+
func.to_datetime(1630833797), func.add_seconds(func.to_datetime(1630833797), 2)
+---------------------------------+---------------------------------------------------+
| func.to_datetime(1630833797) | func.add_seconds(func.to_datetime(1630833797), 2) |
+---------------------------------+---------------------------------------------------+
| 2021-09-05 09:23:17.000000 | 2021-09-05 09:23:19.000000 |
+---------------------------------+---------------------------------------------------+
SQL Syntax
ADD_YEARS(<exp0>, <expr1>)
ADD_QUARTERs(<exp0>, <expr1>)
ADD_MONTHS(<exp0>, <expr1>)
ADD_DAYS(<exp0>, <expr1>)
ADD_HOURS(<exp0>, <expr1>)
ADD_MINUTES(<exp0>, <expr1>)
ADD_SECONDS(<exp0>, <expr1>)
Return Type
DATE, TIMESTAMP, depends on the input.
SQL Examples
SELECT to_date(18875), add_years(to_date(18875), 2);
+----------------+------------------------------+
| to_date(18875) | add_years(to_date(18875), 2) |
+----------------+------------------------------+
| 2021-09-05 | 2023-09-05 |
+----------------+------------------------------+
SELECT to_date(18875), add_quarters(to_date(18875), 2);
+----------------+---------------------------------+
| to_date(18875) | add_quarters(to_date(18875), 2) |
+----------------+---------------------------------+
| 2021-09-05 | 2022-03-05 |
+----------------+---------------------------------+
SELECT to_date(18875), add_months(to_date(18875), 2);
+----------------+-------------------------------+
| to_date(18875) | add_months(to_date(18875), 2) |
+----------------+-------------------------------+
| 2021-09-05 | 2021-11-05 |
+----------------+-------------------------------+
SELECT to_date(18875), add_days(to_date(18875), 2);
+----------------+-----------------------------+
| to_date(18875) | add_days(to_date(18875), 2) |
+----------------+-----------------------------+
| 2021-09-05 | 2021-09-07 |
+----------------+-----------------------------+
SELECT to_datetime(1630833797), add_hours(to_datetime(1630833797), 2);
+----------------------------+---------------------------------------+
| to_datetime(1630833797) | add_hours(to_datetime(1630833797), 2) |
+----------------------------+---------------------------------------+
| 2021-09-05 09:23:17.000000 | 2021-09-05 11:23:17.000000 |
+----------------------------+---------------------------------------+
SELECT to_datetime(1630833797), add_minutes(to_datetime(1630833797), 2);
+----------------------------+-----------------------------------------+
| to_datetime(1630833797) | add_minutes(to_datetime(1630833797), 2) |
+----------------------------+-----------------------------------------+
| 2021-09-05 09:23:17.000000 | 2021-09-05 09:25:17.000000 |
+----------------------------+-----------------------------------------+
SELECT to_datetime(1630833797), add_seconds(to_datetime(1630833797), 2);
+----------------------------+-----------------------------------------+
| to_datetime(1630833797) | add_seconds(to_datetime(1630833797), 2) |
+----------------------------+-----------------------------------------+
| 2021-09-05 09:23:17.000000 | 2021-09-05 09:23:19.000000 |
+----------------------------+-----------------------------------------+
5.8.2 - CURRENT_TIMESTAMP
Alias for NOW.
5.8.3 - DATE
Alias for TO_DATE.
5.8.4 - DATE DIFF
PlaidCloud Lakehouse does not provide a date_diff function yet, but it supports direct arithmetic operations on dates and times. For example, you can use the expression TO_DATE(NOW())-2 to obtain the date from two days ago.
This flexibility of directly manipulating dates and times in PlaidCloud Lakehouse makes it convenient and versatile for handling date and time computations. See an example below:
CREATE TABLE tasks (
task_name VARCHAR(50),
start_date DATE,
end_date DATE
);
INSERT INTO tasks (task_name, start_date, end_date)
VALUES
('Task 1', '2023-06-15', '2023-06-20'),
('Task 2', '2023-06-18', '2023-06-25'),
('Task 3', '2023-06-20', '2023-06-23');
SELECT task_name, end_date - start_date AS duration
FROM tasks;
task_name|duration|
---------+--------+
Task 1 | 5|
Task 2 | 7|
Task 3 | 3|
5.8.5 - DATE_ADD
Add the time interval or date interval to the provided date or date with time (timestamp/datetime).
Analyze Syntax
func.date_add(<unit>, <value>, <date_or_time_expr>)
Analyze Examples
func.date_add('YEAR', 1, func.to_date('2018-01-02'))
+------------------------------------------------------+
| func.date_add('YEAR', 1, func.to_date('2018-01-02')) |
+------------------------------------------------------+
| 2019-01-02 |
+------------------------------------------------------+
SQL Syntax
DATE_ADD(<unit>, <value>, <date_or_time_expr>)
Arguments
| Arguments | Description |
|---|---|
<unit> | Must be of the following values: YEAR, QUARTER, MONTH, DAY, HOUR, MINUTE and SECOND |
<value> | This is the number of units of time that you want to add. For example, if you want to add 2 days, this will be 2. |
<date_or_time_expr> | A value of DATE or TIMESTAMP type |
Return Type
The function returns a value of the same type as the <date_or_time_expr> argument.
SQL Examples
Query:
SELECT date_add(YEAR, 1, to_date('2018-01-02'));
+---------------------------------------------------+
| DATE_ADD(YEAR, INTERVAL 1, to_date('2018-01-02')) |
+---------------------------------------------------+
| 2019-01-02 |
+---------------------------------------------------+
5.8.6 - DATE_FORMAT
Alias for TO_STRING.
5.8.7 - DATE_PART
Retrieves the designated portion of a date, time, or timestamp.
See also: EXTRACT
Analyze Syntax
func.date_part(<unit>, <date_or_time_expr>)
Analyze Examples
func.now() |
---------------------+
2023-10-16 02:09:28.0|
func.date_part('day', now())
func.date_part('day', now())|
----------------------------+
16 |
SQL Syntax
DATE_PART( YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND | DOW | DOY, <date_or_time_expr> )
- DOW: Day of Week.
- DOY: Day of Year.
Return Type
Integer.
SQL Examples
SELECT NOW();
now() |
---------------------+
2023-10-16 02:09:28.0|
SELECT DATE_PART(DAY, NOW());
date_part(day, now())|
---------------------+
16|
-- October 16, 2023, is a Monday
SELECT DATE_PART(DOW, NOW());
date_part(dow, now())|
---------------------+
1|
-- October 16, 2023, is the 289th day of the year
SELECT DATE_PART(DOY, NOW());
date_part(doy, now())|
---------------------+
289|
SELECT DATE_PART(MONTH, TO_DATE('2022-05-13'));
date_part(month, to_date('2022-05-13'))|
---------------------------------------+
5|
5.8.8 - DATE_SUB
Subtract the time interval or date interval from the provided date or date with time (timestamp/datetime).
Analyze Syntax
func.date_sub(<unit>, <value>, <date_or_time_expr>)
Analyze Examples
func.date_sub('YEAR', 1, func.to_date('2018-01-02'))
+------------------------------------------------------+
| func.date_sub('YEAR', 1, func.to_date('2018-01-02')) |
+------------------------------------------------------+
| 2017-01-02 |
+------------------------------------------------------+
SQL Syntax
DATE_SUB(<unit>, <value>, <date_or_time_expr>)
Arguments
| Arguments | Description |
|---|---|
<unit> | Must be of the following values: YEAR, QUARTER, MONTH, DAY, HOUR, MINUTE and SECOND |
<value> | This is the number of units of time that you want to add. For example, if you want to add 2 days, this will be 2. |
<date_or_time_expr> | A value of DATE or TIMESTAMP type |
Return Type
The function returns a value of the same type as the <date_or_time_expr> argument.
SQL Examples
Query:
SELECT date_sub(YEAR, 1, to_date('2018-01-02'));
+---------------------------------------------------+
| DATE_SUB(YEAR, INTERVAL 1, to_date('2018-01-02')) |
+---------------------------------------------------+
| 2017-01-02 |
+---------------------------------------------------+
5.8.9 - DATE_TRUNC
Truncates a date, time, or timestamp value to a specified precision. For example, if you truncate 2022-07-07 to MONTH, the result will be 2022-07-01; if you truncate 2022-07-07 01:01:01.123456 to SECOND, the result will be 2022-07-07 01:01:01.000000.
Analyze Syntax
func.date_sub(<precision>, <date_or_time_expr>)
Analyze Examples
func.date_trunc('month', func.to_date('2022-07-07'))
+------------------------------------------------------+
| func.date_trunc('month', func.to_date('2022-07-07')) |
+------------------------------------------------------+
| 2022-07-01 |
+------------------------------------------------------+
SQL Syntax
DATE_TRUNC(<precision>, <date_or_time_expr>)
Arguments
| Arguments | Description |
|---|---|
<precision> | Must be of the following values: YEAR, QUARTER, MONTH, DAY, HOUR, MINUTE and SECOND |
<date_or_time_expr> | A value of DATE or TIMESTAMP type |
Return Type
The function returns a value of the same type as the <date_or_time_expr> argument.
SQL Examples
select date_trunc(month, to_date('2022-07-07'));
+------------------------------------------+
| date_trunc(month, to_date('2022-07-07')) |
+------------------------------------------+
| 2022-07-01 |
+------------------------------------------+
5.8.10 - DAY
Alias for TO_DAY_OF_MONTH.
5.8.11 - EXTRACT
Retrieves the designated portion of a date, time, or timestamp.
See also: DATE_PART
SQL Syntax
EXTRACT( YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND | DOW | DOY FROM <date_or_time_expr> )
- DOW: Day of the Week.
- DOY: Day of Year.
Return Type
Integer.
SQL Examples
SELECT NOW();
now() |
---------------------+
2023-10-16 02:09:28.0|
SELECT EXTRACT(DAY FROM NOW());
extract(day from now())|
-----------------------+
16|
-- October 16, 2023, is a Monday
SELECT EXTRACT(DOW FROM NOW());
extract(dow from now())|
-----------------------+
1|
-- October 16, 2023, is the 289th day of the year
SELECT EXTRACT(DOY FROM NOW());
extract(doy from now())|
-----------------------+
289|
SELECT EXTRACT(MONTH FROM TO_DATE('2022-05-13'));
extract(month from to_date('2022-05-13'))|
-----------------------------------------+
5|
5.8.12 - LAST_DAY
Returns the last day of the specified interval (week, month, quarter, or year) based on the provided date or timestamp.
Analyze Syntax
func.last_day(<date_expression>, <interval>)
Analyze Examples
func.last_day(func.to_date('2024-11-13'), 'month')
+------------------------------------------------------+
| func.last_day(func.to_date('2024-11-13'), 'month') |
+------------------------------------------------------+
| 2024-11-30 |
+------------------------------------------------------+
SQL Syntax
LAST_DAY(<date_expression>, <interval>)
| Parameter | Description |
|---|---|
<date_expression> | A DATE or TIMESTAMP value to calculate the last day of the specified interval. |
<interval> | The interval type for which to find the last day. Accepted values are week, month, quarter, and year. |
Return Type
Date.
SQL Examples
Let's say you want to determine the billing date, which is always the last day of the month, based on an arbitrary date of a transaction (e.g., 2024-11-13):
SELECT LAST_DAY(to_date('2024-11-13'), month) AS billing_date;
┌──────────────┐
│ billing_date │
├──────────────┤
│ 2024-11-30 │
└──────────────┘
5.8.13 - MONTH
Alias for TO_MONTH.
5.8.14 - MONTHS_BETWEEN
Returns the number of months between date1 and date2.
Analyze Syntax
func.months_between(<date1>, <date2>)
Analyze Examples
func.months_between(func.to_date('2024-03-15'), func.to_date('2024-02-15'))
+-------------------------------------------------------------------------------+
| func.months_between(func.to_date('2024-03-15'), func.to_date('2024-02-15')) |
+-------------------------------------------------------------------------------+
| 1 |
+-------------------------------------------------------------------------------+
func.months_between(func.to_date('2024-02-15'), func.to_date('2024-03-15'))
+-------------------------------------------------------------------------------+
| func.months_between(func.to_date('2024-02-15'), func.to_date('2024-03-15')) |
+-------------------------------------------------------------------------------+
| -1 |
+-------------------------------------------------------------------------------+
SQL Syntax
MONTHS_BETWEEN( <date1>, <date2> )
Arguments
date1 and date2 can be of DATE type, TIMESTAMP type, or a mix of both.
Return Type
The function returns a FLOAT value based on the following rules:
If date1 is earlier than date2, the function returns a negative value; otherwise, it returns a positive value.
SELECT MONTHS_BETWEEN('2024-03-15'::DATE, '2024-02-15'::DATE), MONTHS_BETWEEN('2024-02-15'::DATE, '2024-03-15'::DATE); -[ RECORD 1 ]----------------------------------- months_between('2024-03-15'::date, '2024-02-15'::date): 1 months_between('2024-02-15'::date, '2024-03-15'::date): -1If date1 and date2 fall on the same day of their respective months or both are the last day of their respective months, the result is an integer. Otherwise, the function calculates the fractional portion of the result based on a 31-day month.
SELECT MONTHS_BETWEEN('2024-02-29'::DATE, '2024-01-29'::DATE), MONTHS_BETWEEN('2024-02-29'::DATE, '2024-01-31'::DATE); -[ RECORD 1 ]----------------------------------- months_between('2024-02-29'::date, '2024-01-29'::date): 1 months_between('2024-02-29'::date, '2024-01-31'::date): 1 SELECT MONTHS_BETWEEN('2024-08-05'::DATE, '2024-01-01'::DATE); -[ RECORD 1 ]----------------------------------- months_between('2024-08-05'::date, '2024-01-01'::date): 7.129032258064516If date1 and date2 are the same date, the function ignores any time components and returns 0.
SELECT MONTHS_BETWEEN('2024-08-05'::DATE, '2024-08-05'::DATE), MONTHS_BETWEEN('2024-08-05 02:00:00'::TIMESTAMP, '2024-08-05 01:00:00'::TIMESTAMP); -[ RECORD 1 ]----------------------------------- months_between('2024-08-05'::date, '2024-08-05'::date): 0 months_between('2024-08-05 02:00:00'::timestamp, '2024-08-05 01:00:00'::timestamp): 0
5.8.15 - NEXT_DAY
Returns the date of the upcoming specified day of the week after the given date or timestamp.
Analyze Syntax
func.next_day(date_expression>, <target_day>)
Analyze Examples
func.next_day(func.to_date('2024-11-13'), 'monday')
+------------------------------------------------------+
| func.next_day(func.to_date('2024-11-13'), 'monday') |
+------------------------------------------------------+
| 2024-11-18 |
+------------------------------------------------------+
SQL Syntax
NEXT_DAY(<date_expression>, <target_day>)
| Parameter | Description |
|---|---|
<date_expression> | A DATE or TIMESTAMP value to calculate the next occurrence of the specified day. |
<target_day> | The target day of the week to find the next occurrence of. Accepted values include monday, tuesday, wednesday, thursday, friday, saturday, and sunday. |
Return Type
Date.
SQL Examples
To find the next Monday after a specific date, such as 2024-11-13:
SELECT NEXT_DAY(to_date('2024-11-13'), monday) AS next_monday;
┌─────────────┐
│ next_monday │
├─────────────┤
│ 2024-11-18 │
└─────────────┘
5.8.16 - NOW
Returns the current date and time.
Analyze Syntax
func.now()
Analyze Examples
┌─────────────────────────────────────────────────────────┐
│ func.current_timestamp() │ func.now() │
├────────────────────────────┼────────────────────────────┤
│ 2024-01-29 04:38:12.584359 │ 2024-01-29 04:38:12.584417 │
└─────────────────────────────────────────────────────────┘
SQL Syntax
NOW()
Return Type
TIMESTAMP
Aliases
SQL Examples
This example returns the current date and time:
SELECT CURRENT_TIMESTAMP(), NOW();
┌─────────────────────────────────────────────────────────┐
│ current_timestamp() │ now() │
├────────────────────────────┼────────────────────────────┤
│ 2024-01-29 04:38:12.584359 │ 2024-01-29 04:38:12.584417 │
└─────────────────────────────────────────────────────────┘
5.8.17 - PREVIOUS_DAY
Returns the date of the most recent specified day of the week before the given date or timestamp.
Analyze Syntax
func.next_day(date_expression>, <target_day>)
Analyze Examples
func.next_day(func.to_date('2024-11-13'), 'friday')
+------------------------------------------------------+
| func.next_day(func.to_date('2024-11-13'), 'friday') |
+------------------------------------------------------+
| 2024-11-08 |
+------------------------------------------------------+
SQL Syntax
PREVIOUS_DAY(<date_expression>, <target_day>)
| Parameter | Description |
|---|---|
<date_expression> | A DATE or TIMESTAMP value to calculate the previous occurrence of the specified day. |
<target_day> | The target day of the week to find the previous occurrence of. Accepted values include monday, tuesday, wednesday, thursday, friday, saturday, and sunday. |
Return Type
Date.
SQL Examples
If you need to find the previous Friday before a given date, such as 2024-11-13:
SELECT PREVIOUS_DAY(to_date('2024-11-13'), friday) AS last_friday;
┌─────────────┐
│ last_friday │
├─────────────┤
│ 2024-11-08 │
└─────────────┘
5.8.18 - QUARTER
Alias for TO_QUARTER.
5.8.19 - STR_TO_DATE
Alias for TO_DATE.
5.8.20 - STR_TO_TIMESTAMP
Alias for TO_TIMESTAMP.
5.8.21 - SUBTRACT TIME INTERVAL
Subtract time interval from a date or timestamp, return the result of date or timestamp type.
Analyze Syntax
func.subtract_years(<exp0>, <expr1>)
func.subtract_quarters(<exp0>, <expr1>)
func.subtract_months(<exp0>, <expr1>)
func.subtract_days(<exp0>, <expr1>)
func.subtract_hours(<exp0>, <expr1>)
func.subtract_minutes(<exp0>, <expr1>)
func.subtract_seconds(<exp0>, <expr1>)
Analyze Examples
func.to_date(18875), func.subtract_years(func.to_date(18875), 2)
+---------------------------------+--------------------------------------------------------+
| func.to_date(18875) | func.subtract_years(func.to_date(18875), 2) |
+---------------------------------+--------------------------------------------------------+
| 2021-09-05 | 2019-09-05 |
+---------------------------------+--------------------------------------------------------+
func.to_date(18875), func.subtract_quarters(func.to_date(18875), 2)
+---------------------------------+--------------------------------------------------------+
| func.to_date(18875) | subtract_quarters(func.to_date(18875), 2) |
+---------------------------------+--------------------------------------------------------+
| 2021-09-05 | 2021-03-05 |
+---------------------------------+--------------------------------------------------------+
func.to_date(18875), func.subtract_months(func.to_date(18875), 2)
+---------------------------------+--------------------------------------------------------+
| func.to_date(18875) | func.subtract_months(func.to_date(18875), 2) |
+---------------------------------+--------------------------------------------------------+
| 2021-09-05 | 2021-07-05 |
+---------------------------------+--------------------------------------------------------+
func.to_date(18875), func.subtract_days(func.to_date(18875), 2)
+---------------------------------+--------------------------------------------------------+
| func.to_date(18875) | func.subtract_days(func.to_date(18875), 2) |
+---------------------------------+--------------------------------------------------------+
| 2021-09-05 | 2021-09-03 |
+---------------------------------+--------------------------------------------------------+
func.to_datetime(1630833797), func.subtract_hours(func.to_datetime(1630833797), 2)
+---------------------------------+--------------------------------------------------------+
| func.to_datetime(1630833797) | func.subtract_hours(func.to_datetime(1630833797), 2) |
+---------------------------------+--------------------------------------------------------+
| 2021-09-05 09:23:17.000000 | 2021-09-05 07:23:17.000000 |
+---------------------------------+--------------------------------------------------------+
func.to_datetime(1630833797), func.subtract_minutes(func.to_datetime(1630833797), 2)
+---------------------------------+--------------------------------------------------------+
| func.to_datetime(1630833797) | func.subtract_minutes(func.to_datetime(1630833797), 2) |
+---------------------------------+--------------------------------------------------------+
| 2021-09-05 09:23:17.000000 | 2021-09-05 09:21:17.000000 |
+---------------------------------+--------------------------------------------------------+
func.to_datetime(1630833797), func.subtract_seconds(func.to_datetime(1630833797), 2)
+---------------------------------+--------------------------------------------------------+
| func.to_datetime(1630833797) | func.subtract_seconds(func.to_datetime(1630833797), 2) |
+---------------------------------+--------------------------------------------------------+
| 2021-09-05 09:23:17.000000 | 2021-09-05 09:23:15.000000 |
+---------------------------------+--------------------------------------------------------+
SQL Syntax
SUBTRACT_YEARS(<exp0>, <expr1>)
SUBTRACT_QUARTERS(<exp0>, <expr1>)
SUBTRACT_MONTHS(<exp0>, <expr1>)
SUBTRACT_DAYS(<exp0>, <expr1>)
SUBTRACT_HOURS(<exp0>, <expr1>)
SUBTRACT_MINUTES(<exp0>, <expr1>)
SUBTRACT_SECONDS(<exp0>, <expr1>)
Return Type
DATE, TIMESTAMP depends on the input.
SQL Examples
SELECT to_date(18875), subtract_years(to_date(18875), 2);
+----------------+-----------------------------------+
| to_date(18875) | subtract_years(to_date(18875), 2) |
+----------------+-----------------------------------+
| 2021-09-05 | 2019-09-05 |
+----------------+-----------------------------------+
SELECT to_date(18875), subtract_quarters(to_date(18875), 2);
+----------------+--------------------------------------+
| to_date(18875) | subtract_quarters(to_date(18875), 2) |
+----------------+--------------------------------------+
| 2021-09-05 | 2021-03-05 |
+----------------+--------------------------------------+
SELECT to_date(18875), subtract_months(to_date(18875), 2);
+----------------+------------------------------------+
| to_date(18875) | subtract_months(to_date(18875), 2) |
+----------------+------------------------------------+
| 2021-09-05 | 2021-07-05 |
+----------------+------------------------------------+
SELECT to_date(18875), subtract_days(to_date(18875), 2);
+----------------+----------------------------------+
| to_date(18875) | subtract_days(to_date(18875), 2) |
+----------------+----------------------------------+
| 2021-09-05 | 2021-09-03 |
+----------------+----------------------------------+
SELECT to_datetime(1630833797), subtract_hours(to_datetime(1630833797), 2);
+----------------------------+--------------------------------------------+
| to_datetime(1630833797) | subtract_hours(to_datetime(1630833797), 2) |
+----------------------------+--------------------------------------------+
| 2021-09-05 09:23:17.000000 | 2021-09-05 07:23:17.000000 |
+----------------------------+--------------------------------------------+
SELECT to_datetime(1630833797), subtract_minutes(to_datetime(1630833797), 2);
+----------------------------+----------------------------------------------+
| to_datetime(1630833797) | subtract_minutes(to_datetime(1630833797), 2) |
+----------------------------+----------------------------------------------+
| 2021-09-05 09:23:17.000000 | 2021-09-05 09:21:17.000000 |
+----------------------------+----------------------------------------------+
SELECT to_datetime(1630833797), subtract_seconds(to_datetime(1630833797), 2);
+----------------------------+----------------------------------------------+
| to_datetime(1630833797) | subtract_seconds(to_datetime(1630833797), 2) |
+----------------------------+----------------------------------------------+
| 2021-09-05 09:23:17.000000 | 2021-09-05 09:23:15.000000 |
+----------------------------+----------------------------------------------+
5.8.22 - TIME_SLOT
Rounds the time to the half-hour.
Analyze Syntax
func.time_slot(<expr>)
Analyze Examples
func.time_slot('2023-11-12 09:38:18.165575')
┌───────────────────────────────-───-───-──────┐
│ func.time_slot('2023-11-12 09:38:18.165575') │
│ Timestamp │
├─────────────────────────────────-───-────────┤
│ 2023-11-12 09:30:00 │
└─────────────────────────────────-───-────────┘
SQL Syntax
time_slot(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | timestamp |
Return Type
TIMESTAMP, returns in “YYYY-MM-DD hh:mm:ss.ffffff” format.
SQL Examples
SELECT
time_slot('2023-11-12 09:38:18.165575')
┌─────────────────────────────────────────┐
│ time_slot('2023-11-12 09:38:18.165575') │
│ Timestamp │
├─────────────────────────────────────────┤
│ 2023-11-12 09:30:00 │
└─────────────────────────────────────────┘
5.8.23 - TIMESTAMP_DIFF
Calculates the difference between two timestamps and returns the result as an INTERVAL.
Analyze Syntax
func.timestamp_diff(<timestamp1>, <timestamp2>)
Analyze Examples
func.timestamp_diff(func.to_timestamp('2025-02-01'), func.to_timestamp('2025-01-01'))
+----------------------------------------------------------------------------------------+
| func.timestamp_diff(func.to_timestamp('2025-02-01'), func.to_timestamp('2025-01-01')) |
+----------------------------------------------------------------------------------------+
| 744:00:00 |
+----------------------------------------------------------------------------------------+
SQL Syntax
TIMESTAMP_DIFF(<timestamp1>, <timestamp2>)
Return Type
INTERVAL (formatted as hours:minutes:seconds).
SQL Examples
This example shows that the time difference between February 1, 2025, and January 1, 2025, is 744 hours, corresponding to 31 days:
SELECT TIMESTAMP_DIFF('2025-02-01'::TIMESTAMP, '2025-01-01'::TIMESTAMP);
┌──────────────────────────────────────────────────────────────────┐
│ timestamp_diff('2025-02-01'::TIMESTAMP, '2025-01-01'::TIMESTAMP) │
├──────────────────────────────────────────────────────────────────┤
│ 744:00:00 │
└──────────────────────────────────────────────────────────────────┘
5.8.24 - TIMEZONE
Returns the timezone for the current connection.
PlaidCloud Lakehouse uses UTC (Coordinated Universal Time) as the default timezone and allows you to change the timezone to your current geographic location. For the available values you can assign to the timezone setting, refer to https://docs.rs/chrono-tz/latest/chrono_tz/enum.Tz.html. See the examples below for details.
Analyze Syntax
func.timezone()
Analyze Examples
func.timezone()
┌─────────────────────┐
│ timezone │
├─────────────────────┤
│ UTC │
└─────────────────────┘
SQL Syntax
SELECT TIMEZONE();
SQL Examples
-- Return the current timezone
SELECT TIMEZONE();
+-----------------+
| TIMEZONE('UTC') |
+-----------------+
| UTC |
+-----------------+
-- Set the timezone to China Standard Time
SET timezone='Asia/Shanghai';
SELECT TIMEZONE();
+---------------------------+
| TIMEZONE('Asia/Shanghai') |
+---------------------------+
| Asia/Shanghai |
+---------------------------+
5.8.25 - TO_DATE
Converts an expression to a date, including:
Converting a timestamp-format string to a date: Extracts a date from the given string.
Converting an integer to a date: Interprets the integer as the number of days before (for negative numbers) or after (for positive numbers) the Unix epoch (midnight on January 1, 1970). Please note that a Date value ranges from
1000-01-01to9999-12-31. PlaidCloud Lakehouse would return an error if you run "SELECT TO_DATE(9999999999999999999)".Converting a string to a date using the specified format: The function takes two arguments, converting the first string to a date based on the format specified in the second string. To customize the date and time format in PlaidCloud Lakehouse, specifiers can be used. For a comprehensive list of supported specifiers, see Formatting Date and Time.
Date formats are expressed using the strftime specification. A quick reference is here.
See also: TO_TIMESTAMP
strftime Parameters
Quick Reference
Date
| Example | Output |
|---|---|
%m/%d/%Y | 06/05/2013 |
%A, %B %e, %Y | Sunday, June 5, 2013 |
%b %e %a | Jun 5 Sun |
Time
| Example | Output |
|---|---|
%H:%M | 23:05 |
%I:%M %p | 11:05 PM |
Date
| Symbol | Example | Area |
|---|---|---|
%a | Sun | Weekday |
%A | Sunday | |
%w | 0..6 (Sunday is 0) | |
| --- | --- | --- |
%y | 13 | Year |
%Y | 2013 | |
| --- | --- | --- |
%b | Jan | Month |
%B | January | |
%m | 01..12 | |
| --- | --- | --- |
%d | 01..31 | Day |
%e | 1..31 |
Time
| Symbol | Example | Area |
|---|---|---|
%l | 1 | Hour |
%H | 00..23 | 24h Hour |
%I | 01..12 | 12h Hour |
| -- | --- | --- |
%M | 00..59 | Minute |
%S | 00..60 | Second |
| --- | --- | --- |
%p | AM | AM or PM |
%Z | +08 | Time zone |
| --- | --- | --- |
%j | 001..366 | Day of the year |
%% | % | Literal % character |
Analyze Syntax
func.to_date('<timestamp_expr>')
func.to_date(<integer>)
func.to_date('<string>', '<format>')
Analyze Examples
func.typeof(func.to_date('2022-01-02')), func.typeof(func.str_to_date('2022-01-02'))
┌───────────────────────────────────────────────────────────────────────────────────────┐
│ func.typeof(func.to_date('2022-01-02')) │ func.typeof(func.str_to_date('2022-01-02')) │
├─────────────────────────────────────────┼─────────────────────────────────────────────┤
│ DATE │ DATE │
└───────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
-- Convert a timestamp-format string
TO_DATE('<timestamp_expr>')
-- Convert an integer
TO_DATE(<integer>)
-- Convert a string using the given format
TO_DATE('<string>', '<format>')
Aliases
Return Type
The function returns a date in the format "YYYY-MM-DD":
SELECT TYPEOF(TO_DATE('2022-01-02')), TYPEOF(STR_TO_DATE('2022-01-02'));
┌───────────────────────────────────────────────────────────────────┐
│ typeof(to_date('2022-01-02')) │ typeof(str_to_date('2022-01-02')) │
├───────────────────────────────┼───────────────────────────────────┤
│ DATE │ DATE │
└───────────────────────────────────────────────────────────────────┘
To convert the returned date back to a string, use the DATE_FORMAT function:
SELECT DATE_FORMAT(TO_DATE('2022-01-02')) AS dt, TYPEOF(dt);
┌─────────────────────────┐
│ dt │ typeof(dt) │
├────────────┼────────────┤
│ 2022-01-02 │ VARCHAR │
└─────────────────────────┘
SQL Examples
SQL Examples 1: Converting a Timestamp-Format String
SELECT TO_DATE('2022-01-02T01:12:00+07:00'), STR_TO_DATE('2022-01-02T01:12:00+07:00');
┌─────────────────────────────────────────────────────────────────────────────────┐
│ to_date('2022-01-02t01:12:00+07:00') │ str_to_date('2022-01-02t01:12:00+07:00') │
├──────────────────────────────────────┼──────────────────────────────────────────┤
│ 2022-01-01 │ 2022-01-01 │
└─────────────────────────────────────────────────────────────────────────────────┘
SELECT TO_DATE('2022-01-02'), STR_TO_DATE('2022-01-02');
┌───────────────────────────────────────────────────┐
│ to_date('2022-01-02') │ str_to_date('2022-01-02') │
├───────────────────────┼───────────────────────────┤
│ 2022-01-02 │ 2022-01-02 │
└───────────────────────────────────────────────────┘
SQL Examples 2: Converting an Integer
SELECT TO_DATE(1), STR_TO_DATE(1), TO_DATE(-1), STR_TO_DATE(-1);
┌───────────────────────────────────────────────────────────────────┐
│ to_date(1) │ str_to_date(1) │ to_date((- 1)) │ str_to_date((- 1)) │
│ Date │ Date │ Date │ Date │
├────────────┼────────────────┼────────────────┼────────────────────┤
│ 1970-01-02 │ 1970-01-02 │ 1969-12-31 │ 1969-12-31 │
└───────────────────────────────────────────────────────────────────┘
SQL Examples 3: Converting a String using the Given Format
SELECT TO_DATE('12/25/2022','%m/%d/%Y'), STR_TO_DATE('12/25/2022','%m/%d/%Y');
┌───────────────────────────────────────────────────────────────────────────┐
│ to_date('12/25/2022', '%m/%d/%y') │ str_to_date('12/25/2022', '%m/%d/%y') │
├───────────────────────────────────┼───────────────────────────────────────┤
│ 2022-12-25 │ 2022-12-25 │
└───────────────────────────────────────────────────────────────────────────┘
5.8.26 - TO_DATETIME
Alias for TO_TIMESTAMP.
5.8.27 - TO_DAY_OF_MONTH
Convert a date or date with time (timestamp/datetime) to a UInt8 number containing the number of the day of the month (1-31).
Analyze Syntax
func.to_day_of_month(<expr>)
Analyze Examples
func.now(), func.to_day_of_month(func.now()), func.day(func.now())
┌──────────────────────────────────────────────────────────────────────────────────────┐
│ func.now() │ func.to_day_of_month(func.now()) │ func.day(func.now()) │
├────────────────────────────┼──────────────────────────────────┼──────────────────────┤
│ 2024-03-14 23:35:41.947962 │ 14 │ 14 │
└──────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_DAY_OF_MONTH(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
Aliases
Return Type
TINYINT
SQL Examples
SELECT NOW(), TO_DAY_OF_MONTH(NOW()), DAY(NOW());
┌──────────────────────────────────────────────────────────────────┐
│ now() │ to_day_of_month(now()) │ day(now()) │
├────────────────────────────┼────────────────────────┼────────────┤
│ 2024-03-14 23:35:41.947962 │ 14 │ 14 │
└──────────────────────────────────────────────────────────────────┘
5.8.28 - TO_DAY_OF_WEEK
Converts a date or date with time (timestamp/datetime) to a UInt8 number containing the number of the day of the week (Monday is 1, and Sunday is 7).
Analyze Syntax
func.to_day_of_week(<expr>)
Analyze Examples
func.to_day_of_week('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────┐
│ func.to_day_of_week('2023-11-12 09:38:18.165575') │
│ UInt8 │
├────────────────────────────────────────────────────┤
│ 7 │
└────────────────────────────────────────────────────┘
SQL Syntax
TO_DAY_OF_WEEK(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
Return Type
``TINYINT`
SQL Examples
SELECT
to_day_of_week('2023-11-12 09:38:18.165575')
┌──────────────────────────────────────────────┐
│ to_day_of_week('2023-11-12 09:38:18.165575') │
│ UInt8 │
├──────────────────────────────────────────────┤
│ 7 │
└──────────────────────────────────────────────┘
5.8.29 - TO_DAY_OF_YEAR
Convert a date or date with time (timestamp/datetime) to a UInt16 number containing the number of the day of the year (1-366).
Analyze Syntax
func.to_day_of_year(<expr>)
Analyze Examples
func.to_day_of_week('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────┐
│ func.to_day_of_year('2023-11-12 09:38:18.165575') │
│ UInt8 │
├────────────────────────────────────────────────────┤
│ 316 │
└────────────────────────────────────────────────────┘
SQL Syntax
TO_DAY_OF_YEAR(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
Return Type
SMALLINT
SQL Examples
SELECT
to_day_of_year('2023-11-12 09:38:18.165575')
┌──────────────────────────────────────────────┐
│ to_day_of_year('2023-11-12 09:38:18.165575') │
│ UInt16 │
├──────────────────────────────────────────────┤
│ 316 │
└──────────────────────────────────────────────┘
5.8.30 - TO_HOUR
Converts a date with time (timestamp/datetime) to a UInt8 number containing the number of the hour in 24-hour time (0-23). This function assumes that if clocks are moved ahead, it is by one hour and occurs at 2 a.m., and if clocks are moved back, it is by one hour and occurs at 3 a.m. (which is not always true – even in Moscow the clocks were twice changed at a different time).
Analyze Syntax
func.to_hour(<expr>)
Analyze Examples
func.to_hour('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────┐
│ func.to_hour('2023-11-12 09:38:18.165575') │
│ UInt8 │
├────────────────────────────────────────────────────┤
│ 9 │
└────────────────────────────────────────────────────┘
SQL Syntax
TO_HOUR(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | timestamp |
Return Type
TINYINT
SQL Examples
SELECT
to_hour('2023-11-12 09:38:18.165575')
┌───────────────────────────────────────┐
│ to_hour('2023-11-12 09:38:18.165575') │
│ UInt8 │
├───────────────────────────────────────┤
│ 9 │
└───────────────────────────────────────┘
5.8.31 - TO_MINUTE
Converts a date with time (timestamp/datetime) to a UInt8 number containing the number of the minute of the hour (0-59).
Analyze Syntax
func.to_minute(<expr>)
Analyze Examples
func.to_minute('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────┐
│ func.to_minute('2023-11-12 09:38:18.165575') │
│ UInt8 │
├────────────────────────────────────────────────────┤
│ 38 │
└────────────────────────────────────────────────────┘
SQL Syntax
TO_MINUTE(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | timestamp |
Return Type
TINYINT
SQL Examples
SELECT
to_minute('2023-11-12 09:38:18.165575')
┌─────────────────────────────────────────┐
│ to_minute('2023-11-12 09:38:18.165575') │
│ UInt8 │
├─────────────────────────────────────────┤
│ 38 │
└─────────────────────────────────────────┘
5.8.32 - TO_MONDAY
Round down a date or date with time (timestamp/datetime) to the nearest Monday. Returns the date.
Analyze Syntax
func.to_monday(<expr>)
Analyze Examples
func.to_monday('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────┐
│ func.to_monday('2023-11-12 09:38:18.165575') │
│ Date │
├────────────────────────────────────────────────────┤
│ 2023-11-06 │
└────────────────────────────────────────────────────┘
SQL Syntax
TO_MONDAY(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
Return Type
DATE, returns date in “YYYY-MM-DD” format.
SQL Examples
SELECT
to_monday('2023-11-12 09:38:18.165575')
┌─────────────────────────────────────────┐
│ to_monday('2023-11-12 09:38:18.165575') │
│ Date │
├─────────────────────────────────────────┤
│ 2023-11-06 │
└─────────────────────────────────────────┘
5.8.33 - TO_MONTH
Convert a date or date with time (timestamp/datetime) to a UInt8 number containing the month number (1-12).
Analyze Syntax
func.to_month(<expr>)
Analyze Examples
func.now(), func.to_month(func.now()), func.month(func.now())
┌─────────────────────────────────────────────────────────────────────────────────┐
│ func.now() │ func.to_month(func.now()) │ func.month(func.now()) │
├────────────────────────────┼───────────────────────────┼────────────────────────┤
│ 2024-03-14 23:34:02.161291 │ 3 │ 3 │
└─────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_MONTH(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
Aliases
Return Type
TINYINT
SQL Examples
SELECT NOW(), TO_MONTH(NOW()), MONTH(NOW());
┌─────────────────────────────────────────────────────────────┐
│ now() │ to_month(now()) │ month(now()) │
├────────────────────────────┼─────────────────┼──────────────┤
│ 2024-03-14 23:34:02.161291 │ 3 │ 3 │
└─────────────────────────────────────────────────────────────┘
5.8.34 - TO_QUARTER
Retrieves the quarter (1, 2, 3, or 4) from a given date or timestamp.
Analyze Syntax
func.to_quarter(<expr>)
Analyze Examples
func.now(), func.to_quarter(func.now()), func.quarter(func.now())
┌─────────────────────────────────────────────────────────────────────────────────────┐
│ func.now() │ func.to_quarter(func.now()) │ func.quarter(func.now()) │
├────────────────────────────┼─────────────────────────────┼──────────────────────────┤
│ 2024-03-14 23:32:52.743133 │ 3 │ 3 │
└─────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_QUARTER( <date_or_time_expr> )
Aliases
Return Type
Integer.
SQL Examples
SELECT NOW(), TO_QUARTER(NOW()), QUARTER(NOW());
┌─────────────────────────────────────────────────────────────────┐
│ now() │ to_quarter(now()) │ quarter(now()) │
├────────────────────────────┼───────────────────┼────────────────┤
│ 2024-03-14 23:32:52.743133 │ 1 │ 1 │
└─────────────────────────────────────────────────────────────────┘
5.8.35 - TO_SECOND
Converts a date with time (timestamp/datetime) to a UInt8 number containing the number of the second in the minute (0-59).
Analyze Syntax
func.to_second(<expr>)
Analyze Examples
func.to_second('2023-11-12 09:38:18.165575')
┌──────────────────────────────────────────────┐
│ func.to_second('2023-11-12 09:38:18.165575') │
│ UInt8 │
├──────────────────────────────────────────────┤
│ 18 │
└──────────────────────────────────────────────┘
SQL Syntax
TO_SECOND(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | timestamp |
Return Type
TINYINT
SQL Examples
SELECT
to_second('2023-11-12 09:38:18.165575')
┌─────────────────────────────────────────┐
│ to_second('2023-11-12 09:38:18.165575') │
│ UInt8 │
├─────────────────────────────────────────┤
│ 18 │
└─────────────────────────────────────────┘
5.8.36 - TO_START_OF_DAY
Rounds down a date with time (timestamp/datetime) to the start of the day.
Analyze Syntax
func.to_start_of_day(<expr>)
Analyze Examples
func.to_start_of_day('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────┐
│ func.to_start_of_day('2023-11-12 09:38:18.165575') │
│ Timestamp │
├────────────────────────────────────────────────────┤
│ 2023-11-12 00:00:00 │
└────────────────────────────────────────────────────┘
SQL Syntax
TO_START_OF_DAY( <expr> )
Arguments
| Arguments | Description |
|---|---|
<expr> | timestamp |
Return Type
TIMESTAMP, returns date in “YYYY-MM-DD hh:mm:ss.ffffff” format.
SQL Examples
SELECT
to_start_of_day('2023-11-12 09:38:18.165575')
┌───────────────────────────────────────────────┐
│ to_start_of_day('2023-11-12 09:38:18.165575') │
│ Timestamp │
├───────────────────────────────────────────────┤
│ 2023-11-12 00:00:00 │
└───────────────────────────────────────────────┘
5.8.37 - TO_START_OF_FIFTEEN_MINUTES
Rounds down the date with time (timestamp/datetime) to the start of the fifteen-minute interval.
Analyze Syntax
func.to_start_of_fifteen_minutes(<expr>)
Analyze Examples
func.to_start_of_fifteen_minutes('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────────────────┐
│ func.to_start_of_fifteen_minutes('2023-11-12 09:38:18.165575') │
│ Timestamp │
├────────────────────────────────────────────────────────────────┤
│ 2023-11-12 09:30:00 │
└────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_START_OF_FIFTEEN_MINUTES(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | timestamp |
Return Type
TIMESTAMP, returns date in “YYYY-MM-DD hh:mm:ss.ffffff” format.
SQL Examples
SELECT
to_start_of_fifteen_minutes('2023-11-12 09:38:18.165575')
┌───────────────────────────────────────────────────────────┐
│ to_start_of_fifteen_minutes('2023-11-12 09:38:18.165575') │
│ Timestamp │
├───────────────────────────────────────────────────────────┤
│ 2023-11-12 09:30:00 │
└───────────────────────────────────────────────────────────┘
5.8.38 - TO_START_OF_FIVE_MINUTES
Rounds down a date with time (timestamp/datetime) to the start of the five-minute interval.
Analyze Syntax
func.to_start_of_five_minutes(<expr>)
Analyze Examples
func.to_start_of_five_minutes('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────────────────┐
│ func.to_start_of_five_minutes('2023-11-12 09:38:18.165575') │
│ Timestamp │
├────────────────────────────────────────────────────────────────┤
│ 2023-11-12 09:35:00 │
└────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_START_OF_FIVE_MINUTES(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | timestamp |
Return Type
TIMESTAMP, returns date in “YYYY-MM-DD hh:mm:ss.ffffff” format.
SQL Examples
SELECT
to_start_of_five_minutes('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────────┐
│ to_start_of_five_minutes('2023-11-12 09:38:18.165575') │
│ Timestamp │
├────────────────────────────────────────────────────────┤
│ 2023-11-12 09:35:00 │
└────────────────────────────────────────────────────────┘
5.8.39 - TO_START_OF_HOUR
Rounds down a date with time (timestamp/datetime) to the start of the hour.
Analyze Syntax
func.to_start_of_hour(<expr>)
Analyze Examples
func.to_start_of_hour('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────────────────┐
│ func.to_start_of_hour('2023-11-12 09:38:18.165575') │
│ Timestamp │
├────────────────────────────────────────────────────────────────┤
│ 2023-11-12 09:00:00 │
└────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_START_OF_HOUR(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | timestamp |
Return Type
TIMESTAMP, returns date in “YYYY-MM-DD hh:mm:ss.ffffff” format.
SQL Examples
SELECT
to_start_of_hour('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────┐
│ to_start_of_hour('2023-11-12 09:38:18.165575') │
│ Timestamp │
├────────────────────────────────────────────────┤
│ 2023-11-12 09:00:00 │
└────────────────────────────────────────────────┘
5.8.40 - TO_START_OF_ISO_YEAR
Returns the first day of the ISO year for a date or a date with time (timestamp/datetime).
Analyze Syntax
func.to_start_of_iso_year(<expr>)
Analyze Examples
func.to_start_of_iso_year('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────────────────┐
│ func.to_start_of_iso_year('2023-11-12 09:38:18.165575') │
│ Date │
├────────────────────────────────────────────────────────────────┤
│ 2023-01-02 │
└────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_START_OF_ISO_YEAR(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
Return Type
DATE, returns date in “YYYY-MM-DD” format.
SQL Examples
SELECT
to_start_of_iso_year('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────┐
│ to_start_of_iso_year('2023-11-12 09:38:18.165575') │
│ Date │
├────────────────────────────────────────────────────┤
│ 2023-01-02 │
└────────────────────────────────────────────────────┘
5.8.41 - TO_START_OF_MINUTE
Rounds down a date with time (timestamp/datetime) to the start of the minute.
Analyze Syntax
func.to_start_of_minute(<expr>)
Analyze Examples
func.to_start_of_minute('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────────────────┐
│ func.to_start_of_minute('2023-11-12 09:38:18.165575') │
│ Timestamp │
├────────────────────────────────────────────────────────────────┤
│ 2023-11-12 09:38:00 │
└────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_START_OF_MINUTE( <expr> )
Arguments
| Arguments | Description |
|---|---|
<expr> | timestamp |
Return Type
TIMESTAMP, returns date in “YYYY-MM-DD hh:mm:ss.ffffff” format.
SQL Examples
SELECT
to_start_of_minute('2023-11-12 09:38:18.165575')
┌──────────────────────────────────────────────────┐
│ to_start_of_minute('2023-11-12 09:38:18.165575') │
│ Timestamp │
├──────────────────────────────────────────────────┤
│ 2023-11-12 09:38:00 │
└──────────────────────────────────────────────────┘
5.8.42 - TO_START_OF_MONTH
Rounds down a date or date with time (timestamp/datetime) to the first day of the month. Returns the date.
Analyze Syntax
func.to_start_of_month(<expr>)
Analyze Examples
func.to_start_of_month('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────────────────┐
│ func.to_start_of_month('2023-11-12 09:38:18.165575') │
│ Date │
├────────────────────────────────────────────────────────────────┤
│ 2023-11-01 │
└────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_START_OF_MONTH(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
Return Type
DATE, returns date in “YYYY-MM-DD” format.
SQL Examples
SELECT
to_start_of_month('2023-11-12 09:38:18.165575')
┌─────────────────────────────────────────────────┐
│ to_start_of_month('2023-11-12 09:38:18.165575') │
│ Date │
├─────────────────────────────────────────────────┤
│ 2023-11-01 │
└─────────────────────────────────────────────────┘
5.8.43 - TO_START_OF_QUARTER
Rounds down a date or date with time (timestamp/datetime) to the first day of the quarter. The first day of the quarter is either 1 January, 1 April, 1 July, or 1 October. Returns the date.
Analyze Syntax
func.to_start_of_quarter(<expr>)
Analyze Examples
func.to_start_of_quarter('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────────────────┐
│ func.to_start_of_quarter('2023-11-12 09:38:18.165575') │
│ Date │
├────────────────────────────────────────────────────────────────┤
│ 2023-10-01 │
└────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_START_OF_QUARTER(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
Return Type
DATE, returns date in “YYYY-MM-DD” format.
SQL Examples
SELECT
to_start_of_quarter('2023-11-12 09:38:18.165575')
┌───────────────────────────────────────────────────┐
│ to_start_of_quarter('2023-11-12 09:38:18.165575') │
│ Date │
├───────────────────────────────────────────────────┤
│ 2023-10-01 │
└───────────────────────────────────────────────────┘
5.8.44 - TO_START_OF_SECOND
Rounds down a date with time (timestamp/datetime) to the start of the second.
Analyze Syntax
func.to_start_of_second(<expr>)
Analyze Examples
func.to_start_of_second('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────────────────┐
│ func.to_start_of_second('2023-11-12 09:38:18.165575') │
│ Timestamp │
├────────────────────────────────────────────────────────────────┤
│ 2023-11-12 09:38:18 │
└────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_START_OF_SECOND(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | timestamp |
Return Type
TIMESTAMP, returns date in “YYYY-MM-DD hh:mm:ss.ffffff” format.
SQL Examples
SELECT
to_start_of_second('2023-11-12 09:38:18.165575')
┌──────────────────────────────────────────────────┐
│ to_start_of_second('2023-11-12 09:38:18.165575') │
│ Timestamp │
├──────────────────────────────────────────────────┤
│ 2023-11-12 09:38:18 │
└──────────────────────────────────────────────────┘
5.8.45 - TO_START_OF_TEN_MINUTES
Rounds down a date with time (timestamp/datetime) to the start of the ten-minute interval.
Analyze Syntax
func.to_start_of_ten_minutes(<expr>)
Analyze Examples
func.to_start_of_ten_minutes('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────────────────┐
│ func.to_start_of_ten_minutes('2023-11-12 09:38:18.165575') │
│ Timestamp │
├────────────────────────────────────────────────────────────────┤
│ 2023-11-12 09:30:00 │
└────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_START_OF_TEN_MINUTES(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | timestamp |
Return Type
TIMESTAMP, returns date in “YYYY-MM-DD hh:mm:ss.ffffff” format.
SQL Examples
SELECT
to_start_of_ten_minutes('2023-11-12 09:38:18.165575')
┌───────────────────────────────────────────────────────┐
│ to_start_of_ten_minutes('2023-11-12 09:38:18.165575') │
│ Timestamp │
├───────────────────────────────────────────────────────┤
│ 2023-11-12 09:30:00 │
└───────────────────────────────────────────────────────┘
5.8.46 - TO_START_OF_WEEK
Returns the first day of the week for a date or a date with time (timestamp/datetime).
The first day of a week can be Sunday or Monday, which is specified by the argument mode.
Analyze Syntax
func.to_start_of_week(<expr>)
Analyze Examples
func.to_start_of_week('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────────────────┐
│ func.to_start_of_week('2023-11-12 09:38:18.165575') │
│ Date │
├────────────────────────────────────────────────────────────────┤
│ 2023-11-12 │
└────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_START_OF_WEEK(<expr> [, mode])
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
[mode] | Optional. If it is 0, the result is Sunday, otherwise, the result is Monday. The default value is 0 |
Return Type
DATE, returns date in “YYYY-MM-DD” format.
SQL Examples
SELECT
to_start_of_week('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────┐
│ to_start_of_week('2023-11-12 09:38:18.165575') │
│ Date │
├────────────────────────────────────────────────┤
│ 2023-11-12 │
└────────────────────────────────────────────────┘
5.8.47 - TO_START_OF_YEAR
Returns the first day of the year for a date or a date with time (timestamp/datetime).
Analyze Syntax
func.to_start_of_year(<expr>)
Analyze Examples
func.to_start_of_year('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────────────────┐
│ func.to_start_of_year('2023-11-12 09:38:18.165575') │
│ Date │
├────────────────────────────────────────────────────────────────┤
│ 2023-01-01 │
└────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_START_OF_YEAR(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
Return Type
DATE, returns date in “YYYY-MM-DD” format.
SQL Examples
SELECT
to_start_of_year('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────┐
│ to_start_of_year('2023-11-12 09:38:18.165575') │
│ Date │
├────────────────────────────────────────────────┤
│ 2023-01-01 │
└────────────────────────────────────────────────┘
5.8.48 - TO_TIMESTAMP
TO_TIMESTAMP converts an expression to a date with time (timestamp/datetime).
The function can accept one or two arguments. If given one argument, the function extracts a date from the string. If the argument is an integer, the function interprets the integer as the number of seconds, milliseconds, or microseconds before (for a negative number) or after (for a positive number) the Unix epoch (midnight on January 1, 1970):
- If the integer is less than 31,536,000,000, it is treated as seconds.
- If the integer is greater than or equal to 31,536,000,000 and less than 31,536,000,000,000, it is treated as milliseconds.
- If the integer is greater than or equal to 31,536,000,000,000, it is treated as microseconds.
If given two arguments, the function converts the first string to a timestamp based on the format specified in the second string. To customize the format of date and time in PlaidCloud Lakehouse, you can utilize specifiers. These specifiers allow you to define the desired format for date and time values. For a comprehensive list of supported specifiers, see Formatting Date and Time.
- The output timestamp reflects your PlaidCloud Lakehouse timezone.
- The timezone information must be included in the string you want to convert, otherwise NULL will be returned.
Date formats are expressed using the strftime specification. A quick reference is here.
See also: TO_DATE
Analyze Syntax
func.to_timestamp(<expr>)
Analyze Examples
func.to_timestamp('2022-01-02T03:25:02.868894-07:00')
┌────────────────────────────────────────────────────────────────┐
│ func.to_timestamp('2022-01-02T03:25:02.868894-07:00') │
│ Timestamp │
├────────────────────────────────────────────────────────────────┤
│ 2022-01-02 10:25:02.868894 │
└────────────────────────────────────────────────────────────────┘
SQL Syntax
-- Convert a string or integer to a timestamp
TO_TIMESTAMP(<expr>)
-- Convert a string to a timestamp using the given pattern
TO_TIMESTAMP(<expr, expr>)
Return Type
Returns a timestamp in the format "YYYY-MM-DD hh:mm:ss.ffffff". If the given string matches this format but does not have the time part, it is automatically extended to this pattern. The padding value is 0.
Aliases
SQL Examples
Given a String Argument
SELECT TO_TIMESTAMP('2022-01-02T03:25:02.868894-07:00');
---
2022-01-02 10:25:02.868894
SELECT TO_TIMESTAMP('2022-01-02 02:00:11');
---
2022-01-02 02:00:11.000000
SELECT TO_TIMESTAMP('2022-01-02T02:00:22');
---
2022-01-02 02:00:22.000000
SELECT TO_TIMESTAMP('2022-01-02T01:12:00-07:00');
---
2022-01-02 08:12:00.000000
SELECT TO_TIMESTAMP('2022-01-02T01');
---
2022-01-02 01:00:00.000000
Given an Integer Argument
SELECT TO_TIMESTAMP(1);
---
1970-01-01 00:00:01.000000
SELECT TO_TIMESTAMP(-1);
---
1969-12-31 23:59:59.000000
Please note that a Timestamp value ranges from 1000-01-01 00:00:00.000000 to 9999-12-31 23:59:59.999999. PlaidCloud Lakehouse would return an error if you run the following statement:
SELECT TO_TIMESTAMP(9999999999999999999);
Given Two Arguments
SET GLOBAL timezone ='Japan';
SELECT TO_TIMESTAMP('2022 年 2 月 4 日、8 時 58 分 59 秒、タイムゾーン:+0900', '%Y年%m月%d日、%H時%M分%S秒、タイムゾーン:%z');
---
2022-02-04 08:58:59.000000
SET GLOBAL timezone ='America/Toronto';
SELECT TO_TIMESTAMP('2022 年 2 月 4 日、8 時 58 分 59 秒、タイムゾーン:+0900', '%Y年%m月%d日、%H時%M分%S秒、タイムゾーン:%z');
---
2022-02-03 18:58:59.000000
5.8.49 - TO_UNIX_TIMESTAMP
Converts a timestamp in a date/time format to a Unix timestamp format. A Unix timestamp represents the number of seconds that have elapsed since January 1, 1970, at 00:00:00 UTC.
Analyze Syntax
func.to_unix_timestamp(<expr>)
Analyze Examples
func.to_unix_timestamp('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────────────────────┐
│ func.to_unix_timestamp('2023-11-12 09:38:18.165575') │
│ UInt32 │
├────────────────────────────────────────────────────────────────┤
│ 1699781898 │
└────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_UNIX_TIMESTAMP(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | Timestamp |
For more information about the timestamp data type, see Date & Time.
Return Type
BIGINT
SQL Examples
SELECT
to_unix_timestamp('2023-11-12 09:38:18.165575')
┌─────────────────────────────────────────────────┐
│ to_unix_timestamp('2023-11-12 09:38:18.165575') │
│ UInt32 │
├─────────────────────────────────────────────────┤
│ 1699781898 │
└─────────────────────────────────────────────────┘
5.8.50 - TO_WEEK_OF_YEAR
Calculates the week number within a year for a given date.
ISO week numbering works as follows: January 4th is always considered part of the first week. If January 1st is a Thursday, then the week that spans from Monday, December 29th, to Sunday, January 4th, is designated as ISO week 1. If January 1st falls on a Friday, then the week that goes from Monday, January 4th, to Sunday, January 10th, is marked as ISO week 1.
Analyze Syntax
func.to_week_of_year(<expr>)
Analyze Examples
func.now(), func.to_week_of_year(func.now()), func.week(func.now()), func.weekofyear(func.now())
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.now() │ func.to_week_of_year(func.now()) │ func.week(func.now()) │ func.weekofyear(func.now()) │
├────────────────────────────┼──────────────────────────────────┼───────────────────────┼─────────────────────────────┤
│ 2024-03-14 23:30:04.011624 │ 11 │ 11 │ 11 │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_WEEK_OF_YEAR(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
Aliases
Return Type
Returns an integer that represents the week number within a year, with numbering ranging from 1 to 53.
SQL Examples
SELECT NOW(), TO_WEEK_OF_YEAR(NOW()), WEEK(NOW()), WEEKOFYEAR(NOW());
┌───────────────────────────────────────────────────────────────────────────────────────┐
│ now() │ to_week_of_year(now()) │ week(now()) │ weekofyear(now()) │
├────────────────────────────┼────────────────────────┼─────────────┼───────────────────┤
│ 2024-03-14 23:30:04.011624 │ 11 │ 11 │ 11 │
└───────────────────────────────────────────────────────────────────────────────────────┘
5.8.51 - TO_YEAR
Converts a date or date with time (timestamp/datetime) to a UInt16 number containing the year number (AD).
Analyze Syntax
func.to_year(<expr>)
Analyze Examples
func.now(), func.to_year(func.now()), func.year(func.now())
┌───────────────────────────────────────────────────────────────────────────────┐
│ func.now() │ func.to_year(func.now()) │ func.year(func.now()) │
├────────────────────────────┼──────────────────────────┼───────────────────────┤
│ 2024-03-14 23:37:03.895166 │ 2024 │ 2024 │
└───────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
TO_YEAR(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
Aliases
Return Type
SMALLINT
SQL Examples
SELECT NOW(), TO_YEAR(NOW()), YEAR(NOW());
┌───────────────────────────────────────────────────────────┐
│ now() │ to_year(now()) │ year(now()) │
├────────────────────────────┼────────────────┼─────────────┤
│ 2024-03-14 23:37:03.895166 │ 2024 │ 2024 │
└───────────────────────────────────────────────────────────┘
5.8.52 - TO_YYYYMM
Converts a date or date with time (timestamp/datetime) to a UInt32 number containing the year and month number.
Analyze Syntax
func.to_yyyymm(<expr>)
Analyze Examples
func.to_yyyymm('2023-11-12 09:38:18.165575')
┌──────────────────────────────────────────────┐
│ func.to_yyyymm('2023-11-12 09:38:18.165575') │
│ UInt32 │
├──────────────────────────────────────────────┤
│ 202311 │
└──────────────────────────────────────────────┘
SQL Syntax
TO_YYYYMM(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
Return Type
INT, returns in YYYYMM format.
SQL Examples
SELECT
to_yyyymm('2023-11-12 09:38:18.165575')
┌─────────────────────────────────────────┐
│ to_yyyymm('2023-11-12 09:38:18.165575') │
│ UInt32 │
├─────────────────────────────────────────┤
│ 202311 │
└─────────────────────────────────────────┘
5.8.53 - TO_YYYYMMDD
Converts a date or date with time (timestamp/datetime) to a UInt32 number containing the year and month number (YYYY * 10000 + MM * 100 + DD).
Analyze Syntax
func.to_yyyymmdd(<expr>)
Analyze Examples
func.to_yyyymmdd('2023-11-12 09:38:18.165575')
┌────────────────────────────────────────────────┐
│ func.to_yyyymmdd('2023-11-12 09:38:18.165575') │
│ UInt32 │
├────────────────────────────────────────────────┤
│ 20231112 │
└────────────────────────────────────────────────┘
SQL Syntax
TO_YYYYMMDD(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/datetime |
Return Type
INT, returns in YYYYMMDD format.
SQL Examples
SELECT
to_yyyymmdd('2023-11-12 09:38:18.165575')
┌───────────────────────────────────────────┐
│ to_yyyymmdd('2023-11-12 09:38:18.165575') │
│ UInt32 │
├───────────────────────────────────────────┤
│ 20231112 │
└───────────────────────────────────────────┘
5.8.54 - TO_YYYYMMDDHH
Formats a given date or timestamp into a string representation in the format "YYYYMMDDHH" (Year, Month, Day, Hour).
Analyze Syntax
func.to_yyyymmddhh(<expr>)
Analyze Examples
func.to_yyyymmddhh('2023-11-12 09:38:18.165575')
┌──────────────────────────────────────────────────┐
│ func.to_yyyymmddhh('2023-11-12 09:38:18.165575') │
│ UInt32 │
├──────────────────────────────────────────────────┤
│ 2023111209 │
└──────────────────────────────────────────────────┘
SQL Syntax
TO_YYYYMMDDHH(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/datetime |
Return Type
Returns an unsigned 64-bit integer (UInt64) in the format "YYYYMMDDHH".
SQL Examples
SELECT
to_yyyymmddhh('2023-11-12 09:38:18.165575')
┌─────────────────────────────────────────────┐
│ to_yyyymmddhh('2023-11-12 09:38:18.165575') │
│ UInt32 │
├─────────────────────────────────────────────┤
│ 2023111209 │
└─────────────────────────────────────────────┘
5.8.55 - TO_YYYYMMDDHHMMSS
Convert a date or date with time (timestamp/datetime) to a UInt64 number containing the year and month number (YYYY * 10000000000 + MM * 100000000 + DD * 1000000 + hh * 10000 + mm * 100 + ss).
Analyze Syntax
func.to_yyyymmddhhmmss(<expr>)
Analyze Examples
func.to_yyyymmddhhmmss('2023-11-12 09:38:18.165575')
┌──────────────────────────────────────────────────────┐
│ func.to_yyyymmddhhmmss('2023-11-12 09:38:18.165575') │
│ UInt64 │
├──────────────────────────────────────────────────────┤
│ 20231112092818 │
└──────────────────────────────────────────────────────┘
SQL Syntax
TO_YYYYMMDDHHMMSS(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | date/timestamp |
Return Type
BIGINT, returns in YYYYMMDDhhmmss format.
SQL Examples
SELECT
to_yyyymmddhhmmss('2023-11-12 09:38:18.165575')
┌─────────────────────────────────────────────────┐
│ to_yyyymmddhhmmss('2023-11-12 09:38:18.165575') │
│ UInt64 │
├─────────────────────────────────────────────────┤
│ 20231112092818 │
└─────────────────────────────────────────────────┘
5.8.56 - TODAY
Returns current date.
Analyze Syntax
func.today()
Analyze Examples
func.today()
+--------------+
| func.today() |
+--------------+
| 2021-09-03 |
+--------------+
SQL Syntax
TODAY()
Return Type
DATE, returns date in “YYYY-MM-DD” format.
SQL Examples
SELECT TODAY();
+------------+
| TODAY() |
+------------+
| 2021-09-03 |
+------------+
5.8.57 - TOMORROW
Returns tomorrow date, same as today() + 1.
Analyze Syntax
func.tomorrow()
Analyze Examples
func.tomorrow()
+-----------------+
| func.tomorrow() |
+-----------------+
| 2021-09-03 |
+-----------------+
SQL Syntax
TOMORROW()
Return Type
DATE, returns date in “YYYY-MM-DD” format.
SQL Examples
SELECT TOMORROW();
+------------+
| TOMORROW() |
+------------+
| 2021-09-04 |
+------------+
SELECT TODAY()+1;
+---------------+
| (TODAY() + 1) |
+---------------+
| 2021-09-04 |
+---------------+
5.8.58 - TRY_TO_DATETIME
Alias for TRY_TO_TIMESTAMP.
5.8.59 - TRY_TO_TIMESTAMP
A variant of TO_TIMESTAMP in PlaidCloud Lakehouse that, while performing the same conversion of an input expression to a timestamp, incorporates error-handling support by returning NULL if the conversion fails instead of raising an error.
See also: TO_TIMESTAMP
Analyze Syntax
func.try_to_timestamp(<expr>)
Analyze Examples
func.try_to_timestamp('2022-01-02 02:00:11'), func.try_to_datetime('2022-01-02 02:00:11'), func.try_to_timestamp('plaidcloud')
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.try_to_timestamp('2022-01-02 02:00:11') │ func.try_to_datetime('2022-01-02 02:00:11') │ func.try_to_timestamp('plaidcloud') │
│ Timestamp │ Timestamp │ │
├─────────────────────────────────────────┼──────────────────────────────────────────────────┤─────────────────────────────────────│
│ 2022-01-02 02:00:11 │ 2022-01-02 02:00:11 │ NULL │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
-- Convert a string or integer to a timestamp
TRY_TO_TIMESTAMP(<expr>)
-- Convert a string to a timestamp using the given pattern
TRY_TO_TIMESTAMP(<expr, expr>)
Aliases
SQL Examples
SELECT TRY_TO_TIMESTAMP('2022-01-02 02:00:11'), TRY_TO_DATETIME('2022-01-02 02:00:11');
┌──────────────────────────────────────────────────────────────────────────────────┐
│ try_to_timestamp('2022-01-02 02:00:11') │ try_to_datetime('2022-01-02 02:00:11') │
│ Timestamp │ Timestamp │
├─────────────────────────────────────────┼────────────────────────────────────────┤
│ 2022-01-02 02:00:11 │ 2022-01-02 02:00:11 │
└──────────────────────────────────────────────────────────────────────────────────┘
SELECT TRY_TO_TIMESTAMP('databend'), TRY_TO_DATETIME('databend');
┌────────────────────────────────────────────────────────────┐
│ try_to_timestamp('databend') │ try_to_datetime('databend') │
├──────────────────────────────┼─────────────────────────────┤
│ NULL │ NULL │
└────────────────────────────────────────────────────────────┘
5.8.60 - WEEK
Alias for TO_WEEK_OF_YEAR.
5.8.61 - WEEKOFYEAR
Alias for TO_WEEK_OF_YEAR.
5.8.62 - YEAR
Alias for TO_YEAR.
5.8.63 - YESTERDAY
Returns yesterday date, same as today() - 1.
Analyze Syntax
func.yesterday()
Analyze Examples
func.yesterday()
+------------------+
| func.yesterday() |
+------------------+
| 2021-09-02 |
+------------------+
SQL Syntax
YESTERDAY()
Return Type
DATE, returns date in “YYYY-MM-DD” format.
SQL Examples
SELECT YESTERDAY();
+-------------+
| YESTERDAY() |
+-------------+
| 2021-09-02 |
+-------------+
SELECT TODAY()-1;
+---------------+
| (TODAY() - 1) |
+---------------+
| 2021-09-02 |
+---------------+
5.9 - Dictionary Functions
This section provides reference information for dictionary functions in PlaidCloud Lakehouse.
5.9.1 - DICT_GET
Retrieves the value of a specified attribute from a dictionary using a provided key expression.
SQL Syntax
DICT_GET([db_name.]<dict_name>, '<attr_name>', <key_expr>)
| Parameter | Description |
|---|---|
| dict_name | The name of the dictionary. |
| attr_name | The name of the attribute in the dictionary that you want to retrieve the value for. |
| key_expr | The key expression used to locate a specific entry in the dictionary. It represents the value of the dictionary's primary key to retrieve the corresponding data. |
SQL Examples
5.10 - Geography Functions
This section provides reference information for the geography functions in PlaidCloud Lakehouse. These functions are based on the very innovate H3 system developed by Uber to better calculate geographic relationships. The explanation of H3 can be found here.
Coordinate Conversion
Hexagon Properties
- H3_CELL_AREA_M2
- H3_CELL_AREA_RADS2
- H3_HEX_AREA_KM2
- H3_HEX_AREA_M2
- H3_GET_BASE_CELL
- H3_GET_FACES
- H3_GET_RESOLUTION
- H3_TO_CENTER_CHILD
- H3_TO_CHILDREN
- H3_TO_GEO_BOUNDARY
- H3_TO_PARENT
- H3_NUM_HEXAGONS
Hexagon Relationships
- H3_HEX_RING
- H3_K_RING
- H3_INDEXES_ARE_NEIGHBORS
- H3_IS_PENTAGON
- H3_IS_RES_CLASS_III
- H3_IS_VALID
- H3_GET_DESTINATION_INDEX_FROM_UNIDIRECTIONAL_EDGE
- H3_GET_INDEXES_FROM_UNIDIRECTIONAL_EDGE
- H3_GET_ORIGIN_INDEX_FROM_UNIDIRECTIONAL_EDGE
- H3_GET_UNIDIRECTIONAL_EDGE_BOUNDARY
- H3_GET_UNIDIRECTIONAL_EDGE
- H3_GET_UNIDIRECTIONAL_EDGES_FROM_HEXAGON
- H3_UNIDIRECTIONAL_EDGE_IS_VALID
Measurement
- H3_DISTANCE
- H3_EDGE_ANGLE
- H3_EDGE_LENGTH_KM
- H3_EDGE_LENGTH_M
- H3_EXACT_EDGE_LENGTH_KM
- H3_EXACT_EDGE_LENGTH_M
- H3_EXACT_EDGE_LENGTH_RADS
General Utility
5.10.1 - GEO_TO_H3
Returns the H3 index of the hexagon cell where the given location resides. Returning 0 means an error occurred.
Analyze Syntax
func.geo_to_h3(lon, lat, res)
Analyze Examples
func.geo_to_h3(37.79506683, 55.71290588, 15)
┌──────────────────────────────────────────────┐
│ func.geo_to_h3(37.79506683, 55.71290588, 15) │
├──────────────────────────────────────────────┤
│ 644325524701193974 │
└──────────────────────────────────────────────┘
SQL Syntax
GEO_TO_H3(lon, lat, res)
SQL Examples
SELECT GEO_TO_H3(37.79506683, 55.71290588, 15);
┌─────────────────────────────────────────┐
│ geo_to_h3(37.79506683, 55.71290588, 15) │
├─────────────────────────────────────────┤
│ 644325524701193974 │
└─────────────────────────────────────────┘
5.10.2 - GEOHASH_DECODE
Converts a Geohash-encoded string into latitude/longitude coordinates.
Analyze Syntax
func.geohash_decode('<geohashed-string\>')
Analyze Examples
func.geohash_decode('ezs42')
┌─────────────────────────────────┐
│ func.geohash_decode('ezs42') │
├─────────────────────────────────┤
│ (-5.60302734375,42.60498046875) │
└─────────────────────────────────┘
SQL Syntax
GEOHASH_DECODE('<geohashed-string\>')
SQL Examples
SELECT GEOHASH_DECODE('ezs42');
┌─────────────────────────────────┐
│ geohash_decode('ezs42') │
├─────────────────────────────────┤
│ (-5.60302734375,42.60498046875) │
└─────────────────────────────────┘
5.10.3 - GEOHASH_ENCODE
Converts a pair of latitude and longitude coordinates into a Geohash-encoded string.
Analyze Syntax
func.geohash_encode(lon, lat)
Analyze Examples
func.geohash_encode(-5.60302734375, 42.593994140625)
┌─────────────────────────────────────────────────────────┐
│ func.geohash_encode((- 5.60302734375), 42.593994140625) │
├─────────────────────────────────────────────────────────┤
│ ezs42d000000 │
└─────────────────────────────────────────────────────────┘
SQL Syntax
GEOHASH_ENCODE(lon, lat)
SQL Examples
SELECT GEOHASH_ENCODE(-5.60302734375, 42.593994140625);
┌────────────────────────────────────────────────────┐
│ geohash_encode((- 5.60302734375), 42.593994140625) │
├────────────────────────────────────────────────────┤
│ ezs42d000000 │
└────────────────────────────────────────────────────┘
5.10.4 - H3_CELL_AREA_M2
Returns the exact area of specific cell in square meters.
Analyze Syntax
func.h3_cell_area_m2(h3)
Analyze Examples
func.h3_cell_area_m2(599119489002373119)
┌──────────────────────────────────────────┐
│ func.h3_cell_area_m2(599119489002373119) │
├──────────────────────────────────────────┤
│ 127785582.60809991 │
└──────────────────────────────────────────┘
SQL Syntax
H3_CELL_AREA_M2(h3)
SQL Examples
SELECT H3_CELL_AREA_M2(599119489002373119);
┌─────────────────────────────────────┐
│ h3_cell_area_m2(599119489002373119) │
├─────────────────────────────────────┤
│ 127785582.60809991 │
└─────────────────────────────────────┘
5.10.5 - H3_CELL_AREA_RADS2
Returns the exact area of specific cell in square radians.
Analyze Syntax
func.h3_cell_area_rads2(h3)
Analyze Examples
func.h3_cell_area_rads2(599119489002373119)
┌─────────────────────────────────────────────┐
│ func.h3_cell_area_rads2(599119489002373119) │
├─────────────────────────────────────────────┤
│ 0.000003148224310427697 │
└─────────────────────────────────────────────┘
SQL Syntax
H3_CELL_AREA_RADS2(h3)
SQL Examples
SELECT H3_CELL_AREA_RADS2(599119489002373119);
┌────────────────────────────────────────┐
│ h3_cell_area_rads2(599119489002373119) │
├────────────────────────────────────────┤
│ 0.000003148224310427697 │
└────────────────────────────────────────┘
5.10.6 - H3_DISTANCE
Returns the grid distance between the the given two H3 indexes.
Analyze Syntax
func.h3_distance(h3, a_h3)
Analyze Examples
func.h3_distance(599119489002373119, 599119491149856767)
┌──────────────────────────────────────────────────────────┐
│ func.h3_distance(599119489002373119, 599119491149856767) │
├──────────────────────────────────────────────────────────┤
│ 1 │
└──────────────────────────────────────────────────────────┘
SQL Syntax
H3_DISTANCE(h3, a_h3)
SQL Examples
SELECT H3_DISTANCE(599119489002373119, 599119491149856767);
┌─────────────────────────────────────────────────────┐
│ h3_distance(599119489002373119, 599119491149856767) │
├─────────────────────────────────────────────────────┤
│ 1 │
└─────────────────────────────────────────────────────┘
5.10.7 - H3_EDGE_ANGLE
Returns the average length of the H3 hexagon edge in grades.
Analyze Syntax
func.h3_edge_angle(res)
Analyze Examples
func.h3_edge_angle(10)
┌────────────────────────────┐
│ func.h3_edge_angle(10) │
├────────────────────────────┤
│ 0.0006822586214153981 │
└────────────────────────────┘
SQL Syntax
H3_EDGE_ANGLE(res)
SQL Examples
SELECT H3_EDGE_ANGLE(10);
┌───────────────────────┐
│ h3_edge_angle(10) │
├───────────────────────┤
│ 0.0006822586214153981 │
└───────────────────────┘
5.10.8 - H3_EDGE_LENGTH_KM
Returns the average hexagon edge length in kilometers at the given resolution. Excludes pentagons.
Analyze Syntax
func.h3_edge_length_km(res)
Analyze Examples
func.h3_edge_length_km(1)
┌───────────────────────────┐
│ func.h3_edge_length_km(1) │
├───────────────────────────┤
│ 483.0568390711111 │
└───────────────────────────┘
SQL Syntax
H3_EDGE_LENGTH_KM(res)
SQL Examples
SELECT H3_EDGE_LENGTH_KM(1);
┌──────────────────────┐
│ h3_edge_length_km(1) │
├──────────────────────┤
│ 483.0568390711111 │
└──────────────────────┘
5.10.9 - H3_EDGE_LENGTH_M
Returns the average hexagon edge length in meters at the given resolution. Excludes pentagons.
Analyze Syntax
func.h3_edge_length(1)
Analyze Examples
func.h3_edge_length(1)
┌──────────────────────────┐
│ func.h3_edge_length_m(1) │
├──────────────────────────┤
│ 483056.8390711111 │
└──────────────────────────┘
SQL Syntax
H3_EDGE_LENGTH_M(1)
SQL Examples
┌─────────────────────┐
│ h3_edge_length_m(1) │
├─────────────────────┤
│ 483056.8390711111 │
└─────────────────────┘
5.10.10 - H3_EXACT_EDGE_LENGTH_KM
Computes the length of this directed edge, in kilometers.
Analyze Syntax
func.h3_exact_edge_length_km(h3)
Analyze Examples
func.h3_exact_edge_length_km(1319695429381652479)
┌───────────────────────────────────────────────────┐
│ func.h3_exact_edge_length_km(1319695429381652479) │
├───────────────────────────────────────────────────┤
│ 8.267326832647143 │
└───────────────────────────────────────────────────┘
SQL Syntax
H3_EXACT_EDGE_LENGTH_KM(h3)
SQL Examples
SELECT H3_EXACT_EDGE_LENGTH_KM(1319695429381652479);
┌──────────────────────────────────────────────┐
│ h3_exact_edge_length_km(1319695429381652479) │
├──────────────────────────────────────────────┤
│ 8.267326832647143 │
└──────────────────────────────────────────────┘
5.10.11 - H3_EXACT_EDGE_LENGTH_M
Computes the length of this directed edge, in meters.
Analyze Syntax
func.h3_exact_edge_length_m(h3)
Analyze Examples
func.h3_exact_edge_length_m(1319695429381652479)
┌──────────────────────────────────────────────────┐
│ func.h3_exact_edge_length_m(1319695429381652479) │
├──────────────────────────────────────────────────┤
│ 8267.326832647143 │
└──────────────────────────────────────────────────┘
SQL Syntax
H3_EXACT_EDGE_LENGTH_M(h3)
SQL Examples
SELECT H3_EXACT_EDGE_LENGTH_M(1319695429381652479);
┌─────────────────────────────────────────────┐
│ h3_exact_edge_length_m(1319695429381652479) │
├─────────────────────────────────────────────┤
│ 8267.326832647143 │
└─────────────────────────────────────────────┘
5.10.12 - H3_EXACT_EDGE_LENGTH_RADS
Computes the length of this directed edge, in radians.
Analyze Syntax
func.h3_exact_edge_length_km(h3)
Analyze Examples
func.h3_exact_edge_length_km(1319695429381652479)
┌───────────────────────────────────────────────────┐
│ func.h3_exact_edge_length_km(1319695429381652479) │
├───────────────────────────────────────────────────┤
│ 8.267326832647143 │
└───────────────────────────────────────────────────┘
SQL Syntax
H3_EXACT_EDGE_LENGTH_RADS(h3)
SQL Examples
SELECT H3_EXACT_EDGE_LENGTH_KM(1319695429381652479);
┌──────────────────────────────────────────────┐
│ h3_exact_edge_length_km(1319695429381652479) │
├──────────────────────────────────────────────┤
│ 8.267326832647143 │
└──────────────────────────────────────────────┘
5.10.13 - H3_GET_BASE_CELL
Returns the base cell number of the given H3 index.
Analyze Syntax
func.h3_get_base_cell(h3)
Analyze Examples
func.h3_get_base_cell(644325524701193974)
┌───────────────────────────────────────────┐
│ func.h3_get_base_cell(644325524701193974) │
├───────────────────────────────────────────┤
│ 8 │
└───────────────────────────────────────────┘
SQL Syntax
H3_GET_BASE_CELL(h3)
SQL Examples
SELECT H3_GET_BASE_CELL(644325524701193974);
┌──────────────────────────────────────┐
│ h3_get_base_cell(644325524701193974) │
├──────────────────────────────────────┤
│ 8 │
└──────────────────────────────────────┘
5.10.14 - H3_GET_DESTINATION_INDEX_FROM_UNIDIRECTIONAL_EDGE
Returns the destination hexagon index from the unidirectional edge H3Index.
Analyze Syntax
func.h3_get_destination_index_from_unidirectional_edge(h3)
Analyze Examples
func.h3_get_destination_index_from_unidirectional_edge(1248204388774707199)
┌─────────────────────────────────────────────────────────────────────────────┐
│ func.h3_get_destination_index_from_unidirectional_edge(1248204388774707199) │
├─────────────────────────────────────────────────────────────────────────────┤
│ 599686043507097599 │
└─────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
H3_GET_DESTINATION_INDEX_FROM_UNIDIRECTIONAL_EDGE(h3)
SQL Examples
SELECT H3_GET_DESTINATION_INDEX_FROM_UNIDIRECTIONAL_EDGE(1248204388774707199);
┌────────────────────────────────────────────────────────────────────────┐
│ h3_get_destination_index_from_unidirectional_edge(1248204388774707199) │
├────────────────────────────────────────────────────────────────────────┤
│ 599686043507097599 │
└────────────────────────────────────────────────────────────────────────┘
5.10.15 - H3_GET_FACES
Finds all icosahedron faces intersected by the given H3 index. Faces are represented as integers from 0-19.
Analyze Syntax
func.h3_get_faces(h3)
Analyze Examples
func.h3_get_faces(599119489002373119)
┌───────────────────────────────────────┐
│ func.h3_get_faces(599119489002373119) │
├───────────────────────────────────────┤
│ [0,1,2,3,4] │
└───────────────────────────────────────┘
SQL Syntax
H3_GET_FACES(h3)
SQL Examples
SELECT H3_GET_FACES(599119489002373119);
┌──────────────────────────────────┐
│ h3_get_faces(599119489002373119) │
├──────────────────────────────────┤
│ [0,1,2,3,4] │
└──────────────────────────────────┘
5.10.16 - H3_GET_INDEXES_FROM_UNIDIRECTIONAL_EDGE
Returns the origin and destination hexagon indexes from the given unidirectional edge H3Index.
Analyze Syntax
func.h3_get_indexes_from_unidirectional_edge(h3)
Analyze Examples
func.h3_get_indexes_from_unidirectional_edge(1248204388774707199)
┌────────────────────────────────────────────────────────────────────┐
│ func.h3_get_indexes_from_unidirectional_edge(1248204388774707199) │
├────────────────────────────────────────────────────────────────────┤
│ (599686042433355775,599686043507097599) │
└────────────────────────────────────────────────────────────────────┘
SQL Syntax
H3_GET_INDEXES_FROM_UNIDIRECTIONAL_EDGE(h3)
SQL Examples
SELECT H3_GET_INDEXES_FROM_UNIDIRECTIONAL_EDGE(1248204388774707199);
┌──────────────────────────────────────────────────────────────┐
│ h3_get_indexes_from_unidirectional_edge(1248204388774707199) │
├──────────────────────────────────────────────────────────────┤
│ (599686042433355775,599686043507097599) │
└──────────────────────────────────────────────────────────────┘
5.10.17 - H3_GET_ORIGIN_INDEX_FROM_UNIDIRECTIONAL_EDGE
Returns the origin hexagon index from the unidirectional edge H3Index.
Analyze Syntax
func.h3_get_origin_index_from_unidirectional_edge(h3)
Analyze Examples
func.h3_get_origin_index_from_unidirectional_edge(1248204388774707199)
┌────────────────────────────────────────────────────────────────────────┐
│ func.h3_get_origin_index_from_unidirectional_edge(1248204388774707199) │
├────────────────────────────────────────────────────────────────────────┤
│ 599686042433355775 │
└────────────────────────────────────────────────────────────────────────┘
SQL Syntax
H3_GET_ORIGIN_INDEX_FROM_UNIDIRECTIONAL_EDGE(h3)
SQL Examples
SELECT H3_GET_ORIGIN_INDEX_FROM_UNIDIRECTIONAL_EDGE(1248204388774707199);
┌───────────────────────────────────────────────────────────────────┐
│ h3_get_origin_index_from_unidirectional_edge(1248204388774707199) │
├───────────────────────────────────────────────────────────────────┤
│ 599686042433355775 │
└───────────────────────────────────────────────────────────────────┘
5.10.18 - H3_GET_RESOLUTION
Returns the resolution of the given H3 index.
Analyze Syntax
func.h3_get_resolution(h3)
Analyze Examples
func.h3_get_resolution(644325524701193974)
┌────────────────────────────────────────────┐
│ func.h3_get_resolution(644325524701193974) │
├────────────────────────────────────────────┤
│ 15 │
└────────────────────────────────────────────┘
SQL Syntax
H3_GET_RESOLUTION(h3)
SQL Examples
SELECT H3_GET_RESOLUTION(644325524701193974);
┌───────────────────────────────────────┐
│ h3_get_resolution(644325524701193974) │
├───────────────────────────────────────┤
│ 15 │
└───────────────────────────────────────┘
5.10.19 - H3_GET_UNIDIRECTIONAL_EDGE
Returns the edge between the given two H3 indexes.
Analyze Syntax
func.h3_get_unidirectional_edge(h3, a_h3)
Analyze Examples
func.h3_get_unidirectional_edge(644325524701193897, 644325524701193754)
┌─────────────────────────────────────────────────────────────────────────┐
│ func.h3_get_unidirectional_edge(644325524701193897, 644325524701193754) │
├─────────────────────────────────────────────────────────────────────────┤
│ 1581074247194257065 │
└─────────────────────────────────────────────────────────────────────────┘
SQL Syntax
H3_GET_UNIDIRECTIONAL_EDGE(h3, a_h3)
SQL Examples
SELECT H3_GET_UNIDIRECTIONAL_EDGE(644325524701193897, 644325524701193754);
┌────────────────────────────────────────────────────────────────────┐
│ h3_get_unidirectional_edge(644325524701193897, 644325524701193754) │
├────────────────────────────────────────────────────────────────────┤
│ 1581074247194257065 │
└────────────────────────────────────────────────────────────────────┘
5.10.20 - H3_GET_UNIDIRECTIONAL_EDGE_BOUNDARY
Returns the coordinates defining the unidirectional edge.
Analyze Syntax
func.h3_get_unidirectional_edge_boundary(h3)
Analyze Examples
func.h3_get_unidirectional_edge_boundary(1248204388774707199)
┌─────────────────────────────────────────────────────────────────────────────────┐
│ func.h3_get_unidirectional_edge_boundary(1248204388774707199) │
├─────────────────────────────────────────────────────────────────────────────────┤
│ [(37.42012867767778,-122.03773496427027),(37.33755608435298,-122.090428929044)] │
└─────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
H3_GET_UNIDIRECTIONAL_EDGE_BOUNDARY(h3)
SQL Examples
SELECT H3_GET_UNIDIRECTIONAL_EDGE_BOUNDARY(1248204388774707199);
┌─────────────────────────────────────────────────────────────────────────────────┐
│ h3_get_unidirectional_edge_boundary(1248204388774707199) │
├─────────────────────────────────────────────────────────────────────────────────┤
│ [(37.42012867767778,-122.03773496427027),(37.33755608435298,-122.090428929044)] │
└─────────────────────────────────────────────────────────────────────────────────┘
5.10.21 - H3_GET_UNIDIRECTIONAL_EDGES_FROM_HEXAGON
Returns all of the unidirectional edges from the provided H3Index.
Analyze Syntax
func.h3_get_unidirectional_edges_from_hexagon(h3)
Analyze Examples
func.h3_get_unidirectional_edges_from_hexagon(644325524701193754)
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.h3_get_unidirectional_edges_from_hexagon(644325524701193754) │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ [1292843871042545178,1364901465080473114,1436959059118401050,1509016653156328986,1581074247194256922,1653131841232184858] │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
H3_GET_UNIDIRECTIONAL_EDGES_FROM_HEXAGON(h3)
SQL Examples
SELECT H3_GET_UNIDIRECTIONAL_EDGES_FROM_HEXAGON(644325524701193754);
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ h3_get_unidirectional_edges_from_hexagon(644325524701193754) │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ [1292843871042545178,1364901465080473114,1436959059118401050,1509016653156328986,1581074247194256922,1653131841232184858] │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.10.22 - H3_HEX_AREA_KM2
Returns the average hexagon area in square kilometers at the given resolution. Excludes pentagons.
Analyze Syntax
func.h3_area_km2(res)
Analyze Examples
func.h3_area_km2(1)
┌─────────────────────────┐
│ func.h3_hex_area_km2(1) │
├─────────────────────────┤
│ 609788.4417941332 │
└─────────────────────────┘
SQL Syntax
H3_HEX_AREA_KM2(res)
SQL Examples
SELECT H3_HEX_AREA_KM2(1);
┌────────────────────┐
│ h3_hex_area_km2(1) │
├────────────────────┤
│ 609788.4417941332 │
└────────────────────┘
5.10.23 - H3_HEX_AREA_M2
Returns the average hexagon area in square meters at the given resolution. Excludes pentagons.
Analyze Syntax
func.h3_hex_area_m2(res)
Analyze Examples
func.h3_hex_area_m2(1)
┌────────────────────────┐
│ func.h3_hex_area_m2(1) │
├────────────────────────┤
│ 609788441794.1339 │
└────────────────────────┘
SQL Syntax
H3_HEX_AREA_M2(res)
SQL Examples
SELECT H3_HEX_AREA_M2(1);
┌───────────────────┐
│ h3_hex_area_m2(1) │
├───────────────────┤
│ 609788441794.1339 │
└───────────────────┘
5.10.24 - H3_HEX_RING
Returns the "hollow" ring of hexagons at exactly grid distance k from the given H3 index.
Analyze Syntax
func.h3_hex_ring(h3, k)
Analyze Examples
func.h3_hex_ring(599686042433355775, 2)
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.h3_hex_ring(599686042433355775, 2) │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ [599686018811035647,599686034917163007,599686029548453887,599686032769679359,599686198125920255,599686040285872127,599686041359613951,599686039212130303,599686023106002943,599686027400970239,599686013442326527,599686012368584703] │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
H3_HEX_RING(h3, k)
SQL Examples
SELECT H3_HEX_RING(599686042433355775, 2);
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ h3_hex_ring(599686042433355775, 2) │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ [599686018811035647,599686034917163007,599686029548453887,599686032769679359,599686198125920255,599686040285872127,599686041359613951,599686039212130303,599686023106002943,599686027400970239,599686013442326527,599686012368584703] │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.10.25 - H3_INDEXES_ARE_NEIGHBORS
Returns whether or not the provided H3 indexes are neighbors.
Analyze Syntax
func.h3_indexes_are_neighbors(h3, a_h3)
Analyze Examples
func.h3_indexes_are_neighbors(644325524701193974, 644325524701193897)
┌───────────────────────────────────────────────────────────────────────┐
│ func.h3_indexes_are_neighbors(644325524701193974, 644325524701193897) │
├───────────────────────────────────────────────────────────────────────┤
│ true │
└───────────────────────────────────────────────────────────────────────┘
SQL Syntax
H3_INDEXES_ARE_NEIGHBORS(h3, a_h3)
SQL Examples
SELECT H3_INDEXES_ARE_NEIGHBORS(644325524701193974, 644325524701193897);
┌──────────────────────────────────────────────────────────────────┐
│ h3_indexes_are_neighbors(644325524701193974, 644325524701193897) │
├──────────────────────────────────────────────────────────────────┤
│ true │
└──────────────────────────────────────────────────────────────────┘
5.10.26 - H3_IS_PENTAGON
Checks if the given H3 index represents a pentagonal cell.
Analyze Syntax
func.h3_is_pentagon(h3)
Analyze Examples
func.h3_is_pentagon(599119489002373119)
┌─────────────────────────────────────────┐
│ func.h3_is_pentagon(599119489002373119) │
├─────────────────────────────────────────┤
│ true │
└─────────────────────────────────────────┘
SQL Syntax
H3_IS_PENTAGON(h3)
SQL Examples
SELECT H3_IS_PENTAGON(599119489002373119);
┌────────────────────────────────────┐
│ h3_is_pentagon(599119489002373119) │
├────────────────────────────────────┤
│ true │
└────────────────────────────────────┘
5.10.27 - H3_IS_RES_CLASS_III
Checks if the given H3 index has a resolution with Class III orientation.
Analyze Syntax
func.h3_is_res_class_iii(h3)
Analyze Examples
func.h3_is_res_class_iii(635318325446452991)
┌──────────────────────────────────────────────┐
│ func.h3_is_res_class_iii(635318325446452991) │
├──────────────────────────────────────────────┤
│ true │
└──────────────────────────────────────────────┘
SQL Syntax
H3_IS_RES_CLASS_III(h3)
SQL Examples
SELECT H3_IS_RES_CLASS_III(635318325446452991);
┌─────────────────────────────────────────┐
│ h3_is_res_class_iii(635318325446452991) │
├─────────────────────────────────────────┤
│ true │
└─────────────────────────────────────────┘
5.10.28 - H3_IS_VALID
Checks if the given H3 index is valid.
Analyze Syntax
func.h3_is_valid(h3)
Analyze Examples
func.h3_is_valid(644325524701193974)
┌──────────────────────────────────────┐
│ func.h3_is_valid(644325524701193974) │
├──────────────────────────────────────┤
│ true │
└──────────────────────────────────────┘
SQL Syntax
H3_IS_VALID(h3)
SQL Examples
SELECT H3_IS_VALID(644325524701193974);
┌─────────────────────────────────┐
│ h3_is_valid(644325524701193974) │
├─────────────────────────────────┤
│ true │
└─────────────────────────────────┘
5.10.29 - H3_K_RING
Returns an array containing the H3 indexes of the k-ring hexagons surrounding the input H3 index. Each element in this array is an H3 index.
Analyze Syntax
func.h3_k_ring(h3, k)
Analyze Examples
func.h3_k_ring(644325524701193974, 1)
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.h3_k_ring(644325524701193974, 1) │
├────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ [644325524701193974,644325524701193899,644325524701193869,644325524701193970,644325524701193968,644325524701193972,644325524701193897] │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
H3_K_RING(h3, k)
SQL Examples
SELECT H3_K_RING(644325524701193974, 1);
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ h3_k_ring(644325524701193974, 1) │
├────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ [644325524701193974,644325524701193899,644325524701193869,644325524701193970,644325524701193968,644325524701193972,644325524701193897] │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.10.30 - H3_LINE
Returns the line of indexes between the given two H3 indexes.
Analyze Syntax
func.h3_line(h3, a_h3)
Analyze Examples
func.h3_line(599119489002373119, 599119491149856767)
┌──────────────────────────────────────────────────────┐
│ func.h3_line(599119489002373119, 599119491149856767) │
├──────────────────────────────────────────────────────┤
│ [599119489002373119,599119491149856767] │
└──────────────────────────────────────────────────────┘
SQL Syntax
H3_LINE(h3, a_h3)
SQL Examples
SELECT H3_LINE(599119489002373119, 599119491149856767);
┌─────────────────────────────────────────────────┐
│ h3_line(599119489002373119, 599119491149856767) │
├─────────────────────────────────────────────────┤
│ [599119489002373119,599119491149856767] │
└─────────────────────────────────────────────────┘
5.10.31 - H3_NUM_HEXAGONS
Returns the number of unique H3 indexes at the given resolution.
Analyze Syntax
func.h3_num_hexagons(res)
Analyze Examples
func.h3_num_hexagons(10)
┌──────────────────────────┐
│ func.h3_num_hexagons(10) │
├──────────────────────────┤
│ 33897029882 │
└──────────────────────────┘
SQL Syntax
H3_NUM_HEXAGONS(res)
SQL Examples
SELECT H3_NUM_HEXAGONS(10);
┌─────────────────────┐
│ h3_num_hexagons(10) │
├─────────────────────┤
│ 33897029882 │
└─────────────────────┘
5.10.32 - H3_TO_CENTER_CHILD
Returns the center child index at the specified resolution.
Analyze Syntax
func.h3_to_center_child(h3, res)
Analyze Examples
func.h3_to_center_child(599119489002373119, 15)
┌─────────────────────────────────────────────────┐
│ func.h3_to_center_child(599119489002373119, 15) │
├─────────────────────────────────────────────────┤
│ 644155484202336256 │
└─────────────────────────────────────────────────┘
SQL Syntax
H3_TO_CENTER_CHILD(h3, res)
SQL Examples
SELECT H3_TO_CENTER_CHILD(599119489002373119, 15);
┌────────────────────────────────────────────┐
│ h3_to_center_child(599119489002373119, 15) │
├────────────────────────────────────────────┤
│ 644155484202336256 │
└────────────────────────────────────────────┘
5.10.33 - H3_TO_CHILDREN
Returns the indexes contained by h3 at resolution child_res.
Analyze Syntax
func.h3_to_children(h3, child_res)
Analyze Examples
func.h3_to_children(635318325446452991, 14)
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.h3_to_children(635318325446452991, 14) │
├────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ [639821925073823431,639821925073823439,639821925073823447,639821925073823455,639821925073823463,639821925073823471,639821925073823479] │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
H3_TO_CHILDREN(h3, child_res)
SQL Examples
SELECT H3_TO_CHILDREN(635318325446452991, 14);
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ h3_to_children(635318325446452991, 14) │
├────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ [639821925073823431,639821925073823439,639821925073823447,639821925073823455,639821925073823463,639821925073823471,639821925073823479] │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.10.34 - H3_TO_GEO
Returns the longitude and latitude corresponding to the given H3 index.
Analyze Syntax
func.h3_to_geo(h3)
Analyze Examples
func.h3_to_geo(644325524701193974)
┌────────────────────────────────────────┐
│ func.h3_to_geo(644325524701193974) │
├────────────────────────────────────────┤
│ (37.79506616830255,55.712902431456676) │
└────────────────────────────────────────┘
SQL Syntax
H3_TO_GEO(h3)
SQL Examples
SELECT H3_TO_GEO(644325524701193974);
┌────────────────────────────────────────┐
│ h3_to_geo(644325524701193974) │
├────────────────────────────────────────┤
│ (37.79506616830255,55.712902431456676) │
└────────────────────────────────────────┘
5.10.35 - H3_TO_GEO_BOUNDARY
Returns an array containing the longitude and latitude coordinates of the vertices of the hexagon corresponding to the H3 index.
Analyze Syntax
func.h3_to_geo_boundary(h3)
Analyze Examples
func.h3_to_geo_boundary(644325524701193974)
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.h3_to_geo_boundary(644325524701193974) │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ [(37.79505811173477,55.712900225355526),(37.79506506997187,55.71289713485417),(37.795073126539855,55.71289934095484),(37.795074224871684,55.71290463755745),(37.79506726663349,55.71290772805916),(37.79505921006456,55.712905521957914)] │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
H3_TO_GEO_BOUNDARY(h3)
SQL Examples
SELECT H3_TO_GEO_BOUNDARY(644325524701193974);
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ h3_to_geo_boundary(644325524701193974) │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ [(37.79505811173477,55.712900225355526),(37.79506506997187,55.71289713485417),(37.795073126539855,55.71289934095484),(37.795074224871684,55.71290463755745),(37.79506726663349,55.71290772805916),(37.79505921006456,55.712905521957914)] │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.10.36 - H3_TO_PARENT
Returns the parent index containing the h3 at resolution parent_res. Returning 0 means an error occurred.
Analyze Syntax
func.h3_to_parent(h3, parent_res)
Analyze Examples
func.h3_to_parent(635318325446452991, 12)
┌───────────────────────────────────────────┐
│ func.h3_to_parent(635318325446452991, 12) │
├───────────────────────────────────────────┤
│ 630814725819082751 │
└───────────────────────────────────────────┘
SQL Syntax
H3_TO_PARENT(h3, parent_res)
SQL Examples
SELECT H3_TO_PARENT(635318325446452991, 12);
┌──────────────────────────────────────┐
│ h3_to_parent(635318325446452991, 12) │
├──────────────────────────────────────┤
│ 630814725819082751 │
└──────────────────────────────────────┘
5.10.37 - H3_TO_STRING
Converts the representation of the given H3 index to the string representation.
Analyze Syntax
func.h3_to_string(h3)
Analyze Examples
func.h3_to_string(635318325446452991)
┌───────────────────────────────────────┐
│ func.h3_to_string(635318325446452991) │
├───────────────────────────────────────┤
│ 8d11aa6a38826ff │
└───────────────────────────────────────┘
SQL Syntax
H3_TO_STRING(h3)
SQL Examples
SELECT H3_TO_STRING(635318325446452991);
┌──────────────────────────────────┐
│ h3_to_string(635318325446452991) │
├──────────────────────────────────┤
│ 8d11aa6a38826ff │
└──────────────────────────────────┘
5.10.38 - H3_UNIDIRECTIONAL_EDGE_IS_VALID
Determines if the provided H3Index is a valid unidirectional edge index. Returns 1 if it's a unidirectional edge and 0 otherwise.
Analyze Syntax
func.h3_unidirectional_edge_is_valid(h3)
Analyze Examples
func.h3_unidirectional_edge_is_valid(1248204388774707199)
┌───────────────────────────────────────────────────────────┐
│ func.h3_unidirectional_edge_is_valid(1248204388774707199) │
├───────────────────────────────────────────────────────────┤
│ true │
└───────────────────────────────────────────────────────────┘
SQL Syntax
H3_UNIDIRECTIONAL_EDGE_IS_VALID(h3)
SQL Examples
SELECT H3_UNIDIRECTIONAL_EDGE_IS_VALID(1248204388774707199);
┌──────────────────────────────────────────────────────┐
│ h3_unidirectional_edge_is_valid(1248204388774707199) │
├──────────────────────────────────────────────────────┤
│ true │
└──────────────────────────────────────────────────────┘
5.10.39 - POINT_IN_POLYGON
Calculates whether a given point falls within the polygon formed by joining multiple points. A polygon is a closed shape connected by coordinate pairs in the order they appear. Changing the order of coordinate pairs can result in a different shape.
Analyze Syntax
func.point_in_polygon((x,y), [(a,b), (c,d), (e,f) ... ])
Analyze Examples
func.point_in_polygon((3., 3.), [(6, 0), (8, 4), (5, 8), (0, 2)])
┌─────────────────────────────────────────────────────────────────┐
│ func.point_in_polygon((3, 3), [(6, 0), (8, 4), (5, 8), (0, 2)]) │
├─────────────────────────────────────────────────────────────────┤
│ 1 │
└─────────────────────────────────────────────────────────────────┘
SQL Syntax
POINT_IN_POLYGON((x,y), [(a,b), (c,d), (e,f) ... ])
SQL Examples
SELECT POINT_IN_POLYGON((3., 3.), [(6, 0), (8, 4), (5, 8), (0, 2)]);
┌────────────────────────────────────────────────────────────┐
│ point_in_polygon((3, 3), [(6, 0), (8, 4), (5, 8), (0, 2)]) │
├────────────────────────────────────────────────────────────┤
│ 1 │
└────────────────────────────────────────────────────────────┘
5.10.40 - STRING_TO_H3
Converts the string representation to H3 (uint64) representation.
Analyze Syntax
func.string_to_h3(h3)
Analyze Examples
func.string_to_h3('8d11aa6a38826ff')
┌──────────────────────────────────────┐
│ func.string_to_h3('8d11aa6a38826ff') │
├──────────────────────────────────────┤
│ 635318325446452991 │
└──────────────────────────────────────┘
SQL Syntax
STRING_TO_H3(h3)
SQL Examples
SELECT STRING_TO_H3('8d11aa6a38826ff');
┌─────────────────────────────────┐
│ string_to_h3('8d11aa6a38826ff') │
├─────────────────────────────────┤
│ 635318325446452991 │
└─────────────────────────────────┘
5.11 - Geometry Functions
This section provides reference information for geometry and distance functions in PlaidCloud Lakehouse.
5.11.1 - HAVERSINE
Calculates the great circle distance in kilometers between two points on the Earth’s surface, using the Haversine formula. The two points are specified by their latitude and longitude in degrees.
SQL Syntax
HAVERSINE(<lat1>, <lon1>, <lat2>, <lon2>)
Arguments
| Arguments | Description |
|---|---|
<lat1> | The latitude of the first point. |
<lon1> | The longitude of the first point. |
<lat2> | The latitude of the second point. |
<lon2> | The longitude of the second point. |
Return Type
Double.
SQL Examples
SELECT
HAVERSINE(40.7127, -74.0059, 34.0500, -118.2500) AS distance
┌────────────────┐
│ distance │
├────────────────┤
│ 3936.390533556 │
└────────────────┘
5.11.2 - ST_ASBINARY
Alias for ST_ASWKB.
5.11.3 - ST_ASEWKB
Converts a GEOMETRY object into a EWKB(extended well-known-binary) format representation.
SQL Syntax
ST_ASEWKB(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY. |
Return Type
Binary.
SQL Examples
SELECT
ST_ASEWKB(
ST_GEOMETRYFROMWKT(
'SRID=4326;LINESTRING(400000 6000000, 401000 6010000)'
)
) AS pipeline_ewkb;
┌────────────────────────────────────────────────────────────────────────────────────────────┐
│ pipeline_ewkb │
├────────────────────────────────────────────────────────────────────────────────────────────┤
│ 0102000020E61000000200000000000000006A18410000000060E3564100000000A07918410000000024ED5641 │
└────────────────────────────────────────────────────────────────────────────────────────────┘
SELECT
ST_ASEWKB(
ST_GEOMETRYFROMWKT(
'SRID=4326;POINT(-122.35 37.55)'
)
) AS pipeline_ewkb;
┌────────────────────────────────────────────────────┐
│ pipeline_ewkb │
├────────────────────────────────────────────────────┤
│ 0101000020E61000006666666666965EC06666666666C64240 │
└────────────────────────────────────────────────────┘
5.11.4 - ST_ASEWKT
Converts a GEOMETRY object into a EWKT(extended well-known-text) format representation.
SQL Syntax
ST_ASEWKT(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY. |
Return Type
String.
SQL Examples
SELECT
ST_ASEWKT(
ST_GEOMETRYFROMWKT(
'SRID=4326;LINESTRING(400000 6000000, 401000 6010000)'
)
) AS pipeline_ewkt;
┌─────────────────────────────────────────────────────┐
│ pipeline_ewkt │
├─────────────────────────────────────────────────────┤
│ SRID=4326;LINESTRING(400000 6000000,401000 6010000) │
└─────────────────────────────────────────────────────┘
SELECT
ST_ASEWKT(
ST_GEOMETRYFROMWKT(
'SRID=4326;POINT(-122.35 37.55)'
)
) AS pipeline_ewkt;
┌────────────────────────────────┐
│ pipeline_ewkt │
├────────────────────────────────┤
│ SRID=4326;POINT(-122.35 37.55) │
└────────────────────────────────┘
5.11.5 - ST_ASGEOJSON
Converts a GEOMETRY object into a GeoJSON representation.
SQL Syntax
ST_ASGEOJSON(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY. |
Return Type
Variant.
SQL Examples
SELECT
ST_ASGEOJSON(
ST_GEOMETRYFROMWKT(
'SRID=4326;LINESTRING(400000 6000000, 401000 6010000)'
)
) AS pipeline_geojson;
┌─────────────────────────────────────────────────────────────────────────┐
│ pipeline_geojson │
├─────────────────────────────────────────────────────────────────────────┤
│ {"coordinates":[[400000,6000000],[401000,6010000]],"type":"LineString"} │
└─────────────────────────────────────────────────────────────────────────┘
5.11.6 - ST_ASTEXT
Alias for ST_ASWKT.
5.11.7 - ST_ASWKB
Converts a GEOMETRY object into a WKB(well-known-binary) format representation.
SQL Syntax
ST_ASWKB(<geometry>)
Aliases
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY. |
Return Type
Binary.
SQL Examples
SELECT
ST_ASWKB(
ST_GEOMETRYFROMWKT(
'SRID=4326;LINESTRING(400000 6000000, 401000 6010000)'
)
) AS pipeline_wkb;
┌────────────────────────────────────────────────────────────────────────────────────┐
│ pipeline_wkb │
├────────────────────────────────────────────────────────────────────────────────────┤
│ 01020000000200000000000000006A18410000000060E3564100000000A07918410000000024ED5641 │
└────────────────────────────────────────────────────────────────────────────────────┘
SELECT
ST_ASBINARY(
ST_GEOMETRYFROMWKT(
'SRID=4326;POINT(-122.35 37.55)'
)
) AS pipeline_wkb;
┌────────────────────────────────────────────┐
│ pipeline_wkb │
├────────────────────────────────────────────┤
│ 01010000006666666666965EC06666666666C64240 │
└────────────────────────────────────────────┘
5.11.8 - ST_ASWKT
Converts a GEOMETRY object into a WKT(well-known-text) format representation.
SQL Syntax
ST_ASWKT(<geometry>)
Aliases
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY. |
Return Type
String.
SQL Examples
SELECT
ST_ASWKT(
ST_GEOMETRYFROMWKT(
'SRID=4326;LINESTRING(400000 6000000, 401000 6010000)'
)
) AS pipeline_wkt;
┌───────────────────────────────────────────┐
│ pipeline_wkt │
├───────────────────────────────────────────┤
│ LINESTRING(400000 6000000,401000 6010000) │
└───────────────────────────────────────────┘
SELECT
ST_ASTEXT(
ST_GEOMETRYFROMWKT(
'SRID=4326;POINT(-122.35 37.55)'
)
) AS pipeline_wkt;
┌──────────────────────┐
│ pipeline_wkt │
├──────────────────────┤
│ POINT(-122.35 37.55) │
└──────────────────────┘
5.11.9 - ST_CONTAINS
Returns TRUE if the second GEOMETRY object is completely inside the first GEOMETRY object.
SQL Syntax
ST_CONTAINS(<geometry1>, <geometry2>)
Arguments
| Arguments | Description |
|---|---|
<geometry1> | The argument must be an expression of type GEOMETRY object that is not a GeometryCollection. |
<geometry2> | The argument must be an expression of type GEOMETRY object that is not a GeometryCollection. |
:::note
- The function reports an error if the two input GEOMETRY objects have different SRIDs. :::
Return Type
Boolean.
SQL Examples
SELECT ST_CONTAINS(TO_GEOMETRY('POLYGON((-2 0, 0 2, 2 0, -2 0))'), TO_GEOMETRY('POLYGON((-1 0, 0 1, 1 0, -1 0))')) AS contains
┌──────────┐
│ contains │
├──────────┤
│ true │
└──────────┘
SELECT ST_CONTAINS(TO_GEOMETRY('POLYGON((-2 0, 0 2, 2 0, -2 0))'), TO_GEOMETRY('LINESTRING(-1 1, 0 2, 1 1)')) AS contains
┌──────────┐
│ contains │
├──────────┤
│ false │
└──────────┘
SELECT ST_CONTAINS(TO_GEOMETRY('POLYGON((-2 0, 0 2, 2 0, -2 0))'), TO_GEOMETRY('LINESTRING(-2 0, 0 0, 0 1)')) AS contains
┌──────────┐
│ contains │
├──────────┤
│ true │
└──────────┘
5.11.10 - ST_DIMENSION
Return the dimension for a geometry object. The dimension of a GEOMETRY object is:
| Geospatial Object Type | Dimension |
|---|---|
| Point / MultiPoint | 0 |
| LineString / MultiLineString | 1 |
| Polygon / MultiPolygon | 2 |
SQL Syntax
ST_DIMENSION(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY. |
Return Type
UInt8.
SQL Examples
SELECT
ST_DIMENSION(
ST_GEOMETRYFROMWKT(
'POINT(-122.306100 37.554162)'
)
) AS pipeline_dimension;
┌────────────────────┐
│ pipeline_dimension │
├────────────────────┤
│ 0 │
└────────────────────┘
SELECT
ST_DIMENSION(
ST_GEOMETRYFROMWKT(
'LINESTRING(-124.20 42.00, -120.01 41.99)'
)
) AS pipeline_dimension;
┌────────────────────┐
│ pipeline_dimension │
├────────────────────┤
│ 1 │
└────────────────────┘
SELECT
ST_DIMENSION(
ST_GEOMETRYFROMWKT(
'POLYGON((-124.20 42.00, -120.01 41.99, -121.1 42.01, -124.20 42.00))'
)
) AS pipeline_dimension;
┌────────────────────┐
│ pipeline_dimension │
├────────────────────┤
│ 2 │
└────────────────────┘
5.11.11 - ST_DISTANCE
Returns the minimum Euclidean distance between two GEOMETRY objects.
SQL Syntax
ST_DISTANCE(<geometry1>, <geometry2>)
Arguments
| Arguments | Description |
|---|---|
<geometry1> | The argument must be an expression of type GEOMETRY and must contain a Point. |
<geometry2> | The argument must be an expression of type GEOMETRY and must contain a Point. |
:::note
- Returns NULL if one or more input points are NULL.
- The function reports an error if the two input GEOMETRY objects have different SRIDs. :::
Return Type
Double.
SQL Examples
SELECT
ST_DISTANCE(
TO_GEOMETRY('POINT(0 0)'),
TO_GEOMETRY('POINT(1 1)')
) AS distance
┌─────────────┐
│ distance │
├─────────────┤
│ 1.414213562 │
└─────────────┘
5.11.12 - ST_ENDPOINT
Returns the last Point in a LineString.
SQL Syntax
ST_ENDPOINT(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY that represents a LineString. |
Return Type
Geometry.
SQL Examples
SELECT
ST_ENDPOINT(
ST_GEOMETRYFROMWKT(
'LINESTRING(1 1, 2 2, 3 3, 4 4)'
)
) AS pipeline_endpoint;
┌───────────────────┐
│ pipeline_endpoint │
├───────────────────┤
│ POINT(4 4) │
└───────────────────┘
5.11.13 - ST_GEOHASH
Return the geohash for a GEOMETRY object. A geohash is a short base32 string that identifies a geodesic rectangle containing a location in the world. The optional precision argument specifies the precision of the returned geohash. For example, passing 5 for `precision returns a shorter geohash (5 characters long) that is less precise.
SQL Syntax
ST_GEOHASH(<geometry> [, <precision>])
Arguments
| Arguments | Description |
|---|---|
geometry | The argument must be an expression of type GEOMETRY. |
[precision] | Optional. specifies the precision of the returned geohash, default is 12. |
Return Type
String.
SQL Examples
SELECT
ST_GEOHASH(
ST_GEOMETRYFROMWKT(
'POINT(-122.306100 37.554162)'
)
) AS pipeline_geohash;
┌──────────────────┐
│ pipeline_geohash │
├──────────────────┤
│ 9q9j8ue2v71y │
└──────────────────┘
SELECT
ST_GEOHASH(
ST_GEOMETRYFROMWKT(
'SRID=4326;POINT(-122.35 37.55)'
),
5
) AS pipeline_geohash;
┌──────────────────┐
│ pipeline_geohash │
├──────────────────┤
│ 9q8vx │
└──────────────────┘
5.11.14 - ST_GEOM_POINT
Alias for ST_MAKEGEOMPOINT.
5.11.15 - ST_GEOMETRYFROMEWKB
Alias for ST_GEOMTRYFROMWKB.
5.11.16 - ST_GEOMETRYFROMEWKT
Alias for ST_GEOMTRYFROMWKT.
5.11.17 - ST_GEOMETRYFROMTEXT
Alias for ST_GEOMETRYFROMWKT.
5.11.18 - ST_GEOMETRYFROMWKB
Parses a WKB(well-known-binary) or EWKB(extended well-known-binary) input and returns a value of type GEOMETRY.
SQL Syntax
ST_GEOMETRYFROMWKB(<string>, [<srid>])
ST_GEOMETRYFROMWKB(<binary>, [<srid>])
Aliases
Arguments
| Arguments | Description |
|---|---|
<string> | The argument must be a string expression in WKB or EWKB in hexadecimal format. |
<binary> | The argument must be a binary expression in WKB or EWKB format. |
<srid> | The integer value of the SRID to use. |
Return Type
Geometry.
SQL Examples
SELECT
ST_GEOMETRYFROMWKB(
'0101000020797f000066666666a9cb17411f85ebc19e325641'
) AS pipeline_geometry;
┌────────────────────────────────────────┐
│ pipeline_geometry │
├────────────────────────────────────────┤
│ SRID=32633;POINT(389866.35 5819003.03) │
└────────────────────────────────────────┘
SELECT
ST_GEOMETRYFROMWKB(
FROM_HEX('0101000020797f000066666666a9cb17411f85ebc19e325641'), 4326
) AS pipeline_geometry;
┌───────────────────────────────────────┐
│ pipeline_geometry │
├───────────────────────────────────────┤
│ SRID=4326;POINT(389866.35 5819003.03) │
└───────────────────────────────────────┘
5.11.19 - ST_GEOMETRYFROMWKT
Parses a WKT(well-known-text) or EWKT(extended well-known-text) input and returns a value of type GEOMETRY.
SQL Syntax
ST_GEOMETRYFROMWKT(<string>, [<srid>])
Aliases
Arguments
| Arguments | Description |
|---|---|
<string> | The argument must be a string expression in WKT or EWKT format. |
<srid> | The integer value of the SRID to use. |
Return Type
Geometry.
SQL Examples
SELECT
ST_GEOMETRYFROMWKT(
'POINT(1820.12 890.56)'
) AS pipeline_geometry;
┌───────────────────────┐
│ pipeline_geometry │
├───────────────────────┤
│ POINT(1820.12 890.56) │
└───────────────────────┘
SELECT
ST_GEOMETRYFROMWKT(
'POINT(1820.12 890.56)', 4326
) AS pipeline_geometry;
┌─────────────────────────────────┐
│ pipeline_geometry │
│ Geometry │
├─────────────────────────────────┤
│ SRID=4326;POINT(1820.12 890.56) │
└─────────────────────────────────┘
5.11.20 - ST_GEOMFROMEWKB
Alias for ST_GEOMTRYFROMWKB.
5.11.21 - ST_GEOMFROMEWKT
Alias for ST_GEOMTRYFROMWKT.
5.11.22 - ST_GEOMFROMGEOHASH
Returns a GEOMETRY object for the polygon that represents the boundaries of a geohash.
SQL Syntax
ST_GEOMFROMGEOHASH(<geohash>)
Arguments
| Arguments | Description |
|---|---|
<geohash> | The argument must be a geohash. |
Return Type
Geometry.
SQL Examples
SELECT
ST_GEOMFROMGEOHASH(
'9q60y60rhs'
) AS pipeline_geometry;
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ st_geomfromgeohash('9q60y60rhs') │
├──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ POLYGON((-120.66230535507202 35.30029535293579,-120.66230535507202 35.30030071735382,-120.66229462623596 35.30030071735382,-120.66229462623596 35.30029535293579,-120.66230535507202 35.30029535293579)) │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.11.23 - ST_GEOMFROMTEXT
Alias for ST_GEOMTRYFROMWKT.
5.11.24 - ST_GEOMFROMWKB
Alias for ST_GEOMTRYFROMWKB.
5.11.25 - ST_GEOMFROMWKT
Alias for ST_GEOMTRYFROMWKT.
5.11.26 - ST_GEOMPOINTFROMGEOHASH
Returns a GEOMETRY object for the point that represents center of a geohash.
SQL Syntax
ST_GEOMPOINTFROMGEOHASH(<geohash>)
Arguments
| Arguments | Description |
|---|---|
<geohash> | The argument must be a geohash. |
Return Type
Geometry.
SQL Examples
SELECT
ST_GEOMPOINTFROMGEOHASH(
's02equ0'
) AS pipeline_geometry;
┌──────────────────────────────────────────────┐
│ pipeline_geometry │
│ Geometry │
├──────────────────────────────────────────────┤
│ POINT(1.0004425048828125 2.0001983642578125) │
└──────────────────────────────────────────────┘
5.11.27 - ST_LENGTH
Returns the Euclidean length of the LineString(s) in a GEOMETRY object.
SQL Syntax
ST_LENGTH(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY containing linestrings. |
:::note
- If
<geometry>is not aLineString,MultiLineString, orGeometryCollectioncontaining linestrings, returns 0. - If
<geometry>is aGeometryCollection, returns the sum of the lengths of the linestrings in the collection. :::
Return Type
Double.
SQL Examples
SELECT
ST_LENGTH(TO_GEOMETRY('POINT(1 1)')) AS length
┌─────────┐
│ length │
├─────────┤
│ 0 │
└─────────┘
SELECT
ST_LENGTH(TO_GEOMETRY('LINESTRING(0 0, 1 1)')) AS length
┌─────────────┐
│ length │
├─────────────┤
│ 1.414213562 │
└─────────────┘
SELECT
ST_LENGTH(
TO_GEOMETRY('POLYGON((0 0, 0 1, 1 1, 1 0, 0 0))')
) AS length
┌─────────┐
│ length │
├─────────┤
│ 0 │
└─────────┘
5.11.28 - ST_MAKE_LINE
Alias for ST_MAKELINE.
5.11.29 - ST_MAKEGEOMPOINT
Constructs a GEOMETRY object that represents a Point with the specified longitude and latitude.
SQL Syntax
ST_MAKEGEOMPOINT(<longitude>, <latitude>)
Aliases
Arguments
| Arguments | Description |
|---|---|
<longitude> | A Double value that represents the longitude. |
<latitude> | A Double value that represents the latitude. |
Return Type
Geometry.
SQL Examples
SELECT
ST_MAKEGEOMPOINT(
7.0, 8.0
) AS pipeline_point;
┌────────────────┐
│ pipeline_point │
├────────────────┤
│ POINT(7 8) │
└────────────────┘
SELECT
ST_MAKEGEOMPOINT(
-122.3061, 37.554162
) AS pipeline_point;
┌────────────────────────────┐
│ pipeline_point │
├────────────────────────────┤
│ POINT(-122.3061 37.554162) │
└────────────────────────────┘
5.11.30 - ST_MAKELINE
Constructs a GEOMETRY object that represents a line connecting the points in the input two GEOMETRY objects.
SQL Syntax
ST_MAKELINE(<geometry1>, <geometry2>)
Aliases
Arguments
| Arguments | Description |
|---|---|
<geometry1> | A GEOMETRY object containing the points to connect. This object must be a Point, MultiPoint, or LineString. |
<geometry2> | A GEOMETRY object containing the points to connect. This object must be a Point, MultiPoint, or LineString. |
Return Type
Geometry.
SQL Examples
SELECT
ST_MAKELINE(
ST_GEOMETRYFROMWKT(
'POINT(-122.306100 37.554162)'
),
ST_GEOMETRYFROMWKT(
'POINT(-104.874173 56.714538)'
)
) AS pipeline_line;
┌───────────────────────────────────────────────────────┐
│ pipeline_line │
├───────────────────────────────────────────────────────┤
│ LINESTRING(-122.3061 37.554162,-104.874173 56.714538) │
└───────────────────────────────────────────────────────┘
5.11.31 - ST_MAKEPOLYGON
Constructs a GEOMETRY object that represents a Polygon without holes. The function uses the specified LineString as the outer loop.
SQL Syntax
ST_MAKEPOLYGON(<geometry>)
Aliases
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY. |
Return Type
Geometry.
SQL Examples
SELECT
ST_MAKEPOLYGON(
ST_GEOMETRYFROMWKT(
'LINESTRING(0.0 0.0, 1.0 0.0, 1.0 2.0, 0.0 2.0, 0.0 0.0)'
)
) AS pipeline_polygon;
┌────────────────────────────────┐
│ pipeline_polygon │
├────────────────────────────────┤
│ POLYGON((0 0,1 0,1 2,0 2,0 0)) │
└────────────────────────────────┘
5.11.32 - ST_NPOINTS
Returns the number of points in a GEOMETRY object.
SQL Syntax
ST_NPOINTS(<geometry>)
Aliases
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY object. |
Return Type
UInt8.
SQL Examples
SELECT ST_NPOINTS(TO_GEOMETRY('POINT(66 12)')) AS npoints
┌─────────┐
│ npoints │
├─────────┤
│ 1 │
└─────────┘
SELECT ST_NPOINTS(TO_GEOMETRY('MULTIPOINT((45 21),(12 54))')) AS npoints
┌─────────┐
│ npoints │
├─────────┤
│ 2 │
└─────────┘
SELECT ST_NPOINTS(TO_GEOMETRY('LINESTRING(40 60,50 50,60 40)')) AS npoints
┌─────────┐
│ npoints │
├─────────┤
│ 3 │
└─────────┘
SELECT ST_NPOINTS(TO_GEOMETRY('MULTILINESTRING((1 1,32 17),(33 12,73 49,87.1 6.1))')) AS npoints
┌─────────┐
│ npoints │
├─────────┤
│ 5 │
└─────────┘
SELECT ST_NPOINTS(TO_GEOMETRY('GEOMETRYCOLLECTION(POLYGON((-10 0,0 10,10 0,-10 0)),LINESTRING(40 60,50 50,60 40),POINT(99 11))')) AS npoints
┌─────────┐
│ npoints │
├─────────┤
│ 8 │
└─────────┘
5.11.33 - ST_NUMPOINTS
Alias for ST_NPOINTS.
5.11.34 - ST_POINTN
Returns a Point at a specified index in a LineString.
SQL Syntax
ST_POINTN(<geometry>, <index>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY that represents a LineString. |
<index> | The index of the Point to return. |
:::note The index is 1-based, and a negative index is uesed as the offset from the end of LineString. If index is out of bounds, the function returns an error. :::
Return Type
Geometry.
SQL Examples
SELECT
ST_POINTN(
ST_GEOMETRYFROMWKT(
'LINESTRING(1 1, 2 2, 3 3, 4 4)'
),
1
) AS pipeline_pointn;
┌─────────────────┐
│ pipeline_pointn │
├─────────────────┤
│ POINT(1 1) │
└─────────────────┘
SELECT
ST_POINTN(
ST_GEOMETRYFROMWKT(
'LINESTRING(1 1, 2 2, 3 3, 4 4)'
),
-2
) AS pipeline_pointn;
┌─────────────────┐
│ pipeline_pointn │
├─────────────────┤
│ POINT(3 3) │
└─────────────────┘
5.11.35 - ST_POLYGON
Alias for ST_MAKEPOLYGON.
5.11.36 - ST_SETSRID
Returns a GEOMETRY object that has its SRID (spatial reference system identifier) set to the specified value. This Function only change the SRID without affecting the coordinates of the object. If you also need to change the coordinates to match the new SRS (spatial reference system), use ST_TRANSFORM instead.
SQL Syntax
ST_SETSRID(<geometry>, <srid>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY object. |
<srid> | The SRID integer to set in the returned GEOMETRY object. |
Return Type
Geometry.
SQL Examples
SET GEOMETRY_OUTPUT_FORMAT = 'EWKT'
SELECT ST_SETSRID(TO_GEOMETRY('POINT(13 51)'), 4326) AS geometry
┌────────────────────────┐
│ geometry │
├────────────────────────┤
│ SRID=4326;POINT(13 51) │
└────────────────────────┘
5.11.37 - ST_SRID
Returns the SRID (spatial reference system identifier) of a GEOMETRY object.
SQL Syntax
ST_SRID(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY. |
Return Type
INT32.
:::note If the Geometry don't have a SRID, a default value 4326 will be returned. :::
SQL Examples
SELECT
ST_SRID(
TO_GEOMETRY(
'POINT(-122.306100 37.554162)',
1234
)
) AS pipeline_srid;
┌───────────────┐
│ pipeline_srid │
├───────────────┤
│ 1234 │
└───────────────┘
SELECT
ST_SRID(
ST_MAKEGEOMPOINT(
37.5, 45.5
)
) AS pipeline_srid;
┌───────────────┐
│ pipeline_srid │
├───────────────┤
│ 4326 │
└───────────────┘
5.11.38 - ST_STARTPOINT
Returns the first Point in a LineString.
SQL Syntax
ST_STARTPOINT(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY that represents a LineString. |
Return Type
Geometry.
SQL Examples
SELECT
ST_STARTPOINT(
ST_GEOMETRYFROMWKT(
'LINESTRING(1 1, 2 2, 3 3, 4 4)'
)
) AS pipeline_endpoint;
┌───────────────────┐
│ pipeline_endpoint │
├───────────────────┤
│ POINT(1 1) │
└───────────────────┘
5.11.39 - ST_TRANSFORM
Converts a GEOMETRY object from one spatial reference system (SRS) to another. If you just need to change the SRID without changing the coordinates (e.g. if the SRID was incorrect), use ST_SETSRID instead.
SQL Syntax
ST_TRANSFORM(<geometry> [, <from_srid>], <to_srid>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY object. |
<from_srid> | Optional SRID identifying the current SRS of the input GEOMETRY object, if this argument is omitted, use the SRID specified in the input GEOMETRY object. |
<to_srid> | The SRID that identifies the SRS to use, transforms the input GEOMETRY object to a new object that uses this SRS. |
Return Type
Geometry.
SQL Examples
SET GEOMETRY_OUTPUT_FORMAT = 'EWKT'
SELECT ST_TRANSFORM(ST_GEOMFROMWKT('POINT(389866.35 5819003.03)', 32633), 3857) AS transformed_geom
┌───────────────────────────────────────────────┐
│ transformed_geom │
├───────────────────────────────────────────────┤
│ SRID=3857;POINT(1489140.093766 6892872.19868) │
└───────────────────────────────────────────────┘
SELECT ST_TRANSFORM(ST_GEOMFROMWKT('POINT(4.500212 52.161170)'), 4326, 28992) AS transformed_geom
┌──────────────────────────────────────────────┐
│ transformed_geom │
├──────────────────────────────────────────────┤
│ SRID=28992;POINT(94308.670475 464038.168827) │
└──────────────────────────────────────────────┘
5.11.40 - ST_X
Returns the longitude (X coordinate) of a Point represented by a GEOMETRY object.
SQL Syntax
ST_X(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY and must contain a Point. |
Return Type
Double.
SQL Examples
SELECT
ST_X(
ST_MAKEGEOMPOINT(
37.5, 45.5
)
) AS pipeline_x;
┌────────────┐
│ pipeline_x │
├────────────┤
│ 37.5 │
└────────────┘
5.11.41 - ST_XMAX
Returns the maximum longitude (X coordinate) of all points contained in the specified GEOMETRY object.
SQL Syntax
ST_XMAX(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY. |
Return Type
Double.
SQL Examples
SELECT
ST_XMAX(
TO_GEOMETRY(
'GEOMETRYCOLLECTION(POINT(40 10),LINESTRING(10 10,20 20,10 40),POINT EMPTY)'
)
) AS pipeline_xmax;
┌───────────────┐
│ pipeline_xmax │
├───────────────┤
│ 40 │
└───────────────┘
SELECT
ST_XMAX(
TO_GEOMETRY(
'GEOMETRYCOLLECTION(POINT(40 10),LINESTRING(10 10,20 20,10 40),POLYGON((40 40,20 45,45 30,40 40)))'
)
) AS pipeline_xmax;
┌───────────────┐
│ pipeline_xmax │
├───────────────┤
│ 45 │
└───────────────┘
5.11.42 - ST_XMIN
Returns the minimum longitude (X coordinate) of all points contained in the specified GEOMETRY object.
SQL Syntax
ST_XMIN(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY. |
Return Type
Double.
SQL Examples
SELECT
ST_XMIN(
TO_GEOMETRY(
'GEOMETRYCOLLECTION(POINT(180 10),LINESTRING(20 10,30 20,40 40),POINT EMPTY)'
)
) AS pipeline_xmin;
┌───────────────┐
│ pipeline_xmin │
├───────────────┤
│ 20 │
└───────────────┘
SELECT
ST_XMIN(
TO_GEOMETRY(
'GEOMETRYCOLLECTION(POINT(40 10),LINESTRING(20 10,30 20,10 40),POLYGON((40 40,20 45,45 30,40 40)))'
)
) AS pipeline_xmin;
┌───────────────┐
│ pipeline_xmin │
├───────────────┤
│ 10 │
└───────────────┘
5.11.43 - ST_Y
Returns the latitude (Y coordinate) of a Point represented by a GEOMETRY object.
SQL Syntax
ST_Y(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY and must contain a Point. |
Return Type
Double.
SQL Examples
SELECT
ST_Y(
ST_MAKEGEOMPOINT(
37.5, 45.5
)
) AS pipeline_y;
┌────────────┐
│ pipeline_y │
├────────────┤
│ 45.5 │
└────────────┘
5.11.44 - ST_YMAX
Returns the maximum latitude (Y coordinate) of all points contained in the specified GEOMETRY object.
SQL Syntax
ST_YMAX(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY. |
Return Type
Double.
SQL Examples
SELECT
ST_YMAX(
TO_GEOMETRY(
'GEOMETRYCOLLECTION(POINT(180 50),LINESTRING(10 10,20 20,10 40),POINT EMPTY)'
)
) AS pipeline_ymax;
┌───────────────┐
│ pipeline_ymax │
├───────────────┤
│ 50 │
└───────────────┘
SELECT
ST_YMAX(
TO_GEOMETRY(
'GEOMETRYCOLLECTION(POINT(40 10),LINESTRING(10 10,20 20,10 40),POLYGON((40 40,20 45,45 30,40 40)))'
)
) AS pipeline_ymax;
┌───────────────┐
│ pipeline_ymax │
├───────────────┤
│ 45 │
└───────────────┘
5.11.45 - ST_YMIN
Returns the minimum latitude (Y coordinate) of all points contained in the specified GEOMETRY object.
SQL Syntax
ST_YMIN(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY. |
Return Type
Double.
SQL Examples
SELECT
ST_YMIN(
TO_GEOMETRY(
'GEOMETRYCOLLECTION(POINT(-180 -10),LINESTRING(-179 0, 179 30),POINT EMPTY)'
)
) AS pipeline_ymin;
┌───────────────┐
│ pipeline_ymin │
├───────────────┤
│ -10 │
└───────────────┘
SELECT
ST_YMIN(
TO_GEOMETRY(
'GEOMETRYCOLLECTION(POINT(180 0),LINESTRING(-60 -30, 60 30),POLYGON((40 40,20 45,45 30,40 40)))'
)
) AS pipeline_ymin;
┌───────────────┐
│ pipeline_ymin │
├───────────────┤
│ -30 │
└───────────────┘
5.11.46 - TO_GEOMETRY
Parses an input and returns a value of type GEOMETRY.
TRY_TO_GEOMETRY returns a NULL value if an error occurs during parsing.
SQL Syntax
TO_GEOMETRY(<string>, [<srid>])
TO_GEOMETRY(<binary>, [<srid>])
TO_GEOMETRY(<variant>, [<srid>])
TRY_TO_GEOMETRY(<string>, [<srid>])
TRY_TO_GEOMETRY(<binary>, [<srid>])
TRY_TO_GEOMETRY(<variant>, [<srid>])
Arguments
| Arguments | Description |
|---|---|
<string> | The argument must be a string expression in WKT, EWKT, WKB or EWKB in hexadecimal format, GeoJSON format. |
<binary> | The argument must be a binary expression in WKB or EWKB format. |
<variant> | The argument must be a JSON OBJECT in GeoJSON format. |
<srid> | The integer value of the SRID to use. |
Return Type
Geometry.
SQL Examples
SELECT
TO_GEOMETRY(
'POINT(1820.12 890.56)'
) AS pipeline_geometry;
┌───────────────────────┐
│ pipeline_geometry │
├───────────────────────┤
│ POINT(1820.12 890.56) │
└───────────────────────┘
SELECT
TO_GEOMETRY(
'0101000020797f000066666666a9cb17411f85ebc19e325641', 4326
) AS pipeline_geometry;
┌───────────────────────────────────────┐
│ pipeline_geometry │
├───────────────────────────────────────┤
│ SRID=4326;POINT(389866.35 5819003.03) │
└───────────────────────────────────────┘
SELECT
TO_GEOMETRY(
FROM_HEX('0101000020797f000066666666a9cb17411f85ebc19e325641'), 4326
) AS pipeline_geometry;
┌───────────────────────────────────────┐
│ pipeline_geometry │
├───────────────────────────────────────┤
│ SRID=4326;POINT(389866.35 5819003.03) │
└───────────────────────────────────────┘
SELECT
TO_GEOMETRY(
'{"coordinates":[[389866,5819003],[390000,5830000]],"type":"LineString"}'
) AS pipeline_geometry;
┌───────────────────────────────────────────┐
│ pipeline_geometry │
├───────────────────────────────────────────┤
│ LINESTRING(389866 5819003,390000 5830000) │
└───────────────────────────────────────────┘
SELECT
TO_GEOMETRY(
PARSE_JSON('{"coordinates":[[389866,5819003],[390000,5830000]],"type":"LineString"}')
) AS pipeline_geometry;
┌───────────────────────────────────────────┐
│ pipeline_geometry │
├───────────────────────────────────────────┤
│ LINESTRING(389866 5819003,390000 5830000) │
└───────────────────────────────────────────┘
5.11.47 - TO_STRING
Converts a GEOMETRY object into a String representation. The display format of the output data is controlled by the geometry_output_format setting, which contains the following types:
| Parameter | Description |
|---|---|
| GeoJSON (default) | The GEOMETRY result is rendered as a JSON object in GeoJSON format. |
| WKT | The GEOMETRY result is rendered as a String in WKT format. |
| WKB | The GEOMETRY result is rendered as a Binary in WKB format. |
| EWKT | The GEOMETRY result is rendered as a String in EWKT format. |
| EWKB | The GEOMETRY result is rendered as a Binary in EWKB format. |
SQL Syntax
TO_STRING(<geometry>)
Arguments
| Arguments | Description |
|---|---|
<geometry> | The argument must be an expression of type GEOMETRY. |
Return Type
String.
SQL Examples
SET geometry_output_format='GeoJSON';
SELECT
TO_GEOMETRY(
ST_GEOMETRYFROMWKT(
'SRID=4326;LINESTRING(400000 6000000, 401000 6010000)'
)
) AS pipeline_geometry;
┌────────────────────────────────────────────────────────────────────────────┐
│ pipeline_geometry │
├────────────────────────────────────────────────────────────────────────────┤
│ {"type": "LineString", "coordinates": [[400000,6000000],[401000,6010000]]} │
└────────────────────────────────────────────────────────────────────────────┘
SET geometry_output_format='WKT';
SELECT
TO_GEOMETRY(
ST_GEOMETRYFROMWKT(
'SRID=4326;LINESTRING(400000 6000000, 401000 6010000)'
)
) AS pipeline_geometry;
┌───────────────────────────────────────────┐
│ pipeline_geometry │
├───────────────────────────────────────────┤
│ LINESTRING(400000 6000000,401000 6010000) │
└───────────────────────────────────────────┘
SET geometry_output_format='EWKT';
SELECT
TO_GEOMETRY(
ST_GEOMETRYFROMWKT(
'SRID=4326;LINESTRING(400000 6000000, 401000 6010000)'
)
) AS pipeline_geometry;
┌─────────────────────────────────────────────────────┐
│ pipeline_geometry │
├─────────────────────────────────────────────────────┤
│ SRID=4326;LINESTRING(400000 6000000,401000 6010000) │
└─────────────────────────────────────────────────────┘
SET geometry_output_format='WKB';
SELECT
TO_GEOMETRY(
ST_GEOMETRYFROMWKT(
'SRID=4326;LINESTRING(400000 6000000, 401000 6010000)'
)
) AS pipeline_geometry;
┌────────────────────────────────────────────────────────────────────────────────────┐
│ pipeline_geometry │
├────────────────────────────────────────────────────────────────────────────────────┤
│ 01020000000200000000000000006A18410000000060E3564100000000A07918410000000024ED5641 │
└────────────────────────────────────────────────────────────────────────────────────┘
SET geometry_output_format='EWKB';
SELECT
TO_GEOMETRY(
ST_GEOMETRYFROMWKT(
'SRID=4326;LINESTRING(400000 6000000, 401000 6010000)'
)
) AS pipeline_geometry;
┌────────────────────────────────────────────────────────────────────────────────────────────┐
│ pipeline_geometry │
├────────────────────────────────────────────────────────────────────────────────────────────┤
│ 0102000020E61000000200000000000000006A18410000000060E3564100000000A07918410000000024ED5641 │
└────────────────────────────────────────────────────────────────────────────────────────────┘
5.12 - Hash Functions
This section provides reference information for the Hash functions in PlaidCloud Lakehouse.
5.12.1 - BLAKE3
Calculates a BLAKE3 256-bit checksum for a string. The value is returned as a string of 64 hexadecimal digits or NULL if the argument was NULL.
Analyze Syntax
func.blake3(<expr>)
Analyze Examples
func.blake3('1234567890')
+------------------------------------------------------------------+
| func.blake3('1234567890') |
+------------------------------------------------------------------+
| d12e417e04494572b561ba2c12c3d7f9e5107c4747e27b9a8a54f8480c63e841 |
+------------------------------------------------------------------+
SQL Syntax
BLAKE3(<expr>)
SQL Examples
SELECT BLAKE3('1234567890');
┌──────────────────────────────────────────────────────────────────┐
│ blake3('1234567890') │
├──────────────────────────────────────────────────────────────────┤
│ d12e417e04494572b561ba2c12c3d7f9e5107c4747e27b9a8a54f8480c63e841 │
└──────────────────────────────────────────────────────────────────┘
5.12.2 - CITY64WITHSEED
Calculates a City64WithSeed 64-bit hash for a string.
Analyze Syntax
func.city64withseed(<expr1>, <expr2>)
Analyze Examples
func.city64withseed('1234567890', 12)
+---------------------------------------+
| func.city64withseed('1234567890', 12) |
+---------------------------------------+
| 10660895976650300430 |
+---------------------------------------+
SQL Syntax
CITY64WITHSEED(<expr1>, <expr2>)
SQL Examples
SELECT CITY64WITHSEED('1234567890', 12);
┌──────────────────────────────────┐
│ city64withseed('1234567890', 12) │
├──────────────────────────────────┤
│ 10660895976650300430 │
└──────────────────────────────────┘
5.12.3 - MD5
Calculates an MD5 128-bit checksum for a string. The value is returned as a string of 32 hexadecimal digits or NULL if the argument was NULL.
Analyze Syntax
func.md5(<expr>)
Analyze Examples
func.md5('1234567890')
+------------------------------------------+
| func.md5('1234567890') |
+------------------------------------------+
| e807f1fcf82d132f9bb018ca6738a19f |
+------------------------------------------+
SQL Syntax
MD5(<expr>)
SQL Examples
SELECT MD5('1234567890');
┌──────────────────────────────────┐
│ md5('1234567890') │
├──────────────────────────────────┤
│ e807f1fcf82d132f9bb018ca6738a19f │
└──────────────────────────────────┘
5.12.4 - SHA
Calculates an SHA-1 160-bit checksum for the string, as described in RFC 3174 (Secure Hash Algorithm). The value is returned as a string of 40 hexadecimal digits or NULL if the argument was NULL.
Analyze Syntax
func.sha(<expr>)
Analyze Examples
func.sha('1234567890')
+------------------------------------------+
| func.sha('1234567890') |
+------------------------------------------+
| 01b307acba4f54f55aafc33bb06bbbf6ca803e9a |
+------------------------------------------+
SQL Syntax
SHA(<expr>)
Aliases
SQL Examples
SELECT SHA('1234567890'), SHA1('1234567890');
┌─────────────────────────────────────────────────────────────────────────────────────┐
│ sha('1234567890') │ sha1('1234567890') │
├──────────────────────────────────────────┼──────────────────────────────────────────┤
│ 01b307acba4f54f55aafc33bb06bbbf6ca803e9a │ 01b307acba4f54f55aafc33bb06bbbf6ca803e9a │
└─────────────────────────────────────────────────────────────────────────────────────┘
5.12.5 - SHA1
Alias for SHA.
5.12.6 - SHA2
Calculates the SHA-2 family of hash functions (SHA-224, SHA-256, SHA-384, and SHA-512). If the hash length is not one of the permitted values, the return value is NULL. Otherwise, the function result is a hash value containing the desired number of bits as a string of hexadecimal digits.
Analyze Syntax
func.sha2(<expr>, <expr>)
Analyze Examples
func.sha2('1234567890', 0)
+------------------------------------------------------------------+
| func.sha2('1234567890', 0)) |
+------------------------------------------------------------------+
| c775e7b757ede630cd0aa1113bd102661ab38829ca52a6422ab782862f268646 |
+------------------------------------------------------------------+
SQL Syntax
SHA2(<expr>, <expr>)
SQL Examples
SELECT SHA2('1234567890', 0);
┌──────────────────────────────────────────────────────────────────┐
│ sha2('1234567890', 0) │
├──────────────────────────────────────────────────────────────────┤
│ c775e7b757ede630cd0aa1113bd102661ab38829ca52a6422ab782862f268646 │
└──────────────────────────────────────────────────────────────────┘
5.12.7 - SIPHASH
Alias for SIPHASH64.
5.12.8 - SIPHASH64
Produces a 64-bit SipHash hash value.
Analyze Syntax
func.siphash64(<expr>)
Analyze Examples
func.siphash64('1234567890')
+-------------------------------+
| func.siphash64('1234567890') |
+-------------------------------+
| 18110648197875983073 |
+-------------------------------+
SQL Syntax
SIPHASH64(<expr>)
Aliases
SQL Examples
SELECT SIPHASH('1234567890'), SIPHASH64('1234567890');
┌─────────────────────────────────────────────────┐
│ siphash('1234567890') │ siphash64('1234567890') │
├───────────────────────┼─────────────────────────┤
│ 18110648197875983073 │ 18110648197875983073 │
└─────────────────────────────────────────────────┘
5.12.9 - XXHASH32
Calculates an xxHash32 32-bit hash value for a string. The value is returned as a UInt32 or NULL if the argument was NULL.
Analyze Syntax
func.xxhash32(<expr>)
Analyze Examples
func.xxhash32('1234567890')
+-----------------------------+
| func.xxhash32('1234567890') |
+-----------------------------+
| 3896585587 |
+-----------------------------+
SQL Syntax
XXHASH32(<expr>)
SQL Examples
SELECT XXHASH32('1234567890');
┌────────────────────────┐
│ xxhash32('1234567890') │
├────────────────────────┤
│ 3896585587 │
└────────────────────────┘
5.12.10 - XXHASH64
Calculates an xxHash64 64-bit hash value for a string. The value is returned as a UInt64 or NULL if the argument was NULL.
Analyze Syntax
func.xxhash64(<expr>)
Analyze Examples
func.xxhash64('1234567890')
+-----------------------------+
| func.xxhash64('1234567890') |
+-----------------------------+
| 12237639266330420150 |
+-----------------------------+
SQL Syntax
XXHASH64(<expr>)
SQL Examples
SELECT XXHASH64('1234567890');
┌────────────────────────┐
│ xxhash64('1234567890') │
├────────────────────────┤
│ 12237639266330420150 │
└────────────────────────┘
5.13 - Interval Functions
This section provides reference information for interval functions in PlaidCloud Lakehouse.
5.13.1 - EPOCH
Alias for TO_SECONDS.
5.13.2 - TO_CENTURIES
Converts a specified number of centuries into an Interval type.
- Accepts positive integers, zero, and negative integers as input.
Analyze Syntax
func.to_centuries(<centuries>)
Analyze Examples
func.to_centuries(2)
+------------------------------------------------------+
| func.to_centuries(2) |
+------------------------------------------------------+
| 200 years |
+------------------------------------------------------+
SQL Syntax
TO_CENTURIES(<centuries>)
Return Type
Interval (represented in years).
SQL Examples
SELECT TO_CENTURIES(2), TO_CENTURIES(0), TO_CENTURIES(-2);
┌───────────────────────────────────────────────────────┐
│ to_centuries(2) │ to_centuries(0) │ to_centuries(- 2) │
├─────────────────┼─────────────────┼───────────────────┤
│ 200 years │ 00:00:00 │ -200 years │
└───────────────────────────────────────────────────────┘
5.13.3 - TO_DAYS
Converts a specified number of days into an Interval type.
- Accepts positive integers, zero, and negative integers as input.
Analyze Syntax
func.to_days(<days>)
Analyze Examples
func.to_days(2)
+------------------------------------------------------+
| func.to_days(2) |
+------------------------------------------------------+
| 200 days |
+------------------------------------------------------+
SQL Syntax
TO_DAYS(<days>)
Return Type
Interval (represented in days).
SQL Examples
SELECT TO_DAYS(2), TO_DAYS(0), TO_DAYS(-2);
┌────────────────────────────────────────┐
│ to_days(2) │ to_days(0) │ to_days(- 2) │
├────────────┼────────────┼──────────────┤
│ 2 days │ 00:00:00 │ -2 days │
└────────────────────────────────────────┘
5.13.4 - TO_DECADES
Converts a specified number of decades into an Interval type.
- Accepts positive integers, zero, and negative integers as input.
Analyze Syntax
func.to_decades(<decades>)
Analyze Examples
func.to_decades(2)
+------------------------------------------------------+
| func.to_decades(2) |
+------------------------------------------------------+
| 20 years |
+------------------------------------------------------+
SQL Syntax
TO_DECADES(<decades>)
Return Type
Interval (represented in years).
SQL Examples
SELECT TO_DECADES(2), TO_DECADES(0), TO_DECADES((- 2));
┌─────────────────────────────────────────────────┐
│ to_decades(2) │ to_decades(0) │ to_decades(- 2) │
├───────────────┼───────────────┼─────────────────┤
│ 20 years │ 00:00:00 │ -20 years │
└─────────────────────────────────────────────────┘
5.13.5 - TO_HOURS
Converts a specified number of hours into an Interval type.
- Accepts positive integers, zero, and negative integers as input.
Analyze Syntax
func.to_hours(<hours>)
Analyze Examples
func.to_hours(2)
+------------------------------------------------------+
| func.to_hours(2) |
+------------------------------------------------------+
| 2:00:00 |
+------------------------------------------------------+
SQL Syntax
TO_HOURS(<hours>)
Return Type
Interval (in the format hh:mm:ss).
SQL Examples
SELECT TO_HOURS(2), TO_HOURS(0), TO_HOURS((- 2));
┌───────────────────────────────────────────┐
│ to_hours(2) │ to_hours(0) │ to_hours(- 2) │
├─────────────┼─────────────┼───────────────┤
│ 2:00:00 │ 00:00:00 │ -2:00:00 │
└───────────────────────────────────────────┘
5.13.6 - TO_MICROSECONDS
Converts a specified number of microseconds into an Interval type.
- Accepts positive integers, zero, and negative integers as input.
Analyze Syntax
func.to_microseconds(<microseconds>)
Analyze Examples
func.to_microseconds(2)
+------------------------------------------------------+
| func.to_microseconds(2) |
+------------------------------------------------------+
| 0:00:00.000002 |
+------------------------------------------------------+
SQL Syntax
TO_MICROSECONDS(<microseconds>)
Return Type
Interval (in the format hh:mm:ss.sssssss).
SQL Examples
SELECT TO_MICROSECONDS(2), TO_MICROSECONDS(0), TO_MICROSECONDS((- 2));
┌────────────────────────────────────────────────────────────────┐
│ to_microseconds(2) │ to_microseconds(0) │ to_microseconds(- 2) │
├────────────────────┼────────────────────┼──────────────────────┤
│ 0:00:00.000002 │ 00:00:00 │ -0:00:00.000002 │
└────────────────────────────────────────────────────────────────┘
5.13.7 - TO_MILLENNIA
Converts a specified number of millennia into an Interval type.
- Accepts positive integers, zero, and negative integers as input.
Analyze Syntax
func.to_millennia(<millennia>)
Analyze Examples
func.to_millennia(2)
+------------------------------------------------------+
| func.to_millennia(2) |
+------------------------------------------------------+
| 2000 years |
+------------------------------------------------------+
SQL Syntax
TO_MILLENNIA(<millennia>)
Return Type
Interval (represented in years).
SQL Examples
SELECT TO_MILLENNIA(2), TO_MILLENNIA(0), TO_MILLENNIA((- 2));
┌───────────────────────────────────────────────────────┐
│ to_millennia(2) │ to_millennia(0) │ to_millennia(- 2) │
├─────────────────┼─────────────────┼───────────────────┤
│ 2000 years │ 00:00:00 │ -2000 years │
└───────────────────────────────────────────────────────┘
5.13.8 - TO_MILLISECONDS
Converts a specified number of milliseconds into an Interval type.
- Accepts positive integers, zero, and negative integers as input.
Analyze Syntax
func.to_milliseconds(<milliseconds>)
Analyze Examples
func.to_milliseconds(2)
+------------------------------------------------------+
| func.to_milliseconds(2) |
+------------------------------------------------------+
| 0:00:00.002 |
+------------------------------------------------------+
SQL Syntax
TO_MILLISECONDS(<milliseconds>)
Return Type
Interval (in the format hh:mm:ss.sss).
SQL Examples
SELECT TO_MILLISECONDS(2), TO_MILLISECONDS(0), TO_MILLISECONDS((- 2));
┌────────────────────────────────────────────────────────────────┐
│ to_milliseconds(2) │ to_milliseconds(0) │ to_milliseconds(- 2) │
├────────────────────┼────────────────────┼──────────────────────┤
│ 0:00:00.002 │ 00:00:00 │ -0:00:00.002 │
└────────────────────────────────────────────────────────────────┘
5.13.9 - TO_MINUTES
Converts a specified number of minutes into an Interval type.
- Accepts positive integers, zero, and negative integers as input.
Analyze Syntax
func.to_minutes(<minutes>)
Analyze Examples
func.to_minutes(2)
+------------------------------------------------------+
| func.to_minutes(2) |
+------------------------------------------------------+
| 0:02:00 |
+------------------------------------------------------+
SQL Syntax
TO_MINUTES(<minutes>)
Return Type
Interval (in the format hh:mm:ss).
SQL Examples
SELECT TO_MINUTES(2), TO_MINUTES(0), TO_MINUTES((- 2));
┌─────────────────────────────────────────────────┐
│ to_minutes(2) │ to_minutes(0) │ to_minutes(- 2) │
├───────────────┼───────────────┼─────────────────┤
│ 0:02:00 │ 00:00:00 │ -0:02:00 │
└─────────────────────────────────────────────────┘
5.13.10 - TO_MONTHS
Converts a specified number of months into an Interval type.
- Accepts positive integers, zero, and negative integers as input.
Analyze Syntax
func.to_months(<months>)
Analyze Examples
func.to_months(2)
+------------------------------------------------------+
| func.to_months(2) |
+------------------------------------------------------+
| 2 months |
+------------------------------------------------------+
SQL Syntax
TO_MONTHS(<months>)
Return Type
Interval (represented in months).
SQL Examples
SELECT TO_MONTHS(2), TO_MONTHS(0), TO_MONTHS((- 2));
┌──────────────────────────────────────────────┐
│ to_months(2) │ to_months(0) │ to_months(- 2) │
├──────────────┼──────────────┼────────────────┤
│ 2 months │ 00:00:00 │ -2 months │
└──────────────────────────────────────────────┘
5.13.11 - TO_SECONDS
Converts a specified number of seconds into an Interval type.
- Accepts positive integers, zero, and negative integers as input.
Analyze Syntax
func.to_seconds(<seconds>)
Analyze Examples
func.to_seconds(2)
+------------------------------------------------------+
| func.to_seconds(2) |
+------------------------------------------------------+
| 0:00:02 |
+------------------------------------------------------+
SQL Syntax
TO_SECONDS(<seconds>)
Aliases
Return Type
Interval (in the format hh:mm:ss).
sQL Examples
SELECT TO_SECONDS(2), TO_SECONDS(0), TO_SECONDS((- 2));
┌─────────────────────────────────────────────────┐
│ to_seconds(2) │ to_seconds(0) │ to_seconds(- 2) │
├───────────────┼───────────────┼─────────────────┤
│ 0:00:02 │ 00:00:00 │ -0:00:02 │
└─────────────────────────────────────────────────┘
5.13.12 - TO_WEEKS
Converts a specified number of weeks into an Interval type.
- Accepts positive integers, zero, and negative integers as input.
Analyze Syntax
func.to_weeks(<weeks>)
Analyze Examples
func.to_weeks(2)
+------------------------------------------------------+
| func.to_weeks(2) |
+------------------------------------------------------+
| 14 days |
+------------------------------------------------------+
SQL Syntax
TO_WEEKS(<weeks>)
Return Type
Interval (represented in days).
sQL Examples
SELECT TO_WEEKS(2), TO_WEEKS(0), TO_WEEKS((- 2));
┌───────────────────────────────────────────┐
│ to_weeks(2) │ to_weeks(0) │ to_weeks(- 2) │
├─────────────┼─────────────┼───────────────┤
│ 14 days │ 00:00:00 │ -14 days │
└───────────────────────────────────────────┘
5.13.13 - TO_YEARS
Converts a specified number of years into an Interval type.
- Accepts positive integers, zero, and negative integers as input.
Analyze Syntax
func.to_years(<years>)
Analyze Examples
func.to_years(2)
+------------------------------------------------------+
| func.to_years(2) |
+------------------------------------------------------+
| 2 years |
+------------------------------------------------------+
SQL Syntax
TO_YEARS(<years>)
Return Type
Interval (represented in years).
SQL Examples
SELECT TO_YEARS(2), TO_YEARS(0), TO_YEARS((- 2));
┌───────────────────────────────────────────┐
│ to_years(2) │ to_years(0) │ to_years(- 2) │
├─────────────┼─────────────┼───────────────┤
│ 2 years │ 00:00:00 │ -2 years │
└───────────────────────────────────────────┘
5.14 - IP Address Functions
This section provides reference information for the IP address-related functions in PlaidCloud Lakehouse.
5.14.1 - INET_ATON
Converts an IPv4 address to a 32-bit integer.
Analyze Syntax
func.inet_aton(<ip>)
Analyze Examples
func.inet_aton('1.2.3.4')
┌───────────────────────────────┐
│ func.inet_aton('1.2.3.4') │
├───────────────────────────────┤
│ 16909060 │
└───────────────────────────────┘
SQL Syntax
INET_ATON(<ip>)
Aliases
Return Type
Integer.
SQL Examples
SELECT IPV4_STRING_TO_NUM('1.2.3.4'), INET_ATON('1.2.3.4');
┌──────────────────────────────────────────────────────┐
│ ipv4_string_to_num('1.2.3.4') │ inet_aton('1.2.3.4') │
├───────────────────────────────┼──────────────────────┤
│ 16909060 │ 16909060 │
└──────────────────────────────────────────────────────┘
5.14.2 - INET_NTOA
Converts a 32-bit integer to an IPv4 address.
Analyze Syntax
func.inet_ntoa(<int32>)
Analyze Examples
SELECT func.inet_ntoa(16909060)
┌──────────────────────────────┐
│ func.inet_ntoa(16909060) │
├──────────────────────────────┤
│ 1.2.3.4 │
└──────────────────────────────┘
SQL Syntax
INET_NOTA( <int32> )
Aliases
Return Type
String.
SQL Examples
SELECT IPV4_NUM_TO_STRING(16909060), INET_NTOA(16909060);
┌────────────────────────────────────────────────────┐
│ ipv4_num_to_string(16909060) │ inet_ntoa(16909060) │
├──────────────────────────────┼─────────────────────┤
│ 1.2.3.4 │ 1.2.3.4 │
└────────────────────────────────────────────────────┘
5.14.3 - IPV4_NUM_TO_STRING
Alias for INET_NTOA.
5.14.4 - IPV4_STRING_TO_NUM
Alias for INET_ATON.
5.14.5 - TRY_INET_ATON
try_inet_aton function is used to take the dotted-quad representation of an IPv4 address as a string and returns the numeric value of the given IP address in form of an integer.
Analyze Syntax
func.try_inet_aton(<str>)
Analyze Examples
func.try_inet_aton('10.0.5.9')
┌────────────────────────────────┐
│ func.try_inet_aton('10.0.5.9') │
├────────────────────────────────┤
│ 167773449 │
└────────────────────────────────┘
SQL Syntax
TRY_INET_ATON( <str> )
Aliases
Return Type
Integer.
SQL Examples
SELECT TRY_INET_ATON('10.0.5.9'), TRY_IPV4_STRING_TO_NUM('10.0.5.9');
┌────────────────────────────────────────────────────────────────┐
│ try_inet_aton('10.0.5.9') │ try_ipv4_string_to_num('10.0.5.9') │
│ UInt32 │ UInt32 │
├───────────────────────────┼────────────────────────────────────┤
│ 167773449 │ 167773449 │
└────────────────────────────────────────────────────────────────┘
5.14.6 - TRY_INET_NTOA
Takes an IPv4 address in network byte order and then returns the address as a dotted-quad string representation.
Analyze Syntax
func.try_inet_ntoa(<integer>)
Analyze Examples
func.try_inet_ntoaA(167773449)
┌───────────────────────────────┐
│ func.try_inet_ntoa(167773449) │
├───────────────────────────────┤
│ 10.0.5.9 │
└───────────────────────────────┘
SQL Syntax
TRY_INET_NTOA( <integer> )
Aliases
Return Type
String.
SQL Examples
SELECT TRY_INET_NTOA(167773449), TRY_IPV4_NUM_TO_STRING(167773449);
┌──────────────────────────────────────────────────────────────┐
│ try_inet_ntoa(167773449) │ try_ipv4_num_to_string(167773449) │
├──────────────────────────┼───────────────────────────────────┤
│ 10.0.5.9 │ 10.0.5.9 │
└──────────────────────────────────────────────────────────────┘
5.14.7 - TRY_IPV4_NUM_TO_STRING
Alias for TRY_INET_NTOA.
5.14.8 - TRY_IPV4_STRING_TO_NUM
Alias for TRY_INET_ATON.
5.15 - Map Functions
This section provides reference information for map functions in PlaidCloud Lakehouse.
5.15.1 - MAP_CAT
Returns the concatenatation of two MAPs.
SQL Syntax
MAP_CAT( <map1>, <map2> )
Arguments
| Arguments | Description |
|---|---|
<map1> | The source MAP. |
<map2> | The MAP to be appended to map1. |
:::note
- If both map1 and map2 have a value with the same key, then the output map contains the value from map2.
- If either argument is NULL, the function returns NULL without reporting any error. :::
Return Type
Map.
SQL Examples
SELECT MAP_CAT({'a':1,'b':2,'c':3}, {'c':5,'d':6});
┌─────────────────────────────────────────────┐
│ map_cat({'a':1,'b':2,'c':3}, {'c':5,'d':6}) │
├─────────────────────────────────────────────┤
│ {'a':1,'b':2,'c':5,'d':6} │
└─────────────────────────────────────────────┘
5.15.2 - MAP_CONTAINS_KEY
Determines whether the specified MAP contains the specified key.
SQL Syntax
MAP_CONTAINS_KEY( <map>, <key> )
Arguments
| Arguments | Description |
|---|---|
<map> | The map to be searched. |
<key> | The key to find. |
Return Type
Boolean.
SQL Examples
SELECT MAP_CONTAINS_KEY({'a':1,'b':2,'c':3}, 'c');
┌────────────────────────────────────────────┐
│ map_contains_key({'a':1,'b':2,'c':3}, 'c') │
├────────────────────────────────────────────┤
│ true │
└────────────────────────────────────────────┘
SELECT MAP_CONTAINS_KEY({'a':1,'b':2,'c':3}, 'x');
┌────────────────────────────────────────────┐
│ map_contains_key({'a':1,'b':2,'c':3}, 'x') │
├────────────────────────────────────────────┤
│ false │
└────────────────────────────────────────────┘
5.15.3 - MAP_DELETE
Returns an existing MAP with one or more keys removed.
SQL Syntax
MAP_DELETE( <map>, <key1> [, <key2>, ... ] )
MAP_DELETE( <map>, <array> )
Arguments
| Arguments | Description |
|---|---|
<map> | The MAP that contains the KEY to remove. |
<keyN> | The KEYs to be omitted from the returned MAP. |
<array> | The Array of KEYs to be omitted from the returned MAP. |
:::note
- The types of the key expressions and the keys in the map must be the same.
- Key values not found in the map will be ignored. :::
Return Type
Map.
SQL Examples
SELECT MAP_DELETE({'a':1,'b':2,'c':3}, 'a', 'c');
┌───────────────────────────────────────────┐
│ map_delete({'a':1,'b':2,'c':3}, 'a', 'c') │
├───────────────────────────────────────────┤
│ {'b':2} │
└───────────────────────────────────────────┘
SELECT MAP_DELETE({'a':1,'b':2,'c':3}, ['a', 'b']);
┌─────────────────────────────────────────────┐
│ map_delete({'a':1,'b':2,'c':3}, ['a', 'b']) │
├─────────────────────────────────────────────┤
│ {'c':3} │
└─────────────────────────────────────────────┘
5.15.4 - MAP_FILTER
Filters key-value pairs from a map using a lambda expression to define the condition.
SQL Syntax
MAP_FILTER(<map>, (<key>, <value>) -> <condition>)
Return Type
Returns a map that includes only the key-value pairs meeting the condition specified by the lambda expression.
SQL Examples
This example returns a map containing only the products with stock quantities below 10:
SELECT MAP_FILTER({101:15, 102:8, 103:12, 104:5}, (product_id, stock) -> (stock < 10)) AS low_stock_products;
┌────────────────────┐
│ low_stock_products │
├────────────────────┤
│ {102:8,104:5} │
└────────────────────┘
5.15.5 - MAP_INSERT
Returns a new MAP consisting of the input MAP with a new key-value pair inserted (an existing key updated with a new value).
SQL Syntax
MAP_INSERT( <map>, <key>, <value> [, <updateFlag> ] )
Arguments
| Arguments | Description |
|---|---|
<map> | The input MAP. |
<key> | The new key to insert into the MAP. |
<value> | The new value to insert into the MAP. |
<updateFlag> | The boolean flag indicates whether an existing key can be overwritten. The default is FALSE. |
Return Type
Map.
SQL Examples
SELECT MAP_INSERT({'a':1,'b':2,'c':3}, 'd', 4);
┌─────────────────────────────────────────┐
│ map_insert({'a':1,'b':2,'c':3}, 'd', 4) │
├─────────────────────────────────────────┤
│ {'a':1,'b':2,'c':3,'d':4} │
└─────────────────────────────────────────┘
SELECT MAP_INSERT({'a':1,'b':2,'c':3}, 'a', 5, true);
┌───────────────────────────────────────────────┐
│ map_insert({'a':1,'b':2,'c':3}, 'a', 5, TRUE) │
├───────────────────────────────────────────────┤
│ {'a':5,'b':2,'c':3} │
└───────────────────────────────────────────────┘
5.15.6 - MAP_KEYS
Returns the keys in a map.
SQL Syntax
MAP_KEYS( <map> )
Arguments
| Arguments | Description |
|---|---|
<map> | The input map. |
Return Type
Array.
SQL Examples
SELECT MAP_KEYS({'a':1,'b':2,'c':3});
┌───────────────────────────────┐
│ map_keys({'a':1,'b':2,'c':3}) │
├───────────────────────────────┤
│ ['a','b','c'] │
└───────────────────────────────┘
5.15.7 - MAP_PICK
Returns a new MAP containing the specified key-value pairs from an existing MAP.
SQL Syntax
MAP_PICK( <map>, <key1> [, <key2>, ... ] )
MAP_PICK( <map>, <array> )
Arguments
| Arguments | Description |
|---|---|
<map> | The input MAP. |
<keyN> | The KEYs to be included from the returned MAP. |
<array> | The Array of KEYs to be included from the returned MAP. |
:::note
- The types of the key expressions and the keys in the map must be the same.
- Key values not found in the map will be ignored. :::
Return Type
Map.
SQL Examples
SELECT MAP_PICK({'a':1,'b':2,'c':3}, 'a', 'c');
┌─────────────────────────────────────────┐
│ map_pick({'a':1,'b':2,'c':3}, 'a', 'c') │
├─────────────────────────────────────────┤
│ {'a':1,'c':3} │
└─────────────────────────────────────────┘
SELECT MAP_PICK({'a':1,'b':2,'c':3}, ['a', 'b']);
┌───────────────────────────────────────────┐
│ map_pick({'a':1,'b':2,'c':3}, ['a', 'b']) │
├───────────────────────────────────────────┤
│ {'a':1,'b':2} │
└───────────────────────────────────────────┘
5.15.8 - MAP_SIZE
Returns the size of a MAP.
SQL Syntax
MAP_SIZE( <map> )
Arguments
| Arguments | Description |
|---|---|
<map> | The input map. |
Return Type
UInt64.
SQL Examples
SELECT MAP_SIZE({'a':1,'b':2,'c':3});
┌───────────────────────────────┐
│ map_size({'a':1,'b':2,'c':3}) │
├───────────────────────────────┤
│ 3 │
└───────────────────────────────┘
5.15.9 - MAP_TRANSFORM_KEYS
Applies a transformation to each key in a map using a lambda expression.
SQL Syntax
MAP_TRANSFORM_KEYS(<map>, (<key>, <value>) -> <key_transformation>)
Return Type
Returns a map with the same values as the input map but with keys modified according to the specified lambda transformation.
SQL Examples
This example adds 1,000 to each product ID, creating a new map with updated keys while keeping the associated prices the same:
SELECT MAP_TRANSFORM_KEYS({101: 29.99, 102: 45.50, 103: 15.00}, (product_id, price) -> product_id + 1000) AS updated_product_ids;
┌────────────────────────────────────┐
│ updated_product_ids │
├────────────────────────────────────┤
│ {1101:29.99,1102:45.50,1103:15.00} │
└────────────────────────────────────┘
5.15.10 - MAP_TRANSFORM_VALUES
Applies a transformation to each value in a map using a lambda expression.
SQL Syntax
MAP_TRANSFORM_VALUES(<map>, (<key>, <value>) -> <value_transformation>)
Return Type
Returns a map with the same keys as the input map but with values modified according to the specified lambda transformation.
SQL Examples
This example reduces each product's price by 10%, while the product IDs (keys) remain unchanged:
SELECT MAP_TRANSFORM_VALUES({101: 100.0, 102: 150.0, 103: 200.0}, (product_id, price) -> price * 0.9) AS discounted_prices;
┌───────────────────────────────────┐
│ discounted_prices │
├───────────────────────────────────┤
│ {101:90.00,102:135.00,103:180.00} │
└───────────────────────────────────┘
5.15.11 - MAP_VALUES
Returns the values in a map.
SQL Syntax
MAP_VALUES( <map> )
Arguments
| Arguments | Description |
|---|---|
<map> | The input map. |
Return Type
Array.
SQL Examples
SELECT MAP_VALUES({'a':1,'b':2,'c':3});
┌─────────────────────────────────┐
│ map_values({'a':1,'b':2,'c':3}) │
├─────────────────────────────────┤
│ [1,2,3] │
└─────────────────────────────────┘
5.16 - Numeric Functions
This section provides reference information for the numeric functions in PlaidCloud Lakehouse.
5.16.1 - ABS
Returns the absolute value of x.
Analyze Syntax
func.abs( <x> )
Analyze Examples
func.abs((- 5))
┌─────────────────┐
│ func.abs((- 5)) │
├─────────────────┤
│ 5 │
└─────────────────┘
SQL Syntax
ABS( <x> )
SQL Examples
SELECT ABS(-5);
┌────────────┐
│ abs((- 5)) │
├────────────┤
│ 5 │
└────────────┘
5.16.2 - ACOS
Returns the arc cosine of x, that is, the value whose cosine is x. Returns NULL if x is not in the range -1 to 1.
Analyze Syntax
func.abs( <x> )
Analyze Examples
func.abs(1)
┌──────────────┐
│ func.acos(1) │
├──────────────┤
│ 0 │
└──────────────┘
SQL Syntax
ACOS( <x> )
SQL Examples
SELECT ACOS(1);
┌─────────┐
│ acos(1) │
├─────────┤
│ 0 │
└─────────┘
5.16.3 - ADD
Alias for PLUS.
5.16.4 - ASIN
Returns the arc sine of x, that is, the value whose sine is x. Returns NULL if x is not in the range -1 to 1.
Analyze Syntax
func.asin( <x> )
Analyze Examples
func.asin(0.2)
┌────────────────────┐
│ func.asin(0.2) │
├────────────────────┤
│ 0.2013579207903308 │
└────────────────────┘
SQL Syntax
ASIN( <x> )
SQL Examples
SELECT ASIN(0.2);
┌────────────────────┐
│ asin(0.2) │
├────────────────────┤
│ 0.2013579207903308 │
└────────────────────┘
5.16.5 - ATAN
Returns the arc tangent of x, that is, the value whose tangent is x.
Analyze Syntax
func.atan( <x> )
Analyze Examples
func.atan(-2)
┌─────────────────────┐
│ func.atan((- 2)) │
├─────────────────────┤
│ -1.1071487177940906 │
└─────────────────────┘
SQL Syntax
ATAN( <x> )
SQL Examples
SELECT ATAN(-2);
┌─────────────────────┐
│ atan((- 2)) │
├─────────────────────┤
│ -1.1071487177940906 │
└─────────────────────┘
5.16.6 - ATAN2
Returns the arc tangent of the two variables x and y. It is similar to calculating the arc tangent of y / x, except that the signs of both arguments are used to determine the quadrant of the result. ATAN(y, x) is a synonym for ATAN2(y, x).
Analyze Syntax
func.atan2( <y, x> )
Analyze Examples
func.atan2((- 2), 2)
┌─────────────────────┐
│ func.atan2((- 2), 2)│
├─────────────────────┤
│ -0.7853981633974483 │
└─────────────────────┘
SQL Syntax
ATAN2( <y, x> )
SQL Examples
SELECT ATAN2(-2, 2);
┌─────────────────────┐
│ atan2((- 2), 2) │
├─────────────────────┤
│ -0.7853981633974483 │
└─────────────────────┘
5.16.7 - CBRT
Returns the cube root of a nonnegative number x.
Analyze Syntax
func.cbrt( <x> )
Analyze Examples
func.cbrt(27)
┌───────────────┐
│ func.cbrt(27) │
├───────────────┤
│ 3 │
└───────────────┘
SQL Syntax
CBRT( <x> )
SQL Examples
SELECT CBRT(27);
┌──────────┐
│ cbrt(27) │
├──────────┤
│ 3 │
└──────────┘
5.16.8 - CEIL
Rounds the number up.
Analyze Syntax
func.ceil( <x> )
Analyze Examples
func.ceil((- 1.23))
┌─────────────────────┐
│ func.ceil((- 1.23)) │
├─────────────────────┤
│ -1 │
└─────────────────────┘
SQL Syntax
CEIL( <x> )
Aliases
SQL Examples
SELECT CEILING(-1.23), CEIL(-1.23);
┌────────────────────────────────────┐
│ ceiling((- 1.23)) │ ceil((- 1.23)) │
├───────────────────┼────────────────┤
│ -1 │ -1 │
└────────────────────────────────────┘
5.16.9 - CEILING
Alias for CEIL.
5.16.10 - COS
Returns the cosine of x, where x is given in radians.
Analyze Syntax
func.cos( <x> )
Analyze Examples
func.cos(func.pi())
┌─────────────────────┐
│ func.cos(func.pi()) │
├─────────────────────┤
│ -1 │
└─────────────────────┘
SQL Syntax
COS( <x> )
SQL Examples
SELECT COS(PI());
┌───────────┐
│ cos(pi()) │
├───────────┤
│ -1 │
└───────────┘
5.16.11 - COT
Returns the cotangent of x, where x is given in radians.
Analyze Syntax
func.cot( <x> )
Analyze Examples
func.cot(12)
┌─────────────────────┐
│ func.cot(12) │
├─────────────────────┤
│ -1.5726734063976895 │
└─────────────────────┘
SQL Syntax
COT( <x> )
SQL Examples
SELECT COT(12);
┌─────────────────────┐
│ cot(12) │
├─────────────────────┤
│ -1.5726734063976895 │
└─────────────────────┘
5.16.12 - CRC32
Returns the CRC32 checksum of x, where 'x' is expected to be a string and (if possible) is treated as one if it is not.
Analyze Syntax
func.crc32( '<x>' )
Analyze Examples
func.crc32('databend')
┌────────────────────────┐
│ func.crc32('databend') │
├────────────────────────┤
│ 1177678456 │
└────────────────────────┘
SQL Syntax
CRC32( '<x>' )
SQL Examples
SELECT CRC32('databend');
┌───────────────────┐
│ crc32('databend') │
├───────────────────┤
│ 1177678456 │
└───────────────────┘
5.16.13 - DEGREES
Returns the argument x, converted from radians to degrees, where x is given in radians.
Analyze Syntax
func.degrees( <x> )
Analyze Examples
func.degrees(func.pi())
┌─────────────────────────┐
│ func.degrees(func.pi()) │
├─────────────────────────┤
│ 180 │
└─────────────────────────┘
SQL Syntax
DEGREES( <x> )
SQL Examples
SELECT DEGREES(PI());
┌───────────────┐
│ degrees(pi()) │
├───────────────┤
│ 180 │
└───────────────┘
5.16.14 - DIV
Returns the quotient by dividing the first number by the second one, rounding down to the closest smaller integer. Equivalent to the division operator //.
See also:
SQL Syntax
func.div(<numerator>, <denominator>)
Analyze Examples
# Equivalent to the division operator "//"
func.div(6.1, 2)
┌───────────────────────────────┐
│ func.div(6.1, 2) │ (6.1 // 2) │
├──────────────────┼────────────┤
│ 3 │ 3 │
└───────────────────────────────┘
# Error when divided by 0
error: APIError: ResponseError with 1006: divided by zero while evaluating function `div(6.1, 0)`
Analyze Syntax
<number1> DIV <number2>
Aliases
SQL Examples
-- Equivalent to the division operator "//"
SELECT 6.1 DIV 2, 6.1//2;
┌──────────────────────────┐
│ (6.1 div 2) │ (6.1 // 2) │
├─────────────┼────────────┤
│ 3 │ 3 │
└──────────────────────────┘
SELECT 6.1 DIV 2, INTDIV(6.1, 2), 6.1 DIV NULL;
┌───────────────────────────────────────────────┐
│ (6.1 div 2) │ intdiv(6.1, 2) │ (6.1 div null) │
├─────────────┼────────────────┼────────────────┤
│ 3 │ 3 │ NULL │
└───────────────────────────────────────────────┘
-- Error when divided by 0
root@localhost:8000/default> SELECT 6.1 DIV 0;
error: APIError: ResponseError with 1006: divided by zero while evaluating function `div(6.1, 0)`
5.16.15 - DIV0
Returns the quotient by dividing the first number by the second one. Returns 0 if the second number is 0.
See also:
Analyze Syntax
func.div0(<numerator>, <denominator>)
Analyze Examples
func.div0(20, 6), func.div0(20, 0), func.div0(20, null)
┌─────────────────────────────────────────────────────────────┐
│ func.div0(20, 6) │ func.div0(20, 0) │ func.div0(20, null) │
├────────────────────┼──────────────────┼─────────────────────┤
│ 3.3333333333333335 │ 0 │ NULL │
└─────────────────────────────────────────────────────────────┘
SQL Syntax
DIV0(<number1>, <number2>)
SQL Examples
SELECT
DIV0(20, 6),
DIV0(20, 0),
DIV0(20, NULL);
┌───────────────────────────────────────────────────┐
│ div0(20, 6) │ div0(20, 0) │ div0(20, null) │
├────────────────────┼─────────────┼────────────────┤
│ 3.3333333333333335 │ 0 │ NULL │
└───────────────────────────────────────────────────┘
5.16.16 - DIVNULL
Returns the quotient by dividing the first number by the second one. Returns NULL if the second number is 0 or NULL.
See also:
Analyze Syntax
func.divnull(<numerator>, <denominator>)
Analyze Examples
func.divnull(20, 6), func.divnull(20, 0), func.divnull(20, null)
┌───────────────────────────────────────────────────────────────────┐
│ func.divnull(20, 6)│ func.divnull(20, 0) │ func.divnull(20, null) │
├────────────────────┼─────────────────────┼────────────────────────┤
│ 3.3333333333333335 │ NULL │ NULL │
└───────────────────────────────────────────────────────────────────┘
SQL Syntax
DIVNULL(<number1>, <number2>)
SQL Examples
SELECT
DIVNULL(20, 6),
DIVNULL(20, 0),
DIVNULL(20, NULL);
┌─────────────────────────────────────────────────────────┐
│ divnull(20, 6) │ divnull(20, 0) │ divnull(20, null) │
├────────────────────┼────────────────┼───────────────────┤
│ 3.3333333333333335 │ NULL │ NULL │
└─────────────────────────────────────────────────────────┘
5.16.17 - EXP
Returns the value of e (the base of natural logarithms) raised to the power of x.
Analyze Syntax
func.exp( <x> )
Analyze Examples
func.exp(2)
┌──────────────────┐
│ func.exp(2) │
├──────────────────┤
│ 7.38905609893065 │
└──────────────────┘
SQL Syntax
EXP( <x> )
SQL Examples
SELECT EXP(2);
┌──────────────────┐
│ exp(2) │
├──────────────────┤
│ 7.38905609893065 │
└──────────────────┘
5.16.18 - FACTORIAL
Returns the factorial logarithm of x. If x is less than or equal to 0, the function returns 0.
Analyze Syntax
func.factorial( <x> )
Analyze Examples
func.factorial(5)
┌───────────────────┐
│ func.factorial(5) │
├───────────────────┤
│ 120 │
└───────────────────┘
SQL Syntax
FACTORIAL( <x> )
SQL Examples
SELECT FACTORIAL(5);
┌──────────────┐
│ factorial(5) │
├──────────────┤
│ 120 │
└──────────────┘
5.16.19 - FLOOR
Rounds the number down.
Analyze Syntax
func.floor( <x> )
Analyze Examples
func.floor(1.23)
┌──────────────────┐
│ func.floor(1.23) │
├──────────────────┤
│ 1 │
└──────────────────┘
SQL Syntax
FLOOR( <x> )
SQL Examples
SELECT FLOOR(1.23);
┌─────────────┐
│ floor(1.23) │
├─────────────┤
│ 1 │
└─────────────┘
5.16.20 - INTDIV
Alias for DIV.
5.16.21 - LN
Returns the natural logarithm of x; that is, the base-e logarithm of x. If x is less than or equal to 0.0E0, the function returns NULL.
Analyze Syntax
func.ln( <x> )
Analyze Examples
func.ln(2)
┌────────────────────┐
│ func.ln(2) │
├────────────────────┤
│ 0.6931471805599453 │
└────────────────────┘
SQL Syntax
LN( <x> )
SQL Examples
SELECT LN(2);
┌────────────────────┐
│ ln(2) │
├────────────────────┤
│ 0.6931471805599453 │
└────────────────────┘
5.16.22 - LOG(b, x)
Returns the base-b logarithm of x. If x is less than or equal to 0.0E0, the function returns NULL.
Analyze Syntax
func.log( <b, x> )
Analyze Examples
func.log(2, 65536)
┌────────────────────┐
│ func.log(2, 65536) │
├────────────────────┤
│ 16 │
└────────────────────┘
SQL Syntax
LOG( <b, x> )
SQL Examples
SELECT LOG(2, 65536);
┌───────────────┐
│ log(2, 65536) │
├───────────────┤
│ 16 │
└───────────────┘
5.16.23 - LOG(x)
Returns the natural logarithm of x. If x is less than or equal to 0.0E0, the function returns NULL.
Analyze Syntax
func.log( <x> )
Analyze Examples
func.log(2)
┌────────────────────┐
│ func.log(2) │
├────────────────────┤
│ 0.6931471805599453 │
└────────────────────┘
SQL Syntax
LOG( <x> )
SQL Examples
SELECT LOG(2);
┌────────────────────┐
│ log(2) │
├────────────────────┤
│ 0.6931471805599453 │
└────────────────────┘
5.16.24 - LOG10
Returns the base-10 logarithm of x. If x is less than or equal to 0.0E0, the function returns NULL.
Analyze Syntax
func.log10( <x> )
Analyze Examples
func.log10(100)
┌─────────────────┐
│ func.log10(100) │
├─────────────────┤
│ 2 │
└─────────────────┘
SQL Syntax
LOG10( <x> )
SQL Examples
SELECT LOG10(100);
┌────────────┐
│ log10(100) │
├────────────┤
│ 2 │
└────────────┘
5.16.25 - LOG2
Returns the base-2 logarithm of x. If x is less than or equal to 0.0E0, the function returns NULL.
Analyze Syntax
func.log2( <x> )
Analyze Examples
func.log2(65536)
┌──────────────────┐
│ func.log2(65536) │
├──────────────────┤
│ 16 │
└──────────────────┘
SQL Syntax
LOG2( <x> )
SQL Examples
SELECT LOG2(65536);
┌─────────────┐
│ log2(65536) │
├─────────────┤
│ 16 │
└─────────────┘
5.16.26 - MINUS
Negates a numeric value.
Analyze Syntax
func.minus( <x> )
Analyze Examples
func.minus(func.pi())
┌─────────────────────────┐
│ func.minus(func.pi()) │
├─────────────────────────┤
│ -3.141592653589793 │
└─────────────────────────┘
SQL Syntax
MINUS( <x> )
Aliases
SQL Examples
SELECT MINUS(PI()), NEG(PI()), NEGATE(PI()), SUBTRACT(PI());
┌───────────────────────────────────────────────────────────────────────────────────┐
│ minus(pi()) │ neg(pi()) │ negate(pi()) │ subtract(pi()) │
├────────────────────┼────────────────────┼────────────────────┼────────────────────┤
│ -3.141592653589793 │ -3.141592653589793 │ -3.141592653589793 │ -3.141592653589793 │
└───────────────────────────────────────────────────────────────────────────────────┘
5.16.27 - MOD
Alias for MODULO.
5.16.28 - MODULO
Returns the remainder of x divided by y. If y is 0, it returns an error.
Analyze Syntax
func.modulo( <x>, <y> )
Analyze Examples
func.modulo(9, 2)
┌───────────────────┐
│ func.modulo(9, 2) │
├───────────────────┤
│ 1 │
└───────────────────┘
SQL Syntax
MODULO( <x>, <y> )
Aliases
SQL Examples
SELECT MOD(9, 2), MODULO(9, 2);
┌──────────────────────────┐
│ mod(9, 2) │ modulo(9, 2) │
├───────────┼──────────────┤
│ 1 │ 1 │
└──────────────────────────┘
5.16.29 - NEG
Alias for MINUS.
5.16.30 - NEGATE
Alias for MINUS.
5.16.31 - PI
Returns the value of π as a floating-point value.
Analyze Syntax
func.pi()
Analyze Examples
func.pi()
┌───────────────────┐
│ func.pi() │
├───────────────────┤
│ 3.141592653589793 │
└───────────────────┘
SQL Syntax
PI()
SQL Examples
SELECT PI();
┌───────────────────┐
│ pi() │
├───────────────────┤
│ 3.141592653589793 │
└───────────────────┘
5.16.32 - PLUS
Calculates the sum of two numeric or decimal values.
Analyze Syntax
func.plus(<number1>, <number2>)
Analyze Examples
func.plus(1, 2.3)
┌────────────────────┐
│ func.plus(1, 2.3) │
├────────────────────┤
│ 3.3 │
└────────────────────┘
SQL Syntax
PLUS(<number1>, <number2>)
Aliases
SQL Examples
SELECT ADD(1, 2.3), PLUS(1, 2.3);
┌───────────────────────────────┐
│ add(1, 2.3) │ plus(1, 2.3) │
├───────────────┼───────────────┤
│ 3.3 │ 3.3 │
└───────────────────────────────┘
5.16.33 - POW
Returns the value of x to the power of y.
Analyze Syntax
func.pow( <x, y> )
Analyze Examples
func.pow(-2, 2)
┌────────────────────┐
│ func.pow((- 2), 2) │
├────────────────────┤
│ 4 │
└────────────────────┘
SQL Syntax
POW( <x, y> )
Aliases
SQL Examples
SELECT POW(-2, 2), POWER(-2, 2);
┌─────────────────────────────────┐
│ pow((- 2), 2) │ power((- 2), 2) │
├───────────────┼─────────────────┤
│ 4 │ 4 │
└─────────────────────────────────┘
5.16.34 - POWER
Alias for POW.
5.16.35 - RADIANS
Returns the argument x, converted from degrees to radians.
Analyze Syntax
func.radians( <x> )
Analyze Examples
func.radians(90)
┌────────────────────┐
│ func.radians(90) │
├────────────────────┤
│ 1.5707963267948966 │
└────────────────────┘
SQL Syntax
RADIANS( <x> )
SQL Examples
SELECT RADIANS(90);
┌────────────────────┐
│ radians(90) │
├────────────────────┤
│ 1.5707963267948966 │
└────────────────────┘
5.16.36 - RAND()
Returns a random floating-point value v in the range 0 <= v < 1.0. To obtain a random integer R in the range i <= R < j, use the expression FLOOR(i + RAND() * (j − i)).
Analyze Syntax
func.rand()
Analyze Examples
func.rand()
┌────────────────────┐
│ func.rand() │
├────────────────────┤
│ 0.5191511074382174 │
└────────────────────┘
SQL Syntax
RAND()
SQL Examples
SELECT RAND();
┌────────────────────┐
│ rand() │
├────────────────────┤
│ 0.5191511074382174 │
└────────────────────┘
5.16.37 - RAND(n)
Returns a random floating-point value v in the range 0 <= v < 1.0. To obtain a random integer R in the range i <= R < j, use the expression FLOOR(i + RAND() * (j − i)). Argument n is used as the seed value. For equal argument values, RAND(n) returns the same value each time , and thus produces a repeatable sequence of column values.
Analyze Syntax
func.rand( <n>)
Analyze Examples
func.rand(1)
┌────────────────────┐
│ func.rand(1) │
├────────────────────┤
│ 0.7133693869548766 │
└────────────────────┘
SQL Syntax
RAND( <n>)
SQL Examples
SELECT RAND(1);
┌────────────────────┐
│ rand(1) │
├────────────────────┤
│ 0.7133693869548766 │
└────────────────────┘
5.16.38 - ROUND
Rounds the argument x to d decimal places. The rounding algorithm depends on the data type of x. d defaults to 0 if not specified. d can be negative to cause d digits left of the decimal point of the value x to become zero. The maximum absolute value for d is 30; any digits in excess of 30 (or -30) are truncated.
When using this function's result in calculations, be aware of potential precision issues due to its return data type being DOUBLE, which may affect final accuracy:
SELECT ROUND(4/7, 4) - ROUND(3/7, 4); -- Result: 0.14280000000000004
SELECT ROUND(4/7, 4)::DECIMAL(8,4) - ROUND(3/7, 4)::DECIMAL(8,4); -- Result: 0.1428
Analyze Syntax
func.round( <x, d> )
Analyze Examples
func.round(0.123, 2)
┌──────────────────────┐
│ func.round(0.123, 2) │
├──────────────────────┤
│ 0.12 │
└──────────────────────┘
SQL Syntax
ROUND( <x, d> )
SQL Examples
SELECT ROUND(0.123, 2);
┌─────────────────┐
│ round(0.123, 2) │
├─────────────────┤
│ 0.12 │
└─────────────────┘
5.16.39 - SIGN
Returns the sign of the argument as -1, 0, or 1, depending on whether x is negative, zero, or positive or NULL if the argument was NULL.
Analyze Syntax
func.sign( <x> )
Analyze Examples
func.sign(0)
┌──────────────┐
│ func.sign(0) │
├──────────────┤
│ 0 │
└──────────────┘
SQL Syntax
SIGN( <x> )
SQL Examples
SELECT SIGN(0);
┌─────────┐
│ sign(0) │
├─────────┤
│ 0 │
└─────────┘
5.16.40 - SIN
Returns the sine of x, where x is given in radians.
Analyze Syntax
func.sin( <x> )
Analyze Examples
func.sin(90)
┌────────────────────┐
│ func.sin(90) │
├────────────────────┤
│ 0.8939966636005579 │
└────────────────────┘
SQL Syntax
SIN( <x> )
SQL Examples
SELECT SIN(90);
┌────────────────────┐
│ sin(90) │
├────────────────────┤
│ 0.8939966636005579 │
└────────────────────┘
5.16.41 - SQRT
Returns the square root of a nonnegative number x. Returns Nan for negative input.
Analyze Syntax
func.sqrt( <x> )
Analyze Examples
func.sqrt(4)
┌──────────────┐
│ func.sqrt(4) │
├──────────────┤
│ 2 │
└──────────────┘
SQL Syntax
SQRT( <x> )
SQL Examples
SELECT SQRT(4);
┌─────────┐
│ sqrt(4) │
├─────────┤
│ 2 │
└─────────┘
5.16.42 - SUBTRACT
Alias for MINUS.
5.16.43 - TAN
Returns the tangent of x, where x is given in radians.
Analyze Syntax
func.tan( <x> )
Analyze Examples
func.tan(90)
┌────────────────────┐
│ func.tan(90) │
├────────────────────┤
│ -1.995200412208242 │
└────────────────────┘
SQL Syntax
TAN( <x> )
SQL Examples
SELECT TAN(90);
┌────────────────────┐
│ tan(90) │
├────────────────────┤
│ -1.995200412208242 │
└────────────────────┘
5.16.44 - TRUNCATE
Returns the number x, truncated to d decimal places. If d is 0, the result has no decimal point or fractional part. d can be negative to cause d digits left of the decimal point of the value x to become zero. The maximum absolute value for d is 30; any digits in excess of 30 (or -30) are truncated.
Analyze Syntax
func.truncate( <x, d> )
Analyze Examples
func.truncate(1.223, 1)
┌─────────────────────────┐
│ func.truncate(1.223, 1) │
├─────────────────────────┤
│ 1.2 │
└─────────────────────────┘
SQL Syntax
TRUNCATE( <x, d> )
SQL Examples
SELECT TRUNCATE(1.223, 1);
┌────────────────────┐
│ truncate(1.223, 1) │
├────────────────────┤
│ 1.2 │
└────────────────────┘
5.17 - Other Functions
Type Conversion Functions
Utility Functions
Others
5.17.1 - ASSUME_NOT_NULL
Results in an equivalent non-Nullable value for a Nullable type. In case the original value is NULL the result is undetermined.
Analyze Syntax
func.assume_not_null(<x>)
Analyze Examples
With a table like:
┌────────────────────┐
│ x │ y │
├────────────────────┤
│ 1 │ NULL │
│ 2 │ 3 │
└────────────────────┘
func.assume_not_null(y)
┌─────────────────────────┐
│ func.assume_not_null(y) │
├─────────────────────────┤
│ 0 │
│ 3 │
└─────────────────────────┘
SQL Syntax
ASSUME_NOT_NULL(<x>)
Aliases
Return Type
Returns the original datatype from the non-Nullable type; Returns the embedded non-Nullable datatype for Nullable type.
SQL Examples
CREATE TABLE default.t_null ( x int, y int null);
INSERT INTO default.t_null values (1, null), (2, 3);
SELECT ASSUME_NOT_NULL(y), REMOVE_NULLABLE(y) FROM t_null;
┌─────────────────────────────────────────┐
│ assume_not_null(y) │ remove_nullable(y) │
├────────────────────┼────────────────────┤
│ 0 │ 0 │
│ 3 │ 3 │
└─────────────────────────────────────────┘
5.17.2 - EXISTS
The exists condition is used in combination with a subquery and is considered "to be met" if the subquery returns at least one row.
SQL Syntax
WHERE EXISTS ( <subquery> );
SQL Examples
SELECT number FROM numbers(5) AS A WHERE exists (SELECT * FROM numbers(3) WHERE number=1);
+--------+
| number |
+--------+
| 0 |
| 1 |
| 2 |
| 3 |
| 4 |
+--------+
5.17.3 - GROUPING
Returns a bit mask indicating which GROUP BY expressions are not included in the current grouping set. Bits are assigned with the rightmost argument corresponding to the least-significant bit; each bit is 0 if the corresponding expression is included in the grouping criteria of the grouping set generating the current result row, and 1 if it is not included.
SQL Syntax
GROUPING ( expr [, expr, ...] )
GROUPING can only be used with GROUPING SETS, ROLLUP, or CUBE, and its arguments must be in the grouping sets list.Arguments
Grouping sets items.
Return Type
UInt32.
SQL Examples
select a, b, grouping(a), grouping(b), grouping(a,b), grouping(b,a) from t group by grouping sets ((a,b),(a),(b), ()) ;
+------+------+-------------+-------------+----------------+----------------+
| a | b | grouping(a) | grouping(b) | grouping(a, b) | grouping(b, a) |
+------+------+-------------+-------------+----------------+----------------+
| NULL | A | 1 | 0 | 2 | 1 |
| a | NULL | 0 | 1 | 1 | 2 |
| b | A | 0 | 0 | 0 | 0 |
| NULL | NULL | 1 | 1 | 3 | 3 |
| a | A | 0 | 0 | 0 | 0 |
| b | B | 0 | 0 | 0 | 0 |
| b | NULL | 0 | 1 | 1 | 2 |
| a | B | 0 | 0 | 0 | 0 |
| NULL | B | 1 | 0 | 2 | 1 |
+------+------+-------------+-------------+----------------+----------------+
5.17.4 - HUMANIZE_NUMBER
Returns a readable number.
Analyze Syntax
func.humanize_number(x);
Analyze Examples
func.humanize_number(1000 * 1000)
+-------------------------------------+
| func.humanize_number((1000 * 1000)) |
+-------------------------------------+
| 1 million |
+-------------------------------------+
SQL Syntax
HUMANIZE_NUMBER(x);
Arguments
| Arguments | Description |
|---|---|
| x | The numerical size. |
Return Type
String.
SQL Examples
SELECT HUMANIZE_NUMBER(1000 * 1000)
+-------------------------+
| HUMANIZE_NUMBER((1000 * 1000)) |
+-------------------------+
| 1 million |
+-------------------------+
5.17.5 - HUMANIZE_SIZE
Returns the readable size with a suffix(KiB, MiB, etc).
Analyze Syntax
func.humanize_size(x);
Analyze Examples
func.humanize_size(1024 * 1024)
+----------------------------------------+
| func.func.humanize_size((1024 * 1024)) |
+----------------------------------------+
| 1 MiB |
+----------------------------------------+
SQL Syntax
HUMANIZE_SIZE(x);
Arguments
| Arguments | Description |
|---|---|
| x | The numerical size. |
Return Type
String.
SQL Examples
SELECT HUMANIZE_SIZE(1024 * 1024)
+-------------------------+
| HUMANIZE_SIZE((1024 * 1024)) |
+-------------------------+
| 1 MiB |
+-------------------------+
5.17.6 - IGNORE
By using insert ignore statement, the rows with invalid data that cause the error are ignored and the rows with valid data are inserted into the table.
SQL Syntax
INSERT ignore INTO TABLE(column_list)
VALUES( value_list),
( value_list),
...
5.17.7 - REMOVE_NULLABLE
Alias for ASSUME_NOT_NULL.
5.17.8 - TO_NULLABLE
Converts a value to its nullable equivalent.
When you apply this function to a value, it checks if the value is already able to hold NULL values or not. If the value is already able to hold NULL values, the function will return the value without making any changes.
However, if the value is not able to hold NULL values, the TO_NULLABLE function will modify the value to make it able to hold NULL values. It does this by wrapping the value in a structure that can hold NULL values, which means the value can now hold NULL values in the future.
Analyze Syntax
func.to_nullable(x);
Analyze Examples
func.typeof(3), func.to_nullable(3), func.typeof(func.to_nullable(3))
func.typeof(3) | func.to_nullable(3) | func.typeof(func.to_nullable(3)) |
-----------------+---------------------+----------------------------------+
TINYINT UNSIGNED | 3 | TINYINT UNSIGNED NULL |
SQL Syntax
TO_NULLABLE(x);
Arguments
| Arguments | Description |
|---|---|
| x | The original value. |
Return Type
Returns a value of the same data type as the input value, but wrapped in a nullable container if the input value is not already nullable.
SQL Examples
SELECT typeof(3), TO_NULLABLE(3), typeof(TO_NULLABLE(3));
typeof(3) |to_nullable(3)|typeof(to_nullable(3))|
----------------+--------------+----------------------+
TINYINT UNSIGNED| 3|TINYINT UNSIGNED NULL |
5.17.9 - TYPEOF
TYPEOF function is used to return the name of a data type.
Analyze Syntax
func.typeof( <expr> )
Analyze Examples
func.typeof(1)
+------------------+
| func.typeof(1) |
+------------------+
| INT |
+------------------+
SQL Syntax
TYPEOF( <expr> )
Arguments
| Arguments | Description |
|---|---|
<expr> | Any expression. This may be a column name, the result of another function, or a math operation. |
Return Type
String
SQL Examples
SELECT typeof(1::INT);
+------------------+
| typeof(1::Int32) |
+------------------+
| INT |
+------------------+
5.18 - Search Functions
This section provides reference information for search functions in PlaidCloud Lakehouse.
5.18.1 - MATCH
Searches for documents containing specified keywords. Please note that the MATCH function can only be used in a WHERE clause.
:::info Databend's MATCH function is inspired by Elasticsearch's MATCH. :::
SQL Syntax
MATCH( '<columns>', '<keywords>'[, '<options>'] )
| Parameter | Description |
|---|---|
<columns> | A comma-separated list of column names in the table to search for the specified keywords, with optional weighting using the syntax (^), which allows assigning different weights to each column, influencing the importance of each column in the search. |
<keywords> | The keywords to match against the specified columns in the table. This parameter can also be used for suffix matching, where the search term followed by an asterisk (*) can match any number of characters or words. |
<options> | A set of configuration options, separated by semicolons ;, that customize the search behavior. See the table below for details. |
| Option | Description | Example | Explanation |
|---|---|---|---|
| fuzziness | Allows matching terms within a specified Levenshtein distance. fuzziness can be set to 1 or 2. | SELECT id, score(), content FROM t WHERE match(content, 'box', 'fuzziness=1'); | When matching the query term "box", fuzziness=1 allows matching terms like "fox", since "box" and "fox" have a Levenshtein distance of 1. |
| operator | Specifies how multiple query terms are combined. Can be set to OR (default) or AND. OR returns results containing any of the query terms, while AND returns results containing all query terms. | SELECT id, score(), content FROM t WHERE match(content, 'action works', 'fuzziness=1;operator=AND'); | With operator=AND, the query requires both "action" and "works" to be present in the results. Due to fuzziness=1, it matches terms like "Actions" and "words", so "Actions speak louder than words" is returned. |
| lenient | Controls whether errors are reported when the query text is invalid. Defaults to false. If set to true, no error is reported, and an empty result set is returned if the query text is invalid. | SELECT id, score(), content FROM t WHERE match(content, '()', 'lenient=true'); | If the query text () is invalid, setting lenient=true prevents an error from being thrown and returns an empty result set instead. |
SQL Examples
CREATE TABLE test(title STRING, body STRING);
CREATE INVERTED INDEX idx ON test(title, body);
INSERT INTO test VALUES
('The Importance of Reading', 'Reading is a crucial skill that opens up a world of knowledge and imagination.'),
('The Benefits of Exercise', 'Exercise is essential for maintaining a healthy lifestyle.'),
('The Power of Perseverance', 'Perseverance is the key to overcoming obstacles and achieving success.'),
('The Art of Communication', 'Effective communication is crucial in everyday life.'),
('The Impact of Technology on Society', 'Technology has revolutionized our society in countless ways.');
-- Retrieve documents where the 'title' column matches 'art power'
SELECT * FROM test WHERE MATCH('title', 'art power');
┌────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ title │ body │
├───────────────────────────┼────────────────────────────────────────────────────────────────────────┤
│ The Power of Perseverance │ Perseverance is the key to overcoming obstacles and achieving success. │
│ The Art of Communication │ Effective communication is crucial in everyday life. │
└────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- Retrieve documents where the 'title' column contains values that start with 'The' followed by any characters
SELECT * FROM test WHERE MATCH('title', 'The*')
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ title │ body │
│ Nullable(String) │ Nullable(String) │
├─────────────────────────────────────┼────────────────────────────────────────────────────────────────────────────────┤
│ The Importance of Reading │ Reading is a crucial skill that opens up a world of knowledge and imagination. │
│ The Benefits of Exercise │ Exercise is essential for maintaining a healthy lifestyle. │
│ The Power of Perseverance │ Perseverance is the key to overcoming obstacles and achieving success. │
│ The Art of Communication │ Effective communication is crucial in everyday life. │
│ The Impact of Technology on Society │ Technology has revolutionized our society in countless ways. │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- Retrieve documents where either the 'title' or 'body' column matches 'knowledge technology'
SELECT *, score() FROM test WHERE MATCH('title, body', 'knowledge technology');
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ title │ body │ score() │
├─────────────────────────────────────┼────────────────────────────────────────────────────────────────────────────────┼───────────┤
│ The Importance of Reading │ Reading is a crucial skill that opens up a world of knowledge and imagination. │ 1.1550591 │
│ The Impact of Technology on Society │ Technology has revolutionized our society in countless ways. │ 2.6830134 │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- Retrieve documents where either the 'title' or 'body' column matches 'knowledge technology', with weighted importance on both columns
SELECT *, score() FROM test WHERE MATCH('title^5, body^1.2', 'knowledge technology');
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ title │ body │ score() │
├─────────────────────────────────────┼────────────────────────────────────────────────────────────────────────────────┼───────────┤
│ The Importance of Reading │ Reading is a crucial skill that opens up a world of knowledge and imagination. │ 1.3860708 │
│ The Impact of Technology on Society │ Technology has revolutionized our society in countless ways. │ 7.8053584 │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- Retrieve documents where the 'body' column contains both "knowledge" and "imagination" (allowing for minor typos).
SELECT * FROM test WHERE MATCH('body', 'knowledg imaginatio', 'fuzziness = 1; operator = AND');
-[ RECORD 1 ]-----------------------------------
title: The Importance of Reading
body: Reading is a crucial skill that opens up a world of knowledge and imagination.
5.18.2 - QUERY
Searches for documents satisfying a specified query expression. Please note that the QUERY function can only be used in a WHERE clause.
:::info Databend's QUERY function is inspired by Elasticsearch's QUERY. :::
SQL Syntax
QUERY( '<query_expr>'[, '<options>'] )
The query expression supports the following syntaxes. Please note that <keyword> can also be used for suffix matching, where the search term followed by an asterisk (*) can match any number of characters or words.
| Syntax | Description | Examples |
|---|---|---|
<column>:<keyword> | Matches documents where the specified column contains the specified keyword. | QUERY('title:power') |
<column>:IN [<keyword1>, <keyword2>...] | Matches documents where the specified column contains any of the keywords listed within the square brackets. | QUERY('title:IN [power, art]') |
<column>:<keyword> AND / OR <keyword> | Matches documents where the specified column contains both or either of the specified keywords. In queries with both AND and OR, AND operations are prioritized over OR, meaning that 'a AND b OR c' is read as '(a AND b) OR c'. | QUERY('title:power AND art') |
<column>:+<keyword> -<keyword> | Matches documents where the specified positive keyword exists in the specified column and excludes documents where the specified negative keyword exists. | QUERY('title:+the -reading') |
<column>:"<phrase>" | Matches documents where the specified column contains the exact specified phrase. | QUERY('title:"Benefits of Exercise"') |
<column>:<keyword>^<boost> <column>:<keyword>^<boost> | Matches documents where the specified keyword exists in the specified columns with the specified boosts to increase their relevance in the search. This syntax allows setting different weights for multiple columns to influence the search relevance. | QUERY('title:art^5 body:reading^1.2') |
| Option | Description | Example | Explanation |
|---|---|---|---|
| fuzziness | Allows matching terms within a specified Levenshtein distance. fuzziness can be set to 1 or 2. | SELECT id, score(), content FROM t WHERE query('content:box', 'fuzziness=1'); | When matching the query term "box", fuzziness=1 allows matching terms like "fox", since "box" and "fox" have a Levenshtein distance of 1. |
| operator | Specifies how multiple query terms are combined. Can be set to OR (default) or AND. OR returns results containing any of the query terms, while AND returns results containing all query terms. | SELECT id, score(), content FROM t WHERE query('content:action works', 'fuzziness=1;operator=AND'); | With operator=AND, the query requires both "action" and "works" to be present in the results. Due to fuzziness=1, it matches terms like "Actions" and "words", so "Actions speak louder than words" is returned. |
| lenient | Controls whether errors are reported when the query text is invalid. Defaults to false. If set to true, no error is reported, and an empty result set is returned if the query text is invalid. | SELECT id, score(), content FROM t WHERE query('content:()', 'lenient=true'); | If the query text () is invalid, setting lenient=true prevents an error from being thrown and returns an empty result set instead. |
SQL Examples
CREATE TABLE test(title STRING, body STRING);
CREATE INVERTED INDEX idx ON test(title, body);
INSERT INTO test VALUES
('The Importance of Reading', 'Reading is a crucial skill that opens up a world of knowledge and imagination.'),
('The Benefits of Exercise', 'Exercise is essential for maintaining a healthy lifestyle.'),
('The Power of Perseverance', 'Perseverance is the key to overcoming obstacles and achieving success.'),
('The Art of Communication', 'Effective communication is crucial in everyday life.'),
('The Impact of Technology on Society', 'Technology has revolutionized our society in countless ways.');
-- Retrieve documents where the 'title' column contains the keyword 'power'
SELECT * FROM test WHERE QUERY('title:power');
┌────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ title │ body │
├───────────────────────────┼────────────────────────────────────────────────────────────────────────┤
│ The Power of Perseverance │ Perseverance is the key to overcoming obstacles and achieving success. │
└────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- Retrieve documents where the 'title' column contains values that start with 'The' followed by any characters
SELECT * FROM test WHERE QUERY('title:The*');
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ title │ body │
├─────────────────────────────────────┼────────────────────────────────────────────────────────────────────────────────┤
│ The Importance of Reading │ Reading is a crucial skill that opens up a world of knowledge and imagination. │
│ The Benefits of Exercise │ Exercise is essential for maintaining a healthy lifestyle. │
│ The Power of Perseverance │ Perseverance is the key to overcoming obstacles and achieving success. │
│ The Art of Communication │ Effective communication is crucial in everyday life. │
│ The Impact of Technology on Society │ Technology has revolutionized our society in countless ways. │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- Retrieve documents where the 'title' column contains either the keyword 'power' or 'art'
SELECT * FROM test WHERE QUERY('title:power OR art');
┌────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ title │ body │
├───────────────────────────┼────────────────────────────────────────────────────────────────────────┤
│ The Power of Perseverance │ Perseverance is the key to overcoming obstacles and achieving success. │
│ The Art of Communication │ Effective communication is crucial in everyday life. │
└────────────────────────────────────────────────────────────────────────────────────────────────────┘
SELECT * FROM test WHERE QUERY('title:IN [power, art]')
┌────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ title │ body │
│ Nullable(String) │ Nullable(String) │
├───────────────────────────┼────────────────────────────────────────────────────────────────────────┤
│ The Power of Perseverance │ Perseverance is the key to overcoming obstacles and achieving success. │
│ The Art of Communication │ Effective communication is crucial in everyday life. │
└────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- Retrieve documents where the 'title' column contains the positive keyword 'the' but not 'reading'
SELECT * FROM test WHERE QUERY('title:+the -reading');
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ title │ body │
├─────────────────────────────────────┼────────────────────────────────────────────────────────────────────────┤
│ The Benefits of Exercise │ Exercise is essential for maintaining a healthy lifestyle. │
│ The Power of Perseverance │ Perseverance is the key to overcoming obstacles and achieving success. │
│ The Art of Communication │ Effective communication is crucial in everyday life. │
│ The Impact of Technology on Society │ Technology has revolutionized our society in countless ways. │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- Retrieve documents where the 'title' column contains the exact phrase 'Benefits of Exercise'
SELECT * FROM test WHERE QUERY('title:"Benefits of Exercise"');
┌───────────────────────────────────────────────────────────────────────────────────────┐
│ title │ body │
├──────────────────────────┼────────────────────────────────────────────────────────────┤
│ The Benefits of Exercise │ Exercise is essential for maintaining a healthy lifestyle. │
└───────────────────────────────────────────────────────────────────────────────────────┘
-- Retrieve documents where the 'title' column contains the keyword 'art' with a boost of 5 and the 'body' column contains the keyword 'reading' with a boost of 1.2
SELECT *, score() FROM test WHERE QUERY('title:art^5 body:reading^1.2');
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ title │ body │ score() │
├───────────────────────────┼────────────────────────────────────────────────────────────────────────────────┼───────────┤
│ The Importance of Reading │ Reading is a crucial skill that opens up a world of knowledge and imagination. │ 1.3860708 │
│ The Art of Communication │ Effective communication is crucial in everyday life. │ 7.1992116 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- Retrieve documents where the 'body' column contains both "knowledge" and "imagination" (allowing for minor typos).
SELECT * FROM test WHERE QUERY('body:knowledg OR imaginatio', 'fuzziness = 1; operator = AND');
-[ RECORD 1 ]-----------------------------------
title: The Importance of Reading
body: Reading is a crucial skill that opens up a world of knowledge and imagination.
5.18.3 - SCORE
Returns the relevance of the query string. The higher the score, the more relevant the data. Please note that SCORE function can only be used with the QUERY or MATCH function.
:::info Databend's SCORE function is inspired by Elasticsearch's SCORE. :::
SQL Syntax
SCORE()
SQL Examples
CREATE TABLE test(title STRING, body STRING);
CREATE INVERTED INDEX idx ON test(title, body);
INSERT INTO test VALUES
('The Importance of Reading', 'Reading is a crucial skill that opens up a world of knowledge and imagination.'),
('The Benefits of Exercise', 'Exercise is essential for maintaining a healthy lifestyle.'),
('The Power of Perseverance', 'Perseverance is the key to overcoming obstacles and achieving success.'),
('The Art of Communication', 'Effective communication is crucial in everyday life.'),
('The Impact of Technology on Society', 'Technology has revolutionized our society in countless ways.');
-- Retrieve documents where the 'title' column contains the keyword 'art' with a boost of 5 and the 'body' column contains the keyword 'reading' with a boost of 1.2, along with their relevance scores
SELECT *, score() FROM test WHERE QUERY('title:art^5 body:reading^1.2');
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ title │ body │ score() │
├───────────────────────────┼────────────────────────────────────────────────────────────────────────────────┼───────────┤
│ The Importance of Reading │ Reading is a crucial skill that opens up a world of knowledge and imagination. │ 1.3860708 │
│ The Art of Communication │ Effective communication is crucial in everyday life. │ 7.1992116 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- Retrieve documents where the 'title' column contains the keyword 'reading' with a boost of 5 and the 'body' column contains the keyword 'everyday' with a boost of 1.2, along with their relevance scores
SELECT *, score() FROM test WHERE MATCH('title^5, body^1.2', 'reading everyday');
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ title │ body │ score() │
├───────────────────────────┼────────────────────────────────────────────────────────────────────────────────┼───────────┤
│ The Importance of Reading │ Reading is a crucial skill that opens up a world of knowledge and imagination. │ 8.585282 │
│ The Art of Communication │ Effective communication is crucial in everyday life. │ 1.8575745 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.19 - Semi-Structured Functions
This section provides reference information for the semi-structured data functions in PlaidCloud Lakehouse.
JSON Parsing, Conversion & Type Checking:
- CHECK_JSON
- JSON_PRETTY
- JSON_TYPEOF
- PARSE_JSON
- FLATTEN
- IS_ARRAY
- IS_BOOLEAN
- IS_FLOAT
- IS_INTEGER
- IS_NULL_VALUE
- IS_OBJECT
- IS_STRING
JSON Query and Extraction:
- JSON_ARRAY_ELEMENTS
- JSON_EACH
- JSON_EXTRACT_PATH_TEXT
- JSON_PATH_EXISTS
- JSON_PATH_MATCH
- JSON_PATH_QUERY
- JSON_PATH_QUERY_ARRAY
- JSON_PATH_QUERY_FIRST
JSON Data Manipulation:
Object Operations:
Type Conversion:
5.19.1 - AS_<type>
Strict casting VARIANT values to other data types.
If the input data type is not VARIANT, the output is NULL.
If the type of value in the VARIANT does not match the output value, the output is NULL.
Analyze Syntax
func.as_boolean( <variant> )
func.as_integer( <variant> )
func.as_float( <variant> )
func.as_string( <variant> )
func.as_array( <variant> )
func.as_object( <variant> )
SQL Syntax
AS_BOOLEAN( <variant> )
AS_INTEGER( <variant> )
AS_FLOAT( <variant> )
AS_STRING( <variant> )
AS_ARRAY( <variant> )
AS_OBJECT( <variant> )
Arguments
| Arguments | Description |
|---|---|
<variant> | The VARIANT value |
Return Type
- AS_BOOLEAN: BOOLEAN
- AS_INTEGER: BIGINT
- AS_FLOAT: DOUBLE
- AS_STRING: VARCHAR
- AS_ARRAY: Variant contains Array
- AS_OBJECT: Variant contains Object
SQL Examples
SELECT as_boolean(parse_json('true'));
+--------------------------------+
| as_boolean(parse_json('true')) |
+--------------------------------+
| 1 |
+--------------------------------+
SELECT as_integer(parse_json('123'));
+-------------------------------+
| as_integer(parse_json('123')) |
+-------------------------------+
| 123 |
+-------------------------------+
SELECT as_float(parse_json('12.34'));
+-------------------------------+
| as_float(parse_json('12.34')) |
+-------------------------------+
| 12.34 |
+-------------------------------+
SELECT as_string(parse_json('"abc"'));
+--------------------------------+
| as_string(parse_json('"abc"')) |
+--------------------------------+
| abc |
+--------------------------------+
SELECT as_array(parse_json('[1,2,3]'));
+---------------------------------+
| as_array(parse_json('[1,2,3]')) |
+---------------------------------+
| [1,2,3] |
+---------------------------------+
SELECT as_object(parse_json('{"k":"v","a":"b"}'));
+--------------------------------------------+
| as_object(parse_json('{"k":"v","a":"b"}')) |
+--------------------------------------------+
| {"k":"v","a":"b"} |
+--------------------------------------------+
5.19.2 - CHECK_JSON
Checks the validity of a JSON document.
If the input string is a valid JSON document or a NULL, the output is NULL.
If the input cannot be translated to a valid JSON value, the output string contains the error message.
Analyze Syntax
func.check_json(<expr>)
Analyze Example
func.check_json('[1,2,3]');
+----------------------------+
| func.check_json('[1,2,3]') |
+----------------------------+
| NULL |
+----------------------------+
SQL Syntax
CHECK_JSON( <expr> )
Arguments
| Arguments | Description |
|---|---|
<expr> | An expression of string type |
Return Type
String
SQL Examples
SELECT check_json('[1,2,3]');
+-----------------------+
| check_json('[1,2,3]') |
+-----------------------+
| NULL |
+-----------------------+
SELECT check_json('{"key":"val"}');
+-----------------------------+
| check_json('{"key":"val"}') |
+-----------------------------+
| NULL |
+-----------------------------+
SELECT check_json('{"key":');
+----------------------------------------------+
| check_json('{"key":') |
+----------------------------------------------+
| EOF while parsing a value at line 1 column 7 |
+----------------------------------------------+
5.19.3 - FLATTEN
Transforms nested JSON data into a tabular format, where each element or field is represented as a separate row.
SQL Syntax
[LATERAL] FLATTEN ( INPUT => <expr> [ , PATH => <expr> ]
[ , OUTER => TRUE | FALSE ]
[ , RECURSIVE => TRUE | FALSE ]
[ , MODE => 'OBJECT' | 'ARRAY' | 'BOTH' ] )
| Parameter / Keyword | Description | Default |
|---|---|---|
| INPUT | Specifies the JSON or array data to flatten. | - |
| PATH | Specifies the path to the array or object within the input data to flatten. | - |
| OUTER | If set to TRUE, rows with zero results will still be included in the output, but the values in the KEY, INDEX, and VALUE columns of those rows will be set to NULL. | FALSE |
| RECURSIVE | If set to TRUE, the function will continue to flatten nested elements. | FALSE |
| MODE | Controls whether to flatten only objects ('OBJECT'), only arrays ('ARRAY'), or both ('BOTH'). | 'BOTH' |
| LATERAL | LATERAL is an optional keyword used to reference columns defined to the left of the LATERAL keyword within the FROM clause. LATERAL enables cross-referencing between the preceding table expressions and the function. | - |
Output
The following table describes the output columns of the FLATTEN function:
| Column | Description |
|---|---|
| SEQ | A unique sequence number associated with the input. |
| KEY | Key to the expanded value. If the flattened element does not contain a key, it's set to NULL. |
| PATH | Path to the flattened element. |
| INDEX | If the element is an array, this column contains its index; otherwise, it's set to NULL. |
| VALUE | Value of the flattened element. |
| THIS | This column identifies the element currently being flattened. |
SQL Examples
SQL Examples 1: Demonstrating PATH, OUTER, RECURSIVE, and MODE Parameters
This example demonstrates the behavior of the FLATTEN function with respect to the PATH, OUTER, RECURSIVE, and MODE parameters.
SELECT
*
FROM
FLATTEN (
INPUT => PARSE_JSON (
'{"name": "John", "languages": ["English", "Spanish", "French"], "address": {"city": "New York", "state": "NY"}}'
)
);
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ seq │ key │ path │ index │ value │ this │
├────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────────────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ 1 │ address │ address │ NULL │ {"city":"New York","state":"NY"} │ {"address":{"city":"New York","state":"NY"},"languages":["English","Spanish","French"],"name":"John"} │
│ 1 │ languages │ languages │ NULL │ ["English","Spanish","French"] │ {"address":{"city":"New York","state":"NY"},"languages":["English","Spanish","French"],"name":"John"} │
│ 1 │ name │ name │ NULL │ "John" │ {"address":{"city":"New York","state":"NY"},"languages":["English","Spanish","French"],"name":"John"} │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- PATH helps in selecting elements at a specific path from the original JSON data.
SELECT
*
FROM
FLATTEN (
INPUT => PARSE_JSON (
'{"name": "John", "languages": ["English", "Spanish", "French"], "address": {"city": "New York", "state": "NY"}}'
),
PATH => 'languages'
);
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ seq │ key │ path │ index │ value │ this │
├────────┼──────────────────┼──────────────────┼──────────────────┼───────────────────┼────────────────────────────────┤
│ 1 │ NULL │ languages[0] │ 0 │ "English" │ ["English","Spanish","French"] │
│ 1 │ NULL │ languages[1] │ 1 │ "Spanish" │ ["English","Spanish","French"] │
│ 1 │ NULL │ languages[2] │ 2 │ "French" │ ["English","Spanish","French"] │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- RECURSIVE enables recursive flattening of nested structures.
SELECT
*
FROM
FLATTEN (
INPUT => PARSE_JSON (
'{"name": "John", "languages": ["English", "Spanish", "French"], "address": {"city": "New York", "state": "NY"}}'
),
RECURSIVE => TRUE
);
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ seq │ key │ path │ index │ value │ this │
├────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────────────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ 1 │ address │ address │ NULL │ {"city":"New York","state":"NY"} │ {"address":{"city":"New York","state":"NY"},"languages":["English","Spanish","French"],"name":"John"} │
│ 1 │ city │ address.city │ NULL │ "New York" │ {"city":"New York","state":"NY"} │
│ 1 │ state │ address.state │ NULL │ "NY" │ {"city":"New York","state":"NY"} │
│ 1 │ languages │ languages │ NULL │ ["English","Spanish","French"] │ {"address":{"city":"New York","state":"NY"},"languages":["English","Spanish","French"],"name":"John"} │
│ 1 │ NULL │ languages[0] │ 0 │ "English" │ ["English","Spanish","French"] │
│ 1 │ NULL │ languages[1] │ 1 │ "Spanish" │ ["English","Spanish","French"] │
│ 1 │ NULL │ languages[2] │ 2 │ "French" │ ["English","Spanish","French"] │
│ 1 │ name │ name │ NULL │ "John" │ {"address":{"city":"New York","state":"NY"},"languages":["English","Spanish","French"],"name":"John"} │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- MODE specifies whether only objects ('OBJECT'), only arrays ('ARRAY'), or both ('BOTH') should be flattened.
-- In this example, MODE => 'ARRAY' is used, which means that only arrays within the JSON data will be flattened.
SELECT
*
FROM
FLATTEN (
INPUT => PARSE_JSON (
'{"name": "John", "languages": ["English", "Spanish", "French"], "address": {"city": "New York", "state": "NY"}}'
),
MODE => 'ARRAY'
);
---
-- OUTER determines the inclusion of zero-row expansions in the output.
-- In this first example, OUTER => TRUE is used with an empty JSON array, which results in zero-row expansions.
-- Rows are included in the output even when there are no values to flatten.
SELECT
*
FROM
FLATTEN (INPUT => PARSE_JSON ('[]'), OUTER => TRUE);
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ seq │ key │ path │ index │ value │ this │
├────────┼──────────────────┼──────────────────┼──────────────────┼───────────────────┼───────────────────┤
│ 1 │ NULL │ NULL │ NULL │ NULL │ NULL │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- In this second example, OUTER is omitted, and the output shows how rows with zero results are not included when OUTER is not specified.
SELECT
*
FROM
FLATTEN (INPUT => PARSE_JSON ('[]'));
SQL Examples 2: Demonstrating LATERAL FLATTEN
This example demonstrates the behavior of the FLATTEN function when used in conjunction with the LATERAL keyword.
-- Create a table for Tim Hortons transactions with multiple items
CREATE TABLE tim_hortons_transactions (
transaction_id INT,
customer_id INT,
items VARIANT
);
-- Insert data for Tim Hortons transactions with multiple items
INSERT INTO tim_hortons_transactions (transaction_id, customer_id, items)
VALUES
(101, 1, parse_json('[{"item":"coffee", "price":2.50}, {"item":"donut", "price":1.20}]')),
(102, 2, parse_json('[{"item":"bagel", "price":1.80}, {"item":"muffin", "price":2.00}]')),
(103, 3, parse_json('[{"item":"timbit_assortment", "price":5.00}]'));
-- Show Tim Hortons transactions with multiple items using LATERAL FLATTEN
SELECT
t.transaction_id,
t.customer_id,
f.value:item::STRING AS purchased_item,
f.value:price::FLOAT AS price
FROM
tim_hortons_transactions t,
LATERAL FLATTEN(input => t.items) f;
┌───────────────────────────────────────────────────────────────────────────┐
│ transaction_id │ customer_id │ purchased_item │ price │
├─────────────────┼─────────────────┼───────────────────┼───────────────────┤
│ 101 │ 1 │ coffee │ 2.5 │
│ 101 │ 1 │ donut │ 1.2 │
│ 102 │ 2 │ bagel │ 1.8 │
│ 102 │ 2 │ muffin │ 2 │
│ 103 │ 3 │ timbit_assortment │ 5 │
└───────────────────────────────────────────────────────────────────────────┘
-- Find maximum, minimum, and average prices of the purchased items
SELECT
MAX(f.value:price::FLOAT) AS max_price,
MIN(f.value:price::FLOAT) AS min_price,
AVG(f.value:price::FLOAT) AS avg_price
FROM
tim_hortons_transactions t,
LATERAL FLATTEN(input => t.items) f;
┌───────────────────────────────────────────────────────────┐
│ max_price │ min_price │ avg_price │
├───────────────────┼───────────────────┼───────────────────┤
│ 5 │ 1.2 │ 2.5 │
└───────────────────────────────────────────────────────────┘
5.19.4 - GET
Extracts value from a Variant that contains ARRAY by index, or a Variant that contains OBJECT by field_name.
The value is returned as a Variant or NULL if either of the arguments is NULL.
GET applies case-sensitive matching to field_name. For case-insensitive matching, use GET_IGNORE_CASE.
Analyze Syntax
func.get(<variant>, <index>)
or
func.get(<variant>, <field_name>)
Analyze Example
func.get(func.parse_json('[2.71, 3.14]'), 0);
+----------------------------------------------+
| func.get(func.parse_json('[2.71, 3.14]'), 0) |
+----------------------------------------------+
| 2.71 |
+----------------------------------------------+
func.get(func.parse_json('{"aa":1, "aA":2, "Aa":3}'), 'aa');
+-------------------------------------------------------------+
| func.get(func.parse_json('{"aa":1, "aA":2, "Aa":3}'), 'aa') |
+-------------------------------------------------------------+
| 1 |
+-------------------------------------------------------------+
SQL Syntax
GET( <variant>, <index> )
GET( <variant>, <field_name> )
Arguments
| Arguments | Description |
|---|---|
<variant> | The VARIANT value that contains either an ARRAY or an OBJECT |
<index> | The Uint32 value specifies the position of the value in ARRAY |
<field_name> | The String value specifies the key in a key-value pair of OBJECT |
Return Type
VARIANT
SQL Examples
SELECT get(parse_json('[2.71, 3.14]'), 0);
+------------------------------------+
| get(parse_json('[2.71, 3.14]'), 0) |
+------------------------------------+
| 2.71 |
+------------------------------------+
SELECT get(parse_json('{"aa":1, "aA":2, "Aa":3}'), 'aa');
+---------------------------------------------------+
| get(parse_json('{"aa":1, "aA":2, "Aa":3}'), 'aa') |
+---------------------------------------------------+
| 1 |
+---------------------------------------------------+
SELECT get(parse_json('{"aa":1, "aA":2, "Aa":3}'), 'AA');
+---------------------------------------------------+
| get(parse_json('{"aa":1, "aA":2, "Aa":3}'), 'AA') |
+---------------------------------------------------+
| NULL |
+---------------------------------------------------+
5.19.5 - GET_IGNORE_CASE
Extracts value from a VARIANT that contains OBJECT by the field_name.
The value is returned as a Variant or NULL if either of the arguments is NULL.
GET_IGNORE_CASE is similar to GET but applies case-insensitive matching to field names.
First match the exact same field name, if not found, match the case-insensitive field name alphabetically.
Analyze Syntax
func.get_ignore_Case(<variant>, <field_name>)
Analyze Example
func.get_ignore_case(func.parse_json('{"aa":1, "aA":2, "Aa":3}'), 'AA')
+-------------------------------------------------------------------------+
| func.get_ignore_case(func.parse_json('{"aa":1, "aA":2, "Aa":3}'), 'AA') |
+-------------------------------------------------------------------------+
| 3 |
+-------------------------------------------------------------------------+
SQL Syntax
GET_IGNORE_CASE( <variant>, <field_name> )
Arguments
| Arguments | Description |
|---|---|
<variant> | The VARIANT value that contains either an ARRAY or an OBJECT |
<field_name> | The String value specifies the key in a key-value pair of OBJECT |
Return Type
VARIANT
SQL Examples
SELECT get_ignore_case(parse_json('{"aa":1, "aA":2, "Aa":3}'), 'AA');
+---------------------------------------------------------------+
| get_ignore_case(parse_json('{"aa":1, "aA":2, "Aa":3}'), 'AA') |
+---------------------------------------------------------------+
| 3 |
+---------------------------------------------------------------+
5.19.6 - GET_PATH
Extracts value from a VARIANT by path_name.
The value is returned as a Variant or NULL if either of the arguments is NULL.
GET_PATH is equivalent to a chain of GET functions, path_name consists of a concatenation of field names preceded by periods (.), colons (:) or index operators ([index]). The first field name does not require the leading identifier to be specified.
Analyze Syntax
func.get_path(<variant>, <path_name>)
Analyze Example
func.get_path(func.parse_json('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}'), 'k2.k4')
+---------------------------------------------------------------------------------+
| func.get_path(func.parse_json('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}'), 'k2.k4') |
+---------------------------------------------------------------------------------+
| 4 |
+---------------------------------------------------------------------------------+
SQL Syntax
GET_PATH( <variant>, <path_name> )
Arguments
| Arguments | Description |
|---|---|
<variant> | The VARIANT value that contains either an ARRAY or an OBJECT |
<path_name> | The String value that consists of a concatenation of field names |
Return Type
VARIANT
SQL Examples
SELECT get_path(parse_json('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}'), 'k1[0]');
+-----------------------------------------------------------------------+
| get_path(parse_json('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}'), 'k1[0]') |
+-----------------------------------------------------------------------+
| 0 |
+-----------------------------------------------------------------------+
SELECT get_path(parse_json('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}'), 'k2:k3');
+-----------------------------------------------------------------------+
| get_path(parse_json('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}'), 'k2:k3') |
+-----------------------------------------------------------------------+
| 3 |
+-----------------------------------------------------------------------+
SELECT get_path(parse_json('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}'), 'k2.k4');
+-----------------------------------------------------------------------+
| get_path(parse_json('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}'), 'k2.k4') |
+-----------------------------------------------------------------------+
| 4 |
+-----------------------------------------------------------------------+
SELECT get_path(parse_json('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}'), 'k2.k5');
+-----------------------------------------------------------------------+
| get_path(parse_json('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}'), 'k2.k5') |
+-----------------------------------------------------------------------+
| NULL |
+-----------------------------------------------------------------------+
5.19.7 - IS_ARRAY
Checks if the input value is a JSON array. Please note that a JSON array is not the same as the ARRAY data type. A JSON array is a data structure commonly used in JSON, representing an ordered collection of values enclosed within square brackets [ ]. It is a flexible format for organizing and exchanging various data types, including strings, numbers, booleans, objects, and nulls.
[
"Apple",
42,
true,
{"name": "John", "age": 30, "isStudent": false},
[1, 2, 3],
null
]
Analyze Syntax
func.is_array(<expr>)
Analyze Example
func.is_array(func.parse_json('true')), func.is_array(func.parse_json('[1,2,3]'))
┌────────────────────────────────────────────────────────────────────────────────────┐
│ func.is_array(func.parse_json('true')) │ func.is_array(func.parse_json('[1,2,3]')) │
├────────────────────────────────────────┼───────────────────────────────────────────┤
│ false │ true │
└────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
IS_ARRAY( <expr> )
Return Type
Returns true if the input value is a JSON array, and false otherwise.
SQL Examples
SELECT
IS_ARRAY(PARSE_JSON('true')),
IS_ARRAY(PARSE_JSON('[1,2,3]'));
┌────────────────────────────────────────────────────────────────┐
│ is_array(parse_json('true')) │ is_array(parse_json('[1,2,3]')) │
├──────────────────────────────┼─────────────────────────────────┤
│ false │ true │
└────────────────────────────────────────────────────────────────┘
5.19.8 - IS_BOOLEAN
Checks if the input JSON value is a boolean.
Analyze Syntax
func.is_boolean(<expr>)
Analyze Example
func.is_boolean(func.parse_json('true')), func.is_boolean(func.parse_json('[1,2,3]'))
┌────────────────────────────────────────────────────────────────────────────────────────┐
│ func.is_boolean(func.parse_json('true')) │ func.is_boolean(func.parse_json('[1,2,3]')) │
├──────────────────────────────────────────┼─────────────────────────────────────────────┤
│ true │ false │
└────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
IS_BOOLEAN( <expr> )
Return Type
Returns true if the input JSON value is a boolean, and false otherwise.
SQL Examples
SELECT
IS_BOOLEAN(PARSE_JSON('true')),
IS_BOOLEAN(PARSE_JSON('[1,2,3]'));
┌────────────────────────────────────────────────────────────────────┐
│ is_boolean(parse_json('true')) │ is_boolean(parse_json('[1,2,3]')) │
├────────────────────────────────┼───────────────────────────────────┤
│ true │ false │
└────────────────────────────────────────────────────────────────────┘
5.19.9 - IS_FLOAT
Checks if the input JSON value is a float.
Analyze Syntax
func.is_float(<expr>)
Analyze Example
func.is_float(func.parse_json('1.23')), func.is_float(func.parse_json('[1,2,3]'))
┌────────────────────────────────────────────────────────────────────────────────────────┐
│ func.is_float(func.parse_json('1.23')) │ func.is_float(func.parse_json('[1,2,3]')) │
├──────────────────────────────────────────┼─────────────────────────────────────────────┤
│ true │ false │
└────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
IS_FLOAT( <expr> )
Return Type
Returns true if the input JSON value is a float, and false otherwise.
SQL Examples
SELECT
IS_FLOAT(PARSE_JSON('1.23')),
IS_FLOAT(PARSE_JSON('[1,2,3]'));
┌────────────────────────────────────────────────────────────────┐
│ is_float(parse_json('1.23')) │ is_float(parse_json('[1,2,3]')) │
├──────────────────────────────┼─────────────────────────────────┤
│ true │ false │
└────────────────────────────────────────────────────────────────┘
5.19.10 - IS_INTEGER
Checks if the input JSON value is an integer.
Analyze Syntax
func.is_integer(<expr>)
Analyze Example
func.is_integer(func.parse_json('123')), func.is_integer(func.parse_json('[1,2,3]'))
┌────────────────────────────────────────────────────────────────────────────────────────┐
│ func.is_integer(func.parse_json('123')) │ func.is_integer(func.parse_json('[1,2,3]')) │
├──────────────────────────────────────────┼─────────────────────────────────────────────┤
│ true │ false │
└────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
IS_INTEGER( <expr> )
Return Type
Returns true if the input JSON value is an integer, and false otherwise.
SQL Examples
SELECT
IS_INTEGER(PARSE_JSON('123')),
IS_INTEGER(PARSE_JSON('[1,2,3]'));
┌───────────────────────────────────────────────────────────────────┐
│ is_integer(parse_json('123')) │ is_integer(parse_json('[1,2,3]')) │
├───────────────────────────────┼───────────────────────────────────┤
│ true │ false │
└───────────────────────────────────────────────────────────────────┘
5.19.11 - IS_NULL_VALUE
Checks whether the input value is a JSON null. Please note that this function examines JSON null, not SQL NULL. To check if a value is SQL NULL, use IS_NULL.
{
"name": "John",
"age": null
}
Analyze Syntax
func.is_null_value(<expr>)
Analyze Example
func.is_null_value(func.get_path(func.parse_json('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}'), 'k2.k5'))
┌─────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.is_null_value(func.get_path(func.parse_json('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}'), 'k2.k5')) │
├─────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ true │
└─────────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
IS_NULL_VALUE( <expr> )
Return Type
Returns true if the input value is a JSON null, and false otherwise.
SQL Examples
SELECT
IS_NULL_VALUE(PARSE_JSON('{"name":"John", "age":null}') :age), --JSON null
IS_NULL(NULL); --SQL NULL
┌──────────────────────────────────────────────────────────────────────────────┐
│ is_null_value(parse_json('{"name":"john", "age":null}'):age) │ is_null(null) │
├──────────────────────────────────────────────────────────────┼───────────────┤
│ true │ true │
└──────────────────────────────────────────────────────────────────────────────┘
5.19.12 - IS_OBJECT
Checks if the input value is a JSON object.
Analyze Syntax
func.is_object(<expr>)
Analyze Example
func.is_object(func.parse_json('{"a":"b"}')), func.is_object(func.parse_json('["a","b","c"]'))
┌──────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.is_object(func.parse_json('{"a":"b"}')) │ func.is_object(func.parse_json('["a","b","c"]')) │
├───────────────────────────────────────────────┼──────────────────────────────────────────────────┤
│ true │ false │
└──────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
IS_OBJECT( <expr> )
Return Type
Returns true if the input JSON value is a JSON object, and false otherwise.
SQL Examples
SELECT
IS_OBJECT(PARSE_JSON('{"a":"b"}')), -- JSON Object
IS_OBJECT(PARSE_JSON('["a","b","c"]')); --JSON Array
┌─────────────────────────────────────────────────────────────────────────────┐
│ is_object(parse_json('{"a":"b"}')) │ is_object(parse_json('["a","b","c"]')) │
├────────────────────────────────────┼────────────────────────────────────────┤
│ true │ false │
└─────────────────────────────────────────────────────────────────────────────┘
5.19.13 - IS_STRING
Checks if the input JSON value is a string.
Analyze Syntax
func.is_string(<expr>)
Analyze Example
func.is_string(func.parse_json('"abc"')), func.is_string(func.parse_json('123'))
┌──────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.is_string(func.parse_json('"abc"')) │ func.is_string(func.parse_json('123')) │
├───────────────────────────────────────────────┼──────────────────────────────────────────────────┤
│ true │ false │
└──────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
IS_STRING( <expr> )
Return Type
Returns true if the input JSON value is a string, and false otherwise.
SQL Examples
SELECT
IS_STRING(PARSE_JSON('"abc"')),
IS_STRING(PARSE_JSON('123'));
┌───────────────────────────────────────────────────────────────┐
│ is_string(parse_json('"abc"')) │ is_string(parse_json('123')) │
├────────────────────────────────┼──────────────────────────────┤
│ true │ false │
└───────────────────────────────────────────────────────────────┘
5.19.14 - JQ
The JQ function is a set-returning SQL function that allows you to apply jq filters to JSON data stored in Variant columns. With this function, you can process JSON data by applying a specified jq filter, returning the results as a set of rows.
SQL Syntax
JQ (<jq_expression>, <json_data>)
| Parameter | Description |
|---|---|
jq_expression | A jq filter expression that defines how to process and transform JSON data using the jq syntax. This expression can specify how to select, modify, and manipulate data within JSON objects and arrays. For information on the syntax, filters, and functions supported by jq, please refer to the jq Manual. |
json_data | The JSON-formatted input that you want to process or transform using the jq filter expression. It can be a JSON object, array, or any valid JSON data structure. |
Return Type
The JQ function returns a set of JSON values, where each value corresponds to an element of the transformed or extracted result based on the <jq_expression>.
SQL Examples
To start, we create a table named customer_data with columns for id and profile, where profile is a JSON type to store user information:
CREATE TABLE customer_data (
id INT,
profile JSON
);
INSERT INTO customer_data VALUES
(1, '{"name": "Alice", "age": 30, "city": "New York"}'),
(2, '{"name": "Bob", "age": 25, "city": "Los Angeles"}'),
(3, '{"name": "Charlie", "age": 35, "city": "Chicago"}');
This example extracts specific fields from the JSON data:
SELECT
id,
jq('.name', profile) AS customer_name
FROM
customer_data;
┌─────────────────────────────────────┐
│ id │ customer_name │
├─────────────────┼───────────────────┤
│ 1 │ "Alice" │
│ 2 │ "Bob" │
│ 3 │ "Charlie" │
└─────────────────────────────────────┘
This example selects the user ID and the age incremented by 1 for each user:
SELECT
id,
jq('.age + 1', profile) AS updated_age
FROM
customer_data;
┌─────────────────────────────────────┐
│ id │ updated_age │
├─────────────────┼───────────────────┤
│ 1 │ 31 │
│ 2 │ 26 │
│ 3 │ 36 │
└─────────────────────────────────────┘
This example converts city names to uppercase:
SELECT
id,
jq('.city | ascii_upcase', profile) AS city_uppercase
FROM
customer_data;
┌─────────────────────────────────────┐
│ id │ city_uppercase │
├─────────────────┼───────────────────┤
│ 1 │ "NEW YORK" │
│ 2 │ "LOS ANGELES" │
│ 3 │ "CHICAGO" │
└─────────────────────────────────────┘
5.19.15 - JSON_ARRAY
Creates a JSON array with specified values.
Analyze Syntax
func.json_array(value1[, value2[, ...]])
Analyze Example
func.json_array('fruits', func.json_array('apple', 'banana', 'orange'), func.json_object('price', 1.2, 'quantity', 3)) |
-----------------------------------------------------------------------------------------------------------------------+
["fruits",["apple","banana","orange"],{"price":1.2,"quantity":3}] |
SQL Syntax
JSON_ARRAY(value1[, value2[, ...]])
Return Type
JSON array.
SQL Examples
SQL Examples 1: Creating JSON Array with Constant Values or Expressions
SELECT JSON_ARRAY('PlaidCloud Lakehouse', 3.14, NOW(), TRUE, NULL);
json_array('databend', 3.14, now(), true, null) |
--------------------------------------------------------+
["PlaidCloud Lakehouse",3.14,"2023-09-06 07:23:55.399070",true,null]|
SELECT JSON_ARRAY('fruits', JSON_ARRAY('apple', 'banana', 'orange'), JSON_OBJECT('price', 1.2, 'quantity', 3));
json_array('fruits', json_array('apple', 'banana', 'orange'), json_object('price', 1.2, 'quantity', 3))|
-------------------------------------------------------------------------------------------------------+
["fruits",["apple","banana","orange"],{"price":1.2,"quantity":3}] |
SQL Examples 2: Creating JSON Array from Table Data
CREATE TABLE products (
ProductName VARCHAR(255),
Price DECIMAL(10, 2)
);
INSERT INTO products (ProductName, Price)
VALUES
('Apple', 1.2),
('Banana', 0.5),
('Orange', 0.8);
SELECT JSON_ARRAY(ProductName, Price) FROM products;
json_array(productname, price)|
------------------------------+
["Apple",1.2] |
["Banana",0.5] |
["Orange",0.8] |
5.19.16 - JSON_ARRAY_APPLY
Alias for JSON_ARRAY_TRANSFORM.
5.19.17 - JSON_ARRAY_DISTINCT
Removes duplicate elements from a JSON array and returns an array with only distinct elements.
SQL Syntax
JSON_ARRAY_DISTINCT(<json_array>)
Return Type
JSON array.
SQL Examples
SELECT JSON_ARRAY_DISTINCT('["apple", "banana", "apple", "orange", "banana"]'::VARIANT);
-[ RECORD 1 ]-----------------------------------
json_array_distinct('["apple", "banana", "apple", "orange", "banana"]'::VARIANT): ["apple","banana","orange"]
5.19.18 - JSON_ARRAY_ELEMENTS
Extracts the elements from a JSON array, returning them as individual rows in the result set. JSON_ARRAY_ELEMENTS does not recursively expand nested arrays; it treats them as single elements.
Analyze Syntax
func.json_array_elements(<json_string>)
Analyze Example
func.json_array_elements(func.parse_json('[ \n {"product": "laptop", "brand": "apple", "price": 1500},\n {"product": "smartphone", "brand": "samsung", "price": 800},\n {"product": "headphones", "brand": "sony", "price": 150}\n]'))
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.json_array_elements(func.parse_json('[ \n {"product": "laptop", "brand": "apple", "price": 1500},\n {"product": "smartphone", "brand": "samsung", "price": 800},\n {"product": "headphones", "brand": "sony", "price": 150}\n]')) │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ {"brand":"Apple","price":1500,"product":"Laptop"} │
│ {"brand":"Samsung","price":800,"product":"Smartphone"} │
│ {"brand":"Sony","price":150,"product":"Headphones"} │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
JSON_ARRAY_ELEMENTS(<json_string>)
Return Type
JSON_ARRAY_ELEMENTS returns a set of VARIANT values, each representing an element extracted from the input JSON array.
SQL Examples
-- Extract individual elements from a JSON array containing product information
SELECT
JSON_ARRAY_ELEMENTS(
PARSE_JSON (
'[
{"product": "Laptop", "brand": "Apple", "price": 1500},
{"product": "Smartphone", "brand": "Samsung", "price": 800},
{"product": "Headphones", "brand": "Sony", "price": 150}
]'
)
);
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ json_array_elements(parse_json('[ \n {"product": "laptop", "brand": "apple", "price": 1500},\n {"product": "smartphone", "brand": "samsung", "price": 800},\n {"product": "headphones", "brand": "sony", "price": 150}\n]')) │
├─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ {"brand":"Apple","price":1500,"product":"Laptop"} │
│ {"brand":"Samsung","price":800,"product":"Smartphone"} │
│ {"brand":"Sony","price":150,"product":"Headphones"} │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- Display data types of the extracted elements
SELECT
TYPEOF (
JSON_ARRAY_ELEMENTS(
PARSE_JSON (
'[
{"product": "Laptop", "brand": "Apple", "price": 1500},
{"product": "Smartphone", "brand": "Samsung", "price": 800},
{"product": "Headphones", "brand": "Sony", "price": 150}
]'
)
)
);
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ typeof(json_array_elements(parse_json('[ \n {"product": "laptop", "brand": "apple", "price": 1500},\n {"product": "smartphone", "brand": "samsung", "price": 800},\n {"product": "headphones", "brand": "sony", "price": 150}\n]'))) │
├─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ VARIANT NULL │
│ VARIANT NULL │
│ VARIANT NULL │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.19.19 - JSON_ARRAY_EXCEPT
Returns a new JSON array containing the elements from the first JSON array that are not present in the second JSON array.
SQL Syntax
JSON_ARRAY_EXCEPT(<json_array1>, <json_array2>)
Return Type
JSON array.
SQL Examples
SELECT JSON_ARRAY_EXCEPT(
'["apple", "banana", "orange"]'::JSON,
'["banana", "grapes"]'::JSON
);
-[ RECORD 1 ]-----------------------------------
json_array_except('["apple", "banana", "orange"]'::VARIANT, '["banana", "grapes"]'::VARIANT): ["apple","orange"]
-- Return an empty array because all elements in the first array are present in the second array.
SELECT json_array_except('["apple", "banana", "orange"]'::VARIANT, '["apple", "banana", "orange"]'::VARIANT)
-[ RECORD 1 ]-----------------------------------
json_array_except('["apple", "banana", "orange"]'::VARIANT, '["apple", "banana", "orange"]'::VARIANT): []
5.19.20 - JSON_ARRAY_FILTER
Filters elements from a JSON array based on a specified Lambda expression, returning only the elements that satisfy the condition. For more information about Lambda expression, see Lambda Expressions.
SQL Syntax
JSON_ARRAY_FILTER(<json_array>, <lambda_expression>)
Return Type
JSON array.
SQL Examples
This example filters the array to return only the strings that start with the letter a, resulting in ["apple", "avocado"]:
SELECT JSON_ARRAY_FILTER(
['apple', 'banana', 'avocado', 'grape']::JSON,
d -> d::String LIKE 'a%'
);
-[ RECORD 1 ]-----------------------------------
json_array_filter(['apple', 'banana', 'avocado', 'grape']::VARIANT, d -> d::STRING LIKE 'a%'): ["apple","avocado"]
5.19.21 - JSON_ARRAY_INSERT
Inserts a value into a JSON array at the specified index and returns the updated JSON array.
SQL Syntax
JSON_ARRAY_INSERT(<json_array>, <index>, <json_value>)
| Parameter | Description |
|---|---|
<json_array> | The JSON array to modify. |
<index> | The position at which the value will be inserted. Positive indices insert at the specified position or append if out of range; negative indices insert from the end or at the beginning if out of range. |
<json_value> | The JSON value to insert into the array. |
Return Type
JSON array.
SQL Examples
When the <index> is a non-negative integer, the new element is inserted at the specified position, and existing elements are shifted to the right.
-- The new element is inserted at position 0 (the beginning of the array), shifting all original elements to the right
SELECT JSON_ARRAY_INSERT('["task1", "task2", "task3"]'::VARIANT, 0, '"new_task"'::VARIANT);
-[ RECORD 1 ]-----------------------------------
json_array_insert('["task1", "task2", "task3"]'::VARIANT, 0, '"new_task"'::VARIANT): ["new_task","task1","task2","task3"]
-- The new element is inserted at position 1, between task1 and task2
SELECT JSON_ARRAY_INSERT('["task1", "task2", "task3"]'::VARIANT, 1, '"new_task"'::VARIANT);
-[ RECORD 1 ]-----------------------------------
json_array_insert('["task1", "task2", "task3"]'::VARIANT, 1, '"new_task"'::VARIANT): ["task1","new_task","task2","task3"]
-- If the index exceeds the length of the array, the new element is appended at the end of the array
SELECT JSON_ARRAY_INSERT('["task1", "task2", "task3"]'::VARIANT, 6, '"new_task"'::VARIANT);
-[ RECORD 1 ]-----------------------------------
json_array_insert('["task1", "task2", "task3"]'::VARIANT, 6, '"new_task"'::VARIANT): ["task1","task2","task3","new_task"]
A negative <index> counts from the end of the array, with -1 representing the position before the last element, -2 before the second last, and so on.
-- The new element is inserted just before the last element (task3)
SELECT JSON_ARRAY_INSERT('["task1", "task2", "task3"]'::VARIANT, -1, '"new_task"'::VARIANT);
-[ RECORD 1 ]-----------------------------------
json_array_insert('["task1", "task2", "task3"]'::VARIANT, - 1, '"new_task"'::VARIANT): ["task1","task2","new_task","task3"]
-- Since the negative index exceeds the array’s length, the new element is inserted at the beginning
SELECT JSON_ARRAY_INSERT('["task1", "task2", "task3"]'::VARIANT, -6, '"new_task"'::VARIANT);
-[ RECORD 1 ]-----------------------------------
json_array_insert('["task1", "task2", "task3"]'::VARIANT, - 6, '"new_task"'::VARIANT): ["new_task","task1","task2","task3"]
5.19.22 - JSON_ARRAY_INTERSECTION
Returns the common elements between two JSON arrays.
SQL Syntax
JSON_ARRAY_INTERSECTION(<json_array1>, <json_array2>)
Return Type
JSON array.
SQL Examples
-- Find the intersection of two JSON arrays
SELECT json_array_intersection('["Electronics", "Books", "Toys"]'::JSON, '["Books", "Fashion", "Electronics"]'::JSON);
-[ RECORD 1 ]-----------------------------------
json_array_intersection('["Electronics", "Books", "Toys"]'::VARIANT, '["Books", "Fashion", "Electronics"]'::VARIANT): ["Electronics","Books"]
-- Find the intersection of the result from the first query with a third JSON array using an iterative approach
SELECT json_array_intersection(
json_array_intersection('["Electronics", "Books", "Toys"]'::JSON, '["Books", "Fashion", "Electronics"]'::JSON),
'["Electronics", "Books", "Clothing"]'::JSON
);
-[ RECORD 1 ]-----------------------------------
json_array_intersection(json_array_intersection('["Electronics", "Books", "Toys"]'::VARIANT, '["Books", "Fashion", "Electronics"]'::VARIANT), '["Electronics", "Books", "Clothing"]'::VARIANT): ["Electronics","Books"]
5.19.23 - JSON_ARRAY_MAP
Alias for JSON_ARRAY_TRANSFORM.
5.19.24 - JSON_ARRAY_OVERLAP
Checks if there is any overlap between two JSON arrays and returns true if there are common elements; otherwise, it returns false.
SQL Syntax
JSON_ARRAY_OVERLAP(<json_array1>, <json_array2>)
Return Type
The function returns a boolean value:
trueif there is at least one common element between the two JSON arrays,falseif there are no common elements.
SQL Examples
SELECT json_array_overlap(
'["apple", "banana", "cherry"]'::JSON,
'["banana", "kiwi", "mango"]'::JSON
);
-[ RECORD 1 ]-----------------------------------
json_array_overlap('["apple", "banana", "cherry"]'::VARIANT, '["banana", "kiwi", "mango"]'::VARIANT): true
SELECT json_array_overlap(
'["grape", "orange"]'::JSON,
'["apple", "kiwi"]'::JSON
);
-[ RECORD 1 ]-----------------------------------
json_array_overlap('["grape", "orange"]'::VARIANT, '["apple", "kiwi"]'::VARIANT): false
5.19.25 - JSON_ARRAY_REDUCE
Reduces a JSON array to a single value by applying a specified Lambda expression. For more information about Lambda expression, see Lambda Expressions.
SQL Syntax
JSON_ARRAY_REDUCE(<json_array>, <lambda_expression>)
SQL Examples
This example multiplies all the elements in the array (2 _ 3 _ 4):
SELECT JSON_ARRAY_REDUCE(
[2, 3, 4]::JSON,
(acc, d) -> acc::Int * d::Int
);
-[ RECORD 1 ]-----------------------------------
json_array_reduce([2, 3, 4]::VARIANT, (acc, d) -> acc::Int32 * d::Int32): 24
5.19.26 - JSON_ARRAY_TRANSFORM
Transforms each element of a JSON array using a specified transformation Lambda expression. For more information about Lambda expression, see Lambda Expressions.
SQL Syntax
JSON_ARRAY_TRANSFORM(<json_array>, <lambda_expression>)
Aliases
Return Type
JSON array.
SQL Examples
In this example, each numeric element in the array is multiplied by 10, transforming the original array into [10, 20, 30, 40]:
SELECT JSON_ARRAY_TRANSFORM(
[1, 2, 3, 4]::JSON,
data -> (data::Int * 10)
);
-[ RECORD 1 ]-----------------------------------
json_array_transform([1, 2, 3, 4]::VARIANT, data -> data::Int32 * 10): [10,20,30,40]
5.19.27 - JSON_EACH
Extracts key-value pairs from a JSON object, breaking down the structure into individual rows in the result set. Each row represents a distinct key-value pair derived from the input JSON expression.
Analyze Syntax
func.json_each(<json_string>)
Analyze Example
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.json_each(func.parse_json('{"name": "john", "age": 25, "isstudent": false, "grades": [90, 85, 92]}')) │
├────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ ('age','25') │
│ ('grades','[90,85,92]') │
│ ('isStudent','false') │
│ ('name','"John"') │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
JSON_EACH(<json_string>)
Return Type
JSON_EACH returns a set of tuples, each consisting of a STRING key and a corresponding VARIANT value.
SQL Examples
-- Extract key-value pairs from a JSON object representing information about a person
SELECT
JSON_EACH(
PARSE_JSON (
'{"name": "John", "age": 25, "isStudent": false, "grades": [90, 85, 92]}'
)
);
┌──────────────────────────────────────────────────────────────────────────────────────────────────┐
│ json_each(parse_json('{"name": "john", "age": 25, "isstudent": false, "grades": [90, 85, 92]}')) │
├──────────────────────────────────────────────────────────────────────────────────────────────────┤
│ ('age','25') │
│ ('grades','[90,85,92]') │
│ ('isStudent','false') │
│ ('name','"John"') │
└──────────────────────────────────────────────────────────────────────────────────────────────────┘
-- Display data types of the extracted values
SELECT
TYPEOF (
JSON_EACH(
PARSE_JSON (
'{"name": "John", "age": 25, "isStudent": false, "grades": [90, 85, 92]}'
)
)
);
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ typeof(json_each(parse_json('{"name": "john", "age": 25, "isstudent": false, "grades": [90, 85, 92]}'))) │
├──────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ TUPLE(STRING, VARIANT) NULL │
│ TUPLE(STRING, VARIANT) NULL │
│ TUPLE(STRING, VARIANT) NULL │
│ TUPLE(STRING, VARIANT) NULL │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.19.28 - JSON_EXTRACT_PATH_TEXT
Extracts value from a Json string by path_name.
The value is returned as a String or NULL if either of the arguments is NULL.
This function is equivalent to to_varchar(GET_PATH(PARSE_JSON(JSON), PATH_NAME)).
Analyze Syntax
func.json_extract_path_text(<expr>, <path_name>)
Analyze Example
func.json_extract_path_text('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}', 'k2.k4')
+------------------------------------------------------------------------------+
| func.json_extract_path_text('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}', 'k2.k4') |
+------------------------------------------------------------------------------+
| 4 |
+------------------------------------------------------------------------------+
SQL Syntax
JSON_EXTRACT_PATH_TEXT( <expr>, <path_name> )
Arguments
| Arguments | Description |
|---|---|
<expr> | The Json String value |
<path_name> | The String value that consists of a concatenation of field names |
Return Type
String
SQL Examples
SELECT json_extract_path_text('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}', 'k1[0]');
+-------------------------------------------------------------------------+
| json_extract_path_text('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}', 'k1[0]') |
+-------------------------------------------------------------------------+
| 0 |
+-------------------------------------------------------------------------+
SELECT json_extract_path_text('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}', 'k2:k3');
+-------------------------------------------------------------------------+
| json_extract_path_text('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}', 'k2:k3') |
+-------------------------------------------------------------------------+
| 3 |
+-------------------------------------------------------------------------+
SELECT json_extract_path_text('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}', 'k2.k4');
+-------------------------------------------------------------------------+
| json_extract_path_text('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}', 'k2.k4') |
+-------------------------------------------------------------------------+
| 4 |
+-------------------------------------------------------------------------+
SELECT json_extract_path_text('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}', 'k2.k5');
+-------------------------------------------------------------------------+
| json_extract_path_text('{"k1":[0,1,2], "k2":{"k3":3,"k4":4}}', 'k2.k5') |
+-------------------------------------------------------------------------+
| NULL |
+-------------------------------------------------------------------------+
5.19.29 - JSON_MAP_FILTER
Filters key-value pairs in a JSON object based on a specified condition, defined using a lambda expression.
SQL Syntax
JSON_MAP_FILTER(<json_object>, (<key>, <value>) -> <condition>)
Return Type
Returns a JSON object with only the key-value pairs that satisfy the specified condition.
SQL Examples
This example extracts only the "status": "active" key-value pair from the JSON object, filtering out the other fields:
SELECT JSON_MAP_FILTER('{"status":"active", "user":"admin", "time":"2024-11-01"}'::VARIANT, (k, v) -> k = 'status') AS filtered_metadata;
┌─────────────────────┐
│ filtered_metadata │
├─────────────────────┤
│ {"status":"active"} │
└─────────────────────┘
5.19.30 - JSON_MAP_TRANSFORM_KEYS
Applies a transformation to each key in a JSON object using a lambda expression.
SQL Syntax
JSON_MAP_TRANSFORM_KEYS(<json_object>, (<key>, <value>) -> <key_transformation>)
Return Type
Returns a JSON object with the same values as the input JSON object, but with keys modified according to the specified lambda transformation.
SQL Examples
This example appends "_v1" to each key, creating a new JSON object with modified keys:
SELECT JSON_MAP_TRANSFORM_KEYS('{"name":"John", "role":"admin"}'::VARIANT, (k, v) -> CONCAT(k, '_v1')) AS versioned_metadata;
┌──────────────────────────────────────┐
│ versioned_metadata │
├──────────────────────────────────────┤
│ {"name_v1":"John","role_v1":"admin"} │
└──────────────────────────────────────┘
5.19.31 - JSON_MAP_TRANSFORM_VALUES
Applies a transformation to each value in a JSON object using a lambda expression.
SQL Syntax
JSON_MAP_TRANSFORM_VALUES(<json_object>, (<key>, <value>) -> <value_transformation>)
Return Type
Returns a JSON object with the same keys as the input JSON object, but with values modified according to the specified lambda transformation.
SQL Examples
This example appends " - Special Offer" to each product description:
SELECT JSON_MAP_TRANSFORM_VALUES('{"product1":"laptop", "product2":"phone"}'::VARIANT, (k, v) -> CONCAT(v, ' - Special Offer')) AS promo_descriptions;
┌──────────────────────────────────────────────────────────────────────────┐
│ promo_descriptions │
├──────────────────────────────────────────────────────────────────────────┤
│ {"product1":"laptop - Special Offer","product2":"phone - Special Offer"} │
└──────────────────────────────────────────────────────────────────────────┘
5.19.32 - JSON_OBJECT_DELETE
Deletes specified keys from a JSON object and returns the modified object. If a specified key doesn't exist in the object, it is ignored.
SQL Syntax
json_object_delete(<json_object>, <key1> [, <key2>, ...])
Parameters
| Parameter | Description |
|---|---|
| json_object | A JSON object (VARIANT type) from which to delete keys. |
| key1, key2, ... | One or more string literals representing the keys to be deleted from the object. |
Return Type
Returns a VARIANT containing the modified JSON object with specified keys removed.
SQL Examples
Delete a single key:
SELECT json_object_delete('{"a":1,"b":2,"c":3}'::VARIANT, 'a');
-- Result: {"b":2,"c":3}
Delete multiple keys:
SELECT json_object_delete('{"a":1,"b":2,"d":4}'::VARIANT, 'a', 'c');
-- Result: {"b":2,"d":4}
Delete a non-existent key (key is ignored):
SELECT json_object_delete('{"a":1,"b":2}'::VARIANT, 'x');
-- Result: {"a":1,"b":2}
5.19.33 - JSON_OBJECT_INSERT
Inserts or updates a key-value pair in a JSON object.
SQL Syntax
JSON_OBJECT_INSERT(<json_object>, <key>, <value>[, <update_flag>])
| Parameter | Description | |
|---|---|---|
<json_object> | The input JSON object. | |
<key> | The key to be inserted or updated. | |
<value> | The value to assign to the key. | |
<update_flag> | A boolean flag that controls whether to replace the value if the specified key already exists in the JSON object. If true, the function replaces the value if the key already exists. If false (or omitted), an error occurs if the key exists. |
Return Type
Returns the updated JSON object.
SQL Examples
This example demonstrates how to insert a new key 'c' with the value 3 into the existing JSON object:
SELECT JSON_OBJECT_INSERT('{"a":1,"b":2,"d":4}'::variant, 'c', 3);
┌────────────────────────────────────────────────────────────┐
│ json_object_insert('{"a":1,"b":2,"d":4}'::VARIANT, 'c', 3) │
├────────────────────────────────────────────────────────────┤
│ {"a":1,"b":2,"c":3,"d":4} │
└────────────────────────────────────────────────────────────┘
This example shows how to update the value of an existing key 'a' from 1 to 10 using the update flag set to true, allowing the key's value to be replaced:
SELECT JSON_OBJECT_INSERT('{"a":1,"b":2,"d":4}'::variant, 'a', 10, true);
┌───────────────────────────────────────────────────────────────────┐
│ json_object_insert('{"a":1,"b":2,"d":4}'::VARIANT, 'a', 10, TRUE) │
├───────────────────────────────────────────────────────────────────┤
│ {"a":10,"b":2,"d":4} │
└───────────────────────────────────────────────────────────────────┘
This example demonstrates an error that occurs when trying to insert a value for an existing key 'a' without specifying the update flag set to true:
SELECT JSON_OBJECT_INSERT('{"a":1,"b":2,"d":4}'::variant, 'a', 10);
error: APIError: ResponseError with 1006: ObjectDuplicateKey while evaluating function `json_object_insert('{"a":1,"b":2,"d":4}', 'a', 10)` in expr `json_object_insert('{"a":1,"b":2,"d":4}', 'a', 10)`
5.19.34 - JSON_OBJECT_KEEP_NULL
Creates a JSON object with keys and values.
- The arguments are zero or more key-value pairs(where keys are strings, and values are of any type).
- If a key is NULL, the key-value pair is omitted from the resulting object. However, if a value is NULL, the key-value pair will be kept.
- The keys must be distinct from each other, and their order in the resulting JSON might be different from the order you specify.
TRY_JSON_OBJECT_KEEP_NULLreturns a NULL value if an error occurs when building the object.
See also: JSON_OBJECT
SQL Syntax
JSON_OBJECT_KEEP_NULL(key1, value1[, key2, value2[, ...]])
TRY_JSON_OBJECT_KEEP_NULL(key1, value1[, key2, value2[, ...]])
Return Type
JSON object.
SQL Examples
SELECT JSON_OBJECT_KEEP_NULL();
┌─────────────────────────┐
│ json_object_keep_null() │
├─────────────────────────┤
│ {} │
└─────────────────────────┘
SELECT JSON_OBJECT_KEEP_NULL('a', 3.14, 'b', 'xx', 'c', NULL);
┌────────────────────────────────────────────────────────┐
│ json_object_keep_null('a', 3.14, 'b', 'xx', 'c', null) │
├────────────────────────────────────────────────────────┤
│ {"a":3.14,"b":"xx","c":null} │
└────────────────────────────────────────────────────────┘
SELECT JSON_OBJECT_KEEP_NULL('fruits', ['apple', 'banana', 'orange'], 'vegetables', ['carrot', 'celery']);
┌────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ json_object_keep_null('fruits', ['apple', 'banana', 'orange'], 'vegetables', ['carrot', 'celery']) │
├────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ {"fruits":["apple","banana","orange"],"vegetables":["carrot","celery"]} │
└────────────────────────────────────────────────────────────────────────────────────────────────────┘
SELECT JSON_OBJECT_KEEP_NULL('key');
|
1 | SELECT JSON_OBJECT_KEEP_NULL('key')
| ^^^^^^^^^^^^^^^^^^ The number of keys and values must be equal while evaluating function `json_object_keep_null('key')`
SELECT TRY_JSON_OBJECT_KEEP_NULL('key');
┌──────────────────────────────────┐
│ try_json_object_keep_null('key') │
├──────────────────────────────────┤
│ NULL │
└──────────────────────────────────┘
5.19.35 - JSON_OBJECT_KEYS
Returns an Array containing the list of keys in the input Variant OBJECT.
Analyze Syntax
func.json_object_keys(<variant>)
Analyze Example
func.json_object_keys(func.parse_json(parse_json('{"a": 1, "b": [1,2,3]}')), func.json_object_keys(func.parse_json(parse_json('{"b": [2,3,4]}'))
┌─────────────────────────────────────────────────────────────────┐
│ id │ json_object_keys(var) │ json_object_keys(var) │
├────────────────┼────────────────────────┼───────────────────────┤
│ 1 │ ["a","b"] │ ["a","b"] │
│ 2 │ ["b"] │ ["b"] │
└─────────────────────────────────────────────────────────────────┘
SQL Syntax
JSON_OBJECT_KEYS(<variant>)
Arguments
| Arguments | Description |
|---|---|
<variant> | The VARIANT value that contains an OBJECT |
Aliases
Return Type
Array<String>
SQL Examples
CREATE TABLE IF NOT EXISTS objects_test1(id TINYINT, var VARIANT);
INSERT INTO
objects_test1
VALUES
(1, parse_json('{"a": 1, "b": [1,2,3]}'));
INSERT INTO
objects_test1
VALUES
(2, parse_json('{"b": [2,3,4]}'));
SELECT
id,
object_keys(var),
json_object_keys(var)
FROM
objects_test1;
┌────────────────────────────────────────────────────────────┐
│ id │ object_keys(var) │ json_object_keys(var) │
├────────────────┼───────────────────┼───────────────────────┤
│ 1 │ ["a","b"] │ ["a","b"] │
│ 2 │ ["b"] │ ["b"] │
└────────────────────────────────────────────────────────────┘
5.19.36 - JSON_OBJECT_PICK
Creates a new JSON object containing only the specified keys from the input JSON object. If a specified key doesn't exist in the input object, it is omitted from the result.
SQL Syntax
json_object_pick(<json_object>, <key1> [, <key2>, ...])
Parameters
| Parameter | Description |
|---|---|
| json_object | A JSON object (VARIANT type) from which to pick keys. |
| key1, key2, ... | One or more string literals representing the keys to be included in the result object. |
Return Type
Returns a VARIANT containing a new JSON object with only the specified keys and their corresponding values.
SQL Examples
Pick a single key:
SELECT json_object_pick('{"a":1,"b":2,"c":3}'::VARIANT, 'a');
-- Result: {"a":1}
Pick multiple keys:
SELECT json_object_pick('{"a":1,"b":2,"d":4}'::VARIANT, 'a', 'b');
-- Result: {"a":1,"b":2}
Pick with non-existent key (non-existent keys are ignored):
SELECT json_object_pick('{"a":1,"b":2,"d":4}'::VARIANT, 'a', 'c');
-- Result: {"a":1}
5.19.37 - JSON_PATH_EXISTS
Checks whether a specified path exists in JSON data.
Analyze Syntax
func.json_path_exists(<json_data>, <json_path_expression)
Analyze Example
func.json_path_exists(parse_json('{"a": 1, "b": 2}'), '$.a ? (@ == 1)'), func.json_path_exists(parse_json('{"a": 1, "b": 2}'), '$.a ? (@ > 1)')
┌─────────────────────────────┐
│ Item 1 │ Item 2 │
├────────────────┼────────────┤
│ True │ False │
└─────────────────────────────┘
SQL Syntax
JSON_PATH_EXISTS(<json_data>, <json_path_expression>)
json_data: Specifies the JSON data you want to search within. It can be a JSON object or an array.
json_path_expression: Specifies the path, starting from the root of the JSON data represented by
$, that you want to check within the JSON data. You can also include conditions within the expression, using@to refer to the current node or element being evaluated, to filter the results.
Return Type
The function returns:
trueif the specified JSON path (and conditions if any) exists within the JSON data.falseif the specified JSON path (and conditions if any) does not exist within the JSON data.- NULL if either the json_data or json_path_expression is NULL or invalid.
SQL Examples
SELECT JSON_PATH_EXISTS(parse_json('{"a": 1, "b": 2}'), '$.a ? (@ == 1)');
----
true
SELECT JSON_PATH_EXISTS(parse_json('{"a": 1, "b": 2}'), '$.a ? (@ > 1)');
----
false
SELECT JSON_PATH_EXISTS(NULL, '$.a');
----
NULL
SELECT JSON_PATH_EXISTS(parse_json('{"a": 1, "b": 2}'), NULL);
----
NULL
5.19.38 - JSON_PATH_MATCH
Checks whether a specified JSON path expression matches certain conditions within a JSON data. Please note that the @@ operator is synonymous with this function. For more information, see JSON Operators.
Analyze Syntax
func.json_path_match(<json_data>, <json_path_expression)
Analyze Example
func.json_path_match(func.parse_json('{"a":1,"b":[1,2,3]}'), '$.a == 1')
┌──────────────────────────────────────────────────────────────────────────┐
│ func.json_path_match(func.parse_json('{"a":1,"b":[1,2,3]}'), '$.a == 1') │
├──────────────────────────────────────────────────────────────────────────┤
│ true │
└──────────────────────────────────────────────────────────────────────────┘
func.json_path_match(func.parse_json('{"a":1,"b":[1,2,3]}'), '$.b[0] > 1')
┌────────────────────────────────────────────────────────────────────────────┐
│ func.json_path_match(func.parse_json('{"a":1,"b":[1,2,3]}'), '$.b[0] > 1') │
├────────────────────────────────────────────────────────────────────────────┤
│ false │
└────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
JSON_PATH_MATCH(<json_data>, <json_path_expression>)
json_data: Specifies the JSON data you want to examine. It can be a JSON object or an array.json_path_expression: Specifies the conditions to be checked within the JSON data. This expression describes the specific path or criteria to be matched, such as verifying whether specific field values in the JSON structure meet certain conditions. The$symbol represents the root of the JSON data. It is used to start the path expression and indicates the top-level object in the JSON structure.
Return Type
The function returns:
trueif the specified JSON path expression matches the conditions within the JSON data.falseif the specified JSON path expression does not match the conditions within the JSON data.- NULL if either
json_dataorjson_path_expressionis NULL or invalid.
SQL Examples
-- Check if the value at JSON path $.a is equal to 1
SELECT JSON_PATH_MATCH(parse_json('{"a":1,"b":[1,2,3]}'), '$.a == 1');
┌────────────────────────────────────────────────────────────────┐
│ json_path_match(parse_json('{"a":1,"b":[1,2,3]}'), '$.a == 1') │
├────────────────────────────────────────────────────────────────┤
│ true │
└────────────────────────────────────────────────────────────────┘
-- Check if the first element in the array at JSON path $.b is greater than 1
SELECT JSON_PATH_MATCH(parse_json('{"a":1,"b":[1,2,3]}'), '$.b[0] > 1');
┌──────────────────────────────────────────────────────────────────┐
│ json_path_match(parse_json('{"a":1,"b":[1,2,3]}'), '$.b[0] > 1') │
├──────────────────────────────────────────────────────────────────┤
│ false │
└──────────────────────────────────────────────────────────────────┘
-- Check if any element in the array at JSON path $.b
-- from the second one to the last are greater than or equal to 2
SELECT JSON_PATH_MATCH(parse_json('{"a":1,"b":[1,2,3]}'), '$.b[1 to last] >= 2');
┌───────────────────────────────────────────────────────────────────────────┐
│ json_path_match(parse_json('{"a":1,"b":[1,2,3]}'), '$.b[1 to last] >= 2') │
├───────────────────────────────────────────────────────────────────────────┤
│ true │
└───────────────────────────────────────────────────────────────────────────┘
-- NULL is returned if either the json_data or json_path_expression is NULL or invalid.
SELECT JSON_PATH_MATCH(parse_json('{"a":1,"b":[1,2,3]}'), NULL);
┌──────────────────────────────────────────────────────────┐
│ json_path_match(parse_json('{"a":1,"b":[1,2,3]}'), null) │
├──────────────────────────────────────────────────────────┤
│ NULL │
└──────────────────────────────────────────────────────────┘
SELECT JSON_PATH_MATCH(NULL, '$.a == 1');
┌───────────────────────────────────┐
│ json_path_match(null, '$.a == 1') │
├───────────────────────────────────┤
│ NULL │
└───────────────────────────────────┘
5.19.39 - JSON_PATH_QUERY
Get all JSON items returned by JSON path for the specified JSON value.
Analyze Syntax
func.json_path_query(<variant>, <path_name>)
Analyze Example
table.name, func.json_path_query(table.details, '$.features.*').alias('all_features')
+------------+--------------+
| name | all_features |
+------------+--------------+
| Laptop | "16GB" |
| Laptop | "512GB" |
| Smartphone | "4GB" |
| Smartphone | "128GB" |
| Headphones | "20h" |
| Headphones | "5.0" |
+------------+--------------+
SQL Syntax
JSON_PATH_QUERY(<variant>, '<path_name>')
Return Type
VARIANT
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE products (
name VARCHAR,
details VARIANT
);
INSERT INTO products (name, details)
VALUES ('Laptop', '{"brand": "Dell", "colors": ["Black", "Silver"], "price": 1200, "features": {"ram": "16GB", "storage": "512GB"}}'),
('Smartphone', '{"brand": "Apple", "colors": ["White", "Black"], "price": 999, "features": {"ram": "4GB", "storage": "128GB"}}'),
('Headphones', '{"brand": "Sony", "colors": ["Black", "Blue", "Red"], "price": 150, "features": {"battery": "20h", "bluetooth": "5.0"}}');
Query Demo: Extracting All Features from Product Details
SELECT
name,
JSON_PATH_QUERY(details, '$.features.*') AS all_features
FROM
products;
Result
+------------+--------------+
| name | all_features |
+------------+--------------+
| Laptop | "16GB" |
| Laptop | "512GB" |
| Smartphone | "4GB" |
| Smartphone | "128GB" |
| Headphones | "20h" |
| Headphones | "5.0" |
+------------+--------------+
5.19.40 - JSON_PATH_QUERY_ARRAY
Get all JSON items returned by JSON path for the specified JSON value and wrap a result into an array.
Analyze Syntax
func.json_path_query_array(<variant>, <path_name>)
Analyze Example
table.name, func.json_path_query_array(table.details, '$.features.*').alias('all_features')
name | all_features
------------+-----------------------
Laptop | ["16GB", "512GB"]
Smartphone | ["4GB", "128GB"]
Headphones | ["20h", "5.0"]
SQL Syntax
JSON_PATH_QUERY_ARRAY(<variant>, '<path_name>')
Return Type
VARIANT
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE products (
name VARCHAR,
details VARIANT
);
INSERT INTO products (name, details)
VALUES ('Laptop', '{"brand": "Dell", "colors": ["Black", "Silver"], "price": 1200, "features": {"ram": "16GB", "storage": "512GB"}}'),
('Smartphone', '{"brand": "Apple", "colors": ["White", "Black"], "price": 999, "features": {"ram": "4GB", "storage": "128GB"}}'),
('Headphones', '{"brand": "Sony", "colors": ["Black", "Blue", "Red"], "price": 150, "features": {"battery": "20h", "bluetooth": "5.0"}}');
Query Demo: Extracting All Features from Product Details as an Array
SELECT
name,
JSON_PATH_QUERY_ARRAY(details, '$.features.*') AS all_features
FROM
products;
Result
name | all_features
-----------+-----------------------
Laptop | ["16GB", "512GB"]
Smartphone | ["4GB", "128GB"]
Headphones | ["20h", "5.0"]
5.19.41 - JSON_PATH_QUERY_FIRST
Get the first JSON item returned by JSON path for the specified JSON value.
Analyze Syntax
func.json_path_query_first(<variant>, <path_name>)
Analyze Example
table.name, func.json_path_query_first(table.details, '$.features.*').alias('first_feature')
+------------+---------------+
| name | first_feature |
+------------+---------------+
| Laptop | "16GB" |
| Laptop | "16GB" |
| Smartphone | "4GB" |
| Smartphone | "4GB" |
| Headphones | "20h" |
| Headphones | "20h" |
+------------+---------------+
SQL Syntax
JSON_PATH_QUERY_FIRST(<variant>, '<path_name>')
Return Type
VARIANT
SQL Examples
Create a Table and Insert Sample Data
CREATE TABLE products (
name VARCHAR,
details VARIANT
);
INSERT INTO products (name, details)
VALUES ('Laptop', '{"brand": "Dell", "colors": ["Black", "Silver"], "price": 1200, "features": {"ram": "16GB", "storage": "512GB"}}'),
('Smartphone', '{"brand": "Apple", "colors": ["White", "Black"], "price": 999, "features": {"ram": "4GB", "storage": "128GB"}}'),
('Headphones', '{"brand": "Sony", "colors": ["Black", "Blue", "Red"], "price": 150, "features": {"battery": "20h", "bluetooth": "5.0"}}');
Query Demo: Extracting the First Feature from Product Details
SELECT
name,
JSON_PATH_QUERY(details, '$.features.*') AS all_features,
JSON_PATH_QUERY_FIRST(details, '$.features.*') AS first_feature
FROM
products;
Result
+------------+--------------+---------------+
| name | all_features | first_feature |
+------------+--------------+---------------+
| Laptop | "16GB" | "16GB" |
| Laptop | "512GB" | "16GB" |
| Smartphone | "4GB" | "4GB" |
| Smartphone | "128GB" | "4GB" |
| Headphones | "20h" | "20h" |
| Headphones | "5.0" | "20h" |
+------------+--------------+---------------+
5.19.42 - JSON_PRETTY
Formats JSON data, making it more readable and presentable. It automatically adds indentation, line breaks, and other formatting to the JSON data for better visual representation.
Analyze Syntax
func.json_pretty(<json_string>)
Analyze Example
func.json_pretty(func.parse_json('{"person": {"name": "bob", "age": 25}, "location": "city"}'))
┌─────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.json_pretty(func.parse_json('{"person": {"name": "bob", "age": 25}, "location": "city"}')) │
│ String │
├─────────────────────────────────────────────────────────────────────────────────────────────────┤
│ { │
│ "location": "City", │
│ "person": { │
│ "age": 25, │
│ "name": "Bob" │
│ } │
│ } │
└─────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
JSON_PRETTY(<json_string>)
Return Type
String.
SQL Examples
SELECT JSON_PRETTY(PARSE_JSON('{"name":"Alice","age":30}'));
---
┌──────────────────────────────────────────────────────┐
│ json_pretty(parse_json('{"name":"alice","age":30}')) │
│ String │
├──────────────────────────────────────────────────────┤
│ { │
│ "age": 30, │
│ "name": "Alice" │
│ } │
└──────────────────────────────────────────────────────┘
SELECT JSON_PRETTY(PARSE_JSON('{"person": {"name": "Bob", "age": 25}, "location": "City"}'));
---
┌───────────────────────────────────────────────────────────────────────────────────────┐
│ json_pretty(parse_json('{"person": {"name": "bob", "age": 25}, "location": "city"}')) │
│ String │
├───────────────────────────────────────────────────────────────────────────────────────┤
│ { │
│ "location": "City", │
│ "person": { │
│ "age": 25, │
│ "name": "Bob" │
│ } │
│ } │
└───────────────────────────────────────────────────────────────────────────────────────┘
5.19.43 - JSON_STRIP_NULLS
Removes all properties with null values from a JSON object.
Analyze Syntax
func.json_strip_nulls(<json_string>)
Analyze Example
func.json_strip_nulls(func.parse_json('{"name": "alice", "age": 30, "city": null}'))
┌─────────────────────────────────────────────────────────────────────────────────────────────────┐
│ func.json_strip_nulls(func.parse_json('{"name": "alice", "age": 30, "city": null}')) │
│ String │
├─────────────────────────────────────────────────────────────────────────────────────────────────┤
│ {"age":30,"name":"Alice"} │
└─────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
JSON_STRIP_NULLS(<json_string>)
Return Type
Returns a value of the same type as the input JSON value.
SQL Examples
SELECT JSON_STRIP_NULLS(PARSE_JSON('{"name": "Alice", "age": 30, "city": null}'));
json_strip_nulls(parse_json('{"name": "alice", "age": 30, "city": null}'))|
--------------------------------------------------------------------------+
{"age":30,"name":"Alice"} |
5.19.44 - JSON_TO_STRING
Alias for TO_STRING.
5.19.45 - JSON_TYPEOF
Returns the type of the main-level of a JSON structure.
Analyze Syntax
func.json_typeof(<json_string>)
Analyze Example
func.json_typeof(func.parse_json('null'))|
-----------------------------------------+
null |
--
func.json_typeof(func.parse_json('true'))|
-----------------------------------------+
boolean |
--
func.json_typeof(func.parse_json('"plaidcloud"'))|
-----------------------------------------------+
string |
--
func.json_typeof(func.parse_json('-1.23'))|
------------------------------------------+
number |
--
func.json_typeof(func.parse_json('[1,2,3]'))|
--------------------------------------------+
array |
--
func.json_typeof(func.parse_json('{"name": "alice", "age": 30}'))|
-----------------------------------------------------------------+
object |
SQL Syntax
JSON_TYPEOF(<json_string>)
Return Type
The return type of the json_typeof function (or similar) is a string that indicates the data type of the parsed JSON value. The possible return values are: 'null', 'boolean', 'string', 'number', 'array', and 'object'.
SQL Examples
-- Parsing a JSON value that is NULL
SELECT JSON_TYPEOF(PARSE_JSON(NULL));
--
func.json_typeof(func.parse_json(null))|
-----------------------------+
|
-- Parsing a JSON value that is the string 'null'
SELECT JSON_TYPEOF(PARSE_JSON('null'));
--
func.json_typeof(func.parse_json('null'))|
-------------------------------+
null |
SELECT JSON_TYPEOF(PARSE_JSON('true'));
--
func.json_typeof(func.parse_json('true'))|
-------------------------------+
boolean |
SELECT JSON_TYPEOF(PARSE_JSON('"PlaidCloud Lakehouse"'));
--
func.json_typeof(func.parse_json('"databend"'))|
-------------------------------------+
string |
SELECT JSON_TYPEOF(PARSE_JSON('-1.23'));
--
func.json_typeof(func.parse_json('-1.23'))|
--------------------------------+
number |
SELECT JSON_TYPEOF(PARSE_JSON('[1,2,3]'));
--
func.json_typeof(func.parse_json('[1,2,3]'))|
----------------------------------+
array |
SELECT JSON_TYPEOF(PARSE_JSON('{"name": "Alice", "age": 30}'));
--
func.json_typeof(func.parse_json('{"name": "alice", "age": 30}'))|
-------------------------------------------------------+
object |
5.19.46 - OBJECT_KEYS
Alias for JSON_OBJECT_KEYS.
5.19.47 - PARSE_JSON
parse_json and try_parse_json interprets an input string as a JSON document, producing a VARIANT value.
try_parse_json returns a NULL value if an error occurs during parsing.
Analyze Syntax
func.parse_json(<json_string>)
or
func.try_parse_json(<json_string>)
Analyze Example
func.parse_json('[-1, 12, 289, 2188, false]')
+-----------------------------------------------+
| func.parse_json('[-1, 12, 289, 2188, false]') |
+-----------------------------------------------+
| [-1,12,289,2188,false] |
+-----------------------------------------------+
func.try_parse_json('{ "x" : "abc", "y" : false, "z": 10} ')
+--------------------------------------------------------------+
| func.try_parse_json('{ "x" : "abc", "y" : false, "z": 10} ') |
+--------------------------------------------------------------+
| {"x":"abc","y":false,"z":10} |
+--------------------------------------------------------------+
SQL Syntax
PARSE_JSON(<expr>)
TRY_PARSE_JSON(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | An expression of string type (e.g. VARCHAR) that holds valid JSON information. |
Return Type
VARIANT
SQL Examples
SELECT parse_json('[-1, 12, 289, 2188, false]');
+------------------------------------------+
| parse_json('[-1, 12, 289, 2188, false]') |
+------------------------------------------+
| [-1,12,289,2188,false] |
+------------------------------------------+
SELECT try_parse_json('{ "x" : "abc", "y" : false, "z": 10} ');
+---------------------------------------------------------+
| try_parse_json('{ "x" : "abc", "y" : false, "z": 10} ') |
+---------------------------------------------------------+
| {"x":"abc","y":false,"z":10} |
+---------------------------------------------------------+
5.20 - Sequence Functions
This section provides reference information for sequence functions in PlaidCloud Lakehouse.
5.20.1 - NEXTVAL
Retrieves the next value from a sequence.
SQL Syntax
NEXTVAL(<sequence_name>)
Return Type
Integer.
SQL Examples
This example demonstrates how the NEXTVAL function works with a sequence:
CREATE SEQUENCE my_seq;
SELECT
NEXTVAL(my_seq),
NEXTVAL(my_seq),
NEXTVAL(my_seq);
┌─────────────────────────────────────────────────────┐
│ nextval(my_seq) │ nextval(my_seq) │ nextval(my_seq) │
├─────────────────┼─────────────────┼─────────────────┤
│ 1 │ 2 │ 3 │
└─────────────────────────────────────────────────────┘
This example showcases how sequences and the NEXTVAL function are employed to automatically generate and assign unique identifiers to rows in a table.
-- Create a new sequence named staff_id_seq
CREATE SEQUENCE staff_id_seq;
-- Create a new table named staff with columns for staff_id, name, and department
CREATE TABLE staff (
staff_id INT,
name VARCHAR(50),
department VARCHAR(50)
);
-- Insert a new row into the staff table, using the next value from the staff_id_seq sequence for the staff_id column
INSERT INTO staff (staff_id, name, department)
VALUES (NEXTVAL(staff_id_seq), 'John Doe', 'HR');
-- Insert another row into the staff table, using the next value from the staff_id_seq sequence for the staff_id column
INSERT INTO staff (staff_id, name, department)
VALUES (NEXTVAL(staff_id_seq), 'Jane Smith', 'Finance');
SELECT * FROM staff;
┌───────────────────────────────────────────────────────┐
│ staff_id │ name │ department │
├─────────────────┼──────────────────┼──────────────────┤
│ 2 │ Jane Smith │ Finance │
│ 1 │ John Doe │ HR │
└───────────────────────────────────────────────────────┘
5.21 - String Functions
This section provides reference information for the string-related functions in PlaidCloud Lakehouse.
String Manipulation:
- CONCAT
- CONCAT_WS
- INSERT
- LEFT
- LPAD
- REPEAT
- REPLACE
- REVERSE
- RIGHT
- RPAD
- SPLIT
- SPLIT_PART
- SUBSTR
- SUBSTRING
- TRANSLATE
- TRIM
String Information:
Case Conversion:
Regular Expressions:
Encoding and Decoding:
Miscellaneous:
5.21.1 - ASCII
Returns the numeric value of the leftmost character of the string str.
Analyze Syntax
func.ascii(<expr>)
Analyze Examples
func.ascii('2')
+-----------------+
| func.ascii('2') |
+-----------------+
| 50 |
+-----------------+
SQL Syntax
ASCII(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | The string. |
Return Type
TINYINT
SQL Examples
SELECT ASCII('2');
+------------+
| ASCII('2') |
+------------+
| 50 |
+------------+
5.21.2 - BIN
Returns a string representation of the binary value of N.
Analyze Syntax
func.bin(<expr>)
Analyze Examples
func.bin(12)
+--------------+
| func.bin(12) |
+--------------+
| 1100 |
+--------------+
SQL Syntax
BIN(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | The number. |
Return Type
VARCHAR
SQL Examples
SELECT BIN(12);
+---------+
| BIN(12) |
+---------+
| 1100 |
+---------+
5.21.3 - BIT_LENGTH
Return the length of a string in bits.
Analyze Syntax
func.bit_length(<expr>)
Analyze Examples
func.bit_length('Word')
+-------------------------+
| func.bit_length('Word') |
+-------------------------+
| 32 |
+-------------------------+
SQL Syntax
BIT_LENGTH(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | The string. |
Return Type
BIGINT
SQL Examples
SELECT BIT_LENGTH('Word');
+----------------------------+
| SELECT BIT_LENGTH('Word'); |
+----------------------------+
| 32 |
+----------------------------+
5.21.4 - CHAR
Return the character for each integer passed.
Analyze Syntax
func.char(N,...)
Analyze Examples
func.char(77,121,83,81,76)
+-----------------------------+
| func.char(77,121,83,81,76) |
+-----------------------------+
| 4D7953514C |
+-----------------------------+
SQL Syntax
CHAR(N, ...)
Arguments
| Arguments | Description |
|---|---|
| N | Numeric Column |
Return Type
BINARY
SQL Examples
This example shows both the binary value returned as well as the string representation.
SELECT CHAR(77,121,83,81,76) as a, a::String;
┌────────────────────────┐
│ a │ a::string │
│ Binary │ String │
├────────────┼───────────┤
│ 4D7953514C │ MySQL │
└────────────────────────┘
5.21.5 - CHAR_LENGTH
Alias for LENGTH.
5.21.6 - CHARACTER_LENGTH
Alias for LENGTH.
5.21.7 - CONCAT
Returns the string that results from concatenating the arguments. May have one or more arguments. If all arguments are nonbinary strings, the result is a nonbinary string. If the arguments include any binary strings, the result is a binary string. A numeric argument is converted to its equivalent nonbinary string form.
Analyze Syntax
func.concat(<expr1>, ...)
Analyze Examples
func.concat('data', 'bend')
+-----------------------------+
| func.concat('data', 'bend') |
+-----------------------------+
| databend |
+-----------------------------+
SQL Syntax
CONCAT(<expr1>, ...)
Arguments
| Arguments | Description |
|---|---|
<expr1> | string |
Return Type
A VARCHAR data type value Or NULL data type.
SQL Examples
SELECT CONCAT('data', 'bend');
+------------------------+
| concat('data', 'bend') |
+------------------------+
| databend |
+------------------------+
SELECT CONCAT('data', NULL, 'bend');
+------------------------------+
| CONCAT('data', NULL, 'bend') |
+------------------------------+
| NULL |
+------------------------------+
SELECT CONCAT('14.3');
+----------------+
| concat('14.3') |
+----------------+
| 14.3 |
+----------------+
5.21.8 - CONCAT_WS
CONCAT_WS() stands for Concatenate With Separator and is a special form of CONCAT(). The first argument is the separator for the rest of the arguments. The separator is added between the strings to be concatenated. The separator can be a string, as can the rest of the arguments. If the separator is NULL, the result is NULL.
CONCAT_WS() does not skip empty strings. However, it does skip any NULL values after the separator argument.
Analyze Syntax
func.concat_ws(<separator>, <expr1>, ...)
Analyze Examples
func.concat_ws(',', 'data', 'fuse', 'labs', '2021')
+-----------------------------------------------------+
| func.concat_ws(',', 'data', 'fuse', 'labs', '2021') |
+-----------------------------------------------------+
| data,fuse,labs,2021 |
+-----------------------------------------------------+
SQL Syntax
CONCAT_WS(<separator>, <expr1>, ...)
Arguments
| Arguments | Description |
|---|---|
<separator> | string column |
<expr1> | value column |
Return Type
A VARCHAR data type value Or NULL data type.
SQL Examples
SELECT CONCAT_WS(',', 'data', 'fuse', 'labs', '2021');
+------------------------------------------------+
| CONCAT_WS(',', 'data', 'fuse', 'labs', '2021') |
+------------------------------------------------+
| data,fuse,labs,2021 |
+------------------------------------------------+
SELECT CONCAT_WS(',', 'data', NULL, 'bend');
+--------------------------------------+
| CONCAT_WS(',', 'data', NULL, 'bend') |
+--------------------------------------+
| data,bend |
+--------------------------------------+
SELECT CONCAT_WS(',', 'data', NULL, NULL, 'bend');
+--------------------------------------------+
| CONCAT_WS(',', 'data', NULL, NULL, 'bend') |
+--------------------------------------------+
| data,bend |
+--------------------------------------------+
SELECT CONCAT_WS(NULL, 'data', 'fuse', 'labs');
+-----------------------------------------+
| CONCAT_WS(NULL, 'data', 'fuse', 'labs') |
+-----------------------------------------+
| NULL |
+-----------------------------------------+
SELECT CONCAT_WS(',', NULL);
+----------------------+
| CONCAT_WS(',', NULL) |
+----------------------+
| |
+----------------------+
5.21.9 - FROM_BASE64
Takes a string encoded with the base-64 encoded rules nd returns the decoded result as a binary. The result is NULL if the argument is NULL or not a valid base-64 string.
Analyze Syntax
func.from_base64(<expr>)
Analyze Examples
func.from_base64('YWJj')
+--------------------------+
| func.from_base64('YWJj') |
+--------------------------+
| abc |
+--------------------------+
SQL Syntax
FROM_BASE64(<expr>)
Arguments
| Arguments | Description |
|---|---|
<expr> | The string value. |
Return Type
BINARY
SQL Examples
SELECT TO_BASE64('abc'), FROM_BASE64(TO_BASE64('abc')) as b, b::String;
┌───────────────────────────────────────┐
│ to_base64('abc') │ b │ b::string │
│ String │ Binary │ String │
├──────────────────┼────────┼───────────┤
│ YWJj │ 616263 │ abc │
└───────────────────────────────────────┘
5.21.10 - FROM_HEX
Alias for UNHEX.
5.21.11 - HEX
Alias for TO_HEX.
5.21.12 - INSERT
Returns the string str, with the substring beginning at position pos and len characters long replaced by the string newstr. Returns the original string if pos is not within the length of the string. Replaces the rest of the string from position pos if len is not within the length of the rest of the string. Returns NULL if any argument is NULL.
Analyze Syntax
func.insert(<str>, <pos>, <len>, <newstr>)
Analyze Examples
func.insert('Quadratic', 3, 4, 'What')
+----------------------------------------+
| func.insert('Quadratic', 3, 4, 'What') |
+----------------------------------------+
| QuWhattic |
+----------------------------------------+
SQL Syntax
INSERT(<str>, <pos>, <len>, <newstr>)
Arguments
| Arguments | Description |
|---|---|
<str> | The string. |
<pos> | The position. |
<len> | The length. |
<newstr> | The new string. |
Return Type
VARCHAR
SQL Examples
SELECT INSERT('Quadratic', 3, 4, 'What');
+-----------------------------------+
| INSERT('Quadratic', 3, 4, 'What') |
+-----------------------------------+
| QuWhattic |
+-----------------------------------+
SELECT INSERT('Quadratic', -1, 4, 'What');
+---------------------------------------+
| INSERT('Quadratic', (- 1), 4, 'What') |
+---------------------------------------+
| Quadratic |
+---------------------------------------+
SELECT INSERT('Quadratic', 3, 100, 'What');
+-------------------------------------+
| INSERT('Quadratic', 3, 100, 'What') |
+-------------------------------------+
| QuWhat |
+-------------------------------------+
+--------------------------------------------+--------+
| INSERT('123456789', number, number, 'aaa') | number |
+--------------------------------------------+--------+
| 123456789 | 0 |
| aaa23456789 | 1 |
| 1aaa456789 | 2 |
| 12aaa6789 | 3 |
| 123aaa89 | 4 |
| 1234aaa | 5 |
| 12345aaa | 6 |
| 123456aaa | 7 |
| 1234567aaa | 8 |
| 12345678aaa | 9 |
| 123456789 | 10 |
| 123456789 | 11 |
| 123456789 | 12 |
+--------------------------------------------+--------+
5.21.13 - INSTR
Returns the position of the first occurrence of substring substr in string str. This is the same as the two-argument form of LOCATE(), except that the order of the arguments is reversed.
Analyze Syntax
func.instr(<str>, <substr>)
Analyze Examples
func.instr('foobarbar', 'bar')
+--------------------------------+
| func.instr('foobarbar', 'bar') |
+--------------------------------+
| 4 |
+--------------------------------+
SQL Syntax
INSTR(<str>, <substr>)
Arguments
| Arguments | Description |
|---|---|
<str> | The string. |
<substr> | The substring. |
Return Type
BIGINT
SQL Examples
SELECT INSTR('foobarbar', 'bar');
+---------------------------+
| INSTR('foobarbar', 'bar') |
+---------------------------+
| 4 |
+---------------------------+
SELECT INSTR('xbar', 'foobar');
+-------------------------+
| INSTR('xbar', 'foobar') |
+-------------------------+
| 0 |
+-------------------------+
5.21.14 - JARO_WINKLER
Calculates the Jaro-Winkler distance between two strings. It is commonly used for measuring the similarity between strings, with values ranging from 0.0 (completely dissimilar) to 1.0 (identical strings).
Analyze Syntax
func.jaro_winkler(<string1>, <string2>)
Analyze Examples
func.jaro_winkler('databend', 'Databend')
+-------------------------------------------+
| func.jaro_winkler('databend', 'Databend') |
+-------------------------------------------+
| 0.9166666666666666 |
+-------------------------------------------+
SQL Syntax
JARO_WINKLER(<string1>, <string2>)
SQL Examples
The JARO_WINKLER function returns a FLOAT64 value representing the similarity between the two input strings. The return value follows these rules:
Similarity Range: The result ranges from 0.0 (completely dissimilar) to 1.0 (identical).
SELECT JARO_WINKLER('databend', 'Databend') AS similarity; ┌────────────────────┐ │ similarity │ ├────────────────────┤ │ 0.9166666666666666 │ └────────────────────┘ SELECT JARO_WINKLER('databend', 'database') AS similarity; ┌────────────┐ │ similarity │ ├────────────┤ │ 0.9 │ └────────────┘NULL Handling: If either string1 or string2 is NULL, the result is NULL.
SELECT JARO_WINKLER('databend', NULL) AS similarity; ┌────────────┐ │ similarity │ ├────────────┤ │ NULL │ └────────────┘Empty Strings:
- Comparing two empty strings returns 1.0.
SELECT JARO_WINKLER('', '') AS similarity; ┌────────────┐ │ similarity │ ├────────────┤ │ 1 │ └────────────┘- Comparing an empty string with a non-empty string returns 0.0.
SELECT JARO_WINKLER('databend', '') AS similarity; ┌────────────┐ │ similarity │ ├────────────┤ │ 0 │ └────────────┘
5.21.15 - LCASE
Alias for LOWER.
5.21.16 - LEFT
Returns the leftmost len characters from the string str, or NULL if any argument is NULL.
Analyze Syntax
func.left(<str>, <len>)
Analyze Examples
func.left('foobarbar', 5)
+---------------------------+
| func.left('foobarbar', 5) |
+---------------------------+
| fooba |
+---------------------------+
SQL Syntax
LEFT(<str>, <len>);
Arguments
| Arguments | Description |
|---|---|
<str> | The main string from where the character to be extracted |
<len> | The count of characters |
Return Type
VARCHAR
SQL Examples
SELECT LEFT('foobarbar', 5);
+----------------------+
| LEFT('foobarbar', 5) |
+----------------------+
| fooba |
+----------------------+
5.21.17 - LENGTH
Returns the length of a given input string or binary value. In the case of strings, the length represents the count of characters, with each UTF-8 character considered as a single character. For binary data, the length corresponds to the number of bytes.
Analyze Syntax
func.length(<expr>)
Analyze Examples
func.length('Hello')
+----------------------+
| func.length('Hello') |
+----------------------+
| 5 |
+----------------------+
SQL Syntax
LENGTH(<expr>)
Aliases
Return Type
BIGINT
SQL Examples
SELECT LENGTH('Hello'), LENGTH_UTF8('Hello'), CHAR_LENGTH('Hello'), CHARACTER_LENGTH('Hello');
┌───────────────────────────────────────────────────────────────────────────────────────────┐
│ length('hello') │ length_utf8('hello') │ char_length('hello') │ character_length('hello') │
├─────────────────┼──────────────────────┼──────────────────────┼───────────────────────────┤
│ 5 │ 5 │ 5 │ 5 │
└───────────────────────────────────────────────────────────────────────────────────────────┘
5.21.18 - LENGTH_UTF8
Alias for LENGTH.
5.21.19 - LIKE
Pattern matching using an SQL pattern. Returns 1 (TRUE) or 0 (FALSE). If either expr or pat is NULL, the result is NULL.
Analyze Syntax
<column>.like('plaid%')
Analyze Examples
my_clothes.like('plaid%)
+-----------------+
| my_clothes |
+-----------------+
| plaid pants |
| plaid hat |
| plaid shirt |
+-----------------+
SQL Syntax
<expr> LIKE <pattern>
SQL Examples
SELECT name, category FROM system.functions WHERE name like 'tou%' ORDER BY name;
+----------+------------+
| name | category |
+----------+------------+
| touint16 | conversion |
| touint32 | conversion |
| touint64 | conversion |
| touint8 | conversion |
+----------+------------+
5.21.20 - LOCATE
The first syntax returns the position of the first occurrence of substring substr in string str. The second syntax returns the position of the first occurrence of substring substr in string str, starting at position pos. Returns 0 if substr is not in str. Returns NULL if any argument is NULL.
Analyze Syntax
func.locate(<substr>, <str>, <pos>)
Analyze Examples
func.locate('bar', 'foobarbar')
+------------------------------------+
| func.locate('bar', 'foobarbar') |
+------------------------------------+
| 5 |
+------------------------------------+
func.locate('bar', 'foobarbar', 5)
+------------------------------------+
| func.locate('bar', 'foobarbar', 5) |
+------------------------------------+
| 7 |
+------------------------------------+
SQL Syntax
LOCATE(<substr>, <str>)
LOCATE(<substr>, <str>, <pos>)
Arguments
| Arguments | Description |
|---|---|
<substr> | The substring. |
<str> | The string. |
<pos> | The position. |
Return Type
BIGINT
SQL Examples
SELECT LOCATE('bar', 'foobarbar')
+----------------------------+
| LOCATE('bar', 'foobarbar') |
+----------------------------+
| 4 |
+----------------------------+
SELECT LOCATE('xbar', 'foobar')
+--------------------------+
| LOCATE('xbar', 'foobar') |
+--------------------------+
| 0 |
+--------------------------+
SELECT LOCATE('bar', 'foobarbar', 5)
+-------------------------------+
| LOCATE('bar', 'foobarbar', 5) |
+-------------------------------+
| 7 |
+-------------------------------+
5.21.21 - LOWER
Returns a string with all characters changed to lowercase.
Analyze Syntax
func.lower(<str>)
Analyze Examples
func.lower('Hello, PlaidCloud!')
+----------------------------------+
| func.lower('Hello, PlaidCloud!') |
+----------------------------------+
| hello, plaidcloud! |
+----------------------------------+
SQL Syntax
LOWER(<str>)
Aliases
Return Type
VARCHAR
SQL Examples
SELECT LOWER('Hello, Databend!'), LCASE('Hello, Databend!');
┌───────────────────────────────────────────────────────┐
│ lower('hello, databend!') │ lcase('hello, databend!') │
├───────────────────────────┼───────────────────────────┤
│ hello, databend! │ hello, databend! │
└───────────────────────────────────────────────────────┘
5.21.22 - LPAD
Returns the string str, left-padded with the string padstr to a length of len characters. If str is longer than len, the return value is shortened to len characters.
Analyze Syntax
func.lpad(<str>, <len>, <padstr>)
Analyze Examples
func.lpad('hi',4,'??')
+------------------------+
| func.lpad('hi',4,'??') |
+------------------------+
| ??hi |
+------------------------+
func.lpad('hi',1,'??')
+------------------------+
| func.lpad('hi',1,'??') |
+------------------------+
| h |
+------------------------+
SQL Syntax
LPAD(<str>, <len>, <padstr>)
Arguments
| Arguments | Description |
|---|---|
<str> | The string. |
<len> | The length. |
<padstr> | The pad string. |
Return Type
VARCHAR
SQL Examples
SELECT LPAD('hi',4,'??');
+---------------------+
| LPAD('hi', 4, '??') |
+---------------------+
| ??hi |
+---------------------+
SELECT LPAD('hi',1,'??');
+---------------------+
| LPAD('hi', 1, '??') |
+---------------------+
| h |
+---------------------+
5.21.23 - LTRIM
Removes all occurrences of any character present in the specified trim string from the left side of the string.
See also:
Analyze Syntax
func.ltrim(<string>, <trim_string>)
Analyze Examples
func.ltrim('xxdatabend', 'x')
+--------------------------------+
| func.ltrim('xxdatabend', 'x') |
+--------------------------------+
| databend |
+--------------------------------+
SQL Syntax
LTRIM(<string>, <trim_string>)
SQL Examples
SELECT LTRIM('xxdatabend', 'xx'), LTRIM('xxdatabend', 'xy');
┌───────────────────────────────────────────────────────┐
│ ltrim('xxdatabend', 'xx') │ ltrim('xxdatabend', 'xy') │
├───────────────────────────┼───────────────────────────┤
│ databend │ databend │
└───────────────────────────────────────────────────────┘
5.21.24 - MID
Alias for SUBSTR.
5.21.25 - NOT LIKE
Pattern not matching using an SQL pattern. Returns 1 (TRUE) or 0 (FALSE). If either expr or pat is NULL, the result is NULL.
Analyze Syntax
<column>.not_like(<pattern>)
Analyze Examples
my_clothes.not_like('%pants)
+-----------------+
| my_clothes |
+-----------------+
| plaid pants XL |
| plaid hat |
| plaid shirt |
+-----------------+
SQL Syntax
<expr> NOT LIKE <pattern>
SQL Examples
SELECT name, category FROM system.functions WHERE name like 'tou%' AND name not like '%64' ORDER BY name;
+----------+------------+
| name | category |
+----------+------------+
| touint16 | conversion |
| touint32 | conversion |
| touint8 | conversion |
+----------+------------+
5.21.26 - NOT REGEXP
Returns 1 if the string expr doesn't match the regular expression specified by the pattern pat, 0 otherwise.
Analyze Syntax
not_(<column>.regexp_match(<pattern>))
Analyze Examples
With an input table of:
+-----------------+
| my_clothes |
+-----------------+
| plaid pants |
| plaid hat |
| plaid shirt |
| shoes |
+-----------------+
not_(my_clothes.regexp_match('p*'))
+-------------------------------------+
| not_(my_clothes.regexp_match('p*')) |
+-------------------------------------+
| false |
| false |
| false |
| true |
+-------------------------------------+
SQL Syntax
<expr> NOT REGEXP <pattern>
SQL Examples
SELECT 'databend' NOT REGEXP 'd*';
+------------------------------+
| ('databend' not regexp 'd*') |
+------------------------------+
| 0 |
+------------------------------+
5.21.27 - NOT RLIKE
Returns 1 if the string expr doesn't match the regular expression specified by the pattern pat, 0 otherwise.
Analyze Syntax
not_(<column>.regexp_match(<pattern>))
Analyze Examples
With an input table of:
+-----------------+
| my_clothes |
+-----------------+
| plaid pants |
| plaid hat |
| plaid shirt |
| shoes |
+-----------------+
not_(my_clothes.regexp_match('p*'))
+-------------------------------------+
| not_(my_clothes.regexp_match('p*')) |
+-------------------------------------+
| false |
| false |
| false |
| true |
+-------------------------------------+
SQL Syntax
<expr> NOT RLIKE <pattern>
SQL Examples
SELECT 'databend' not rlike 'd*';
+-----------------------------+
| ('databend' not rlike 'd*') |
+-----------------------------+
| 0 |
+-----------------------------+
5.21.28 - OCT
Returns a string representation of the octal value of N.
Analyze Syntax
func.oct(<expr>)
Analyze Examples
func.oct(12)
+-----------------+
| func.oct(12) |
+-----------------+
| 014 |
+-----------------+
SQL Syntax
OCT(<expr>)
SQL Examples
SELECT OCT(12);
+---------+
| OCT(12) |
+---------+
| 014 |
+---------+
5.21.29 - OCTET_LENGTH
OCTET_LENGTH() is a synonym for LENGTH().
Analyze Syntax
func.octet_length(<str>)
Analyze Examples
func.octet_length('databend')
+-------------------------------+
| func.octet_length('databend') |
+-------------------------------+
| 8 |
+-------------------------------+
SQL Syntax
OCTET_LENGTH(<str>)
SQL Examples
SELECT OCTET_LENGTH('databend');
+--------------------------+
| OCTET_LENGTH('databend') |
+--------------------------+
| 8 |
+--------------------------+
5.21.30 - ORD
If the leftmost character is not a multibyte character, ORD() returns the same value as the ASCII() function.
If the leftmost character of the string str is a multibyte character, returns the code for that character, calculated from the numeric values of its constituent bytes using this formula:
(1st byte code)
+ (2nd byte code * 256)
+ (3rd byte code * 256^2) ...
Analyze Syntax
func.ord(<str>)
Analyze Examples
func.ord('2')
+----------------+
| func.ord('2) |
+----------------+
| 50 |
+----------------+
SQL Syntax
ORD(<str>)
Arguments
| Arguments | Description |
|---|---|
<str> | The string. |
Return Type
BIGINT
SQL Examples
SELECT ORD('2')
+--------+
| ORD(2) |
+--------+
| 50 |
+--------+
5.21.31 - POSITION
POSITION(substr IN str) is a synonym for LOCATE(substr,str). Returns the position of the first occurrence of substring substr in string str. Returns 0 if substr is not in str. Returns NULL if any argument is NULL.
Analyze Syntax
func.position(<substr>, <str>)
Analyze Examples
func.position('bar', 'foobarbar')
+-----------------------------------+
| func.position('bar', 'foobarbar') |
+-----------------------------------+
| 4 |
+-----------------------------------+
SQL Syntax
POSITION(<substr> IN <str>)
Arguments
| Arguments | Description |
|---|---|
<substr> | The substring. |
<str> | The string. |
Return Type
BIGINT
SQL Examples
SELECT POSITION('bar' IN 'foobarbar')
+----------------------------+
| POSITION('bar' IN 'foobarbar') |
+----------------------------+
| 4 |
+----------------------------+
SELECT POSITION('xbar' IN 'foobar')
+--------------------------+
| POSITION('xbar' IN 'foobar') |
+--------------------------+
| 0 |
+--------------------------+
5.21.32 - QUOTE
Quotes a string to produce a result that can be used as a properly escaped data value in an SQL statement.
Analyze Syntax
func.quote(<str>)
Analyze Examples
func.quote('Don\'t')
+----------------------+
| func.quote('Don\'t') |
+----------------------+
| Don\'t! |
+----------------------+
SQL Syntax
QUOTE(<str>)
SQL Examples
SELECT QUOTE('Don\'t!');
+-----------------+
| QUOTE('Don't!') |
+-----------------+
| Don\'t! |
+-----------------+
SELECT QUOTE(NULL);
+-------------+
| QUOTE(NULL) |
+-------------+
| NULL |
+-------------+
5.21.33 - REGEXP
Returns true if the string <expr> matches the regular expression specified by the <pattern>, false otherwise.
Analyze Syntax
<column>.regexp_match(<pattern>)
Analyze Examples
With an input table of:
+-----------------+
| my_clothes |
+-----------------+
| plaid pants |
| plaid hat |
| plaid shirt |
| shoes |
+-----------------+
my_clothes.regexp_match('p*')
+-------------------------------+
| my_clothes.regexp_match('p*') |
+-------------------------------+
| true |
| true |
| true |
| false |
+-------------------------------+
SQL Syntax
<expr> REGEXP <pattern>
Aliases
SQL Examples
SELECT 'databend' REGEXP 'd*', 'databend' RLIKE 'd*';
┌────────────────────────────────────────────────────┐
│ ('databend' regexp 'd*') │ ('databend' rlike 'd*') │
├──────────────────────────┼─────────────────────────┤
│ true │ true │
└────────────────────────────────────────────────────┘
5.21.34 - REGEXP_INSTR
Returns the starting index of the substring of the string expr that matches the regular expression specified by the pattern pat, 0 if there is no match. If expr or pat is NULL, the return value is NULL. Character indexes begin at 1.
Analyze Syntax
func.regexp_instr(<expr>, <pat[, pos[, occurrence[, return_option[, match_type]]]]>)
Analyze Examples
func.regexp_instr('dog cat dog', 'dog')
+-----------------------------------------+
| func.regexp_instr('dog cat dog', 'dog') |
+-----------------------------------------+
| 1 |
+-----------------------------------------+
SQL Syntax
REGEXP_INSTR(<expr>, <pat[, pos[, occurrence[, return_option[, match_type]]]]>)
Arguments
| Arguments | Description |
|---|---|
| expr | The string expr that to be matched |
| pat | The regular expression |
| pos | Optional. The position in expr at which to start the search. If omitted, the default is 1. |
| occurrence | Optional. Which occurrence of a match to search for. If omitted, the default is 1. |
| return_option | Optional. Which type of position to return. If this value is 0, REGEXP_INSTR() returns the position of the matched substring's first character. If this value is 1, REGEXP_INSTR() returns the position following the matched substring. If omitted, the default is 0. |
| match_type | Optional. A string that specifies how to perform matching. The meaning is as described for REGEXP_LIKE(). |
Return Type
A number data type value.
SQL Examples
SELECT REGEXP_INSTR('dog cat dog', 'dog');
+------------------------------------+
| REGEXP_INSTR('dog cat dog', 'dog') |
+------------------------------------+
| 1 |
+------------------------------------+
SELECT REGEXP_INSTR('dog cat dog', 'dog', 2);
+---------------------------------------+
| REGEXP_INSTR('dog cat dog', 'dog', 2) |
+---------------------------------------+
| 9 |
+---------------------------------------+
SELECT REGEXP_INSTR('aa aaa aaaa', 'a{2}');
+-------------------------------------+
| REGEXP_INSTR('aa aaa aaaa', 'a{2}') |
+-------------------------------------+
| 1 |
+-------------------------------------+
SELECT REGEXP_INSTR('aa aaa aaaa', 'a{4}');
+-------------------------------------+
| REGEXP_INSTR('aa aaa aaaa', 'a{4}') |
+-------------------------------------+
| 8 |
+-------------------------------------+
5.21.35 - REGEXP_LIKE
REGEXP_LIKE function is used to check that whether the string matches the regular expression.
Analyze Syntax
func.regexp_like(<expr>, <pat[, match_type]>)
Analyze Examples
func.regexp_like('a', '^[a-d]')
+---------------------------------+
| func.regexp_like('a', '^[a-d]') |
+---------------------------------+
| 1 |
+---------------------------------+
SQL Syntax
REGEXP_LIKE(<expr>, <pat[, match_type]>)
Arguments
| Arguments | Description |
|---|---|
<expr> | The string expr that to be matched |
<pat> | The regular expression |
[match_type] | Optional. match_type argument is a string that specifying how to perform matching |
match_type may contain any or all the following characters:
c: Case-sensitive matching.i: Case-insensitive matching.m: Multiple-line mode. Recognize line terminators within the string. The default behavior is to match line terminators only at the start and end of the string expression.n: The.character matches line terminators. The default is for.matching to stop at the end of a line.u: Unix-only line endings. Not be supported now.
Return Type
BIGINT
Returns 1 if the string expr matches the regular expression specified by the pattern pat, 0 otherwise. If expr or pat is NULL, the return value is NULL.
SQL Examples
SELECT REGEXP_LIKE('a', '^[a-d]');
+----------------------------+
| REGEXP_LIKE('a', '^[a-d]') |
+----------------------------+
| 1 |
+----------------------------+
SELECT REGEXP_LIKE('abc', 'ABC');
+---------------------------+
| REGEXP_LIKE('abc', 'ABC') |
+---------------------------+
| 1 |
+---------------------------+
SELECT REGEXP_LIKE('abc', 'ABC', 'c');
+--------------------------------+
| REGEXP_LIKE('abc', 'ABC', 'c') |
+--------------------------------+
| 0 |
+--------------------------------+
SELECT REGEXP_LIKE('new*\n*line', 'new\\*.\\*line');
+-------------------------------------------+
| REGEXP_LIKE('new*
*line', 'new\*.\*line') |
+-------------------------------------------+
| 0 |
+-------------------------------------------+
SELECT REGEXP_LIKE('new*\n*line', 'new\\*.\\*line', 'n');
+------------------------------------------------+
| REGEXP_LIKE('new*
*line', 'new\*.\*line', 'n') |
+------------------------------------------------+
| 1 |
+------------------------------------------------+
5.21.36 - REGEXP_REPLACE
Replaces occurrences in the string expr that match the regular expression specified by the pattern pat with the replacement string repl, and returns the resulting string. If expr, pat, or repl is NULL, the return value is NULL.
Analyze Syntax
func.regexp_replace(<expr>, <pat>, <repl[, pos[, occurrence[, match_type]]]>)
Analyze Examples
func.regexp_replace('a b c', 'b', 'X')
+----------------------------------------+
| func.regexp_replace('a b c', 'b', 'X') |
+----------------------------------------+
| a X c |
+----------------------------------------+
SQL Syntax
REGEXP_REPLACE(<expr>, <pat>, <repl[, pos[, occurrence[, match_type]]]>)
Arguments
| Arguments | Description |
|---|---|
| expr | The string expr that to be matched |
| pat | The regular expression |
| repl | The replacement string |
| pos | Optional. The position in expr at which to start the search. If omitted, the default is 1. |
| occurrence | Optional. Which occurrence of a match to replace. If omitted, the default is 0 (which means "replace all occurrences"). |
| match_type | Optional. A string that specifies how to perform matching. The meaning is as described for REGEXP_LIKE(). |
Return Type
VARCHAR
SQL Examples
SELECT REGEXP_REPLACE('a b c', 'b', 'X');
+-----------------------------------+
| REGEXP_REPLACE('a b c', 'b', 'X') |
+-----------------------------------+
| a X c |
+-----------------------------------+
SELECT REGEXP_REPLACE('abc def ghi', '[a-z]+', 'X', 1, 3);
+----------------------------------------------------+
| REGEXP_REPLACE('abc def ghi', '[a-z]+', 'X', 1, 3) |
+----------------------------------------------------+
| abc def X |
+----------------------------------------------------+
SELECT REGEXP_REPLACE('周 周周 周周周', '周+', 'X', 3, 2);
+-----------------------------------------------------------+
| REGEXP_REPLACE('周 周周 周周周', '周+', 'X', 3, 2) |
+-----------------------------------------------------------+
| 周 周周 X |
+-----------------------------------------------------------+
5.21.37 - REGEXP_SUBSTR
Returns the substring of the string expr that matches the regular expression specified by the pattern pat, NULL if there is no match. If expr or pat is NULL, the return value is NULL.
Analyze Syntax
func.regexp_substr(<expr>, <pat[, pos[, occurrence[, match_type]]]>)
Analyze Examples
func.regexp_substr('abc def ghi', '[a-z]+')
+---------------------------------------------+
| func.regexp_substr('abc def ghi', '[a-z]+') |
+---------------------------------------------+
| abc |
+---------------------------------------------+
SQL Syntax
REGEXP_SUBSTR(<expr>, <pat[, pos[, occurrence[, match_type]]]>)
Arguments
| Arguments | Description |
|---|---|
| expr | The string expr that to be matched |
| pat | The regular expression |
| pos | Optional. The position in expr at which to start the search. If omitted, the default is 1. |
| occurrence | Optional. Which occurrence of a match to search for. If omitted, the default is 1. |
| match_type | Optional. A string that specifies how to perform matching. The meaning is as described for REGEXP_LIKE(). |
Return Type
VARCHAR
SQL Examples
SELECT REGEXP_SUBSTR('abc def ghi', '[a-z]+');
+----------------------------------------+
| REGEXP_SUBSTR('abc def ghi', '[a-z]+') |
+----------------------------------------+
| abc |
+----------------------------------------+
SELECT REGEXP_SUBSTR('abc def ghi', '[a-z]+', 1, 3);
+----------------------------------------------+
| REGEXP_SUBSTR('abc def ghi', '[a-z]+', 1, 3) |
+----------------------------------------------+
| ghi |
+----------------------------------------------+
SELECT REGEXP_SUBSTR('周 周周 周周周 周周周周', '周+', 2, 3);
+------------------------------------------------------------------+
| REGEXP_SUBSTR('周 周周 周周周 周周周周', '周+', 2, 3) |
+------------------------------------------------------------------+
| 周周周周 |
+------------------------------------------------------------------+
5.21.38 - REPEAT
Returns a string consisting of the string str repeated count times. If count is less than 1, returns an empty string. Returns NULL if str or count are NULL.
Analyze Syntax
func.repeat(<str>, <count>)
Analyze Examples
func.repeat(<str>, <count>)
+-------------------------+
| func.repeat('plaid', 3) |
+-------------------------+
| plaidplaidplaid |
+-------------------------+
SQL Syntax
REPEAT(<str>, <count>)
Arguments
| Arguments | Description |
|---|---|
<str> | The string. |
<count> | The number. |
SQL Examples
SELECT REPEAT('databend', 3);
+--------------------------+
| REPEAT('databend', 3) |
+--------------------------+
| databenddatabenddatabend |
+--------------------------+
SELECT REPEAT('databend', 0);
+-----------------------+
| REPEAT('databend', 0) |
+-----------------------+
| |
+-----------------------+
SELECT REPEAT('databend', NULL);
+--------------------------+
| REPEAT('databend', NULL) |
+--------------------------+
| NULL |
+--------------------------+
5.21.39 - REPLACE
Returns the string str with all occurrences of the string from_str replaced by the string to_str.
Analyze Syntax
func.replace(<str>, <from_str>, <to_str>)
Analyze Examples
func.replace(<str>, <from_str>, <to_str>)
+--------------------------------------+
| func.replace('plaidCloud', 'p', 'P') |
+--------------------------------------+
| PlaidCloud |
+--------------------------------------+
SQL Syntax
REPLACE(<str>, <from_str>, <to_str>)
Arguments
| Arguments | Description |
|---|---|
<str> | The string. |
<from_str> | The from string. |
<to_str> | The to string. |
Return Type
VARCHAR
SQL Examples
SELECT REPLACE('www.mysql.com', 'w', 'Ww');
+-------------------------------------+
| REPLACE('www.mysql.com', 'w', 'Ww') |
+-------------------------------------+
| WwWwWw.mysql.com |
+-------------------------------------+
5.21.40 - REVERSE
Returns the string str with the order of the characters reversed.
Analyze Syntax
func.reverse(<str>)
Analyze Examples
func.reverse('abc')
+----------------------+
| func..reverse('abc') |
+----------------------+
| cba |
+----------------------+
SQL Syntax
REVERSE(<str>)
Arguments
| Arguments | Description |
|---|---|
<str> | The string value. |
Return Type
VARCHAR
SQL Examples
SELECT REVERSE('abc');
+----------------+
| REVERSE('abc') |
+----------------+
| cba |
+----------------+
5.21.41 - RIGHT
Returns the rightmost len characters from the string str, or NULL if any argument is NULL.
Analyze Syntax
func.right(<str>, <len>)
Analyze Examples
func.right('foobarbar', 4)
+----------------------------+
| func.right('foobarbar', 4) |
+----------------------------+
| rbar |
+----------------------------+
SQL Syntax
RIGHT(<str>, <len>);
Arguments
| Arguments | Description |
|---|---|
<str> | The main string from where the character to be extracted |
<len> | The count of characters |
Return Type
VARCHAR
SQL Examples
SELECT RIGHT('foobarbar', 4);
+-----------------------+
| RIGHT('foobarbar', 4) |
+-----------------------+
| rbar |
+-----------------------+
5.21.42 - RLIKE
Alias for REGEXP.
5.21.43 - RPAD
Returns the string str, right-padded with the string padstr to a length of len characters. If str is longer than len, the return value is shortened to len characters.
Analyze Syntax
func.rpad(<str>, <len>, <padstr>)
Analyze Examples
func.rpad('hi',5,'?')
+-----------------------+
| func.rpad('hi',5,'?') |
+-----------------------+
| hi??? |
+-----------------------+
func.rpad('hi',1,'?')
+-----------------------+
| func.rpad('hi',1,'?') |
+-----------------------+
| h |
+-----------------------+
SQL Syntax
RPAD(<str>, <len>, <padstr>)
Arguments
| Arguments | Description |
|---|---|
<str> | The string. |
<len> | The length. |
<padstr> | The pad string. |
Return Type
VARCHAR
SQL Examples
SELECT RPAD('hi',5,'?');
+--------------------+
| RPAD('hi', 5, '?') |
+--------------------+
| hi??? |
+--------------------+
SELECT RPAD('hi',1,'?');
+--------------------+
| RPAD('hi', 1, '?') |
+--------------------+
| h |
+--------------------+
5.21.44 - RTRIM
Removes all occurrences of any character present in the specified trim string from the right side of the string.
See also:
Analyze Syntax
func.rtrim(<string>, <trim_string>)
Analyze Examples
func.rtrim('databend'xx, 'x')
+--------------------------------+
| func.rtrim('databendxx', 'x') |
+--------------------------------+
| databend |
+--------------------------------+
SQL Syntax
RTRIM(<string>, <trim_string>)
SQL Examples
SELECT RTRIM('databendxx', 'x'), RTRIM('databendxx', 'xy');
┌──────────────────────────────────────────────────────┐
│ rtrim('databendxx', 'x') │ rtrim('databendxx', 'xy') │
├──────────────────────────┼───────────────────────────┤
│ databend │ databend │
└──────────────────────────────────────────────────────┘
5.21.45 - SOUNDEX
Generates the Soundex code for a string.
- A Soundex code consists of a letter followed by three numerical digits. PlaidCloud Lakehouse's implementation returns more than 4 digits, but you can SUBSTR the result to get a standard Soundex code.
- All non-alphabetic characters in the string are ignored.
- All international alphabetic characters outside the A-Z range are ignored unless they're the first letter.
See also: SOUNDS LIKE
Analyze Syntax
func.soundex(<str>)
Analyze Examples
func.soundex('PlaidCloud Lakehouse')
+--------------------------------------+
| func.soundex('PlaidCloud Lakehouse') |
+--------------------------------------+
| D153 |
+--------------------------------------+
SQL Syntax
SOUNDEX(<str>)
Arguments
| Arguments | Description |
|---|---|
| str | The string. |
Return Type
Returns a code of type VARCHAR or a NULL value.
SQL Examples
SELECT SOUNDEX('PlaidCloud Lakehouse');
---
D153
-- All non-alphabetic characters in the string are ignored.
SELECT SOUNDEX('PlaidCloud Lakehouse!');
---
D153
-- All international alphabetic characters outside the A-Z range are ignored unless they're the first letter.
SELECT SOUNDEX('PlaidCloud Lakehouse,你好');
---
D153
SELECT SOUNDEX('你好,PlaidCloud Lakehouse');
---
你3153
-- SUBSTR the result to get a standard Soundex code.
SELECT SOUNDEX('databend cloud'),SUBSTR(SOUNDEX('databend cloud'),1,4);
soundex('databend cloud')|substring(soundex('databend cloud') from 1 for 4)|
-------------------------+-------------------------------------------------+
D153243 |D153 |
SELECT SOUNDEX(NULL);
+-------------------------------------+
| `SOUNDEX(NULL)` |
+-------------------------------------+
| <null> |
+-------------------------------------+
5.21.46 - SOUNDS LIKE
Compares the pronunciation of two strings by their Soundex codes. Soundex is a phonetic algorithm that produces a code representing the pronunciation of a string, allowing for approximate matching of strings based on their pronunciation rather than their spelling. PlaidCloud Lakehouse offers the SOUNDEX function that allows you to get the Soundex code from a string.
SOUNDS LIKE is frequently employed in the WHERE clause of SQL queries to narrow down rows using fuzzy string matching, such as for names and addresses, see Filtering Rows in Examples.
Analyze Syntax
func.sounds_like(<str1>, <str2>)
Analyze Examples
func..sounds_like('Monday', 'Sunday')
+---------------------------------------+
| func..sounds_like('Monday', 'Sunday') |
+---------------------------------------+
| 0 |
+---------------------------------------+
SQL Syntax
<str1> SOUNDS LIKE <str2>
Arguments
| Arguments | Description |
|---|---|
| str1, 2 | The strings you compare. |
Return Type
Return a Boolean value of 1 if the Soundex codes for the two strings are the same (which means they sound alike) and 0 otherwise.
SQL Examples
Comparing Strings
SELECT 'two' SOUNDS LIKE 'too'
----
1
SELECT CONCAT('A', 'B') SOUNDS LIKE 'AB';
----
1
SELECT 'Monday' SOUNDS LIKE 'Sunday';
----
0
Filtering Rows
SELECT * FROM employees;
id|first_name|last_name|age|
--+----------+---------+---+
0|John |Smith | 35|
0|Mark |Smythe | 28|
0|Johann |Schmidt | 51|
0|Eric |Doe | 30|
0|Sue |Johnson | 45|
SELECT * FROM employees
WHERE first_name SOUNDS LIKE 'John';
id|first_name|last_name|age|
--+----------+---------+---+
0|John |Smith | 35|
0|Johann |Schmidt | 51|
5.21.47 - SPACE
Returns a string consisting of N blank space characters.
Analyze Syntax
func.space(<n>)
Analyze Examples
func.space(20)
+-----------------+
| func.space(20) |
+-----------------+
| |
+-----------------+
SQL Syntax
SPACE(<n>);
Arguments
| Arguments | Description |
|---|---|
<n> | The number of spaces |
Return Type
String data type value.
SQL Examples
SELECT SPACE(20)
+----------------------+
| SPACE(20) |
+----------------------+
| |
+----------------------+
5.21.48 - SPLIT
Splits a string using a specified delimiter and returns the resulting parts as an array.
See also: SPLIT_PART
Analyze Syntax
func.split('<input_string>', '<delimiter>')
Analyze Examples
func.split('PlaidCloud Lakehouse', ' ')
+-----------------------------------------+
| func.split('PlaidCloud Lakehouse', ' ') |
+-----------------------------------------+
| ['PlaidCloud Lakehouse'] |
+-----------------------------------------+
SQL Syntax
SPLIT('<input_string>', '<delimiter>')
Return Type
Array of strings. SPLIT returns NULL when either the input string or the delimiter is NULL.
SQL Examples
-- Use a space as the delimiter
-- SPLIT returns an array with two parts.
SELECT SPLIT('PlaidCloud Lakehouse', ' ');
split('PlaidCloud Lakehouse', ' ')|
----------------------------------+
['PlaidCloud','Lakehouse'] |
-- Use an empty string as the delimiter or a delimiter that does not exist in the input string
-- SPLIT returns an array containing the entire input string as a single part.
SELECT SPLIT('PlaidCloud Lakehouse', '');
split('databend cloud', '')|
----------------------------------+
['PlaidCloud Lakehouse'] |
SELECT SPLIT('PlaidCloud Lakehouse', ',');
split('databend cloud', ',')|
----------------------------------+
['PlaidCloud Lakehouse'] |
-- Use ' ' (tab) as the delimiter
-- SPLIT returns an array with timestamp, log level, and message.
SELECT SPLIT('2023-10-19 15:30:45 INFO Log message goes here', ' ');
split('2023-10-19 15:30:45\tinfo\tlog message goes here', '\t')|
---------------------------------------------------------------+
['2023-10-19 15:30:45','INFO','Log message goes here'] |
5.21.49 - SPLIT_PART
Splits a string using a specified delimiter and returns the specified part.
See also: SPLIT
Analyze Syntax
func.split_part('<input_string>', '<delimiter>', '<position>')
Analyze Examples
func.split_part('PlaidCloud Lakehouse', ' ', 1)
+-------------------------------------------------+
| func.split_part('PlaidCloud Lakehouse', ' ', 1) |
+-------------------------------------------------+
| PlaidCloud |
+-------------------------------------------------+
SQL Syntax
SPLIT_PART('<input_string>', '<delimiter>', '<position>')
The position argument specifies which part to return. It uses a 1-based index but can also accept positive, negative, or zero values:
- If position is a positive number, it returns the part at the position from the left to the right, or NULL if it doesn't exist.
- If position is a negative number, it returns the part at the position from the right to the left, or NULL if it doesn't exist.
- If position is 0, it is treated as 1, effectively returning the first part of the string.
Return Type
String. SPLIT_PART returns NULL when either the input string, the delimiter, or the position is NULL.
SQL Examples
-- Use a space as the delimiter
-- SPLIT_PART returns a specific part.
SELECT SPLIT_PART('PlaidCloud Lakehouse', ' ', 1);
split_part('PlaidCloud Lakehouse', ' ', 1)|
------------------------------------------+
PlaidCloud Lakehouse |
-- Use an empty string as the delimiter or a delimiter that does not exist in the input string
-- SPLIT_PART returns the entire input string.
SELECT SPLIT_PART('PlaidCloud Lakehouse', '', 1);
split_part('PlaidCloud Lakehouse', '', 1)|
-----------------------------------+
PlaidCloud Lakehouse |
SELECT SPLIT_PART('PlaidCloud Lakehouse', ',', 1);
split_part('PlaidCloud Lakehouse', ',', 1)|
------------------------------------+
PlaidCloud Lakehouse |
-- Use ' ' (tab) as the delimiter
-- SPLIT_PART returns individual fields.
SELECT SPLIT_PART('2023-10-19 15:30:45 INFO Log message goes here', ' ', 3);
split_part('2023-10-19 15:30:45 info log message goes here', ' ', 3)|
--------------------------------------------------------------------------+
Log message goes here |
-- SPLIT_PART returns an empty string as the specified part does not exist at all.
SELECT SPLIT_PART('2023-10-19 15:30:45 INFO Log message goes here', ' ', 4);
split_part('2023-10-19 15:30:45 info log message goes here', ' ', 4)|
--------------------------------------------------------------------------+
|
5.21.50 - STRCMP
Returns 0 if the strings are the same, -1 if the first argument is smaller than the second, and 1 otherwise.
Analyze Syntax
func.strcmp(<expr1> ,<expr2>)
Analyze Examples
func.strcmp('text', 'text2')
+------------------------------+
| func.strcmp('text', 'text2') |
+------------------------------+
| -1 |
+------------------------------+
func.strcmp('text2', 'text')
+------------------------------+
| func.strcmp('text2', 'text') |
+------------------------------+
| 1 |
+------------------------------+
func.strcmp('text', 'text')
+------------------------------+
| func.strcmp('text', 'text') |
+------------------------------+
| 0 |
+------------------------------+
SQL Syntax
STRCMP(<expr1> ,<expr2>)
Arguments
| Arguments | Description |
|---|---|
<expr1> | The string. |
<expr2> | The string. |
Return Type
BIGINT
SQL Examples
SELECT STRCMP('text', 'text2');
+-------------------------+
| STRCMP('text', 'text2') |
+-------------------------+
| -1 |
+-------------------------+
SELECT STRCMP('text2', 'text');
+-------------------------+
| STRCMP('text2', 'text') |
+-------------------------+
| 1 |
+-------------------------+
SELECT STRCMP('text', 'text');
+------------------------+
| STRCMP('text', 'text') |
+------------------------+
| 0 |
+------------------------+
5.21.51 - SUBSTR
Extracts a string containing a specific number of characters from a particular position of a given string.
- The forms without a
lenargument return a substring from stringstrstarting at positionpos. - The forms with a
lenargument return a substringlencharacters long from stringstr, starting at positionpos.
It is also possible to use a negative value for pos. In this case, the beginning of the substring is pos characters from the end of the string, rather than the beginning. A negative value may be used for pos in any of the forms of this function. A value of 0 for pos returns an empty string. The position of the first character in the string from which the substring is to be extracted is reckoned as 1.
Analyze Syntax
func.substr(<str>, <pos>, <len>)
Analyze Examples
func.substr('Quadratically', 5, 6)
+------------------------------------+
| func.substr('Quadratically', 5, 6) |
+------------------------------------+
| ratica |
+------------------------------------+
SQL Syntax
SUBSTR(<str>, <pos>)
SUBSTR(<str>, <pos>, <len>)
Arguments
| Arguments | Description |
|---|---|
<str> | The main string from where the character to be extracted |
<pos> | The position (starting from 1) the substring to start at. If negative, counts from the end |
<len> | The maximum length of the substring to extract |
Aliases
Return Type
VARCHAR
SQL Examples
SELECT
SUBSTRING('Quadratically', 5),
SUBSTR('Quadratically', 5),
MID('Quadratically', 5);
┌─────────────────────────────────────────────────────────────────────────────────────────────────┐
│ substring('quadratically' from 5) │ substring('quadratically' from 5) │ mid('quadratically', 5) │
├───────────────────────────────────┼───────────────────────────────────┼─────────────────────────┤
│ ratically │ ratically │ ratically │
└─────────────────────────────────────────────────────────────────────────────────────────────────┘
SELECT
SUBSTRING('Quadratically', 5, 6),
SUBSTR('Quadratically', 5, 6),
MID('Quadratically', 5, 6);
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ substring('quadratically' from 5 for 6) │ substring('quadratically' from 5 for 6) │ mid('quadratically', 5, 6) │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────────────────┤
│ ratica │ ratica │ ratica │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.21.52 - SUBSTRING
Alias for SUBSTR.
5.21.53 - TO_BASE64
Converts the string argument to base-64 encoded form and returns the result as a character string. If the argument is not a string, it is converted to a string before conversion takes place. The result is NULL if the argument is NULL.
Analyze Syntax
func.to_base64(<v>)
Analyze Examples
func.to_base64('abc')
+-----------------------+
| func.to_base64('abc') |
+-----------------------+
| YWJj |
+-----------------------+
SQL Syntax
TO_BASE64(<v>)
Arguments
| Arguments | Description |
|---|---|
<v> | The value. |
Return Type
VARCHAR
SQL Examples
SELECT TO_BASE64('abc');
+------------------+
| TO_BASE64('abc') |
+------------------+
| YWJj |
+------------------+
5.21.54 - TRANSLATE
Transforms a given string by replacing specific characters with corresponding replacements, as defined by the provided mapping.
Analyze Syntax
func.translate('<inputString>', '<charactersToReplace>', '<replacementCharacters>')
Analyze Examples
func.translate('databend', 'de', 'DE')
+----------------------------------------+
| func.translate('databend', 'de', 'DE') |
+----------------------------------------+
| DatabEnD |
+----------------------------------------+
SQL Syntax
TRANSLATE('<inputString>', '<charactersToReplace>', '<replacementCharacters>')
| Parameter | Description |
|---|---|
<inputString> | The input string to be transformed. |
<charactersToReplace> | The string containing characters to be replaced in the input string. |
<replacementCharacters> | The string containing replacement characters corresponding to those in <charactersToReplace>. |
SQL Examples
-- Replace 'd' with '$' in 'databend'
SELECT TRANSLATE('databend', 'd', '$');
---
$ataben$
-- Replace 'd' with 'D' in 'databend'
SELECT TRANSLATE('databend', 'd', 'D');
---
DatabenD
-- Replace 'd' with 'D' and 'e' with 'E' in 'databend'
SELECT TRANSLATE('databend', 'de', 'DE');
---
DatabEnD
-- Remove 'd' from 'databend'
SELECT TRANSLATE('databend', 'd', '');
---
ataben
5.21.55 - TRIM
Returns the string without leading or trailing occurrences of the specified remove string. If remove string is omitted, spaces are removed.
The Analyze function automatically trims both leading and trailing spaces.
Analyze Syntax
func.trim(str)
Analyze Examples
func.trim(' plaidcloud ')
+--------------------------------+
| func.trim(' plaidcloud ') |
+--------------------------------+
| 'plaidcloud' |
+--------------------------------+
SQL Syntax
TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM ] str)
SQL Examples
Please note that ALL the examples in this section will return the string 'databend'.
The following example removes the leading and trailing string 'xxx' from the string 'xxxdatabendxxx':
SELECT TRIM(BOTH 'xxx' FROM 'xxxdatabendxxx');
The following example removes the leading string 'xxx' from the string 'xxxdatabend':
SELECT TRIM(LEADING 'xxx' FROM 'xxxdatabend' );
The following example removes the trailing string 'xxx' from the string 'databendxxx':
SELECT TRIM(TRAILING 'xxx' FROM 'databendxxx' );
If no remove string is specified, the function removes all leading and trailing spaces. The following examples remove the leading and/or trailing spaces:
SELECT TRIM(' databend ');
SELECT TRIM(' databend');
SELECT TRIM('databend ');
5.21.56 - TRIM_BOTH
Removes all occurrences of the specified trim string from the beginning, end, or both sides of the string.
See also: TRIM
Analyze Syntax
func.trim_both(<string>, <trim_string>)
Analyze Examples
func.trim_both('xxdatabendxx', 'x')
+--------------------------------------+
| func.trim_both('xxdatabendxx', 'x') |
+--------------------------------------+
| databend |
+--------------------------------------+
SQL Syntax
TRIM_BOTH(<string>, <trim_string>)
SQL Examples
SELECT TRIM_BOTH('xxdatabendxx', 'xxx'), TRIM_BOTH('xxdatabendxx', 'xx'), TRIM_BOTH('xxdatabendxx', 'x');
┌─────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ trim_both('xxdatabendxx', 'xxx') │ trim_both('xxdatabendxx', 'xx') │ trim_both('xxdatabendxx', 'x') │
├──────────────────────────────────┼─────────────────────────────────┼────────────────────────────────┤
│ xxdatabendxx │ databend │ databend │
└─────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.21.57 - TRIM_LEADING
Removes all occurrences of the specified trim string from the beginning of the string.
See also:
Analyze Syntax
func.trim_leading(<string>, <trim_string>)
Analyze Examples
func.trim_leading('xxdatabendxx', 'x')
+------------------------------------------+
| func.trim_leading('xxdatabendxx', 'x') |
+------------------------------------------+
| databendxx |
+------------------------------------------+
SQL Syntax
TRIM_LEADING(<string>, <trim_string>)
SQL Examples
SELECT TRIM_LEADING('xxdatabend', 'xxx'), TRIM_LEADING('xxdatabend', 'xx'), TRIM_LEADING('xxdatabend', 'x');
┌────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ trim_leading('xxdatabend', 'xxx') │ trim_leading('xxdatabend', 'xx') │ trim_leading('xxdatabend', 'x') │
├───────────────────────────────────┼──────────────────────────────────┼─────────────────────────────────┤
│ xxdatabend │ databend │ databend │
└────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.21.58 - TRIM_TRAILING
Removes all occurrences of the specified trim string from the end of the string.
See also:
Analyze Syntax
func.trim_trailing(<string>, <trim_string>)
Analyze Examples
func.trim_trailing('xxdatabendxx', 'x')
+------------------------------------------+
| func.trim_trailing('xxdatabendxx', 'x') |
+------------------------------------------+
| xxdatabend |
+------------------------------------------+
SQL Syntax
TRIM_TRAILING(<string>, <trim_string>)
SQL Examples
SELECT TRIM_TRAILING('databendxx', 'xxx'), TRIM_TRAILING('databendxx', 'xx'), TRIM_TRAILING('databendxx', 'x');
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ trim_trailing('databendxx', 'xxx') │ trim_trailing('databendxx', 'xx') │ trim_trailing('databendxx', 'x') │
├────────────────────────────────────┼───────────────────────────────────┼──────────────────────────────────┤
│ databendxx │ databend │ databend │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.21.59 - UCASE
Alias for UPPER.
5.21.60 - UNHEX
For a string argument str, UNHEX(str) interprets each pair of characters in the argument as a hexadecimal number and converts it to the byte represented by the number. The return value is a binary string.
Analyze Syntax
func.unhex(<expr>)
Analyze Examples
func.unhex('6461746162656e64')
+--------------------------------+
| func.unhex('6461746162656e64') |
+--------------------------------+
| 6461746162656E64 |
+--------------------------------+
SQL Syntax
UNHEX(<expr>)
Aliases
SQL Examples
SELECT UNHEX('6461746162656e64') as c1, typeof(c1),UNHEX('6461746162656e64')::varchar as c2, typeof(c2), FROM_HEX('6461746162656e64');
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ c1 │ typeof(c1) │ c2 | typeof(c2) | from_hex('6461746162656e64') |
├───────────────────────────┼────────────────────────|──────────────────┤───────────────────|─────────────────────────────────┤
│ 6461746162656E64 │ binary │ databend | varchar | 6461746162656E64 |
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
SELECT UNHEX(HEX('string')), unhex(HEX('string'))::varchar;
┌──────────────────────────────────────────────────────┐
│ unhex(hex('string')) │ unhex(hex('string'))::varchar │
├──────────────────────┼───────────────────────────────┤
│ 737472696E67 │ string │
└──────────────────────────────────────────────────────┘
5.21.61 - UPPER
Returns a string with all characters changed to uppercase.
Analyze Syntax
func.unhex(<expr>)
Analyze Examples
func.upper('hello, plaidcloud lakehouse!')
+--------------------------------------------+
| func.upper('hello, plaidcloud lakehouse!') |
+--------------------------------------------+
| 'HELLO, PLAIDCLOUD LAKEHOUSE!' |
+--------------------------------------------+
SQL Syntax
UPPER(<str>)
Aliases
Return Type
VARCHAR
SQL Examples
SELECT UPPER('hello, databend!'), UCASE('hello, databend!');
┌───────────────────────────────────────────────────────┐
│ upper('hello, databend!') │ ucase('hello, databend!') │
├───────────────────────────┼───────────────────────────┤
│ HELLO, DATABEND! │ HELLO, DATABEND! │
└───────────────────────────────────────────────────────┘
5.22 - System Functions
This section provides reference information for the system-related functions in PlaidCloud Lakehouse.
List of Functions:
5.22.1 - CLUSTERING_INFORMATION
Returns clustering information of a table.
SQL Syntax
CLUSTERING_INFORMATION('<database_name>', '<table_name>')
SQL Examples
CREATE TABLE mytable(a int, b int) CLUSTER BY(a+1);
INSERT INTO mytable VALUES(1,1),(3,3);
INSERT INTO mytable VALUES(2,2),(5,5);
INSERT INTO mytable VALUES(4,4);
SELECT * FROM CLUSTERING_INFORMATION('default','mytable')\G
*************************** 1. row ***************************
cluster_key: ((a + 1))
total_block_count: 3
constant_block_count: 1
unclustered_block_count: 0
average_overlaps: 1.3333
average_depth: 2.0
block_depth_histogram: {"00002":3}
| Parameter | Description |
|---|---|
| cluster_key | The defined cluster key. |
| total_block_count | The current count of blocks. |
| constant_block_count | The count of blocks where min/max values are equal, meaning each block contains only one (group of) cluster_key value. |
| unclustered_block_count | The count of blocks that have not yet been clustered. |
| average_overlaps | The average ratio of overlapping blocks within a given range. |
| average_depth | The average depth of overlapping partitions for the cluster key. |
| block_depth_histogram | The number of partitions at each depth level. A higher concentration of partitions at lower depths indicates more effective table clustering. |
5.22.2 - FUSE_BLOCK
Returns the block information of the latest or specified snapshot of a table. For more information about what is block in PlaidCloud Lakehouse, see What are Snapshot, Segment, and Block?.
The command returns the location information of each parquet file referenced by a snapshot. This enables downstream applications to access and consume the data stored in the files.
See Also:
SQL Syntax
FUSE_BLOCK('<database_name>', '<table_name>'[, '<snapshot_id>'])
SQL Examples
CREATE TABLE mytable(c int);
INSERT INTO mytable values(1);
INSERT INTO mytable values(2);
SELECT * FROM FUSE_BLOCK('default', 'mytable');
---
+----------------------------------+----------------------------+----------------------------------------------------+------------+----------------------------------------------------+-------------------+
| snapshot_id | timestamp | block_location | block_size | bloom_filter_location | bloom_filter_size |
+----------------------------------+----------------------------+----------------------------------------------------+------------+----------------------------------------------------+-------------------+
| 51e84b56458f44269b05a059b364a659 | 2022-09-15 07:14:14.137268 | 1/7/_b/39a6dbbfd9b44ad5a8ec8ab264c93cf5_v0.parquet | 4 | 1/7/_i/39a6dbbfd9b44ad5a8ec8ab264c93cf5_v1.parquet | 221 |
| 51e84b56458f44269b05a059b364a659 | 2022-09-15 07:14:14.137268 | 1/7/_b/d0ee9688c4d24d6da86acd8b0d6f4fad_v0.parquet | 4 | 1/7/_i/d0ee9688c4d24d6da86acd8b0d6f4fad_v1.parquet | 219 |
+----------------------------------+----------------------------+----------------------------------------------------+------------+----------------------------------------------------+-------------------+
5.22.3 - FUSE_COLUMN
Returns the column information of the latest or specified snapshot of a table. For more information about what is block in PlaidCloud Lakehouse, see What are Snapshot, Segment, and Block?.
See Also:
SQL Syntax
FUSE_COLUMN('<database_name>', '<table_name>'[, '<snapshot_id>'])
SQL Examples
CREATE TABLE mytable(c int);
INSERT INTO mytable values(1);
INSERT INTO mytable values(2);
SELECT * FROM FUSE_COLUMN('default', 'mytable');
---
+----------------------------------+----------------------------+---------------------------------------------------------+------------+-----------+-----------+-------------+-------------+-----------+--------------+------------------+
| snapshot_id | timestamp | block_location | block_size | file_size | row_count | column_name | column_type | column_id | block_offset | bytes_compressed |
+----------------------------------+----------------------------+---------------------------------------------------------+------------+-----------+-----------+-------------+-------------+-----------+--------------+------------------+
| 3faefc1a9b6a48f388a8b59228dd06c1 | 2023-07-18 03:06:30.276502 | 1/118746/_b/44df130c207745cb858928135d39c1c0_v2.parquet | 4 | 196 | 1 | c | Int32 | 0 | 8 | 14 |
| 3faefc1a9b6a48f388a8b59228dd06c1 | 2023-07-18 03:06:30.276502 | 1/118746/_b/b6f8496d7e3f4f62a89c09572840cf70_v2.parquet | 4 | 196 | 1 | c | Int32 | 0 | 8 | 14 |
+----------------------------------+----------------------------+---------------------------------------------------------+------------+-----------+-----------+-------------+-------------+-----------+--------------+------------------+
5.22.4 - FUSE_ENCODING
Returns the encoding types applied to a specific column within a table. It helps you understand how data is compressed and stored in a native format within the table.
SQL Syntax
FUSE_ENCODING('<database_name>', '<table_name>', '<column_name>')
The function returns a result set with the following columns:
| Column | Data Type | Description |
|---|---|---|
| VALIDITY_SIZE | Nullable(UInt32) | The size of a bitmap value that indicates whether each row in the column has a non-null value. This bitmap is used to track the presence or absence of null values in the column's data. |
| COMPRESSED_SIZE | UInt32 | The size of the column data after compression. |
| UNCOMPRESSED_SIZE | UInt32 | The size of the column data before applying encoding. |
| LEVEL_ONE | String | The primary or initial encoding applied to the column. |
| LEVEL_TWO | Nullable(String) | A secondary or recursive encoding method applied to the column after the initial encoding. |
SQL Examples
-- Create a table with an integer column 'c' and apply 'Lz4' compression
CREATE TABLE t(c INT) STORAGE_FORMAT = 'native' COMPRESSION = 'lz4';
-- Insert data into the table.
INSERT INTO t SELECT number FROM numbers(2048);
-- Analyze the encoding for column 'c' in table 't'
SELECT LEVEL_ONE, LEVEL_TWO, COUNT(*)
FROM FUSE_ENCODING('default', 't', 'c')
GROUP BY LEVEL_ONE, LEVEL_TWO;
level_one |level_two|count(*)|
------------+---------+--------+
DeltaBitpack| | 1|
-- Insert 2,048 rows with the value 1 into the table 't'
INSERT INTO t (c)
SELECT 1
FROM numbers(2048);
SELECT LEVEL_ONE, LEVEL_TWO, COUNT(*)
FROM FUSE_ENCODING('default', 't', 'c')
GROUP BY LEVEL_ONE, LEVEL_TWO;
level_one |level_two|count(*)|
------------+---------+--------+
OneValue | | 1|
DeltaBitpack| | 1|
5.22.5 - FUSE_SEGMENT
Returns the segment information of a specified table snapshot. For more information about what is segment in PlaidCloud Lakehouse, see What are Snapshot, Segment, and Block?.
See Also:
SQL Syntax
FUSE_SEGMENT('<database_name>', '<table_name>','<snapshot_id>')
SQL Examples
CREATE TABLE mytable(c int);
INSERT INTO mytable values(1);
INSERT INTO mytable values(2);
-- Obtain a snapshot ID
SELECT snapshot_id FROM FUSE_SNAPSHOT('default', 'mytable') limit 1;
---
+----------------------------------+
| snapshot_id |
+----------------------------------+
| 82c572947efa476892bd7c0635158ba2 |
+----------------------------------+
SELECT * FROM FUSE_SEGMENT('default', 'mytable', '82c572947efa476892bd7c0635158ba2');
---
+----------------------------------------------------+----------------+-------------+-----------+--------------------+------------------+
| file_location | format_version | block_count | row_count | bytes_uncompressed | bytes_compressed |
+----------------------------------------------------+----------------+-------------+-----------+--------------------+------------------+
| 1/319/_sg/d35fe7bf99584301b22e8f6a8a9c97f9_v1.json | 1 | 1 | 1 | 4 | 184 |
| 1/319/_sg/c261059d47c840e1b749222dabb4b2bb_v1.json | 1 | 1 | 1 | 4 | 184 |
+----------------------------------------------------+----------------+-------------+-----------+--------------------+------------------+
5.22.6 - FUSE_SNAPSHOT
Returns the snapshot information of a table. For more information about what is snapshot in PlaidCloud Lakehouse, see What are Snapshot, Segment, and Block?.
See Also:
SQL Syntax
FUSE_SNAPSHOT('<database_name>', '<table_name>')
SQL Examples
CREATE TABLE mytable(a int, b int) CLUSTER BY(a+1);
INSERT INTO mytable VALUES(1,1),(3,3);
INSERT INTO mytable VALUES(2,2),(5,5);
INSERT INTO mytable VALUES(4,4);
SELECT * FROM FUSE_SNAPSHOT('default','mytable');
---
| snapshot_id | snapshot_location | format_version | previous_snapshot_id | segment_count | block_count | row_count | bytes_uncompressed | bytes_compressed | index_size | timestamp |
|----------------------------------|------------------------------------------------------------|----------------|----------------------------------|---------------|-------------|-----------|--------------------|------------------|------------|----------------------------|
| a13d211b7421432898a3786848b8ced3 | 670655/783287/_ss/a13d211b7421432898a3786848b8ced3_v1.json | 1 | \N | 1 | 1 | 2 | 16 | 290 | 363 | 2022-09-19 14:51:52.860425 |
| cf08e6af6c134642aeb76bc81e6e7580 | 670655/783287/_ss/cf08e6af6c134642aeb76bc81e6e7580_v1.json | 1 | a13d211b7421432898a3786848b8ced3 | 2 | 2 | 4 | 32 | 580 | 726 | 2022-09-19 14:52:15.282943 |
| 1bd4f68b831a402e8c42084476461aa1 | 670655/783287/_ss/1bd4f68b831a402e8c42084476461aa1_v1.json | 1 | cf08e6af6c134642aeb76bc81e6e7580 | 3 | 3 | 5 | 40 | 862 | 1085 | 2022-09-19 14:52:20.284347 |
5.22.7 - FUSE_STATISTIC
Returns the estimated number of distinct values of each column in a table.
SQL Syntax
FUSE_STATISTIC('<database_name>', '<table_name>')
SQL Examples
You're most likely to use this function together with ANALYZE TABLE <table_name> to generate and check the statistical information of a table. For more explanations and examples, see OPTIMIZE TABLE.
5.22.8 - FUSE_TIME_TRAVEL_SIZE
Calculates the storage size of historical data (for Time Travel) for tables.
SQL Syntax
-- Calculate historical data size for all tables in all databases
SELECT ...
FROM fuse_time_travel_size();
-- Calculate historical data size for all tables in a specified database
SELECT ...
FROM fuse_time_travel_size('<database_name>');
-- Calculate historical data size for a specified table in a specified database
SELECT ...
FROM fuse_time_travel_size('<database_name>', '<table_name>'));
Output
The function returns a result set with the following columns:
| Column | Description |
|---|---|
database_name | The name of the database where the table is located. |
table_name | The name of the table. |
is_dropped | Indicates whether the table has been dropped (true for dropped tables, false otherwise). |
time_travel_size | The total storage size of historical data (for Time Travel) for the table, in bytes. |
latest_snapshot_size | The storage size of the latest snapshot of the table, in bytes. |
data_retention_period_in_hours | The retention period for Time Travel data in hours (NULL means using the default retention policy). |
error | Any error encountered while retrieving the storage size (NULL if no errors occurred). |
SQL Examples
This example calculates the historical data for all tables in the default database:
SELECT * FROM fuse_time_travel_size('default')
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ database_name │ table_name │ is_dropped │ time_travel_size │ latest_snapshot_size │ data_retention_period_in_hours │ error │
├───────────────┼────────────┼────────────┼──────────────────┼──────────────────────┼────────────────────────────────┼──────────────────┤
│ default │ books │ true │ 2810 │ 1490 │ NULL │ NULL │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.23 - Table Functions
This section provides reference information for the table-related functions in PlaidCloud Lakehouse.
5.23.1 - GENERATE_SERIES
Generates a dataset starting from a specified point, ending at another specified point, and optionally with an incrementing value. The GENERATE_SERIES function works with the following data types:
- Integer
- Date
- Timestamp
Analyze Syntax
func.generate_series(<start>, <stop>[, <step_interval>])
Analyze Examples
func.generate_series(1, 10, 2);
generate_series|
---------------+
1|
3|
5|
7|
9|
SQL Syntax
GENERATE_SERIES(<start>, <stop>[, <step_interval>])
Arguments
| Argument | Description |
|---|---|
| start | The starting value, representing the first number, date, or timestamp in the sequence. |
| stop | The ending value, representing the last number, date, or timestamp in the sequence. |
| step_interval | The step interval, determining the difference between adjacent values in the sequence. For integer sequences, the default value is 1. For date sequences, the default step interval is 1 day. For timestamp sequences, the default step interval is 1 microsecond. |
Return Type
Returns a list containing a continuous sequence of numeric values, dates, or timestamps from start to stop.
SQL Examples
SQL Examples 1: Generating Numeric, Date, and Timestamp Data
SELECT * FROM GENERATE_SERIES(1, 10, 2);
generate_series|
---------------+
1|
3|
5|
7|
9|
SELECT * FROM GENERATE_SERIES('2023-03-20'::date, '2023-03-27'::date);
generate_series|
---------------+
2023-03-20|
2023-03-21|
2023-03-22|
2023-03-23|
2023-03-24|
2023-03-25|
2023-03-26|
2023-03-27|
SELECT * FROM GENERATE_SERIES('2023-03-26 00:00'::timestamp, '2023-03-27 12:00'::timestamp, 86400000000);
generate_series |
-------------------+
2023-03-26 00:00:00|
2023-03-27 00:00:00|
SQL Examples 2: Filling Query Result Gaps
This example uses the GENERATE_SERIES function and left join operator to handle gaps in query results caused by missing information in specific ranges.
CREATE TABLE t_metrics (
date Date,
value INT
);
INSERT INTO t_metrics VALUES
('2020-01-01', 200),
('2020-01-01', 300),
('2020-01-04', 300),
('2020-01-04', 300),
('2020-01-05', 400),
('2020-01-10', 700);
SELECT date, SUM(value), COUNT() FROM t_metrics GROUP BY date ORDER BY date;
date |sum(value)|count()|
----------+----------+-------+
2020-01-01| 500| 2|
2020-01-04| 600| 2|
2020-01-05| 400| 1|
2020-01-10| 700| 1|
To close the gaps between January 1st and January 10th, 2020, use the following query:
SELECT t.date, COALESCE(SUM(t_metrics.value), 0), COUNT(t_metrics.value)
FROM generate_series(
'2020-01-01'::Date,
'2020-01-10'::Date
) AS t(date)
LEFT JOIN t_metrics ON t_metrics.date = t.date
GROUP BY t.date ORDER BY t.date;
date |coalesce(sum(t_metrics.value), 0)|count(t_metrics.value)|
----------+---------------------------------+----------------------+
2020-01-01| 500| 2|
2020-01-02| 0| 0|
2020-01-03| 0| 0|
2020-01-04| 600| 2|
2020-01-05| 400| 1|
2020-01-06| 0| 0|
2020-01-07| 0| 0|
2020-01-08| 0| 0|
2020-01-09| 0| 0|
2020-01-10| 700| 1|
5.23.2 - INFER_SCHEMA
Automatically detects the file metadata schema and retrieves the column definitions.
infer_schema currently only supports parquet file format.SQL Syntax
INFER_SCHEMA(
LOCATION => '{ internalStage | externalStage }'
[ PATTERN => '<regex_pattern>']
)
Where:
internalStage
internalStage ::= @<internal_stage_name>[/<path>]
externalStage
externalStage ::= @<external_stage_name>[/<path>]
PATTERN = 'regex_pattern'
A PCRE2-based regular expression pattern string, enclosed in single quotes, specifying the file names to match. Click here to see an example. For PCRE2 syntax, see http://www.pcre.org/current/doc/html/pcre2syntax.html.
SQL Examples
Generate a parquet file in a stage:
CREATE STAGE infer_parquet FILE_FORMAT = (TYPE = PARQUET);
COPY INTO @infer_parquet FROM (SELECT * FROM numbers(10)) FILE_FORMAT = (TYPE = PARQUET);
LIST @infer_parquet;
+-------------------------------------------------------+------+------------------------------------+-------------------------------+---------+
| name | size | md5 | last_modified | creator |
+-------------------------------------------------------+------+------------------------------------+-------------------------------+---------+
| data_e0fd9cba-f45c-4c43-aa07-d6d87d134378_0_0.parquet | 258 | "7DCC9FFE04EA1F6882AED2CF9640D3D4" | 2023-02-09 05:21:52.000 +0000 | NULL |
+-------------------------------------------------------+------+------------------------------------+-------------------------------+---------+
infer_schema
SELECT * FROM INFER_SCHEMA(location => '@infer_parquet/data_e0fd9cba-f45c-4c43-aa07-d6d87d134378_0_0.parquet');
+-------------+-----------------+----------+----------+
| column_name | type | nullable | order_id |
+-------------+-----------------+----------+----------+
| number | BIGINT UNSIGNED | 0 | 0 |
+-------------+-----------------+----------+----------+
infer_schema with Pattern Matching
SELECT * FROM infer_schema(location => '@infer_parquet/', pattern => '.*parquet');
+-------------+-----------------+----------+----------+
| column_name | type | nullable | order_id |
+-------------+-----------------+----------+----------+
| number | BIGINT UNSIGNED | 0 | 0 |
+-------------+-----------------+----------+----------+
Create a Table From Parquet File
The infer_schema can only display the schema of a parquet file and cannot create a table from it.
To create a table from a parquet file:
CREATE TABLE mytable AS SELECT * FROM @infer_parquet/ (pattern=>'.*parquet') LIMIT 0;
DESC mytable;
+--------+-----------------+------+---------+-------+
| Field | Type | Null | Default | Extra |
+--------+-----------------+------+---------+-------+
| number | BIGINT UNSIGNED | NO | 0 | |
+--------+-----------------+------+---------+-------+
5.23.3 - INSPECT_PARQUET
Retrieves a table of comprehensive metadata from a staged Parquet file, including the following columns:
| Column | Description |
|---|---|
| created_by | The entity or source responsible for creating the Parquet file |
| num_columns | The number of columns in the Parquet file |
| num_rows | The total number of rows or records in the Parquet file |
| num_row_groups | The count of row groups within the Parquet file |
| serialized_size | The size of the Parquet file on disk (compressed) |
| max_row_groups_size_compressed | The size of the largest row group (compressed) |
| max_row_groups_size_uncompressed | The size of the largest row group (uncompressed) |
SQL Syntax
INSPECT_PARQUET('@<path-to-file>')
SQL Examples
This example retrieves the metadata from a staged sample Parquet file named books.parquet. The file contains two records:
Transaction Processing,Jim Gray,1992
Readings in Database Systems,Michael Stonebraker,2004
-- Show the staged file
LIST @my_internal_stage;
┌──────────────────────────────────────────────────────────────────────────────────────────────┐
│ name │ size │ md5 │ last_modified │ creator │
├───────────────┼────────┼──────────────────┼───────────────────────────────┼──────────────────┤
│ books.parquet │ 998 │ NULL │ 2023-04-19 19:34:51.303 +0000 │ NULL │
└──────────────────────────────────────────────────────────────────────────────────────────────┘
-- Retrieve metadata from the staged file
SELECT * FROM INSPECT_PARQUET('@my_internal_stage/books.parquet');
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ created_by │ num_columns │ num_rows │ num_row_groups │ serialized_size │ max_row_groups_size_compressed │ max_row_groups_size_uncompressed │
├────────────────────────────────────┼─────────────┼──────────┼────────────────┼─────────────────┼────────────────────────────────┼──────────────────────────────────┤
│ parquet-cpp version 1.5.1-SNAPSHOT │ 3 │ 2 │ 1 │ 998 │ 332 │ 320 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
5.23.4 - LIST_STAGE
Lists files in a stage. This allows you to filter files in a stage based on their extensions and obtain comprehensive details about each file. The function is similar to the DDL command LIST STAGE FILES, but provides you the flexibility to retrieve specific file information with the SELECT statement, such as file name, size, MD5 hash, last modified timestamp, and creator, rather than all file information.
SQL Syntax
LIST_STAGE(
LOCATION => '{ internalStage | externalStage | userStage }'
[ PATTERN => '<regex_pattern>']
)
Where:
internalStage
internalStage ::= @<internal_stage_name>[/<path>]
externalStage
externalStage ::= @<external_stage_name>[/<path>]
userStage
userStage ::= @~[/<path>]
PATTERN
See COPY INTO table.
SQL Examples
SELECT * FROM list_stage(location => '@my_stage/', pattern => '.*[.]log');
+----------------+------+------------------------------------+-------------------------------+---------+
| name | size | md5 | last_modified | creator |
+----------------+------+------------------------------------+-------------------------------+---------+
| 2023/meta.log | 475 | "4208ff530b252236e14b3cd797abdfbd" | 2023-04-19 20:23:24.000 +0000 | NULL |
| 2023/query.log | 1348 | "1c6654b207472c277fc8c6207c035e18" | 2023-04-19 20:23:24.000 +0000 | NULL |
+----------------+------+------------------------------------+-------------------------------+---------+
-- Equivalent to the following statement:
LIST @my_stage PATTERN = '.log';
5.23.5 - RESULT_SCAN
Returns the result set of a previous command in same session as if the result was a table.
SQL Syntax
RESULT_SCAN( { '<query_id>' | LAST_QUERY_ID() } )
SQL Examples
Create a simple table:
CREATE TABLE t1(a int);
Insert some values;
INSERT INTO t1(a) VALUES (1), (2), (3);
result_scan
SELECT * FROM t1 ORDER BY a;
+-------+
| a |
+-------+
| 1 |
+-------+
| 2 |
+-------+
| 3 |
+-------+
SELECT * FROM RESULT_SCAN(LAST_QUERY_ID()) ORDER BY a;
+-------+
| a |
+-------+
| 1 |
+-------+
| 2 |
+-------+
| 3 |
+-------+
5.23.6 - SHOW_GRANTS
Lists privileges explicitly granted to a user, to a role, or on a specific object.
SQL Syntax
SHOW_GRANTS('role', '<role_name>')
SHOW_GRANTS('user', '<user_name>')
SHOW_GRANTS('stage', '<stage_name>')
SHOW_GRANTS('udf', '<udf_name>')
SHOW_GRANTS('table', '<table_name>', '<catalog_name>', '<db_name>')
SHOW_GRANTS('database', '<db_name>', '<catalog_name>')
Configuring enable_expand_roles Setting
The enable_expand_roles setting controls whether the SHOW_GRANTS function expands role inheritance when displaying privileges.
enable_expand_roles=1(default):- SHOW_GRANTS recursively expands inherited privileges, meaning that if a role has been granted another role, it will display all the inherited privileges.
- Users will also see all privileges granted through their assigned roles.
enable_expand_roles=0:- SHOW_GRANTS only displays privileges that are directly assigned to the specified role or user.
- However, the result will still include GRANT ROLE statements to indicate role inheritance.
For example, role a has the SELECT privilege on t1, and role b has the SELECT privilege on t2:
SELECT grants FROM show_grants('role', 'a') ORDER BY object_id;
┌──────────────────────────────────────────────────────┐
│ grants │
├──────────────────────────────────────────────────────┤
│ GRANT SELECT ON 'default'.'default'.'t1' TO ROLE `a` │
└──────────────────────────────────────────────────────┘
SELECT grants FROM show_grants('role', 'b') ORDER BY object_id;
┌──────────────────────────────────────────────────────┐
│ grants │
├──────────────────────────────────────────────────────┤
│ GRANT SELECT ON 'default'.'default'.'t2' TO ROLE `b` │
└──────────────────────────────────────────────────────┘
If you grant role b to role a and check the grants on role a again, you can see than the SELECT privilege on t2 is now included in role a:
GRANT ROLE b TO ROLE a;
SELECT grants FROM show_grants('role', 'a') ORDER BY object_id;
┌──────────────────────────────────────────────────────┐
│ grants │
├──────────────────────────────────────────────────────┤
│ GRANT SELECT ON 'default'.'default'.'t1' TO ROLE `a` │
│ GRANT SELECT ON 'default'.'default'.'t2' TO ROLE `a` │
└──────────────────────────────────────────────────────┘
If you set enable_expand_roles to 0 and check the grants on role a again, the result will show the GRANT ROLE statement instead of listing the specific privileges inherited from role b:
SET enable_expand_roles=0;
SELECT grants FROM show_grants('role', 'a') ORDER BY object_id;
┌──────────────────────────────────────────────────────┐
│ grants │
├──────────────────────────────────────────────────────┤
│ GRANT SELECT ON 'default'.'default'.'t1' TO ROLE `a` │
│ GRANT ROLE b to ROLE `a` │
│ GRANT ROLE public to ROLE `a` │
└──────────────────────────────────────────────────────┘
SQL Examples
This example illustrates how to list privileges granted to a user, a role, and on a specific object.
-- Create a new user
CREATE USER 'user1' IDENTIFIED BY 'password';
-- Create a new role
CREATE ROLE analyst;
-- Grant the analyst role to the user
GRANT ROLE analyst TO 'user1';
-- Create a stage
CREATE STAGE my_stage;
-- Grant privileges on the stage to the role
GRANT READ ON STAGE my_stage TO ROLE analyst;
-- List privileges granted to the user
SELECT * FROM SHOW_GRANTS('user', 'user1');
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ privileges │ object_name │ object_id │ grant_to │ name │ grants │
├────────────┼─────────────┼──────────────────┼──────────┼────────┼─────────────────────────────────────────────┤
│ Read │ my_stage │ NULL │ USER │ user1 │ GRANT Read ON STAGE my_stage TO 'user1'@'%' │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- List privileges granted to the role
SELECT * FROM SHOW_GRANTS('role', 'analyst');
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ privileges │ object_name │ object_id │ grant_to │ name │ grants │
├────────────┼─────────────┼──────────────────┼──────────┼─────────┼────────────────────────────────────────────────┤
│ Read │ my_stage │ NULL │ ROLE │ analyst │ GRANT Read ON STAGE my_stage TO ROLE `analyst` │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
-- List privileges granted on the stage
SELECT * FROM SHOW_GRANTS('stage', 'my_stage');
┌─────────────────────────────────────────────────────────────────────────────────────┐
│ privileges │ object_name │ object_id │ grant_to │ name │ grants │
├────────────┼─────────────┼──────────────────┼──────────┼─────────┼──────────────────┤
│ Read │ my_stage │ NULL │ ROLE │ analyst │ │
└─────────────────────────────────────────────────────────────────────────────────────┘
5.23.7 - STREAM_STATUS
Provides information about the status of a specified stream, yielding a single-column result (has_data) that can take on values of true or false:
true: Indicates that the stream might contain change data capture records.false: Indicates that the stream currently does not contain any change data capture records.
:::note
The presence of a true in the result (has_data) does not ensure the definite existence of change data capture records. Other operations, such as performing a table compact operation, could also lead to a true value even when there are no actual change data capture records.
:::
:::note
When using STREAM_STATUS in tasks, you must include the database name when referencing the stream (e.g., STREAM_STATUS('mydb.stream_name')).
:::
SQL Syntax
SELECT * FROM STREAM_STATUS('<database_name>.<stream_name>');
-- OR
SELECT * FROM STREAM_STATUS('<stream_name>'); -- Uses current database
SQL Examples
-- Create a table 't' with a column 'c'
CREATE TABLE t (c int);
-- Create a stream 's' on the table 't'
CREATE STREAM s ON TABLE t;
-- Check the initial status of the stream 's'
SELECT * FROM STREAM_STATUS('s');
-- The result should be 'false' indicating no change data capture records initially
┌──────────┐
│ has_data │
├──────────┤
│ false │
└──────────┘
-- Insert a value into the table 't'
INSERT INTO t VALUES (1);
-- Check the updated status of the stream 's' after the insertion
SELECT * FROM STREAM_STATUS('s');
-- The result should now be 'true' indicating the presence of change data capture records
┌──────────┐
│ has_data │
├──────────┤
│ true │
└──────────┘
-- Example with database name specified
SELECT * FROM STREAM_STATUS('mydb.s');
5.23.8 - TASK_HISTORY
Displays task running history given variables.
SQL Syntax
TASK_HISTORY(
[ SCHEDULED_TIME_RANGE_START => <constant_expr> ]
[, SCHEDULED_TIME_RANGE_END => <constant_expr> ]
[, RESULT_LIMIT => <integer> ]
[, TASK_NAME => '<string>' ]
[, ERROR_ONLY => { TRUE | FALSE } ]
[, ROOT_TASK_ID => '<string>'] )
Arguments
All the arguments are optional.
SCHEDULED_TIME_RANGE_START => <constant_expr>, SCHEDULED_TIME_RANGE_END => <constant_expr>
Time range (in TIMESTAMP_LTZ format), within the last 7 days, in which the task execution was scheduled. If the time range does not fall within the last 7 days, an error is returned.
- If
SCHEDULED_TIME_RANGE_ENDis not specified, the function returns those tasks that have already completed, are currently running, or are scheduled in the future. - If
SCHEDULED_TIME_RANGE_ENDis CURRENT_TIMESTAMP, the function returns those tasks that have already completed or are currently running. Note that a task that is executed immediately before the current time might still be identified as scheduled. - To query only those tasks that have already completed or are currently running, include
WHERE query_id IS NOT NULLas a filter. The QUERY_ID column in the TASK_HISTORY output is populated only when a task has started running.
If no start or end time is specified, the most recent tasks are returned, up to the specified RESULT_LIMIT value.
RESULT_LIMIT => <integer>
A number specifying the maximum number of rows returned by the function.
If the number of matching rows is greater than this limit, the task executions with the most recent timestamp are returned, up to the specified limit.
Range: 1 to 10000
Default: 100.
TASK_NAME => <string>
A case-insensitive string specifying a task. Only non-qualified task names are supported. Only executions of the specified task are returned. Note that if multiple tasks have the same name, the function returns the history for each of these tasks.
ERROR_ONLY => { TRUE | FALSE }
When set to TRUE, this function returns only task runs that failed or were cancelled.
ROOT_TASK_ID => <string>
Unique identifier for the root task in a task graph. This ID matches the ID column value in the SHOW TASKS output for the same task. Specify the ROOT_TASK_ID to show the history of the root task and any child tasks that are part of the task graph.
Usage Notes
- This function returns a maximum of 10,000 rows, set in the RESULT_LIMIT argument value. The default value is 100.
- This function returns results only for the ACCOUNTADMIN role.
SQL Examples
SELECT
*
FROM TASK_HISTORY() order by scheduled_time;
The above SQL query retrieves all task history records from the TASK_HISTORY function, ordered by the scheduled_time column.(maximum 10,000)
SELECT *
FROM TASK_HISTORY(
SCHEDULED_TIME_RANGE_START=>TO_TIMESTAMP('2022-01-02T01:12:00-07:00'),
SCHEDULED_TIME_RANGE_END=>TO_TIMESTAMP('2022-01-02T01:12:30-07:00'))
The above SQL query retrieves all task history records from the TASK_HISTORY function where the scheduled time range starts at '2022-01-02T01:12:00-07:00' and ends at '2022-01-02T01:12:30-07:00'. This means it will return the tasks that were scheduled to run within this specific 30-second time window. The result will include details of the tasks that match this criteria.
5.24 - Test Functions
This section provides reference information for test functions in PlaidCloud Lakehouse.
5.24.1 - SLEEP
Sleeps seconds seconds on each data block.
!!! warning Only used for testing where sleep is required.
SQL Syntax
SLEEP(seconds)
Arguments
| Arguments | Description |
|---|---|
| seconds | Must be a constant column of any nonnegative number or float.| |
Return Type
UInt8
SQL Examples
SELECT sleep(2);
+----------+
| sleep(2) |
+----------+
| 0 |
+----------+
5.25 - UUID Functions
This section provides reference information for the UUID-related functions in PlaidCloud Lakehouse.
5.25.1 - GEN_RANDOM_UUID
Generates a random UUID based on v4.
Analyze Syntax
func.gen_random_uuid()
SQL Examples
func.gen_random_uuid()
┌───────────────────────────────────────┐
│ func.gen_random_uuid() │
├───────────────────────────────────────|
│ f88e7efe-1bc2-494b-806b-3ffe90db8f47 │
└───────────────────────────────────────┘
SQL Syntax
GEN_RANDOM_UUID()
Aliases
SQL Examples
SELECT GEN_RANDOM_UUID(), UUID();
┌─────────────────────────────────────────────────────────────────────────────┐
│ gen_random_uuid() │ uuid() │
├──────────────────────────────────────┼──────────────────────────────────────┤
│ f88e7efe-1bc2-494b-806b-3ffe90db8f47 │ f88e7efe-1bc2-494b-806b-3ffe90db8f47 │
└─────────────────────────────────────────────────────────────────────────────┘
5.25.2 - UUID
Alias for GEN_RANDOM_UUID.
5.26 - Window Functions
Overview
A window function operates on a group ("window") of related rows.
For each input row, a window function returns one output row that depends on the specific row passed to the function and the values of the other rows in the window.
There are two main types of order-sensitive window functions:
Rank-related functions: Rank-related functions list information based on the "rank" of a row. For example, ranking stores in descending order by profit per year, the store with the most profit will be ranked 1, and the second-most profitable store will be ranked 2, and so on.Window frame functions: Window frame functions enable you to perform rolling operations, such as calculating a running total or a moving average, on a subset of the rows in the window.
List of Functions that Support Windows
The list below shows all the window functions.
| Function Name | Category | Window | Window Frame | Notes |
|---|---|---|---|---|
| ARRAY_AGG | General | ✔ | ||
| AVG | General | ✔ | ✔ | |
| AVG_IF | General | ✔ | ✔ | |
| COUNT | General | ✔ | ✔ | |
| COUNT_IF | General | ✔ | ✔ | |
| COVAR_POP | General | ✔ | ||
| COVAR_SAMP | General | ✔ | ||
| MAX | General | ✔ | ✔ | |
| MAX_IF | General | ✔ | ✔ | |
| MIN | General | ✔ | ✔ | |
| MIN_IF | General | ✔ | ✔ | |
| STDDEV_POP | General | ✔ | ✔ | |
| STDDEV_SAMP | General | ✔ | ✔ | |
| MEDIAN | General | ✔ | ✔ | |
| QUANTILE_CONT | General | ✔ | ✔ | |
| QUANTILE_DISC | General | ✔ | ✔ | |
| KURTOSIS | General | ✔ | ✔ | |
| SKEWNESS | General | ✔ | ✔ | |
| SUM | General | ✔ | ✔ | |
| SUM_IF | General | ✔ | ✔ | |
| CUME_DIST | Rank-related | ✔ | ||
| PERCENT_RANK | Rank-related | ✔ | ✔ | |
| DENSE_RANK | Rank-related | ✔ | ✔ | |
| RANK | Rank-related | ✔ | ✔ | |
| ROW_NUMBER | Rank-related | ✔ | ||
| NTILE | Rank-related | ✔ | ||
| FIRST_VALUE | Rank-related | ✔ | ✔ | |
| FIRST | Rank-related | ✔ | ✔ | |
| LAST_VALUE | Rank-related | ✔ | ✔ | |
| LAST | Rank-related | ✔ | ✔ | |
| NTH_VALUE | Rank-related | ✔ | ✔ | |
| LEAD | Rank-related | ✔ | ||
| LAG | Rank-related | ✔ |
Window Syntax
<function> ( [ <arguments> ] ) OVER ( { named window | inline window } )
named window ::=
{ window_name | ( window_name ) }
inline window ::=
[ PARTITION BY <expression_list> ]
[ ORDER BY <expression_list> ]
[ window frame ]
The named window is a window that is defined in the WINDOW clause of the SELECT statement, eg: SELECT a, SUM(a) OVER w FROM t WINDOW w AS ( inline window ).
The <function> is one of (aggregate function, rank function, value function).
The OVER clause specifies that the function is being used as a window function.
The PARTITION BY sub-clause allows rows to be grouped into sub-groups, for example by city, by year, etc. The PARTITION BY clause is optional. You can analyze an entire group of rows without breaking it into sub-groups.
The ORDER BY clause orders rows within the window.
The window frame clause specifies the window frame type and the window frame extent. The window frame clause is optional. If you omit the window frame clause, the default window frame type is RANGE and the default window frame extent is UNBOUNDED PRECEDING AND CURRENT ROW.
Window Frame Syntax
window frame can be one of the following types:
cumulativeFrame ::=
{
{ ROWS | RANGE } BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
| { ROWS | RANGE } BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
}
slidingFrame ::=
{
ROWS BETWEEN <N> { PRECEDING | FOLLOWING } AND <N> { PRECEDING | FOLLOWING }
| ROWS BETWEEN UNBOUNDED PRECEDING AND <N> { PRECEDING | FOLLOWING }
| ROWS BETWEEN <N> { PRECEDING | FOLLOWING } AND UNBOUNDED FOLLOWING
}
SQL Examples
Create the table
CREATE TABLE employees (
employee_id INT,
first_name VARCHAR,
last_name VARCHAR,
department VARCHAR,
salary INT
);
Insert data
INSERT INTO employees (employee_id, first_name, last_name, department, salary) VALUES
(1, 'John', 'Doe', 'IT', 75000),
(2, 'Jane', 'Smith', 'HR', 85000),
(3, 'Mike', 'Johnson', 'IT', 90000),
(4, 'Sara', 'Williams', 'Sales', 60000),
(5, 'Tom', 'Brown', 'HR', 82000),
(6, 'Ava', 'Davis', 'Sales', 62000),
(7, 'Olivia', 'Taylor', 'IT', 72000),
(8, 'Emily', 'Anderson', 'HR', 77000),
(9, 'Sophia', 'Lee', 'Sales', 58000),
(10, 'Ella', 'Thomas', 'IT', 67000);
Example 1: Ranking employees by salary
In this example, we use the RANK() function to rank employees based on their salaries in descending order. The highest salary will get a rank of 1, and the lowest salary will get the highest rank number.
SELECT employee_id, first_name, last_name, department, salary, RANK() OVER (ORDER BY salary DESC) AS rank
FROM employees;
Result:
| employee_id | first_name | last_name | department | salary | rank |
|---|---|---|---|---|---|
| 3 | Mike | Johnson | IT | 90000 | 1 |
| 2 | Jane | Smith | HR | 85000 | 2 |
| 5 | Tom | Brown | HR | 82000 | 3 |
| 8 | Emily | Anderson | HR | 77000 | 4 |
| 1 | John | Doe | IT | 75000 | 5 |
| 7 | Olivia | Taylor | IT | 72000 | 6 |
| 10 | Ella | Thomas | IT | 67000 | 7 |
| 6 | Ava | Davis | Sales | 62000 | 8 |
| 4 | Sara | Williams | Sales | 60000 | 9 |
| 9 | Sophia | Lee | Sales | 58000 | 10 |
Example 2: Calculating the total salary per department
In this example, we use the SUM() function with PARTITION BY to calculate the total salary paid per department. Each row will show the department and the total salary for that department.
SELECT department, SUM(salary) OVER (PARTITION BY department) AS total_salary
FROM employees;
Result:
| department | total_salary |
|---|---|
| HR | 244000 |
| HR | 244000 |
| HR | 244000 |
| IT | 304000 |
| IT | 304000 |
| IT | 304000 |
| IT | 304000 |
| Sales | 180000 |
| Sales | 180000 |
| Sales | 180000 |
Example 3: Calculating a running total of salaries per department
In this example, we use the SUM() function with a cumulative window frame to calculate a running total of salaries within each department. The running total is calculated based on the employee's salary ordered by their employee_id.
SELECT employee_id, first_name, last_name, department, salary,
SUM(salary) OVER (PARTITION BY department ORDER BY employee_id
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS running_total
FROM employees;
Result:
| employee_id | first_name | last_name | department | salary | running_total |
|---|---|---|---|---|---|
| 2 | Jane | Smith | HR | 85000 | 85000 |
| 5 | Tom | Brown | HR | 82000 | 167000 |
| 8 | Emily | Anderson | HR | 77000 | 244000 |
| 1 | John | Doe | IT | 75000 | 75000 |
| 3 | Mike | Johnson | IT | 90000 | 165000 |
| 7 | Olivia | Taylor | IT | 72000 | 237000 |
| 10 | Ella | Thomas | IT | 67000 | 304000 |
| 4 | Sara | Williams | Sales | 60000 | 60000 |
| 6 | Ava | Davis | Sales | 62000 | 122000 |
| 9 | Sophia | Lee | Sales | 58000 | 180000 |
5.26.1 - CUME_DIST
Returns the cumulative distribution of a given value in a set of values. It calculates the proportion of rows that have values less than or equal to the specified value, divided by the total number of rows. Please note that the resulting value falls between 0 and 1, inclusive.
See also: PERCENT_RANK
Analyze Syntax
func.cume_dist().over(partition_by=[<columns>], order_by=[<columns>])
Analyze Examples
table.name, table.score, table.grade, func.cume_dist().over(partition_by=[table.grade], order_by=table.score).alias('cume_dist_val')
name |score|grade|cume_dist_val|
--------+-----+-----+-------------+
Smith | 81|A | 0.25|
Davies | 84|A | 0.5|
Evans | 87|A | 0.75|
Johnson | 100|A | 1.0|
Taylor | 62|B | 0.5|
Brown | 62|B | 0.5|
Wilson | 72|B | 1.0|
Thomas | 72|B | 1.0|
Jones | 55|C | 1.0|
Williams| 55|C | 1.0|
SQL Syntax
CUME_DIST() OVER (
PARTITION BY expr, ...
ORDER BY expr [ASC | DESC], ...
)
SQL Examples
This example retrieves the students' names, scores, grades, and the cumulative distribution values (cume_dist_val) within each grade using the CUME_DIST() window function.
CREATE TABLE students (
name VARCHAR(20),
score INT NOT NULL,
grade CHAR(1) NOT NULL
);
INSERT INTO students (name, score, grade)
VALUES
('Smith', 81, 'A'),
('Jones', 55, 'C'),
('Williams', 55, 'C'),
('Taylor', 62, 'B'),
('Brown', 62, 'B'),
('Davies', 84, 'A'),
('Evans', 87, 'A'),
('Wilson', 72, 'B'),
('Thomas', 72, 'B'),
('Johnson', 100, 'A');
SELECT
name,
score,
grade,
CUME_DIST() OVER (PARTITION BY grade ORDER BY score) AS cume_dist_val
FROM
students;
name |score|grade|cume_dist_val|
--------+-----+-----+-------------+
Smith | 81|A | 0.25|
Davies | 84|A | 0.5|
Evans | 87|A | 0.75|
Johnson | 100|A | 1.0|
Taylor | 62|B | 0.5|
Brown | 62|B | 0.5|
Wilson | 72|B | 1.0|
Thomas | 72|B | 1.0|
Jones | 55|C | 1.0|
Williams| 55|C | 1.0|
5.26.2 - DENSE_RANK
Returns the rank of a value within a group of values, without gaps in the ranks.
The rank value starts at 1 and continues up sequentially.
If two values are the same, they have the same rank.
Analyze Syntax
func.dense_rank().over(partition_by=[<columns>], order_by=[<columns>])
Analyze Examples
table.department, func.sum(salary), func.dense_rank().over(order_by=func.sum(table.salary).desc()).alias('dense_rank')
| department | total_salary | dense_rank |
|------------|--------------|------------|
| IT | 172000 | 1 |
| HR | 160000 | 2 |
| Sales | 77000 | 3 |
SQL Syntax
DENSE_RANK() OVER ( [ PARTITION BY <expr1> ] ORDER BY <expr2> [ ASC | DESC ] [ <window_frame> ] )
SQL Examples
Create the table
CREATE TABLE employees (
employee_id INT,
first_name VARCHAR,
last_name VARCHAR,
department VARCHAR,
salary INT
);
Insert data
INSERT INTO employees (employee_id, first_name, last_name, department, salary) VALUES
(1, 'John', 'Doe', 'IT', 90000),
(2, 'Jane', 'Smith', 'HR', 85000),
(3, 'Mike', 'Johnson', 'IT', 82000),
(4, 'Sara', 'Williams', 'Sales', 77000),
(5, 'Tom', 'Brown', 'HR', 75000);
Calculating the total salary per department using DENSE_RANK
SELECT
department,
SUM(salary) AS total_salary,
DENSE_RANK() OVER (ORDER BY SUM(salary) DESC) AS dense_rank
FROM
employees
GROUP BY
department;
Result:
| department | total_salary | dense_rank |
|---|---|---|
| IT | 172000 | 1 |
| HR | 160000 | 2 |
| Sales | 77000 | 3 |
5.26.3 - FIRST
Alias for FIRST_VALUE.
5.26.4 - FIRST_VALUE
Returns the first value from an ordered group of values.
See also:
Analyze Syntax
func.first_value(<expr>).over(partition_by=[<columns>], order_by=[<columns>])
Analyze Examples
table.employee_id, table.first_name, table.last_name, table.salary, func.first_value(table.first_name).over(order_by=table.salary.desc()).alias('highest_salary_first_name')
employee_id | first_name | last_name | salary | highest_salary_first_name
------------+------------+-----------+---------+--------------------------
4 | Mary | Williams | 7000.00 | Mary
2 | Jane | Smith | 6000.00 | Mary
3 | David | Johnson | 5500.00 | Mary
1 | John | Doe | 5000.00 | Mary
5 | Michael | Brown | 4500.00 | Mary
SQL Syntax
FIRST_VALUE(expression) OVER ([PARTITION BY partition_expression] ORDER BY order_expression [window_frame])
For the syntax of window frame, see Window Frame Syntax.
SQL Examples
CREATE TABLE employees (
employee_id INT,
first_name VARCHAR(50),
last_name VARCHAR(50),
salary DECIMAL(10,2)
);
INSERT INTO employees (employee_id, first_name, last_name, salary)
VALUES
(1, 'John', 'Doe', 5000.00),
(2, 'Jane', 'Smith', 6000.00),
(3, 'David', 'Johnson', 5500.00),
(4, 'Mary', 'Williams', 7000.00),
(5, 'Michael', 'Brown', 4500.00);
-- Use FIRST_VALUE to retrieve the first name of the employee with the highest salary
SELECT employee_id, first_name, last_name, salary,
FIRST_VALUE(first_name) OVER (ORDER BY salary DESC) AS highest_salary_first_name
FROM employees;
employee_id | first_name | last_name | salary | highest_salary_first_name
------------+------------+-----------+---------+--------------------------
4 | Mary | Williams | 7000.00 | Mary
2 | Jane | Smith | 6000.00 | Mary
3 | David | Johnson | 5500.00 | Mary
1 | John | Doe | 5000.00 | Mary
5 | Michael | Brown | 4500.00 | Mary
5.26.5 - LAG
LAG allows you to access the value of a column from a preceding row within the same result set. It is typically used to retrieve the value of a column in the previous row, based on a specified ordering.
See also: LEAD
Analyze Syntax
func.lag(<expr>, <offset>).over(partition_by=[<columns>], order_by=[<columns>])
Analyze Examples
table.product_name, table.sale_amount, func.lag(table.sale_amount, 1).over(partition_by=table.product_name, order_by=table.sale_id).alias('previous_sale_amount')
product_name | sale_amount | previous_sale_amount
-----------------------------------------------
Product A | 1000.00 | NULL
Product A | 1500.00 | 1000.00
Product A | 2000.00 | 1500.00
Product B | 500.00 | NULL
Product B | 800.00 | 500.00
Product B | 1200.00 | 800.00
SQL Syntax
LAG(expression [, offset [, default]]) OVER (PARTITION BY partition_expression ORDER BY sort_expression)
- offset: Specifies the number of rows ahead (LEAD) or behind (LAG) the current row within the partition to retrieve the value from. Defaults to 1.
Note that setting a negative offset has the same effect as using the LEAD function.
- default: Specifies a value to be returned if the LEAD or LAG function encounters a situation where there is no value available due to the offset exceeding the partition's boundaries. Defaults to NULL.
SQL Examples
CREATE TABLE sales (
sale_id INT,
product_name VARCHAR(50),
sale_amount DECIMAL(10, 2)
);
INSERT INTO sales (sale_id, product_name, sale_amount)
VALUES (1, 'Product A', 1000.00),
(2, 'Product A', 1500.00),
(3, 'Product A', 2000.00),
(4, 'Product B', 500.00),
(5, 'Product B', 800.00),
(6, 'Product B', 1200.00);
SELECT product_name, sale_amount, LAG(sale_amount) OVER (PARTITION BY product_name ORDER BY sale_id) AS previous_sale_amount
FROM sales;
product_name | sale_amount | previous_sale_amount
-----------------------------------------------
Product A | 1000.00 | NULL
Product A | 1500.00 | 1000.00
Product A | 2000.00 | 1500.00
Product B | 500.00 | NULL
Product B | 800.00 | 500.00
Product B | 1200.00 | 800.00
-- The following statements return the same result.
SELECT product_name, sale_amount, LAG(sale_amount, -1) OVER (PARTITION BY product_name ORDER BY sale_id) AS next_sale_amount
FROM sales;
SELECT product_name, sale_amount, LEAD(sale_amount) OVER (PARTITION BY product_name ORDER BY sale_id) AS next_sale_amount
FROM sales;
product_name|sale_amount|next_sale_amount|
------------+-----------+----------------+
Product A | 1000.00| 1500.00|
Product A | 1500.00| 2000.00|
Product A | 2000.00| |
Product B | 500.00| 800.00|
Product B | 800.00| 1200.00|
Product B | 1200.00| |
5.26.6 - LAST
Alias for LAST_VALUE.
5.26.7 - LAST_VALUE
Returns the last value from an ordered group of values.
See also:
Analyze Syntax
func.last_value(<expr>).over(partition_by=[<columns>], order_by=[<columns>])
Analyze Examples
table.employee_id, table.first_name, table.last_name, table.salary, func.last_value(table.first_name).over(order_by=table.salary.desc()).alias('lowest_salary_first_name')
employee_id | first_name | last_name | salary | lowest_salary_first_name
------------+------------+-----------+---------+------------------------
4 | Mary | Williams | 7000.00 | Michael
2 | Jane | Smith | 6000.00 | Michael
3 | David | Johnson | 5500.00 | Michael
1 | John | Doe | 5000.00 | Michael
5 | Michael | Brown | 4500.00 | Michael
SQL Syntax
LAST_VALUE(expression) OVER ([PARTITION BY partition_expression] ORDER BY order_expression [window_frame])
For the syntax of window frame, see Window Frame Syntax.
SQL Examples
CREATE TABLE employees (
employee_id INT,
first_name VARCHAR(50),
last_name VARCHAR(50),
salary DECIMAL(10,2)
);
INSERT INTO employees (employee_id, first_name, last_name, salary)
VALUES
(1, 'John', 'Doe', 5000.00),
(2, 'Jane', 'Smith', 6000.00),
(3, 'David', 'Johnson', 5500.00),
(4, 'Mary', 'Williams', 7000.00),
(5, 'Michael', 'Brown', 4500.00);
-- Use LAST_VALUE to retrieve the first name of the employee with the lowest salary
SELECT employee_id, first_name, last_name, salary,
LAST_VALUE(first_name) OVER (ORDER BY salary DESC) AS lowest_salary_first_name
FROM employees;
employee_id | first_name | last_name | salary | lowest_salary_first_name
------------+------------+-----------+---------+------------------------
4 | Mary | Williams | 7000.00 | Michael
2 | Jane | Smith | 6000.00 | Michael
3 | David | Johnson | 5500.00 | Michael
1 | John | Doe | 5000.00 | Michael
5 | Michael | Brown | 4500.00 | Michael
5.26.8 - LEAD
LEAD allows you to access the value of a column from a subsequent row within the same result set. It is typically used to retrieve the value of a column in the next row, based on a specified ordering.
See also: LAG
Analyze Syntax
func.lead(<expr>, <offset>).over(partition_by=[<columns>], order_by=[<columns>])
Analyze Examples
table.product_name, table.sale_amount, func.lead(table.sale_amount, 1).over(partition_by=table.product_name, order_by=table.sale_id).alias('next_sale_amount')
product_name | sale_amount | next_sale_amount
----------------------------------------------
Product A | 1000.00 | 1500.00
Product A | 1500.00 | 2000.00
Product A | 2000.00 | NULL
Product B | 500.00 | 800.00
Product B | 800.00 | 1200.00
Product B | 1200.00 | NULL
SQL Syntax
LEAD(expression [, offset [, default]]) OVER (PARTITION BY partition_expression ORDER BY sort_expression)
- offset: Specifies the number of rows ahead (LEAD) or behind (LAG) the current row within the partition to retrieve the value from. Defaults to 1.
Note that setting a negative offset has the same effect as using the LAG function.
- default: Specifies a value to be returned if the LEAD or LAG function encounters a situation where there is no value available due to the offset exceeding the partition's boundaries. Defaults to NULL.
SQL Examples
CREATE TABLE sales (
sale_id INT,
product_name VARCHAR(50),
sale_amount DECIMAL(10, 2)
);
INSERT INTO sales (sale_id, product_name, sale_amount)
VALUES (1, 'Product A', 1000.00),
(2, 'Product A', 1500.00),
(3, 'Product A', 2000.00),
(4, 'Product B', 500.00),
(5, 'Product B', 800.00),
(6, 'Product B', 1200.00);
SELECT product_name, sale_amount, LEAD(sale_amount) OVER (PARTITION BY product_name ORDER BY sale_id) AS next_sale_amount
FROM sales;
product_name | sale_amount | next_sale_amount
----------------------------------------------
Product A | 1000.00 | 1500.00
Product A | 1500.00 | 2000.00
Product A | 2000.00 | NULL
Product B | 500.00 | 800.00
Product B | 800.00 | 1200.00
Product B | 1200.00 | NULL
-- The following statements return the same result.
SELECT product_name, sale_amount, LEAD(sale_amount, -1) OVER (PARTITION BY product_name ORDER BY sale_id) AS previous_sale_amount
FROM sales;
SELECT product_name, sale_amount, LAG(sale_amount) OVER (PARTITION BY product_name ORDER BY sale_id) AS previous_sale_amount
FROM sales;
product_name|sale_amount|previous_sale_amount|
------------+-----------+--------------------+
Product A | 1000.00| |
Product A | 1500.00| 1000.00|
Product A | 2000.00| 1500.00|
Product B | 500.00| |
Product B | 800.00| 500.00|
Product B | 1200.00| 800.00|
5.26.9 - NTH_VALUE
Returns the Nth value from an ordered group of values.
See also:
Analyze Syntax
func.nth_value(<expr>, <n>).over(partition_by=[<columns>], order_by=[<columns>])
Analyze Examples
table.employee_id, table.first_name, table.last_name, table.salary, func.nth_value(table.first_name, 2).over(order_by=table.salary.desc()).alias('second_highest_salary_first_name')
employee_id | first_name | last_name | salary | second_highest_salary_first_name
------------+------------+-----------+---------+----------------------------------
4 | Mary | Williams | 7000.00 | Jane
2 | Jane | Smith | 6000.00 | Jane
3 | David | Johnson | 5500.00 | Jane
1 | John | Doe | 5000.00 | Jane
5 | Michael | Brown | 4500.00 | Jane
SQL Syntax
NTH_VALUE(expression, n) OVER ([PARTITION BY partition_expression] ORDER BY order_expression [window_frame])
For the syntax of window frame, see Window Frame Syntax.
SQL Examples
CREATE TABLE employees (
employee_id INT,
first_name VARCHAR(50),
last_name VARCHAR(50),
salary DECIMAL(10,2)
);
INSERT INTO employees (employee_id, first_name, last_name, salary)
VALUES
(1, 'John', 'Doe', 5000.00),
(2, 'Jane', 'Smith', 6000.00),
(3, 'David', 'Johnson', 5500.00),
(4, 'Mary', 'Williams', 7000.00),
(5, 'Michael', 'Brown', 4500.00);
-- Use NTH_VALUE to retrieve the first name of the employee with the second highest salary
SELECT employee_id, first_name, last_name, salary,
NTH_VALUE(first_name, 2) OVER (ORDER BY salary DESC) AS second_highest_salary_first_name
FROM employees;
employee_id | first_name | last_name | salary | second_highest_salary_first_name
------------+------------+-----------+---------+----------------------------------
4 | Mary | Williams | 7000.00 | Jane
2 | Jane | Smith | 6000.00 | Jane
3 | David | Johnson | 5500.00 | Jane
1 | John | Doe | 5000.00 | Jane
5 | Michael | Brown | 4500.00 | Jane
5.26.10 - NTILE
Divides the sorted result set into a specified number of buckets or groups. It evenly distributes the sorted rows into these buckets and assigns a bucket number to each row. The NTILE function is typically used with the ORDER BY clause to sort the results.
Please note that the NTILE function evenly distributes the rows into buckets based on the sorting order of the rows and ensures that the number of rows in each bucket is as equal as possible. If the number of rows cannot be evenly distributed into the buckets, some buckets may have one extra row compared to the others.
Analyze Syntax
func.ntile(<n>).over(partition_by=[<columns>], order_by=[<columns>])
Analyze Examples
table.name, table.score, table.grade, func.ntile(3).over(partition_by=[table.grade], order_by=table.score).alias('bucket')
name |score|grade|bucket|
--------+-----+-----+------+
Johnson | 100|A | 1|
Evans | 87|A | 1|
Davies | 84|A | 2|
Smith | 81|A | 3|
Wilson | 72|B | 1|
Thomas | 72|B | 1|
Taylor | 62|B | 2|
Brown | 62|B | 3|
Jones | 55|C | 1|
Williams| 55|C | 2|
SQL Syntax
NTILE(n) OVER (
PARTITION BY expr, ...
ORDER BY expr [ASC | DESC], ...
)
SQL Examples
This example retrieves the students' names, scores, grades, and assigns them to buckets based on their scores within each grade using the NTILE() window function.
CREATE TABLE students (
name VARCHAR(20),
score INT NOT NULL,
grade CHAR(1) NOT NULL
);
INSERT INTO students (name, score, grade)
VALUES
('Smith', 81, 'A'),
('Jones', 55, 'C'),
('Williams', 55, 'C'),
('Taylor', 62, 'B'),
('Brown', 62, 'B'),
('Davies', 84, 'A'),
('Evans', 87, 'A'),
('Wilson', 72, 'B'),
('Thomas', 72, 'B'),
('Johnson', 100, 'A');
SELECT
name,
score,
grade,
ntile(3) OVER (PARTITION BY grade ORDER BY score DESC) AS bucket
FROM
students;
name |score|grade|bucket|
--------+-----+-----+------+
Johnson | 100|A | 1|
Evans | 87|A | 1|
Davies | 84|A | 2|
Smith | 81|A | 3|
Wilson | 72|B | 1|
Thomas | 72|B | 1|
Taylor | 62|B | 2|
Brown | 62|B | 3|
Jones | 55|C | 1|
Williams| 55|C | 2|
5.26.11 - PERCENT_RANK
Returns the relative rank of a given value within a set of values. The resulting value falls between 0 and 1, inclusive. Please note that the first row in any set has a PERCENT_RANK of 0.
See also: CUME_DIST
Analyze Syntax
func.percent_rank().over(partition_by=[<columns>], order_by=[<columns>])
Analyze Examples
table.name, table.score, table.grade, func.percent_rank().over(partition_by=[table.grade], order_by=table.score).alias('percent_rank')
name |score|grade|percent_rank |
--------+-----+-----+------------------+
Smith | 81|A | 0.0|
Davies | 84|A |0.3333333333333333|
Evans | 87|A |0.6666666666666666|
Johnson | 100|A | 1.0|
Taylor | 62|B | 0.0|
Brown | 62|B | 0.0|
Wilson | 72|B |0.6666666666666666|
Thomas | 72|B |0.6666666666666666|
Jones | 55|C | 0.0|
Williams| 55|C | 0.0|
SQL Syntax
PERCENT_RANK() OVER (
PARTITION BY expr, ...
ORDER BY expr [ASC | DESC], ...
)
SQL Examples
This example retrieves the students' names, scores, grades, and the percentile ranks (percent_rank) within each grade using the PERCENT_RANK() window function.
CREATE TABLE students (
name VARCHAR(20),
score INT NOT NULL,
grade CHAR(1) NOT NULL
);
INSERT INTO students (name, score, grade)
VALUES
('Smith', 81, 'A'),
('Jones', 55, 'C'),
('Williams', 55, 'C'),
('Taylor', 62, 'B'),
('Brown', 62, 'B'),
('Davies', 84, 'A'),
('Evans', 87, 'A'),
('Wilson', 72, 'B'),
('Thomas', 72, 'B'),
('Johnson', 100, 'A');
SELECT
name,
score,
grade,
PERCENT_RANK() OVER (PARTITION BY grade ORDER BY score) AS percent_rank
FROM
students;
name |score|grade|percent_rank |
--------+-----+-----+------------------+
Smith | 81|A | 0.0|
Davies | 84|A |0.3333333333333333|
Evans | 87|A |0.6666666666666666|
Johnson | 100|A | 1.0|
Taylor | 62|B | 0.0|
Brown | 62|B | 0.0|
Wilson | 72|B |0.6666666666666666|
Thomas | 72|B |0.6666666666666666|
Jones | 55|C | 0.0|
Williams| 55|C | 0.0|
5.26.12 - RANK
The RANK() function assigns a unique rank to each value within an ordered group of values.
The rank value starts at 1 and continues up sequentially. If two values are the same, they have the same rank.
Analyze Syntax
func.rank().over(partition_by=[<columns>], order_by=[<columns>])
Analyze Examples
table.employee_id, table.first_name, table.last_name, table.department, table.salary, func.rank().over(order_by=table.salary).alias('rank')
| employee_id | first_name | last_name | department | salary | rank |
|-------------|------------|-----------|------------|--------|------|
| 1 | John | Doe | IT | 90000 | 1 |
| 2 | Jane | Smith | HR | 85000 | 2 |
| 3 | Mike | Johnson | IT | 82000 | 3 |
| 4 | Sara | Williams | Sales | 77000 | 4 |
| 5 | Tom | Brown | HR | 75000 | 5 |
SQL Syntax
RANK() OVER (
[ PARTITION BY <expr1> ]
ORDER BY <expr2> [ { ASC | DESC } ]
[ <window_frame> ]
)
SQL Examples
Create the table
CREATE TABLE employees (
employee_id INT,
first_name VARCHAR,
last_name VARCHAR,
department VARCHAR,
salary INT
);
Insert data
INSERT INTO employees (employee_id, first_name, last_name, department, salary) VALUES
(1, 'John', 'Doe', 'IT', 90000),
(2, 'Jane', 'Smith', 'HR', 85000),
(3, 'Mike', 'Johnson', 'IT', 82000),
(4, 'Sara', 'Williams', 'Sales', 77000),
(5, 'Tom', 'Brown', 'HR', 75000);
Ranking employees by salary
SELECT
employee_id,
first_name,
last_name,
department,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank
FROM
employees;
Result:
| employee_id | first_name | last_name | department | salary | rank |
|---|---|---|---|---|---|
| 1 | John | Doe | IT | 90000 | 1 |
| 2 | Jane | Smith | HR | 85000 | 2 |
| 3 | Mike | Johnson | IT | 82000 | 3 |
| 4 | Sara | Williams | Sales | 77000 | 4 |
| 5 | Tom | Brown | HR | 75000 | 5 |
5.26.13 - ROW_NUMBER
Assigns a temporary sequential number to each row within a partition of a result set, starting at 1 for the first row in each partition.
Analyze Syntax
func.row_number().over(partition_by=[<columns>], order_by=[<columns>])
Analyze Examples
table.employee_id, table.first_name, table.last_name, table.department, table.salary, func.row_number().over(partition=table.department, order_by=table.salary).alias('row_num')
┌──────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ employee_id │ first_name │ last_name │ department │ salary │ row_num │
├─────────────────┼──────────────────┼──────────────────┼──────────────────┼─────────────────┼─────────┤
│ 2 │ Jane │ Smith │ HR │ 85000 │ 1 │
│ 5 │ Tom │ Brown │ HR │ 75000 │ 2 │
│ 1 │ John │ Doe │ IT │ 90000 │ 1 │
│ 3 │ Mike │ Johnson │ IT │ 82000 │ 2 │
│ 4 │ Sara │ Williams │ Sales │ 77000 │ 1 │
└──────────────────────────────────────────────────────────────────────────────────────────────────────┘
SQL Syntax
ROW_NUMBER()
OVER ( [ PARTITION BY <expr1> [, <expr2> ... ] ]
ORDER BY <expr3> [ , <expr4> ... ] [ { ASC | DESC } ] )
| Parameter | Required? | Description |
|---|---|---|
| ORDER BY | Yes | Specifies the order of rows within each partition. |
| ASC / DESC | No | Specifies the sorting order within each partition. ASC (ascending) is the default. |
| QUALIFY | No | Filters rows based on conditions. |
SQL Examples
This example demonstrates the use of ROW_NUMBER() to assign sequential numbers to employees within their departments, ordered by descending salary.
-- Prepare the data
CREATE TABLE employees (
employee_id INT,
first_name VARCHAR,
last_name VARCHAR,
department VARCHAR,
salary INT
);
INSERT INTO employees (employee_id, first_name, last_name, department, salary) VALUES
(1, 'John', 'Doe', 'IT', 90000),
(2, 'Jane', 'Smith', 'HR', 85000),
(3, 'Mike', 'Johnson', 'IT', 82000),
(4, 'Sara', 'Williams', 'Sales', 77000),
(5, 'Tom', 'Brown', 'HR', 75000);
-- Select employee details along with the row number partitioned by department and ordered by salary in descending order.
SELECT
employee_id,
first_name,
last_name,
department,
salary,
ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) AS row_num
FROM
employees;
┌──────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ employee_id │ first_name │ last_name │ department │ salary │ row_num │
├─────────────────┼──────────────────┼──────────────────┼──────────────────┼─────────────────┼─────────┤
│ 2 │ Jane │ Smith │ HR │ 85000 │ 1 │
│ 5 │ Tom │ Brown │ HR │ 75000 │ 2 │
│ 1 │ John │ Doe │ IT │ 90000 │ 1 │
│ 3 │ Mike │ Johnson │ IT │ 82000 │ 2 │
│ 4 │ Sara │ Williams │ Sales │ 77000 │ 1 │
└──────────────────────────────────────────────────────────────────────────────────────────────────────┘
6 - Custom App Sandbox
6.1 - Getting Started with the Custom App Sandbox
What is the Sandbox
The PlaidCloud Sandbox allows for the deployment of your own custom apps with native local access to data and PlaidCloud operations. The Sandbox environment provides a full compute environment for building custom applications to augment your use of PlaidCloud.
All custom apps run using Kubernetes deployment processes, therefore a basic understanding of Kubernetes objects is necessary. A Hello World example is available to show you how to deploy a simple application.
Available Resources
There is soft resource limit on the Sandbox apps with the expectation that resource usage will not be abused. We can support large amounts of compute if needed but let's discuss before attempting to deploy. Contact us if you expect needing significant resources.
The applications running the in the sandbox will have direct access to the Lakehouse and any number of Postgres databases that you desire. Postgres databases are designed to handle moderate sized data so it is perfect for storing configurations and other meta data. For primary data storage, use the Lakehouse as it will enable storing large amounts of data and remain performant.
All PlaidCloud APIs are also available directly from the Sandbox without using a public URL to help with data transfer speeds.
Image Requirements
Any image that supports a Docker based Kubernetes deployment is suitable for a custom app. Only *nix based images are currently supported. If you have a need to run a Windows based image, please contact us.
Integrate with Your CI/CD Pipeline
The Kubernetes deployment of the Sandbox app utilizes GitOps processes. This allows you to implement your own CI/CD process for image builds and deployments. Your custom app git repo is constantly monitored for changes so as updates are made, your sandbox will be updated.
7 - PySpark and Spark Compute Clusters
7.1 - Getting Started with PySpark
PySpark Documentation
PySpark is similar to using Pandas but allows for distributed compute and is not RAM bound. PySpark is available in both UDFs and Jupyter Notebooks.
Spark Cluster
By default, workspaces do not have the Spark cluster enabled. To activate the Spark Cluster, go to the Workspace management app and enable the "Spark Compute Cluster" service.
Once activated, Spark jobs can be submitted to the cluster.
The cluster can be monitored from the spark sub-domain for the Workspace (e.g. https://spark.my_workspace.plaid.cloud)
8 - How To
8.1 - Selecting the Latest Record in a Large Version History Table
Challenge
A table that contains many versions of each record is available but you must use the latest version.
Discussion
This problem could be solved by selecting the ID and MAX update date into a temporary table. Then that temporary table could be INNER JOINED back to the history table to obtain the result. Unfortunately, this requires two steps and storing an intermediate table that has no function other than finding the latest update.
The more elegant solution to perform this operation in a single query uses a Window Function with sort plus a filter.
Solution
The version history table
| employee_id | department | salary | update_date |
|---|---|---|---|
| 3 | IT | 90000 | 2024-09-17 |
| 2 | HR | 85000 | 2024-09-17 |
| 5 | HR | 82000 | 2024-09-17 |
| 3 | IT | 77000 | 2023-10-01 |
| 3 | IT | 75000 | 2022-10-04 |
| 5 | IT | 72000 | 2024-07-12 |
| 2 | IT | 67000 | 2024-03-18 |
| 1 | Sales | 62000 | 2022-02-28 |
| 5 | Sales | 60000 | 2023-01-14 |
| 4 | Sales | 58000 | 2021-11-19 |
Step Setup
Using an extract step, create a window function expression in a column called Rank like:
func.rank().over(order_by=table.updated_date.desc(), partition_by=table.employee_id)
On the filter tab in the Extract step, set a filter like:
table.Rank == 1
The Result
| employee_id | department | salary | update_date | Rank |
|---|---|---|---|---|
| 3 | IT | 90000 | 2024-09-17 | 1 |
| 2 | HR | 85000 | 2024-09-17 | 1 |
| 5 | HR | 82000 | 2024-09-17 | 1 |
| 1 | Sales | 62000 | 2022-02-28 | 1 |
| 4 | Sales | 58000 | 2021-11-19 | 1 |
This approach is highly efficient and allows selection of the latest record in a multi-version history table in a single step. This works by ranking each record within the employee_id group by the update_date and then only picking the first record.
If there are multiple columns that make up the unique row key, you can add them to the partition_by argument as a list like:
partition_by=[table.first_column, table.second_column, table.third_column]
If you need to apply multi-column sorts you can apply that with a list of columns too like:
order_by=[table.first_column.desc(), table.second_column, table.third_column.desc()]